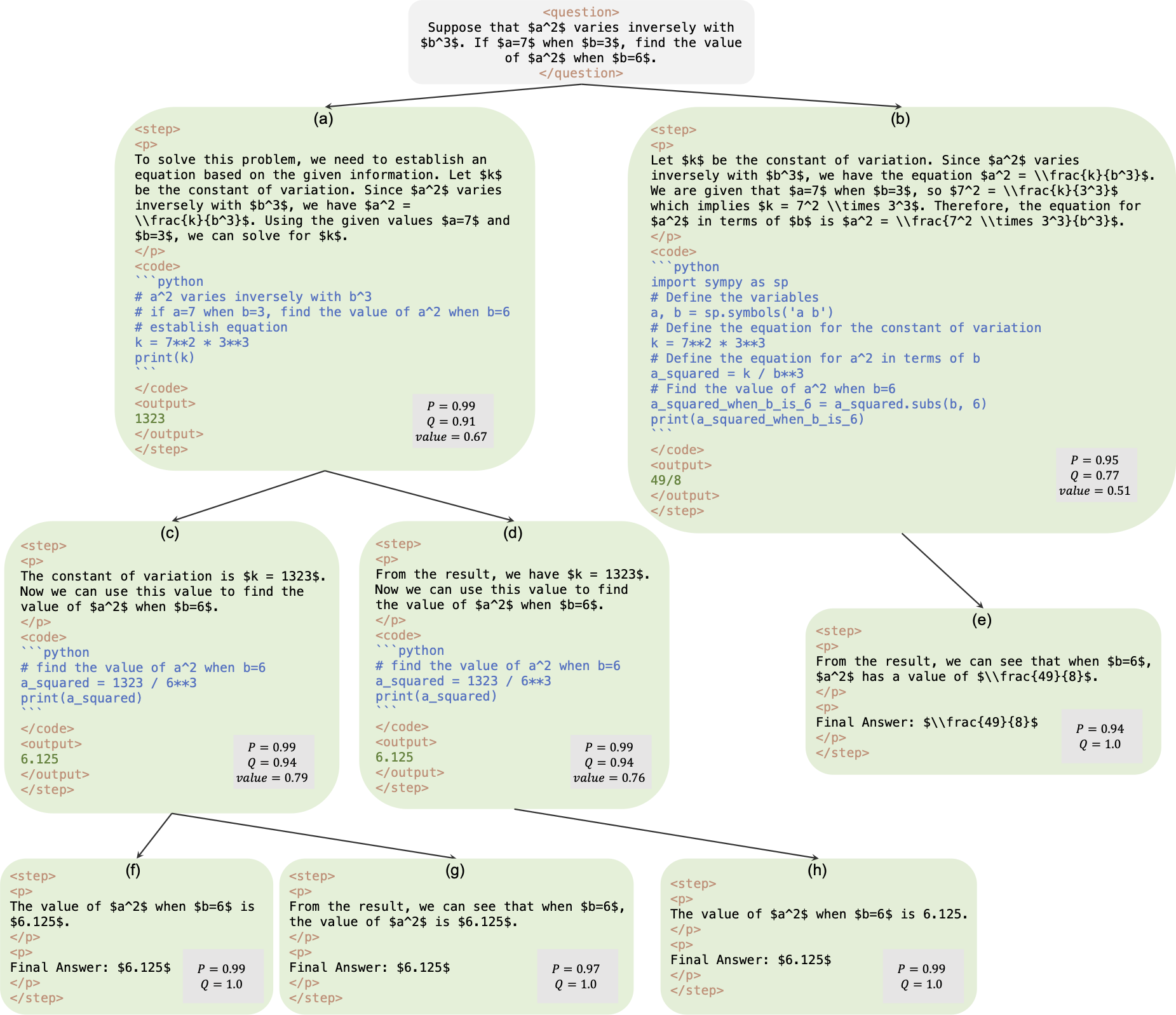
이것은 AlphaMath Almost Zero: 프로세스 없는 프로세스 감독 논문의 공식 저장소입니다. 코드는 내부 회사 코드베이스에서 추출됩니다. 결과적으로 우리 논문에 보고된 수치를 재현할 때 약간의 차이가 있을 수 있지만 매우 유사해야 합니다. 우리의 접근 방식에는 MCTS(Monte Carlo Tree Search) 프레임워크에서 파생된 수학적 추론만을 사용하여 정책 및 가치 모델을 교육하는 것이 포함되어 있어 GPT-4 또는 사람 주석이 필요하지 않습니다. 이는 3라운드에서 MCTS가 생성한 훈련 인스턴스의 그림입니다.
체크포인트 : AlphaMath-7B 3라운드? / AlphaMath-7B 3라운드?
데이터세트 : AlphaMath-Round3-Trainset ? 학습 데이터의 해결 과정은 MCTS와 2라운드 체크포인트를 기반으로 자동 생성됩니다. 정책 및 가치 모델 학습에는 긍정적인 사례와 부정적인 사례가 모두 포함됩니다.
학습 코드 : 정책으로 인해 기본적으로 자체 학습 코드에서 수정되어야 하는 일부 주요 기능의 구현 세부정보만 공개할 수 있습니다.
| 추론 방법 | 정확성 | 평균 q당 시간(초) | 평균 단계 | # 솔 |
|---|---|---|---|---|
| 탐욕스러운 | 53.62 | 1.6 | 3.1 | 1 |
| 메이저@5 | 61.84 | 2.9 | 2.9 | 5 |
| 계단식 빔(1,5) | 62.32 | 3.1 | 3.0 | 탑-1 |
| 5런 + Maj@5 | 67.04 | x5 | x1 | 상위 5개-1 |
| 계단식 빔(2,5) | 64.66 | 2.4 | 2.4 | 탑-1 |
| 계단식 빔(3,5) | 65.74 | 2.3 | 2.2 | 탑-1 |
| 계단식 빔(5,5) | 65.98 | 4.7 | 2.3 | 탑-1 |
| 1런 + Maj@5 | 66.54 | x1 | x1 | 상위 5위 |
| 5런 + Maj@5 | 69.94 | x5 | x1 | 상위 5개-1 |
| MCTS(N=40) | 64.02 | 10.1 | 3.8 | 탑-1 |
+ Maj@5 다양성을 장려하기 위해 5번 실행해야 합니다.+ Maj@5 다양성이 부족한 5개의 후보를 직접 사용합니다.| 온도 | 0.6 | 1.0 |
|---|---|---|
| 계단식 빔(1,5) | 62.32 | 62.76 |
| 계단식 빔(2,5) | 64.66 | 65.60 |
| 계단식 빔(3,5) | 65.74 | 66.28 |
| 계단식 빔(5,5) | 65.98 | 66.38 |
단계 수준 빔 검색의 경우 temperature=1.0 으로 설정하면 약간 더 나은 결과를 얻을 수 있습니다.
requirements.txt 설치.txt pip install -r requirements.txt
아니면 단순히 cmd를 따르십시오
> git clone https://github.com/MARIO-Math-Reasoning/Super_MARIO.git
> git clone https://github.com/MARIO-Math-Reasoning/MARIO_EVAL.git
> git clone https://github.com/MARIO-Math-Reasoning/vllm.git
> cd Super_MARIO && pip install -r requirements.txt && cd ..
> cd MARIO_EVAL/latex2sympy && pip install . && cd ..
> pip install -e .
> cd ../vllm
> pip install -e . scripts/save_value_head.py 사용하여 LLM에 값 head를 추가할 수 있습니다. 다음 두 cmd 중 하나를 실행할 수 있습니다. 둘 사이에는 정확도에 약간의 차이가 있을 수 있습니다. 우리 컴퓨터에서 첫 번째는 53.4%를 얻었고 두 번째는 53.62%를 얻었습니다.
python react_batch_demo.py
--custom_cfg configs/react_sft.yaml
--qaf ../MARIO_EVAL/data/math_testset_annotation.json
또는
# use step_beam (1, 1) without value func
python solver_demo.py
--custom_cfg configs/sbs_greedy.yaml
--qaf ../MARIO_EVAL/data/math_testset_annotation.json
우리 머신의 MATH 테스트 세트에서 B1=1, B2=5 구성을 사용하는 다음 cmd는 ~62%를 달성할 수 있고 B1=3, B2=5 구성을 사용하는 cmd는 ~65%에 도달할 수 있습니다.
python solver_demo.py
--custom_cfg configs/sbs_sft.yaml
--qaf ../MARIO_EVAL/data/math_testset_annotation.json
정확도 계산
python eval_output_jsonl.py
--res_file <the saved tree jsonl file by solver_demo.py>
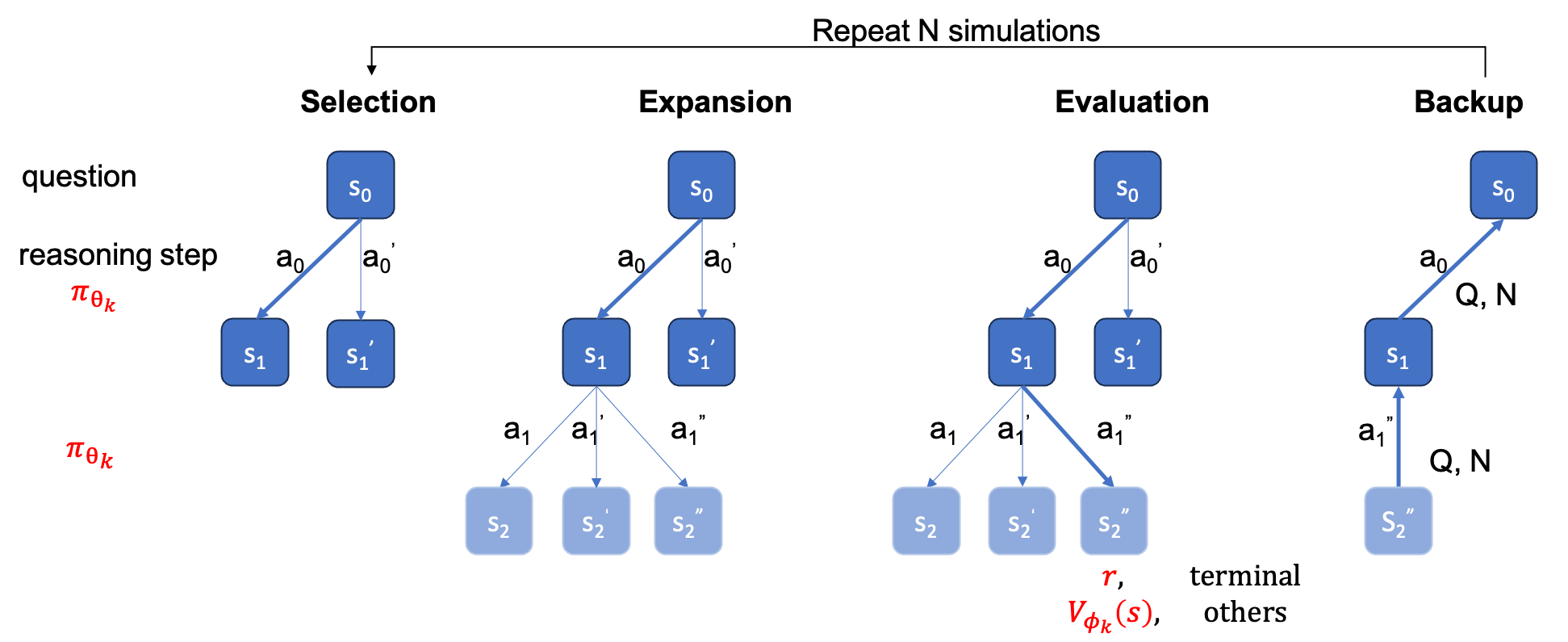
ground_truth (해결 과정이 아닌 최종 답변)는 qaf json 또는 jsonl 파일에 제공되어야 합니다(예제 형식은 ../MARIO_EVAL/data/math_testset_annotation.json 을 참조할 수 있음).
1라운드
# Checkpoint Initialization is required by adding value head
python solver_demo.py
--custom_cfg configs/mcts_round1.yaml
--qaf /path/to/training/data
라운드 > 1, SFT 이후
python solver_demo.py
--custom_cfg configs/mcts_sft_round.yaml
--qaf /path/to/training/data
솔루션 생성에는 question 만 사용되지만 정확도 계산에는 ground_truth 가 사용됩니다.
python solver_demo.py
--custom_cfg configs/mcts_sft.yaml
--qaf ../MARIO_EVAL/data/math_testset_annotation.json
단계 수준 빔 검색과 달리 먼저 완전한 트리를 구축한 다음 MCTS를 오프라인으로 실행한 다음 정확도를 계산해야 합니다.
python offline_inference.py
--custom_cfg configs/offline_inference.yaml
--tree_jsonl <the saved tree jsonl file by solver_demo.py>
참고: 이 평가 스크립트는 단계 수준 빔 검색을 통해 저장된 트리로 실행할 수도 있으며 정확도는 동일하게 유지되어야 합니다.
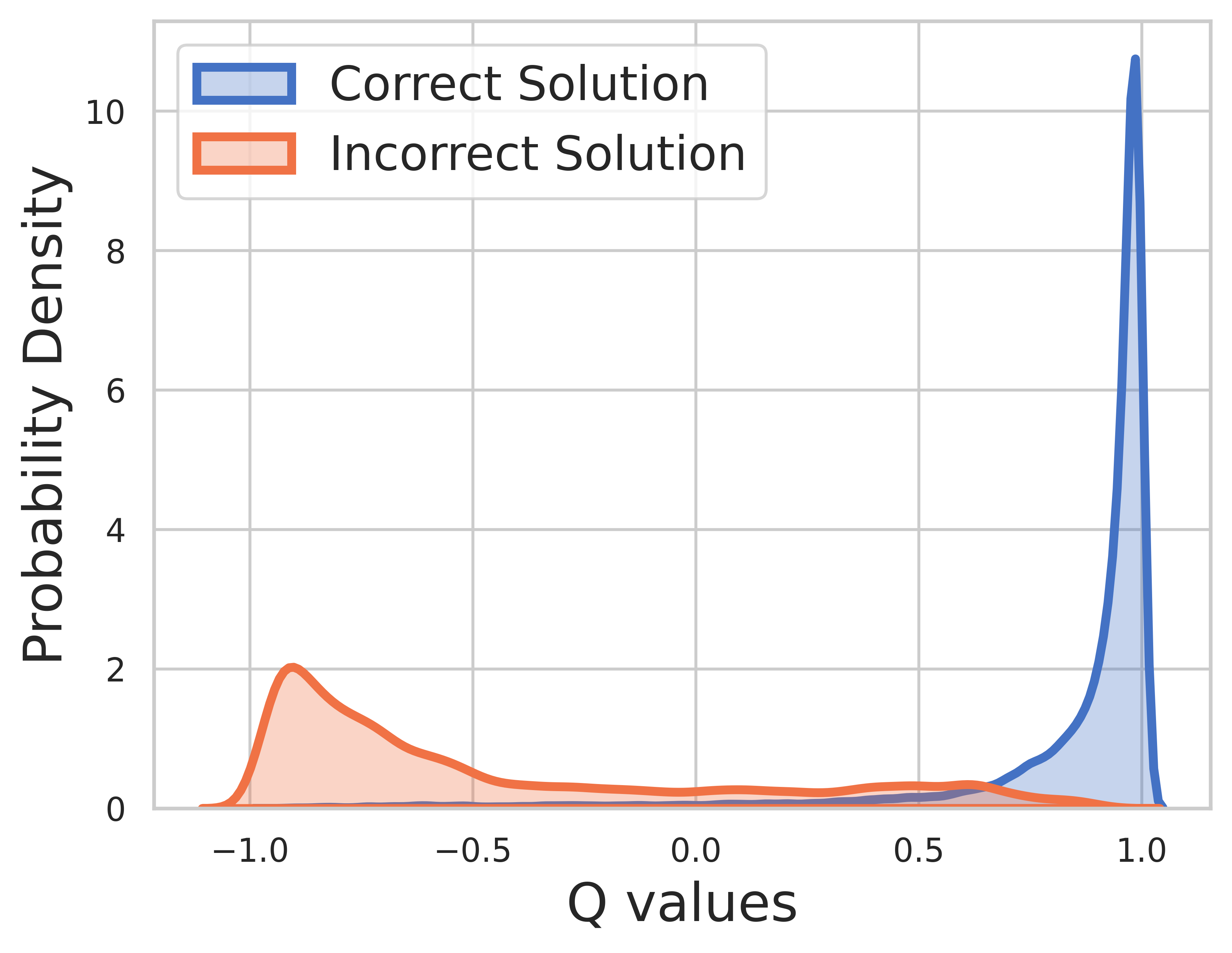
훈련 데이터에 대한 Ground Truth가 알려져 있기 때문에 최종 단계의 가치는 보상이며 Q-값은 매우 잘 수렴할 수 있습니다.
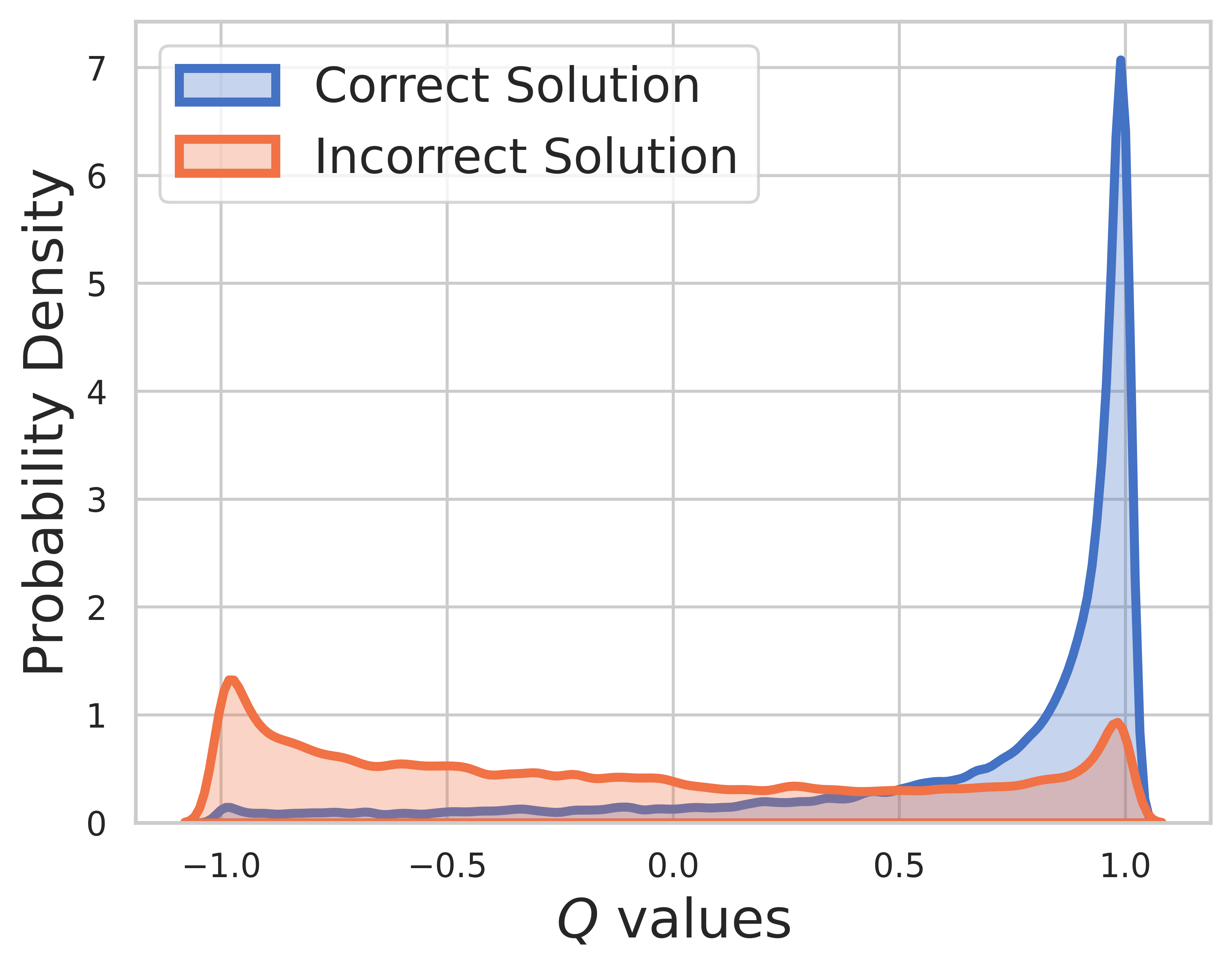
테스트 세트에서는 실제 진실을 알 수 없으므로 Q-값 분포에는 중간 단계와 최종 단계가 모두 포함됩니다. 이 그림에서 우리는 다음을 찾을 수 있습니다.
MCTS의 SVPO
@misc{chen2024steplevelvaluepreferenceoptimization,
title={Step-level Value Preference Optimization for Mathematical Reasoning},
author={Guoxin Chen and Minpeng Liao and Chengxi Li and Kai Fan},
year={2024},
eprint={2406.10858},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2406.10858},
}
MCTS 버전
@misc{chen2024alphamathzeroprocesssupervision,
title={AlphaMath Almost Zero: process Supervision without process},
author={Guoxin Chen and Minpeng Liao and Chengxi Li and Kai Fan},
year={2024},
eprint={2405.03553},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2405.03553},
}
평가 툴킷
@misc{zhang2024marioevalevaluatemath,
title={MARIO Eval: Evaluate Your Math LLM with your Math LLM--A mathematical dataset evaluation toolkit},
author={Boning Zhang and Chengxi Li and Kai Fan},
year={2024},
eprint={2404.13925},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2404.13925},
}
OVM(결과 가치 모델) 버전
@misc{liao2024mariomathreasoningcode,
title={MARIO: MAth Reasoning with code Interpreter Output -- A Reproducible Pipeline},
author={Minpeng Liao and Wei Luo and Chengxi Li and Jing Wu and Kai Fan},
year={2024},
eprint={2401.08190},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2401.08190},
}


