bulk
1.0.0
Bulk는 일부 대량 라벨을 적용하는 빠른 개발자 도구입니다. 2D 임베딩이 포함된 준비된 데이터 세트가 주어지면 정확성은 떨어지더라도 일부 주석을 빠르게 추가할 수 있는 인터페이스를 생성할 수 있습니다.
python -m pip install --upgrade pip
python -m pip install bulk
벌크의 미래는 노트북에서 도움이 될 수 있는 위젯을 제공하는 것입니다. 현재 BaseTextExplorer 는 지원되는 기본 위젯입니다. 일부 전처리된 데이터가 주어지면 탐색기를 사용하여 텍스트 임베딩의 2D UMAP을 살펴볼 수 있습니다.
import pandas as pd
from umap import UMAP
from sklearn . pipeline import make_pipeline
# pip install "embetter[text]"
from embetter . text import SentenceEncoder
# Build a sentence encoder pipeline with UMAP at the end.
enc = SentenceEncoder ( 'all-MiniLM-L6-v2' )
umap = UMAP ()
text_emb_pipeline = make_pipeline (
enc , umap
)
# Load sentences
sentences = list ( pd . read_csv ( "tests/data/text.csv" )[ 'text' ])
# Calculate embeddings
X_tfm = text_emb_pipeline . fit_transform ( sentences )
# Write to disk. Note! Text column must be named "text"
df = pd . DataFrame ({ "text" : sentences })
df [ 'x' ] = X_tfm [:, 0 ]
df [ 'y' ] = X_tfm [:, 1 ]위젯을 사용하려면 다음을 실행하면 됩니다.
from bulk . widgets import BaseTextExplorer
widget = BaseTextExplorer ( df )
widget . show ()이를 통해 데이터에 나타나는 클러스터를 빠르게 탐색할 수 있습니다. 마우스 커서를 누르고 있으면 선택 모드로 들어갈 수 있으며, 항목을 선택하면 오른쪽에 임의의 하위 집합이 나타나는 것을 볼 수 있습니다. 재샘플 버튼을 클릭하면 선택 항목을 다시 샘플링할 수 있습니다.
선택하면 올바른 업데이트에서 위젯을 볼 수 있지만 Python 속성에서 데이터를 가져올 수도 있습니다.
widget . selected_idx
widget . selected_texts
widget . selected_dataframe이러한 클러스터를 탐색할 수 있다는 것은 깔끔하지만, 사용할 수 있는 도구가 더 있으면 모든 것을 더 쉽게 탐색할 수 있을 것 같습니다. 특히, 우리는 임베디드 공간에서 쿼리를 사용할 수 있도록 인코더를 갖고 싶습니다. 아래 UI를 사용하면 텍스트 프롬프트로 색상을 업데이트하여 훨씬 더 대화식으로 탐색할 수 있습니다.
from embetter . text import SentenceEncoder
enc = SentenceEncoder ( 'all-MiniLM-L6-v2' )
# Pay attention here! The rows in df needs to align with the rows in X!
widget = BaseTextExplorer ( df , X = X , encoder = enc )
widget . show ()ipywidget 및 anywidget과 같은 도구 덕분에 우리는 노트북을 데이터 요구 사항에 맞는 장소로 유지하는 몇 가지 도구 구축을 실제로 시작할 수 있습니다. 적절한 위젯이 주어지면 Jupyter 노트북보다 노트북을 능가할 수는 없습니다!
이 프로젝트의 주요 관심은 데이터 품질을 위한 도구를 개발하는 것입니다. 데이터 포인트를 대량으로 선택할 수 있다는 것은 시작하기에 좋은 곳인 것 같습니다. 먼저 주석을 추가할 흥미로운 하위 집합을 찾을 수도 있고, 하나여야 하는 두 개의 서로 다른 클러스터를 보고 놀랄 수도 있습니다. 그 모든 좋은 일들이 노트북에서 일어날 수 있습니다!
Bulk에는 Bokeh를 사용하여 임베딩의 UMAP 표현을 기반으로 주석 인터페이스를 제공하는 작은 웹 앱도 함께 제공됩니다. 텍스트에 대한 인터페이스를 제공합니다. 이 인터페이스는 이 프로젝트의 원래 인터페이스/기능이었습니다.
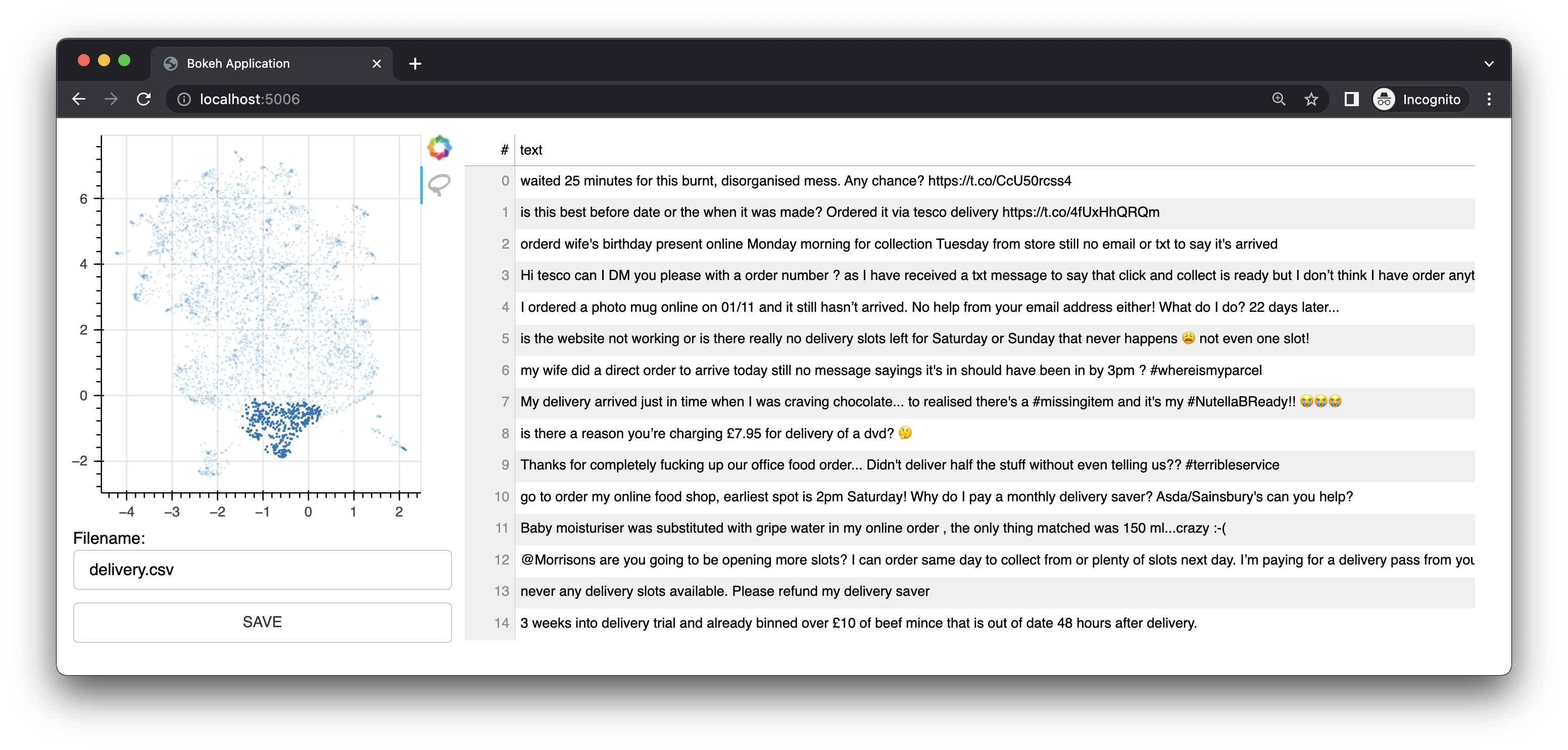
또한 이미지 인터페이스도 제공됩니다.
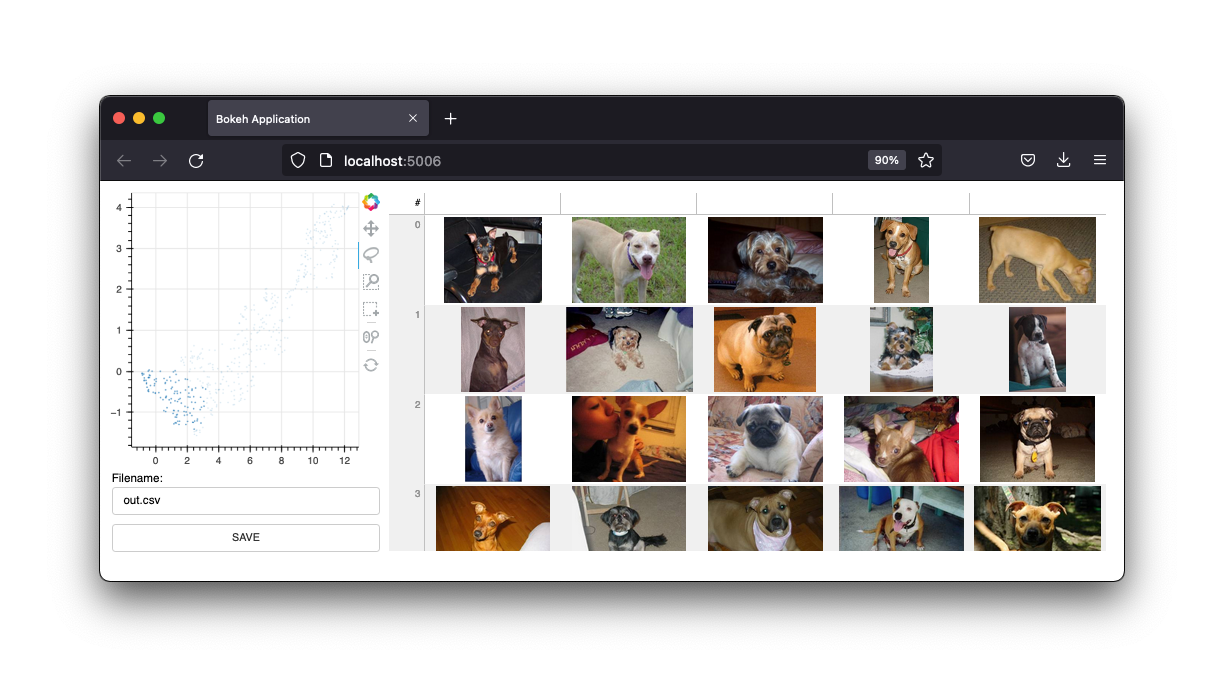
이러한 인터페이스는 계속 유지되지만 이 프로젝트의 미래는 Jupyter 노트북의 위젯이 될 것입니다. 그러나 웹앱은 여전히 유용합니다.
더 자세히 알고 싶다면 YouTube에서 텍스트용 동영상을, 컴퓨터 비전용 YouTube 동영상을 감상해 보세요.
텍스트를 대량으로 사용하려면 먼저 csv 파일을 준비해야 합니다.
메모
아래 예제에서는 embetter를 사용하여 임베딩을 생성하고 Umap을 사용하여 차원을 줄입니다. 하지만 원하는 텍스트 삽입 도구를 자유롭게 사용할 수 있습니다. 이러한 도구는 별도로 설치해야 합니다. Embetter는 내부적으로 문장 변환기를 사용합니다.
import pandas as pd
from umap import UMAP
from sklearn . pipeline import make_pipeline
# pip install "embetter[text]"
from embetter . text import SentenceEncoder
# Build a sentence encoder pipeline with UMAP at the end.
text_emb_pipeline = make_pipeline (
SentenceEncoder ( 'all-MiniLM-L6-v2' ),
UMAP ()
)
# Load sentences
sentences = list ( pd . read_csv ( "original.csv" )[ 'sentences' ])
# Calculate embeddings
X_tfm = text_emb_pipeline . fit_transform ( sentences )
# Write to disk. Note! Text column must be named "text"
df = pd . DataFrame ({ "text" : sentences })
df [ 'x' ] = X_tfm [:, 0 ]
df [ 'y' ] = X_tfm [:, 1 ]
df . to_csv ( "ready.csv" , index = False ) 이제 이 ready.csv 파일을 사용하여 일부 대량 라벨링을 적용할 수 있습니다.
python -m bulk text ready.csv
가지고 놀 수 있는 예제 파일을 찾고 있다면 이 저장소에서 데모 .csv 파일을 다운로드할 수 있습니다. 이 데이터 세트에는 Kaggle에 있는 데이터 세트의 하위 세트가 포함되어 있습니다. 여기에서 원본을 찾을 수 있습니다.
"color"라는 CSV 파일에 추가 열을 전달할 수도 있습니다. 그런 다음 이 열은 인터페이스의 포인트 색상을 지정하는 데 사용됩니다.
--keywords 명령줄 앱에 전달하여 특정 키워드가 포함된 요소를 강조 표시할 수도 있습니다.
python -m bulk text ready.csv --keywords "deliver,card,website,compliment"
아래 예에서는 embetter 라이브러리를 사용하여 이미지 대량 라벨링을 위한 데이터세트를 생성합니다.
메모
아래 예제에서는 embetter를 사용하여 임베딩을 생성하고 Umap을 사용하여 차원을 줄입니다. 하지만 원하는 텍스트 삽입 도구를 자유롭게 사용할 수 있습니다. 이러한 도구는 별도로 설치해야 합니다. Embetter는 내부적으로 TIMM을 사용합니다.
import pathlib
import pandas as pd
from sklearn . pipeline import make_pipeline
from umap import UMAP
from sklearn . preprocessing import MinMaxScaler
# pip install "embetter[vision]"
from embetter . grab import ColumnGrabber
from embetter . vision import ImageLoader , TimmEncoder
# Build image encoding pipeline
image_emb_pipeline = make_pipeline (
ColumnGrabber ( "path" ),
ImageLoader ( convert = "RGB" ),
TimmEncoder ( 'xception' ),
UMAP (),
MinMaxScaler ()
)
# Make dataframe with image paths
img_paths = list ( pathlib . Path ( "downloads" , "pets" ). glob ( "*" ))
dataf = pd . DataFrame ({
"path" : [ str ( p ) for p in img_paths ]
})
# Make csv file with Umap'ed model layer
# Note! Bulk assumes the image path column to be called "path"!
X = image_emb_pipeline . fit_transform ( dataf )
dataf [ 'x' ] = X [:, 0 ]
dataf [ 'y' ] = X [:, 1 ]
dataf . to_csv ( "ready.csv" , index = False )그러면 다음을 통해 대량으로 로드할 수 있는 csv 파일이 생성됩니다.
python -m bulk image ready.csv
이미지에 대한 썸네일 세트를 생성할 수도 있습니다. 이는 대규모 데이터 세트로 작업하는 경우 유용할 수 있습니다.
python -m bulk util resize ready.csv ready2.csv temp
이렇게 하면 크기가 조정된 모든 이미지가 포함된 temp 라는 폴더가 생성됩니다. 그런 다음 이 폴더를 --thumbnail-path 인수로 사용할 수 있습니다.
python -m bulk image ready2.csv --thumbnail-path temp
대량으로 사용할 데이터 세트를 다운로드할 수도 있습니다. 더 많은 정보를 원하시면:
python -m bulk download --help
인터페이스는 매우 빠르게 레이블을 지정하는 데 도움이 될 수 있지만 레이블 자체에는 상당히 노이즈가 많을 수 있습니다. 이 도구의 의도된 사용 사례는 나중에 prodi.gy에서 사용할 흥미로운 하위 집합을 준비하는 것입니다.


