
Xuan Ju 1* , Yiming Gao 1* , Zhaoyang Zhang 1*# , Ziyang Yuan 1 , Xintao Wang 1 , Ailing Zeng, Yu Xiong, Qiang Xu, Ying Shan 1
1 ARC Lab, Tencent PCG 2 홍콩중문대학교 * 동일기여 # 프로젝트 리더
비디오 데이터 세트는 Sora와 같은 비디오 생성에서 중요한 역할을 합니다. 그러나 기존의 텍스트-비디오 데이터 세트는 긴 비디오 시퀀스를 처리 하고 장면 전환을 캡처하는 데 있어 부족한 경우가 많습니다. 이러한 제한 사항을 해결하기 위해 우리는 긴 비디오 생성 작업을 위해 특별히 설계된 비디오 데이터 세트 인 MiraData를 소개합니다. 또한, 비디오 생성 시 시간적 일관성과 모션 강도를 더 잘 평가하기 위해 3D 일관성 및 추적 기반 모션 강도 메트릭을 추가하여 기존 벤치마크를 향상시키는 MiraBench를 도입했습니다. 자세한 내용은 당사 연구 논문에서 확인하실 수 있습니다.
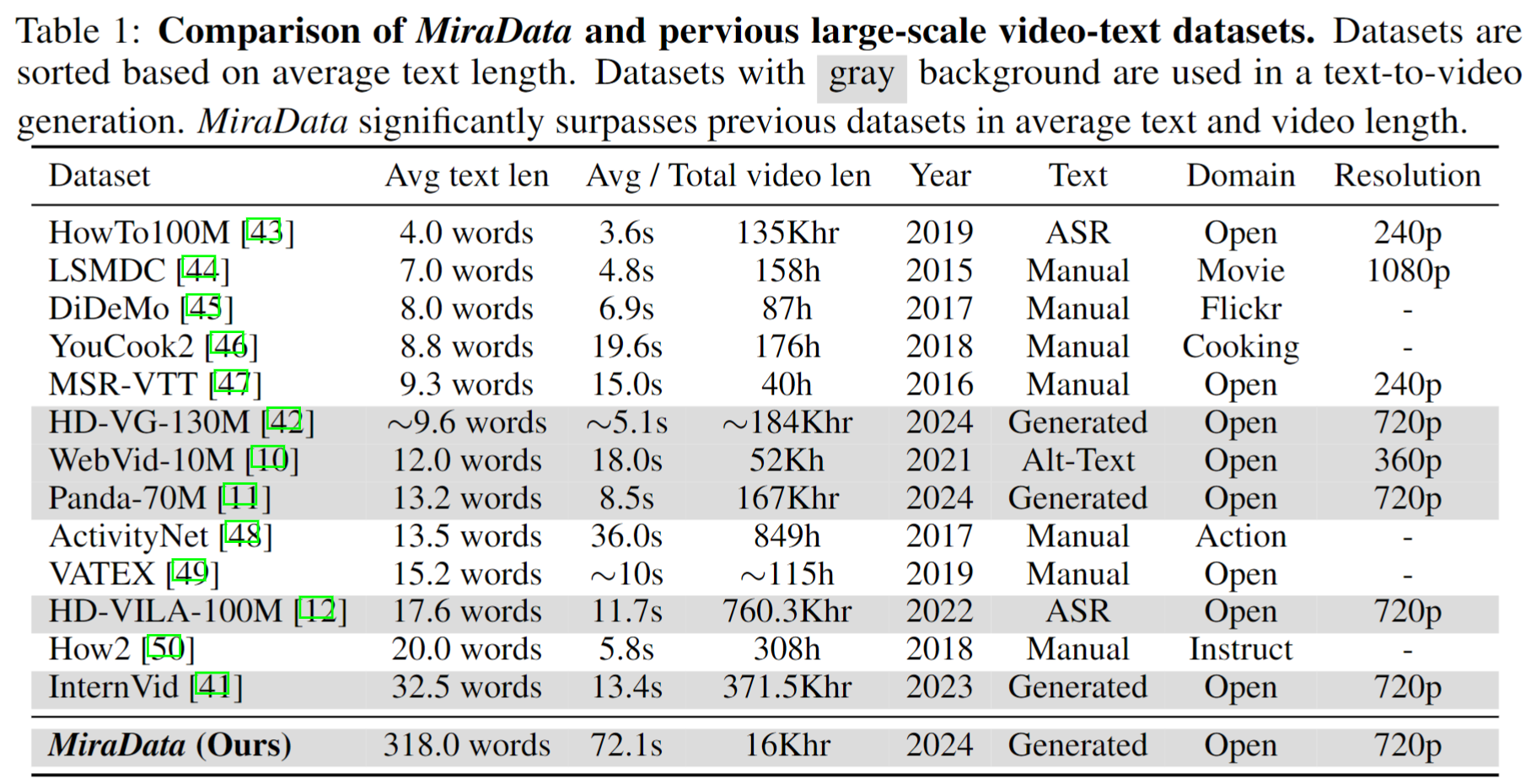
우리는 330K, 93K, 42K, 9K 데이터를 포함하는 네 가지 버전의 MiraData를 출시합니다.
이 버전의 MiraData에 대한 메타 파일은 Google Drive 및 HuggingFace Dataset에서 제공됩니다. 또한 메타 파일 구성을 더 빠르고 더 잘 이해하기 위해 여기에서 액세스할 수 있는 100개의 비디오 클립 세트를 무작위로 샘플링합니다. 메타 파일에는 다음과 같은 색인 정보가 포함되어 있습니다.
{download_id}.{clip_id} 로 구성됩니다.비디오를 다운로드하고 클립으로 분할하려면 먼저 Google Drive 또는 HuggingFace Dataset에서 메타 파일을 다운로드하세요. 메타 파일이 있으면 다음 스크립트를 사용하여 비디오 샘플을 다운로드할 수 있습니다.
python download_data.py --meta_csv {meta file} --download_start_id {the start of download id} --download_end_id {the end of download id} --raw_video_save_dir {the path of saving raw videos} --clip_video_save_dir {the path of saving cutted video}
필요한 경우 데이터세트/Github/프로젝트 웹페이지에서 비디오 샘플을 제거할 예정입니다. 요청에 대해서는 당사에 문의해 주십시오.
MiraData를 수집하기 위해 먼저 다양한 시나리오에서 YouTube 채널을 수동으로 선택하고 HD-VILA-100M, Videovo, Pixabay 및 Pexels의 비디오를 포함합니다. 그런 다음 PySceneDetect를 사용하여 해당 채널의 모든 비디오를 다운로드하고 분할합니다. 그런 다음 여러 모델을 사용하여 짧은 클립을 하나로 묶고 품질이 낮은 비디오를 필터링했습니다. 그 다음에는 길이가 긴 비디오 클립을 선택했습니다. 마지막으로 GPT-4V를 사용하여 모든 비디오 클립에 캡션을 추가했습니다.

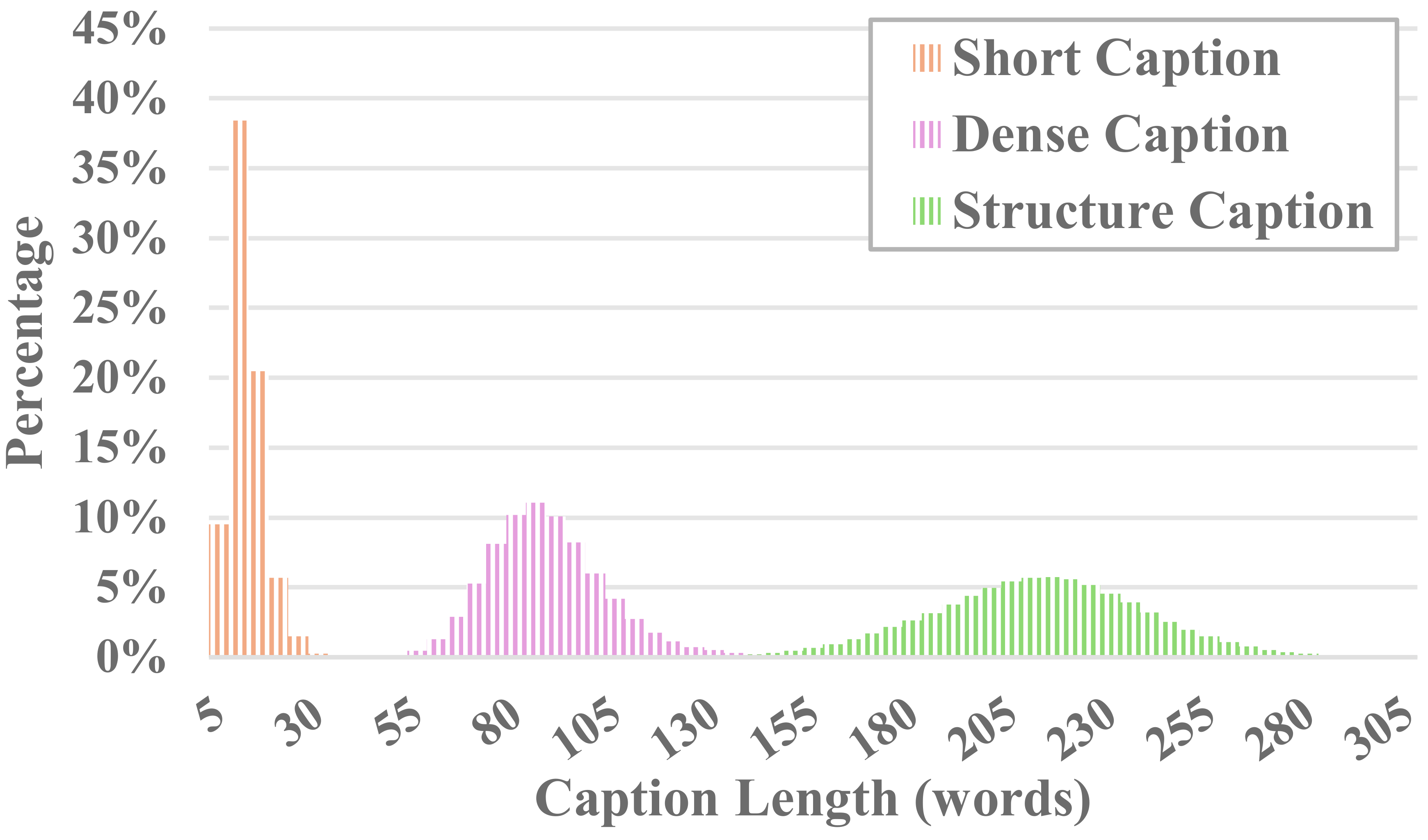
MiraData의 각 비디오에는 구조화된 캡션이 함께 제공됩니다. 이러한 캡션은 다양한 관점에서 자세한 설명을 제공하여 데이터세트의 풍부함을 높여줍니다.
6가지 유형의 캡션
우리는 기존 오픈 소스 시각적 LLM 방법과 GPT-4V를 테스트한 결과, GPT-4V의 캡션이 시간 순서 측면에서 의미론적 이해에 있어 더 나은 정확성과 일관성을 보이는 것을 발견했습니다.
주석 비용과 캡션 정확도의 균형을 맞추기 위해 각 비디오에 대해 8개의 프레임을 균일하게 샘플링하고 이를 하나의 큰 이미지의 2x4 그리드로 배열합니다. 그런 다음 Panda-70M의 캡션 모델을 사용하여 주요 콘텐츠에 대한 힌트 역할을 하는 한 문장 캡션으로 각 비디오에 주석을 달고 이를 미세 조정된 프롬프트에 입력합니다. 미세 조정된 프롬프트와 2x4 대형 이미지를 GPT-4V에 공급함으로써 단 한 번의 대화만으로 다양한 차원의 캡션을 효율적으로 출력할 수 있습니다. 구체적인 프롬프트 내용은 caption_gpt4v.py에서 찾을 수 있으며, 보다 고품질의 텍스트-비디오 데이터에 기여하는 모든 사람을 환영합니다. ?

긴 비디오 생성을 평가하기 위해 MiraBench에서 시간적 일관성, 시간적 동작 강도, 3D 일관성, 시각적 품질, 텍스트-비디오 정렬 및 배포 일관성을 포함한 6가지 관점에서 17가지 평가 지표를 설계했습니다. 이러한 측정항목은 이전 비디오 생성 모델 및 텍스트-비디오 벤치마크에서 사용된 대부분의 일반적인 평가 표준을 포함합니다.
생성된 비디오를 평가하려면 먼저 다음을 통해 Python 환경을 설정하십시오.
pip install torch==1.12.1+cu116 torchvision==0.13.1+cu116 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu116
pip install -r requirements.txt
그런 다음 다음을 통해 평가를 실행합니다.
python calculate_score.py --meta_file data/evaluation_example/meta_generated.csv --frame_dir data/evaluation_example/frames_generated --gt_meta_file data/evaluation_example/meta_gt.csv --gt_frame_dir data/evaluation_example/frames_gt --output_folder data/evaluation_example/results --ckpt_path data/ckpt --device cuda
data/evaluation_example 의 예를 따라 자신이 생성한 비디오를 평가할 수 있습니다.
라이센스를 참조하십시오.
이 프로젝트가 귀하의 연구에 유용하다고 생각하시면 저희 논문을 인용해 주세요. ?
@misc{ju2024miradatalargescalevideodataset,
title={MiraData: A Large-Scale Video Dataset with Long Durations and Structured Captions},
author={Xuan Ju and Yiming Gao and Zhaoyang Zhang and Ziyang Yuan and Xintao Wang and Ailing Zeng and Yu Xiong and Qiang Xu and Ying Shan},
year={2024},
eprint={2407.06358},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2407.06358},
}
문의 사항이 있으시면 [email protected] 으로 이메일을 보내주세요.
MiraData는 GPL-v3 라이선스를 따르며 상업적 사용이 지원됩니다. MiraData에 대한 상용 라이선스가 필요한 경우 언제든지 문의해 주세요.


