ebsynth
1.0.0
ebsynth 는 이미지의 예시별 합성을 위한 다목적 도구입니다. 안내된 텍스처 합성, 예술적 스타일 전송, 콘텐츠 인식 인페인팅 및 초해상도를 포함한 다양한 이미지 합성 작업에 사용할 수 있습니다.
ebsynth 의 초점은 소스 자료의 충실도를 보존하는 것입니다. 다른 최근 접근 방식과 달리 ebsynth 신경망에 의존하지 않습니다. 대신, 비모수적 텍스처 합성 알고리즘의 최첨단 구현을 사용합니다. 패치 기반 특성 덕분에 ebsynth 원본 이미지에 존재하는 모든 미세한 디테일을 보존하는 선명한 결과를 생성합니다.
ebsynth -style <style.png> -guide <source.png> <target.png> -output <output.png>
-style <style.png>
-guide <source.png> <target.png>
-weight <value>
-uniformity <value>
-patchsize <value>
-pyramidlevels <number>
-searchvoteiters <number>
-patchmatchiters <number>
-extrapass3x3
-backend [cpu|cuda]
사전 구축된 Windows 바이너리는 여기(http://jamriska.cz/ebsynth/ebsynth-win64.zip)에서 다운로드할 수 있습니다.
첫 번째 예는 ebsynth 사용하여 기본적인 가이드 텍스처 합성을 수행하는 방법을 보여줍니다. 이 사용 사례는 원본 Image Analogies 논문[1]에서 처음 제안되었으며, 여기서는 'texture-by-numbers'라고 불렀습니다. 분할된 자연 장면의 사진으로 시작합니다(예: 바위는 녹색으로, 하늘은 파란색으로 칠해짐).
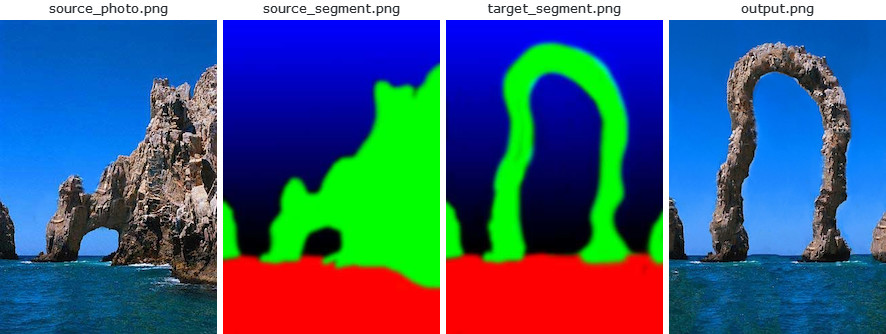
ebsynth -style source_photo.png -guide source_segment.png target_segment.png -output output.png
다음으로, 우리는 손으로 대상 분할을 칠하고, ebsynth 에 이에 일치하는 새로운 '사진'을 생성하도록 요청합니다. 스타일 전송의 언어로 말하면, 우리는 개별 세그먼트를 존중하는 방식으로 소스 사진의 스타일을 대상 세그먼트로 전송하려고 합니다. 분할은 합성을 위한 가이드 역할을 합니다.

이 예에서는 ebsynth 사용하여 비사실적 렌더링을 달성하는 방법을 보여줍니다. 이는 Fišer et al.의 연구를 기반으로 합니다. [7]. 목표는 아티스트처럼 3D 모델을 렌더링하는 것입니다. 특히 우리는 아티스트가 하이라이트, 접촉 그림자, 간접 바운스와 같은 다양한 조명 효과를 전달하는 방식을 포착하고자 합니다. 이를 위해 우리는 조명이 켜진 공을 사용하여 간단한 참조 장면을 설정하고 아티스트가 자신의 스타일로 그리도록 했습니다. 우리는 기성 경로 추적기를 사용하여 별도의 렌더 패스(예: 전체 전역 조명, 직접 확산 구성 요소, 간접 바운스 등)를 생성합니다. 다음으로 대상 3D 모델에 대해 동일한 패스 세트를 렌더링합니다. ebsynth 에 대한 가이드로 사용하십시오.

ebsynth -style source_style.png
-guide source_fullgi.png target_fullgi.png -weight 0.66
-guide source_dirdif.png target_dirdif.png -weight 0.66
-guide source_indirb.png target_indirb.png -weight 0.66
-output output.png
숫자별 텍스처와 비교할 때 여기서 주요 차이점은 이제 여러 안내 채널이 있다는 것입니다. 가이드는 항상 쌍으로 제공됩니다. 소스 가이드가 먼저, 대상 가이드가 두 번째입니다. 더 나은 결과를 위해 스타일과 관련된 가이드의 기여도를 높이고 싶을 수도 있습니다. 위 예에서 스타일의 기본 가중치는 1.0이고 가이드 채널의 가중치는 각각 0.66입니다. 종합하면 총 가이드 무게는 2.0이므로 가이드 대 스타일 비율은 2:1이 됩니다.

이 예는 ebsynth 사용하여 초상화 그림의 스타일을 다른 사람의 사진에 옮기는 방법을 보여줍니다. 이는 Fišer et al.의 연구를 기반으로 합니다. [8]. 목표는 대상 인물의 정체성을 유지하면서 원본 그림의 미세한 뉘앙스를 재현하는 것입니다. 즉, 우리는 합성 후에도 그 사람을 알아볼 수 있기를 원합니다.
StyLit과 달리 이 설정에서는 가이드로 사용할 참조 3D 형상이 없습니다. 그러나 원본 그림과 대상 사진 모두 구조가 잘 정의된 사람의 얼굴이 포함되어 있다는 사실을 활용할 수 있습니다. 우리는 필요한 안내 정보를 추론하기 위해 이 구조를 사용할 것입니다.
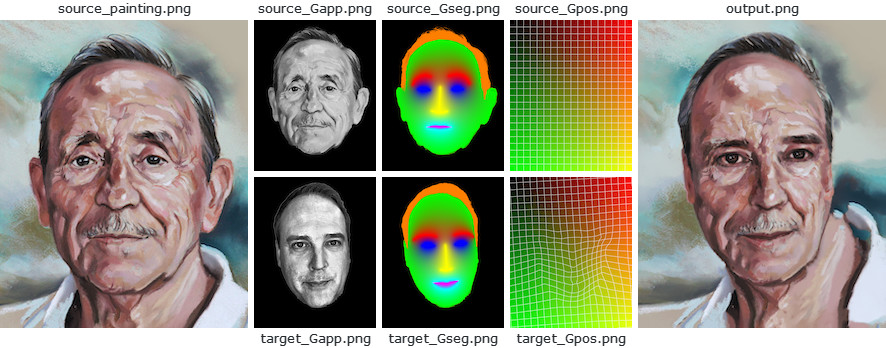
ebsynth -style source_painting.png
-guide source_Gapp.png target_Gapp.png -weight 2.0
-guide source_Gseg.png target_Gseg.png -weight 1.5
-guide source_Gpos.png target_Gpos.png -weight 1.5
-output output.png
구체적으로, 우리는 대상 이미지와 소스 이미지 모두에서 얼굴 랜드마크를 감지하고 이를 사용하여 소프트 분할 가이드 Gseg 와 위치 가이드 Gpos 생성합니다. 이는 본질적으로 모든 대상 픽셀을 소스의 해당 위치에 매핑하는 조밀한 워프 필드입니다. . 사람의 신원을 보존하기 위해 원본 그림의 휘도와 일치하도록 균일화된 대상 사진의 회색조 버전인 모양 가이드 Gapp 사용합니다.
코드는 공개 도메인으로 공개됩니다. 당신은 그것으로 원하는 무엇이든 할 수 있습니다.
그러나 코드는 Adobe에서 특허를 받은 PatchMatch 알고리즘을 구현한다는 점을 알아야 합니다(미국 특허 8,861,869). 다른 기술도 특허를 받을 수 있습니다. 이 코드를 사용하여 특허권자의 권리를 침해하지 않는지 확인하는 것은 귀하의 책임입니다.
이 코드가 연구에 유용하다고 생각되면 다음을 인용해 주세요.
@misc{Jamriska2018,
author = {Jamriska, Ondrej},
title = {Ebsynth: Fast Example-based Image Synthesis and Style Transfer},
year = {2018},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/jamriska/ebsynth}},
}


