MedCalc Bench
1.0.0
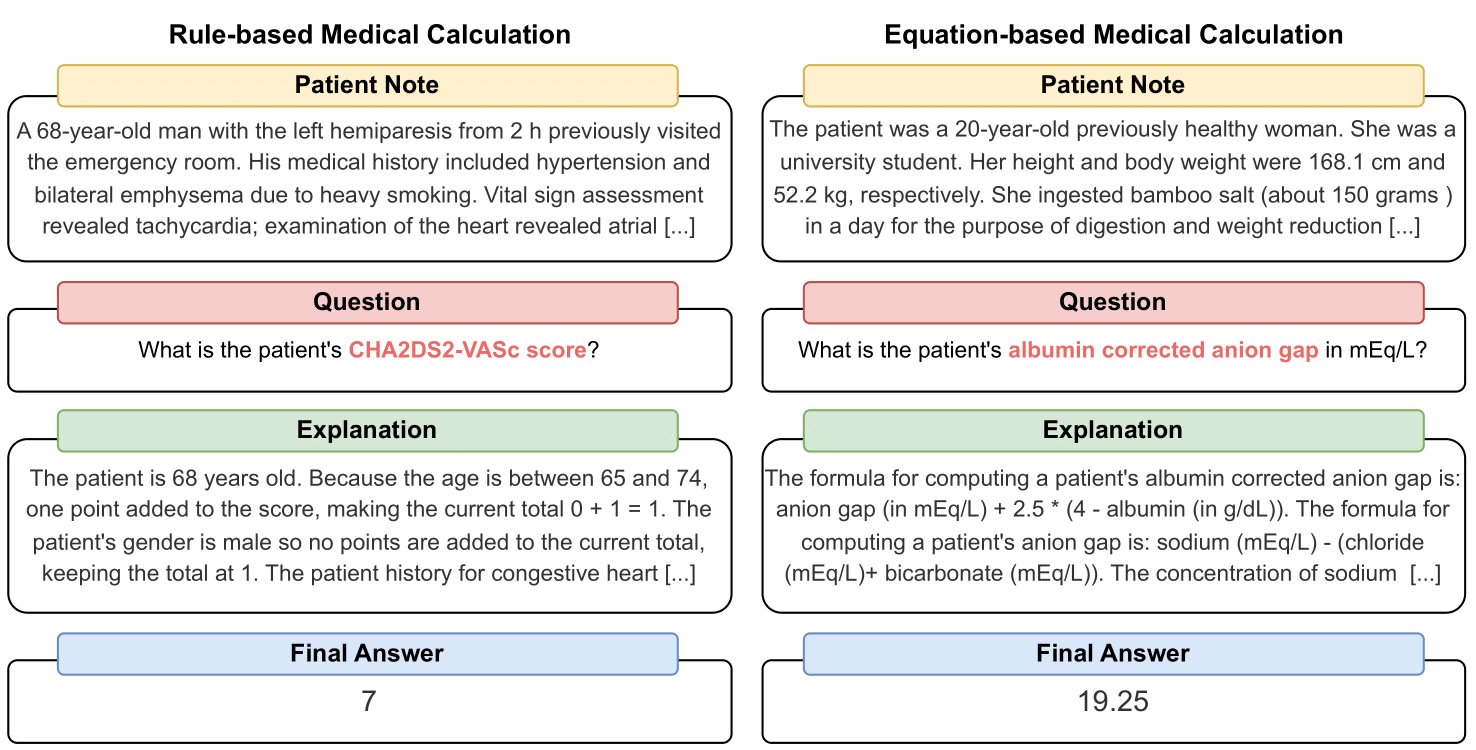
MedCalc-Bench는 LLM의 임상 계산기 역할을 벤치마킹하는 데 사용되는 최초의 의료 계산 데이터세트입니다. 데이터세트의 각 인스턴스는 환자 메모, 특정 임상 값을 계산하기 위한 질문, 최종 답변 값, 최종 답변을 얻은 방법을 설명하는 단계별 솔루션으로 구성됩니다. 우리의 데이터 세트는 규칙 기반 계산 또는 방정식 기반 계산인 55가지의 다양한 계산 작업을 다룹니다. 이 데이터 세트에는 10,053개 인스턴스의 훈련 데이터 세트와 1,047개 인스턴스의 테스트 데이터 세트가 포함되어 있습니다.
전체적으로 우리는 우리의 데이터세트와 벤치마크가 의료 환경에서 LLM의 계산 추론 기술을 향상시키는 데 도움이 되기를 바랍니다.
사전 인쇄본은 https://arxiv.org/abs/2406.12036에서 확인할 수 있습니다.
MedCalc-Bench 평가 데이터 세트에 대한 CSV를 다운로드하려면 이 저장소의 dataset 폴더 내에 test_data.csv 파일을 다운로드하세요. https://huggingface.co/datasets/ncbi/MedCalc-Bench의 HuggingFace에서 분할된 테스트 세트를 다운로드할 수도 있습니다.
1,047개의 평가 인스턴스 외에도 우리는 오픈 소스 LLM을 미세 조정하는 데 사용할 수 있는 10,053개의 인스턴스로 구성된 교육 데이터 세트도 제공합니다(부록의 섹션 C 참조). 훈련 데이터는 dataset/train_data.csv.zip 파일에서 찾을 수 있으며 압축을 풀어 train_data.csv 얻을 수 있습니다. 이 교육 데이터 세트는 HuggingFace 링크의 열차 분할에서도 찾을 수 있습니다.
데이터 세트의 각 인스턴스에는 다음 정보가 포함됩니다.
이 프로젝트에 필요한 모든 패키지를 설치하려면 다음 명령을 실행하십시오: conda env create -f environment.yml . 이 명령은 medcalc-bench conda 환경을 생성합니다. OpenAI 모델을 실행하려면 이 conda 환경에서 OpenAI 키를 제공해야 합니다. medcalc-bench 환경에서 다음 명령을 실행하여 이를 수행할 수 있습니다. export OPENAI_API_KEY = YOUR_API_KEY , 여기서 YOUR_API_KEY는 OpenAI API 키입니다. 또한 다음 명령을 export HUGGINGFACE_TOKEN=your_hugging_face_token 하여 이 환경에서 HuggingFace 토큰을 제공해야 합니다 your_hugging_face_token
논문에서 표 2를 재현하려면 먼저 evaluation 폴더에 cd 넣으세요. 그런 다음 python run.py --model <model_name> and --prompt <prompt_style> 명령을 실행하세요.
--model 옵션은 다음과 같습니다.
--prompt 옵션은 다음과 같습니다.
여기에서 모든 질문의 상태를 출력하는 하나의 jsonl 파일을 얻게 됩니다. run.py 실행하면 결과가 <model>_<prompt>.jsonl 이라는 파일에 저장됩니다. 이 파일은 outputs 폴더에서 찾을 수 있습니다.
jsonl의 각 인스턴스에는 다음과 같은 메타데이터가 연결되어 있습니다.
{
"Row Number": Row index of the item,
"Calculator Name": Name of calculation task,
"Calculator ID": ID of the calculator,
"Category": type of calculation (risk, severity, diagnosis for rule-based calculators and lab, risk, physical, date, dosage for equation-based calculators),
"Note ID": ID of the note taken directly from MedCalc-Bench,
"Patient Note": Paragraph which is the patient note taken directly from MedCalc-Bench,
"Question": Question asking for a specific medical value to be computed,
"LLM Answer": Final Answer Value from LLM,
"LLM Explanation": Step-by-Step explanation by LLM,
"Ground Truth Answer": Ground truth answer value,
"Ground Truth Explanation": Step-by-step ground truth explanation,
"Result": "Correct" or "Incorrect"
}
또한 results_<model>_<prompt_style>.json 이라는 제목의 json에서 각 하위 범주에 대한 평균 정확도 및 표준 편차 백분율을 제공합니다. 전체 1,047개 인스턴스의 누적 정확도와 표준 편차는 JSON의 '전체' 키에서 확인할 수 있습니다. 이 파일은 results 폴더에서 찾을 수 있습니다.
본 논문의 표 2에 대한 결과 외에도 우리는 LLM이 산술을 수행하도록 하는 대신 산술을 수행하는 코드를 작성하도록 LLM에 요청했습니다. 이에 대한 결과는 부록 D에서 확인할 수 있습니다. 제한된 컴퓨팅으로 인해 GPT-3.5 및 GPT-4에 대한 결과만 실행했습니다. 프롬프트를 검사하고 이 설정에서 실행하려면 evaluation 폴더에 있는 generate_code_prompt.py 파일을 검사하십시오.
이 코드를 실행하려면 evaluations 폴더로 cd 입력하고 python generate_code_prompt.py --gpt <gpt_model> 실행하세요. <gpt_model> 의 옵션은 GPT-4를 실행하는 경우 4 , GPT-3.5-turbo-16k를 실행하는 경우 35 입니다. 그러면 결과는 outputs 폴더의 code_exec_{model_name}.jsonl 이라는 jsonl 파일에 저장됩니다. 이 경우 GPT-4를 사용하여 실행하도록 선택한 경우 model_name gpt_4 가 됩니다. 그렇지 않고 GPT-3.5-turbo로 실행하도록 선택한 경우 model_name gpt_35_16k 가 됩니다.
코드 해석기 결과에 대한 jsonl 파일의 각 인스턴스에 대한 메타데이터는 위 섹션에 제공된 인스턴스 정보와 동일합니다. 유일한 차이점은 사용자와 보조자 간의 LLM 채팅 기록을 저장하고 "LLM 설명" 키 대신 "LLM 채팅 기록" 키를 갖는다는 것입니다. 또한 하위 카테고리와 전반적인 정확도는 results_<model_name>_code_augmented.json 이라는 JSON 파일에 저장됩니다. 이 JSON은 results 폴더에 있습니다.
이 연구는 국립의학도서관 NIH 교내 연구 프로그램의 지원을 받았습니다. 또한 Soren Dunn의 기여는 국립과학재단(OAC 전화번호:2005572)과 일리노이주에서 지원하는 Delta 고급 컴퓨팅 및 데이터 리소스를 사용하여 수행되었습니다. Delta는 일리노이 대학교 어바나-샴페인 캠퍼스(UIUC)와 국립 슈퍼컴퓨팅 애플리케이션 센터(NCSA)의 공동 노력입니다.
MedCalc-Bench에서 환자 메모를 관리하기 위해 우리는 PubMed Central에 게시된 사례 보고서 기사와 임상의가 생성한 익명의 환자 비네트에서 공개적으로 사용 가능한 환자 메모만 사용합니다. 따라서 본 연구에서는 식별 가능한 개인 건강 정보가 공개되지 않습니다. MedCalc-Bench는 LLM의 의료 계산 기능을 평가하도록 설계되었지만, 데이터 세트는 임상 전문가의 검토 및 감독 없이 직접적인 진단 사용이나 의학적 의사 결정을 위한 것이 아니라는 점에 유의해야 합니다. 개인은 우리의 연구만을 토대로 자신의 건강 행동을 바꿔서는 안됩니다.
1절에 설명된 대로 의료용 계산기는 임상 환경에서 일반적으로 사용됩니다. 도메인별 애플리케이션에 LLM을 사용하는 것에 대한 관심이 급속히 증가함에 따라 의료 전문가는 ChatGPT와 같은 챗봇이 의료 계산 작업을 수행하도록 직접 유도할 수 있습니다. 그러나 이러한 작업에서 LLM의 기능은 현재 알려져 있지 않습니다. 의료는 위험도가 높은 영역이고 잘못된 의료 계산은 오진, 부적절한 치료 계획, 환자에 대한 잠재적 피해 등 심각한 결과를 초래할 수 있으므로 의료 계산에서 LLM의 성능을 철저하게 평가하는 것이 중요합니다. 놀랍게도 MedCalc-Bench 데이터 세트의 평가 결과는 연구된 모든 LLM이 의료 계산 작업에서 어려움을 겪고 있음을 보여줍니다. 가장 유능한 모델인 GPT-4는 일회성 학습과 일련의 사고방식 프롬프트로 정확도가 50%에 불과합니다. 따라서 우리 연구에 따르면 현재 LLM은 아직 의료 계산에 사용할 준비가 되지 않은 것으로 나타났습니다. MedCalc-Bench의 높은 점수가 의료 계산 작업의 우수성을 보장하지는 않지만, 이 데이터 세트에서 실패한다는 것은 모델이 그러한 목적으로 전혀 고려되어서는 안 된다는 것을 의미합니다. 즉, 우리는 MedCalc-Bench를 통과하는 것이 의료계산에 사용되는 모델의 필요조건(충분조건은 아님)이 되어야 한다고 믿습니다.
이 데이터 세트가 변경되는 경우(예: 새 메모 또는 계산기 추가) README 지침, test_set.csv 및 train_set.csv를 업데이트합니다. 우리는 이러한 데이터 세트의 이전 버전을 archive/ 폴더에 계속 보관할 것입니다. HuggingFace에 대한 학습 및 테스트 세트도 업데이트할 예정입니다.
이 도구는 NCBI/NLM의 전산 생물학 부서에서 수행된 연구 결과를 보여줍니다. 본 웹사이트에서 생성된 정보는 임상 전문가의 검토 및 감독 없이 직접적인 진단 용도나 의학적 의사 결정을 위한 것이 아닙니다. 개인은 이 웹사이트에 제공된 정보만을 토대로 자신의 건강 행동을 바꿔서는 안 됩니다. NIH는 이 도구에서 생성된 정보의 유효성이나 유용성을 독립적으로 확인하지 않습니다. 이 웹사이트에 제공된 정보에 대해 질문이 있는 경우 의료 전문가에게 문의하시기 바랍니다. NCBI의 고지 사항 정책에 대한 자세한 내용을 확인할 수 있습니다.
계산기에 따라 우리의 데이터 세트는 Python으로 구현된 템플릿 기반 함수로 설계되었거나 임상의가 직접 작성했거나 데이터 세트인 Open-Patients에서 가져온 노트로 구성됩니다.
Open-Patients는 세 가지 소스에서 수집된 180,000개의 환자 메모로 구성된 집계된 데이터세트입니다. 우리는 세 가지 소스 모두의 데이터 세트를 사용할 권한이 있습니다. 첫 번째 소스는 MIT 라이센스에 따라 공개되는 MedQA의 USMLE 질문입니다. 우리 데이터 세트의 두 번째 소스는 대중에게 공개되는 정부 소유 데이터 세트이기 때문에 재배포가 가능한 Trec 임상 결정 지원 및 Trec 임상 시험입니다. 마지막으로 PMC-Patients는 CC-BY-SA 4.0 라이선스에 따라 출시되므로 Open-Patients 및 MedCalc-Bench에 PMC-Patients를 통합할 수 있는 권한이 있지만 데이터 세트는 동일한 라이선스에 따라 출시되어야 합니다. 따라서 우리의 노트 소스인 Open-Patients와 여기에서 선별된 데이터 세트인 MedCalc-Bench는 모두 CC-BY-SA 4.0 라이선스에 따라 공개됩니다.
라이선스 규칙의 정당성에 따라 Open-Patients와 MedCalc-Bench 모두 CC-BY-SA 4.0 라이선스를 준수하지만, 권리 침해 시 모든 책임은 본 논문의 저자에게 있습니다.
@misc { khandekar2024medcalcbench ,
title = { MedCalc-Bench: Evaluating Large Language Models for Medical Calculations } ,
author = { Nikhil Khandekar and Qiao Jin and Guangzhi Xiong and Soren Dunn and Serina S Applebaum and Zain Anwar and Maame Sarfo-Gyamfi and Conrad W Safranek and Abid A Anwar and Andrew Zhang and Aidan Gilson and Maxwell B Singer and Amisha Dave and Andrew Taylor and Aidong Zhang and Qingyu Chen and Zhiyong Lu } ,
year = { 2024 } ,
eprint = { 2406.12036 } ,
archivePrefix = { arXiv } ,
primaryClass = { id='cs.CL' full_name='Computation and Language' is_active=True alt_name='cmp-lg' in_archive='cs' is_general=False description='Covers natural language processing. Roughly includes material in ACM Subject Class I.2.7. Note that work on artificial languages (programming languages, logics, formal systems) that does not explicitly address natural-language issues broadly construed (natural-language processing, computational linguistics, speech, text retrieval, etc.) is not appropriate for this area.' }
}

