storm
v1.0.0 & EMNLP 2024 Paper Accepted!
| 연구 미리보기 | 폭풍 종이 | 공동STORM 종이 | 웹사이트 |
최신 뉴스
[2024/09] Co-STORM 코드베이스가 출시되어 knowledge-storm Python 패키지 v1.0.0에 통합되었습니다. pip install knowledge-storm --upgrade 실행하여 확인하세요.
[2024/09] 인간-AI 협업 지식 큐레이션을 지원하는 협업 STORM(Co-STORM)을 소개합니다! Co-STORM 논문이 EMNLP 2024 메인 컨퍼런스에 승인되었습니다.
[2024/07] 이제 pip install knowledge-storm 으로 패키지를 설치할 수 있습니다!
[2024/07] 사용자 제공 문서 기반을 지원하기 위해 VectorRM 추가하여 기존 검색 엔진( YouRM , BingSearch ) 지원을 보완합니다. (#58을 확인하세요)
[2024/07] 로컬 개발 및 데모 호스팅에 편리한 Python의 스트림라이트 프레임워크로 구축된 최소한의 사용자 인터페이스를 개발자를 위한 데모 라이트 출시합니다(체크아웃 #54)
[2024/06] NAACL 2024에서 STORM을 선보입니다! 6월 17일 포스터 세션 2에서 우리를 찾거나 발표 자료를 확인하세요.
[2024/05] rm.py에 Bing Search 지원을 추가합니다. GPT-4o 로 STORM을 테스트하세요. 이제 GPT-4o 모델을 사용하여 데모에서 기사 생성 부분을 구성합니다.
[2024/04] STORM 코드베이스 리팩토링 버전을 출시합니다! STORM 파이프라인에 대한 인터페이스를 정의하고 STORM-wiki( src/storm_wiki 확인)를 다시 구현하여 파이프라인을 인스턴스화하는 방법을 보여줍니다. 다양한 언어 모델의 사용자 정의 및 검색/검색 통합을 지원하는 API를 제공합니다.
시스템은 종종 상당한 수의 편집이 필요한 출판 준비가 된 기사를 생성할 수 없지만 숙련된 Wikipedia 편집자들은 작성 전 단계에서 이 시스템이 도움이 된다는 것을 알았습니다.
70,000명이 넘는 사람들이 실시간 연구 미리보기를 사용해 보았습니다. STORM이 귀하의 지식 탐구 여정에 어떻게 도움이 되는지 확인하고 시스템 개선에 도움이 되는 피드백을 제공해 주세요!
STORM은 인용이 포함된 긴 기사 생성을 두 단계로 나눕니다.
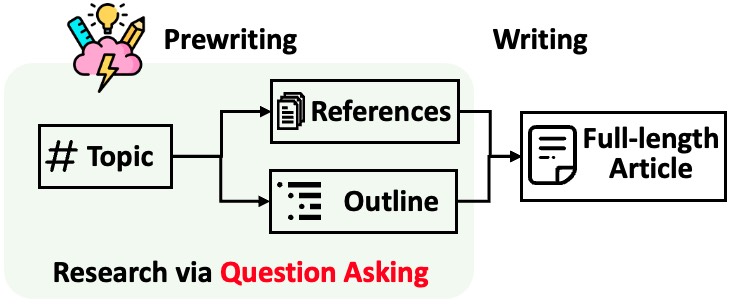
STORM은 조사 프로세스 자동화의 핵심이 좋은 질문을 자동으로 제시하는 것임을 식별합니다. 질문을 하도록 언어 모델에 직접 프롬프트를 표시하는 것은 제대로 작동하지 않습니다. 질문의 깊이와 폭을 높이기 위해 STORM은 두 가지 전략을 채택합니다.
Co-STORM은 구성원 간의 원활한 협업을 지원하기 위해 턴 관리 정책을 구현하는 협업 담론 프로토콜을 제안합니다.
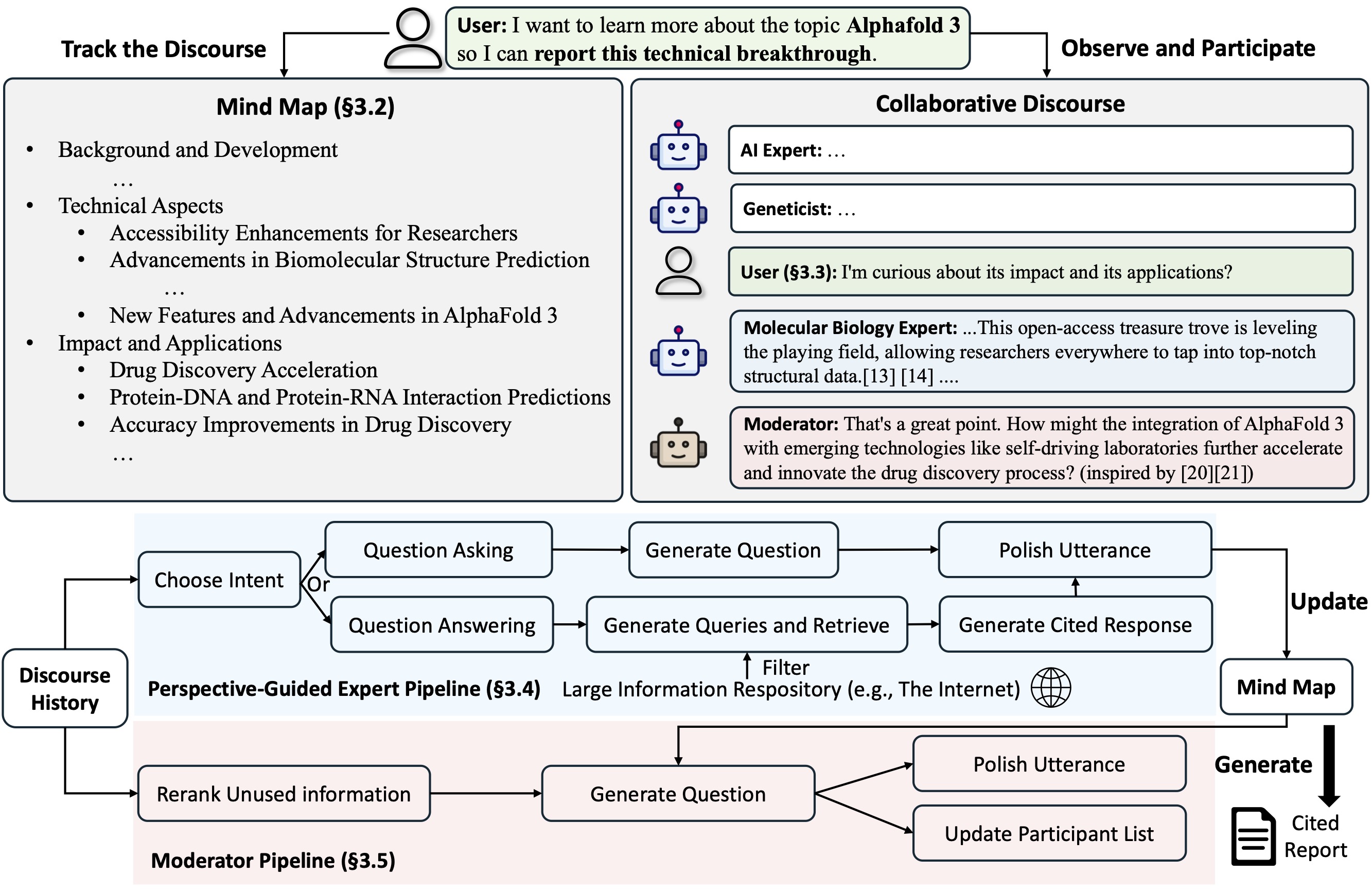
Co-STORM은 또한 인간 사용자와 시스템 사이에 공유 개념 공간을 구축하는 것을 목표로 수집된 정보를 계층적 개념 구조로 구성하는 역동적으로 업데이트된 마인드 맵을 유지합니다. 마인드맵은 담론이 길고 심도 있게 진행될 때 정신적 부담을 줄이는 데 도움이 되는 것으로 입증되었습니다.
STORM과 Co-STORM은 모두 dspy를 사용하여 고도로 모듈화된 방식으로 구현됩니다.
Knowledge Storm 라이브러리를 설치하려면 pip install knowledge-storm 사용하세요.
STORM 엔진의 동작을 직접 수정할 수 있는 소스 코드를 설치할 수도 있습니다.
Git 저장소를 복제합니다.
git clone https://github.com/stanford-oval/storm.git
cd storm필수 패키지를 설치합니다.
conda create -n storm python=3.11
conda activate storm
pip install -r requirements.txt현재 우리의 패키지 지원은 다음과 같습니다.
OpenAIModel , AzureOpenAIModel , ClaudeModel , VLLMClient , TGIClient , TogetherClient , OllamaClient , GoogleModel , DeepSeekModel , GroqModel 언어 모델 구성 요소YouRM , BingSearch , VectorRM , SerperRM , BraveRM , SearXNG , DuckDuckGoSearchRM , TavilySearchRM , GoogleSearch 및 AzureAISearch? 더 많은 언어 모델을 Knowledge_storm/lm.py에 통합하고 검색 엔진/검색기를 Knowledge_storm/rm.py에 통합하기 위한 PR은 높이 평가됩니다!
STORM과 Co-STORM은 모두 정보 큐레이션 레이어에서 작동하므로 각각 Runner 클래스를 생성하려면 정보 검색 모듈과 언어 모델 모듈을 설정해야 합니다.
STORM 지식 큐레이션 엔진은 간단한 Python STORMWikiRunner 클래스로 정의됩니다. 다음은 You.com 검색 엔진과 OpenAI 모델을 사용하는 예입니다.
import os
from knowledge_storm import STORMWikiRunnerArguments , STORMWikiRunner , STORMWikiLMConfigs
from knowledge_storm . lm import OpenAIModel
from knowledge_storm . rm import YouRM
lm_configs = STORMWikiLMConfigs ()
openai_kwargs = {
'api_key' : os . getenv ( "OPENAI_API_KEY" ),
'temperature' : 1.0 ,
'top_p' : 0.9 ,
}
# STORM is a LM system so different components can be powered by different models to reach a good balance between cost and quality.
# For a good practice, choose a cheaper/faster model for `conv_simulator_lm` which is used to split queries, synthesize answers in the conversation.
# Choose a more powerful model for `article_gen_lm` to generate verifiable text with citations.
gpt_35 = OpenAIModel ( model = 'gpt-3.5-turbo' , max_tokens = 500 , ** openai_kwargs )
gpt_4 = OpenAIModel ( model = 'gpt-4o' , max_tokens = 3000 , ** openai_kwargs )
lm_configs . set_conv_simulator_lm ( gpt_35 )
lm_configs . set_question_asker_lm ( gpt_35 )
lm_configs . set_outline_gen_lm ( gpt_4 )
lm_configs . set_article_gen_lm ( gpt_4 )
lm_configs . set_article_polish_lm ( gpt_4 )
# Check out the STORMWikiRunnerArguments class for more configurations.
engine_args = STORMWikiRunnerArguments (...)
rm = YouRM ( ydc_api_key = os . getenv ( 'YDC_API_KEY' ), k = engine_args . search_top_k )
runner = STORMWikiRunner ( engine_args , lm_configs , rm ) STORMWikiRunner 인스턴스는 간단한 run 메소드를 사용하여 호출할 수 있습니다.
topic = input ( 'Topic: ' )
runner . run (
topic = topic ,
do_research = True ,
do_generate_outline = True ,
do_generate_article = True ,
do_polish_article = True ,
)
runner . post_run ()
runner . summary ()do_research : True인 경우 다양한 관점을 가진 대화를 시뮬레이션하여 주제에 대한 정보를 수집합니다. 그렇지 않으면 결과를 로드합니다.do_generate_outline : True인 경우 주제에 대한 개요를 생성합니다. 그렇지 않으면 결과를 로드합니다.do_generate_article : True인 경우 개요 및 수집된 정보를 기반으로 주제에 대한 기사를 생성합니다. 그렇지 않으면 결과를 로드합니다.do_polish_article : True인 경우 요약 섹션을 추가하고 (선택적으로) 중복된 콘텐츠를 제거하여 기사를 다듬습니다. 그렇지 않으면 결과를 로드합니다. Co-STORM 지식 큐레이션 엔진은 간단한 Python CoStormRunner 클래스로 정의됩니다. 다음은 Bing 검색 엔진과 OpenAI 모델을 사용하는 예입니다.
from knowledge_storm . collaborative_storm . engine import CollaborativeStormLMConfigs , RunnerArgument , CoStormRunner
from knowledge_storm . lm import OpenAIModel
from knowledge_storm . logging_wrapper import LoggingWrapper
from knowledge_storm . rm import BingSearch
# Co-STORM adopts the same multi LM system paradigm as STORM
lm_config : CollaborativeStormLMConfigs = CollaborativeStormLMConfigs ()
openai_kwargs = {
"api_key" : os . getenv ( "OPENAI_API_KEY" ),
"api_provider" : "openai" ,
"temperature" : 1.0 ,
"top_p" : 0.9 ,
"api_base" : None ,
}
question_answering_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 1000 , ** openai_kwargs )
discourse_manage_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 500 , ** openai_kwargs )
utterance_polishing_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 2000 , ** openai_kwargs )
warmstart_outline_gen_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 500 , ** openai_kwargs )
question_asking_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 300 , ** openai_kwargs )
knowledge_base_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 1000 , ** openai_kwargs )
lm_config . set_question_answering_lm ( question_answering_lm )
lm_config . set_discourse_manage_lm ( discourse_manage_lm )
lm_config . set_utterance_polishing_lm ( utterance_polishing_lm )
lm_config . set_warmstart_outline_gen_lm ( warmstart_outline_gen_lm )
lm_config . set_question_asking_lm ( question_asking_lm )
lm_config . set_knowledge_base_lm ( knowledge_base_lm )
# Check out the Co-STORM's RunnerArguments class for more configurations.
topic = input ( 'Topic: ' )
runner_argument = RunnerArgument ( topic = topic , ...)
logging_wrapper = LoggingWrapper ( lm_config )
bing_rm = BingSearch ( bing_search_api_key = os . environ . get ( "BING_SEARCH_API_KEY" ),
k = runner_argument . retrieve_top_k )
costorm_runner = CoStormRunner ( lm_config = lm_config ,
runner_argument = runner_argument ,
logging_wrapper = logging_wrapper ,
rm = bing_rm ) CoStormRunner 인스턴스는 warmstart() 및 step(...) 메서드를 사용하여 호출할 수 있습니다.
# Warm start the system to build shared conceptual space between Co-STORM and users
costorm_runner . warm_start ()
# Step through the collaborative discourse
# Run either of the code snippets below in any order, as many times as you'd like
# To observe the conversation:
conv_turn = costorm_runner . step ()
# To inject your utterance to actively steer the conversation:
costorm_runner . step ( user_utterance = "YOUR UTTERANCE HERE" )
# Generate report based on the collaborative discourse
costorm_runner . knowledge_base . reorganize ()
article = costorm_runner . generate_report ()
print ( article )다양한 구성으로 STORM 및 Co-STORM을 실행하기 위한 빠른 시작으로 예제 폴더에 스크립트를 제공합니다.
API 키를 설정하려면 secrets.toml 사용하는 것이 좋습니다. 루트 디렉터리 아래에 secrets.toml 파일을 만들고 다음 콘텐츠를 추가합니다.
# Set up OpenAI API key.
OPENAI_API_KEY= " your_openai_api_key "
# If you are using the API service provided by OpenAI, include the following line:
OPENAI_API_TYPE= " openai "
# If you are using the API service provided by Microsoft Azure, include the following lines:
OPENAI_API_TYPE= " azure "
AZURE_API_BASE= " your_azure_api_base_url "
AZURE_API_VERSION= " your_azure_api_version "
# Set up You.com search API key.
YDC_API_KEY= " your_youcom_api_key " 기본 구성으로 gpt 제품군 모델로 STORM을 실행하려면 다음을 수행하십시오.
다음 명령을 실행하십시오.
python examples/storm_examples/run_storm_wiki_gpt.py
--output-dir $OUTPUT_DIR
--retriever you
--do-research
--do-generate-outline
--do-generate-article
--do-polish-article선호하는 언어 모델을 사용하거나 자신의 코퍼스를 기반으로 STORM을 실행하려면: examples/storm_examples/README.md를 확인하세요.
기본 구성으로 gpt 제품군 모델로 Co-STORM을 실행하려면,
secrets.toml 에 BING_SEARCH_API_KEY="xxx" 및 ENCODER_API_TYPE="xxx" 를 추가하세요.python examples/costorm_examples/run_costorm_gpt.py
--output-dir $OUTPUT_DIR
--retriever bing소스 코드를 설치한 경우 자신의 사용 사례에 따라 STORM을 사용자 정의할 수 있습니다. STORM 엔진은 4개의 모듈로 구성됩니다.
각 모듈의 인터페이스는 knowledge_storm/interface.py 에 정의되어 있으며 해당 구현은 knowledge_storm/storm_wiki/modules/* 에 인스턴스화되어 있습니다. 이러한 모듈은 특정 요구 사항에 따라 사용자 정의할 수 있습니다(예: 전체 단락 대신 글머리 기호 형식으로 섹션 생성).
소스 코드를 설치했다면 자신의 사용 사례에 따라 Co-STORM을 맞춤 설정할 수 있습니다.
knowledge_storm/interface.py 에 정의되어 있으며 해당 구현은 knowledge_storm/collaborative_storm/modules/co_storm_agents.py 에서 인스턴스화됩니다. 다양한 LLM 에이전트 정책을 사용자 정의할 수 있습니다.knowledge_storm/collaborative_storm/engine.py 의 DiscourseManager 통해 턴 정책 관리 구현 예시를 제공합니다. 사용자 정의하고 더욱 개선할 수 있습니다. 자동 지식 큐레이션 및 복잡한 정보 검색에 대한 연구를 촉진하기 위해 우리 프로젝트는 다음 데이터세트를 출시합니다.
FreshWiki 데이터 세트는 2022년 2월부터 2023년 9월까지 가장 많이 편집된 페이지에 초점을 맞춘 100개의 고품질 Wikipedia 기사 모음입니다. 자세한 내용은 STORM 논문의 섹션 2.1을 참조하세요.
Huggingface에서 데이터 세트를 직접 다운로드할 수 있습니다. 데이터 오염 문제를 완화하기 위해 향후 반복될 수 있는 데이터 구축 파이프라인의 소스 코드를 보관합니다.
야생에서 복잡한 정보 검색 작업에 대한 사용자의 관심을 연구하기 위해 웹 조사 미리 보기에서 수집된 데이터를 활용하여 WildSeek 데이터 세트를 만들었습니다. 주제의 다양성과 데이터의 품질을 보장하기 위해 데이터를 다운샘플링했습니다. 각 데이터 포인트는 주제와 주제에 대한 심층 검색을 수행하기 위한 사용자 목표로 구성된 쌍입니다. 자세한 내용은 Co-STORM 논문의 섹션 2.2 및 부록 A를 참조하세요.
WildSeek 데이터 세트는 여기에서 사용할 수 있습니다.
STORM 종이 실험의 경우 여기에서 NAACL-2024-code-backup 분기로 전환하세요.
Co-STORM 논문 실험의 경우 EMNLP-2024-code-backup 분기로 전환하세요(현재 자리 표시자는 곧 업데이트될 예정입니다).
우리 팀은 다음과 같이 적극적으로 노력하고 있습니다.
질문이나 제안 사항이 있는 경우 언제든지 이슈를 열거나 요청을 가져오시기 바랍니다. 시스템과 코드베이스를 개선하기 위한 기여를 환영합니다!
담당자: Yijia Shao 및 Yucheng Jiang
훌륭한 오픈 소스 콘텐츠를 제공해 주신 Wikipedia에 감사드립니다. FreshWiki 데이터 세트는 Creative Commons Attribution-ShareAlike(CC BY-SA) 라이센스에 따라 라이센스가 부여된 Wikipedia에서 제공됩니다.
이 프로젝트의 로고를 디자인한 Michelle Lam과 UI 개발을 주도한 Dekun Ma에게 매우 감사드립니다.
작업에 이 코드나 그 일부를 사용하는 경우 우리 논문을 인용해 주세요.
@misc { jiang2024unknownunknowns ,
title = { Into the Unknown Unknowns: Engaged Human Learning through Participation in Language Model Agent Conversations } ,
author = { Yucheng Jiang and Yijia Shao and Dekun Ma and Sina J. Semnani and Monica S. Lam } ,
year = { 2024 } ,
eprint = { 2408.15232 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL } ,
url = { https://arxiv.org/abs/2408.15232 } ,
}
@inproceedings { shao2024assisting ,
title = { {Assisting in Writing Wikipedia-like Articles From Scratch with Large Language Models} } ,
author = { Yijia Shao and Yucheng Jiang and Theodore A. Kanell and Peter Xu and Omar Khattab and Monica S. Lam } ,
year = { 2024 } ,
booktitle = { Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) }
}

