ai pizza
1.0.0
하지만 기계가 새로운 것을 창조할 수 있는지, 아니면 이미 알고 있는 것에 국한되는지는 아무도 모릅니다. 하지만 지금도 인공지능은 복잡한 문제를 해결하고 구조화되지 않은 데이터 세트를 분석할 수 있습니다. Dodo에서는 실험을 진행하기로 결정했습니다. 혼란스럽고 주관적이라고 생각되는 것을 정리하고 구조적으로 설명하는 것, 바로 맛입니다. 우리는 대부분의 사람들이 맛있다고 생각하는 재료의 가장 거친 조합을 찾기 위해 인공 지능을 사용하기로 결정했습니다.
MIPT 및 Skoltech의 전문가와 협력하여 우리는 케임브리지 및 기타 미국 여러 대학에서 수행한 성분의 분자 조합에 대한 300,000개 이상의 조리법과 연구 결과를 분석한 인공 지능을 만들었습니다. 이를 바탕으로 AI는 재료 사이의 불명확한 연관성을 찾고 재료를 짝짓는 방법과 각각의 존재가 다른 모든 재료의 조합에 어떻게 영향을 미치는지 이해하는 방법을 학습했습니다.
모든 모델에는 데이터가 필요합니다. 이것이 AI를 훈련시키기 위해 300,000개 이상의 요리 레시피를 수집한 이유입니다.
어려운 부분은 모으는 것이 아니라 같은 형태로 만드는 것이었습니다. 예를 들어, 레시피의 칠리 고추는 "chilli", "chili", "chiles" 또는 심지어 "chillis"로 표시됩니다. 이 모든 것이 "고추"를 의미한다는 것은 우리에게 분명하지만 신경망은 각각을 개별 개체로 간주합니다.
처음에는 100,000개가 넘는 고유 성분이 있었고 데이터를 정리한 후에는 1,000개의 고유 위치만 남았습니다.
데이터 세트를 얻은 후 초기 분석을 수행했습니다. 먼저, 데이터 세트에 얼마나 많은 요리가 있는지 정량적으로 평가했습니다.
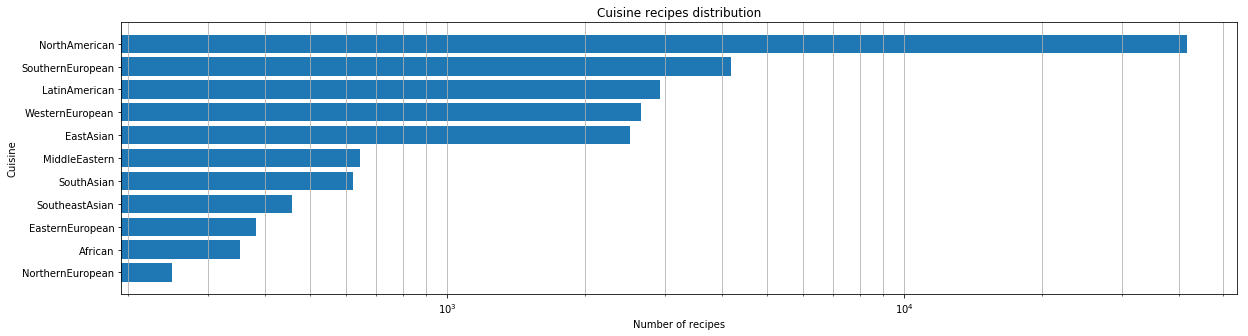
각 요리에 대해 가장 인기 있는 재료를 확인했습니다.
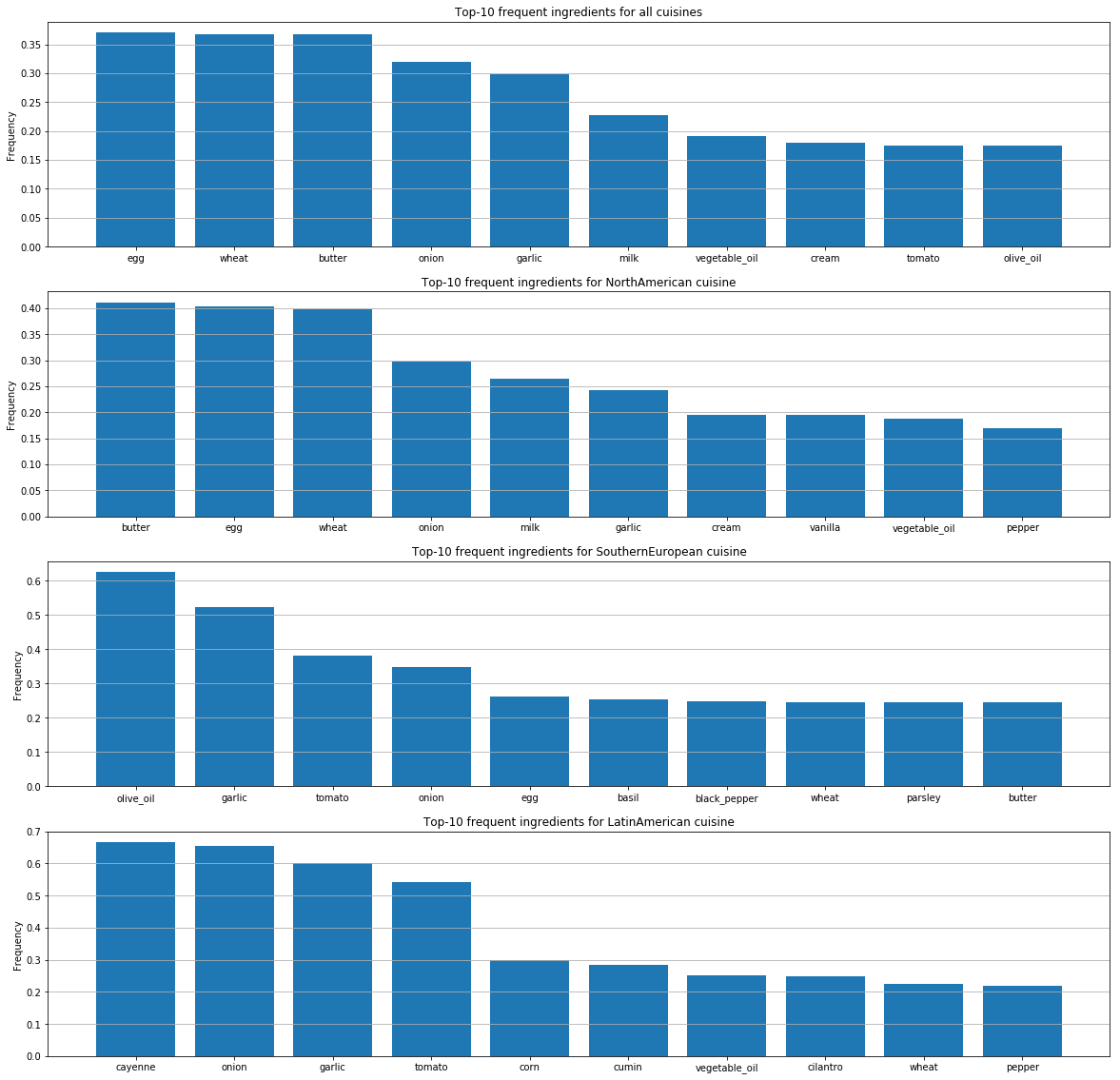
이 그래프는 국가별로 사람들의 취향 선호도의 차이와 재료를 조합하는 방식의 차이를 보여줍니다.
그 후, 우리는 패턴을 발견하기 위해 전 세계의 피자 레시피를 분석하기로 결정했습니다. 이것이 우리가 도출한 결론입니다.
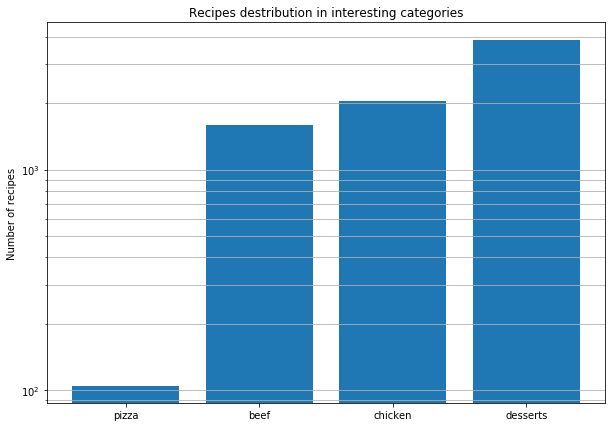
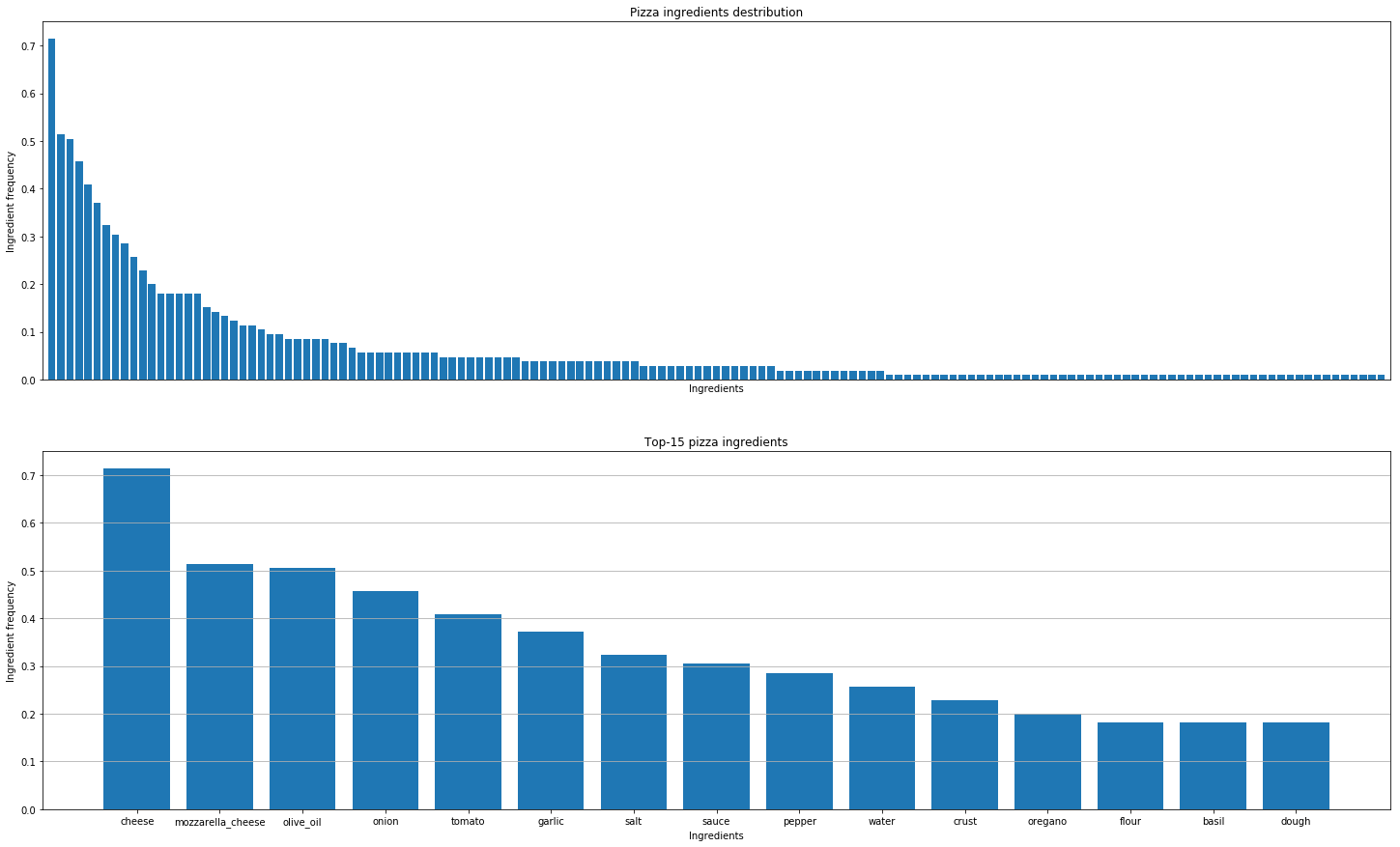
실제 맛의 조합을 찾는 것은 분자 조합을 알아내는 것과 다릅니다. 모든 치즈는 동일한 분자 구성을 가지고 있지만, 그렇다고 해서 가장 가까운 재료에서만 좋은 조합이 나올 수 있다는 의미는 아닙니다.
하지만 성분을 수학으로 환산할 때 꼭 살펴봐야 할 것은 분자적으로 유사한 성분들의 조합이다. 유사한 대상(동일한 치즈)은 우리가 어떻게 설명하든 유사한 상태를 유지해야 하기 때문입니다. 이렇게 하면 객체가 올바르게 설명되었는지 확인할 수 있습니다.
신경망이 이해할 수 있는 형태로 레시피를 제시하기 위해 우리는 문맥에서 단어의 출현을 기반으로 하는 word2vec 알고리즘인 SGNS(Skip-Gram Negative Sampling)를 사용했습니다.
우리는 레시피의 의미 구조가 단순한 텍스트와 다르기 때문에 사전 훈련된 word2vec 모델을 사용하지 않기로 결정했습니다. 그리고 이러한 모델을 사용하면 중요한 정보가 손실될 수 있습니다.
가장 가까운 의미론적 이웃을 살펴봄으로써 word2vec의 결과를 평가할 수 있습니다. 예를 들어, 모델이 치즈에 대해 알고 있는 내용은 다음과 같습니다.
의미론적 모델이 재료의 레시피 상호 관계를 어느 정도 포착할 수 있는지 테스트하기 위해 주제 모델을 적용했습니다. 즉, 우리는 수학적으로 결정된 규칙성에 따라 레시피 데이터 세트를 클러스터로 나누려고 했습니다.
모든 레시피에 대해 우리는 해당 레시피가 결정된 클러스터를 알고 있었습니다. 샘플 레시피의 경우 실제 클러스터와의 연결을 알고 있었습니다. 이를 바탕으로 우리는 이 두 가지 유형의 클러스터 사이의 링크를 찾았습니다.
가장 눈에 띄는 것은 주제 모델에 의해 생성된 주제 0과 1에 포함된 디저트 클래스였습니다. 디저트 외에도 이러한 주제에 대한 다른 클래스가 거의 없으며 이는 디저트가 다른 클래스의 요리와 쉽게 분리된다는 것을 의미합니다. 또한 각 주제에는 해당 주제를 가장 잘 설명하는 클래스가 있습니다. 이는 우리 모델이 "맛"의 불분명한 의미를 수학적으로 성공적으로 정의했음을 의미합니다.
우리는 두 개의 반복 신경망을 사용하여 새로운 레시피를 만들었습니다. 이를 위해 전체 레시피 공간에는 피자 레시피에 해당하는 하위 공간이 있다고 가정했습니다. 그리고 신경망이 새로운 피자 조리법을 만드는 방법을 배우기 위해서는 이 부분 공간을 찾아야 했습니다.
이 작업은 이미지를 저차원 벡터로 표시하는 이미지 자동 인코딩과 유사합니다. 이러한 벡터에는 이미지에 대한 많은 특정 정보가 포함될 수 있습니다.
예를 들어, 이러한 벡터는 사진의 얼굴 인식을 위해 사람의 머리 색깔에 대한 정보를 별도의 셀에 저장할 수 있습니다. 우리는 숨겨진 부분 공간의 고유한 속성 때문에 이 접근 방식을 정확하게 선택했습니다.
피자 부분공간을 식별하기 위해 두 개의 반복 신경망을 통해 피자 레시피를 실행했습니다. 첫 번째는 피자 레시피를 수신하고 그 표현이 잠재 벡터임을 발견했습니다. 두 번째는 첫 번째 신경망으로부터 잠재 벡터를 수신하고 이를 기반으로 레시피를 생성했습니다. 첫 번째 신경망의 입력과 두 번째 신경망의 출력 레시피가 일치해야 합니다.
이러한 방식으로 두 개의 신경망은 잠재 벡터의 레시피를 올바르게 변환하는 방법을 학습했습니다. 그리고 이를 바탕으로 피자 레시피의 전체 범위에 해당하는 숨겨진 부분 공간을 찾을 수 있었습니다.
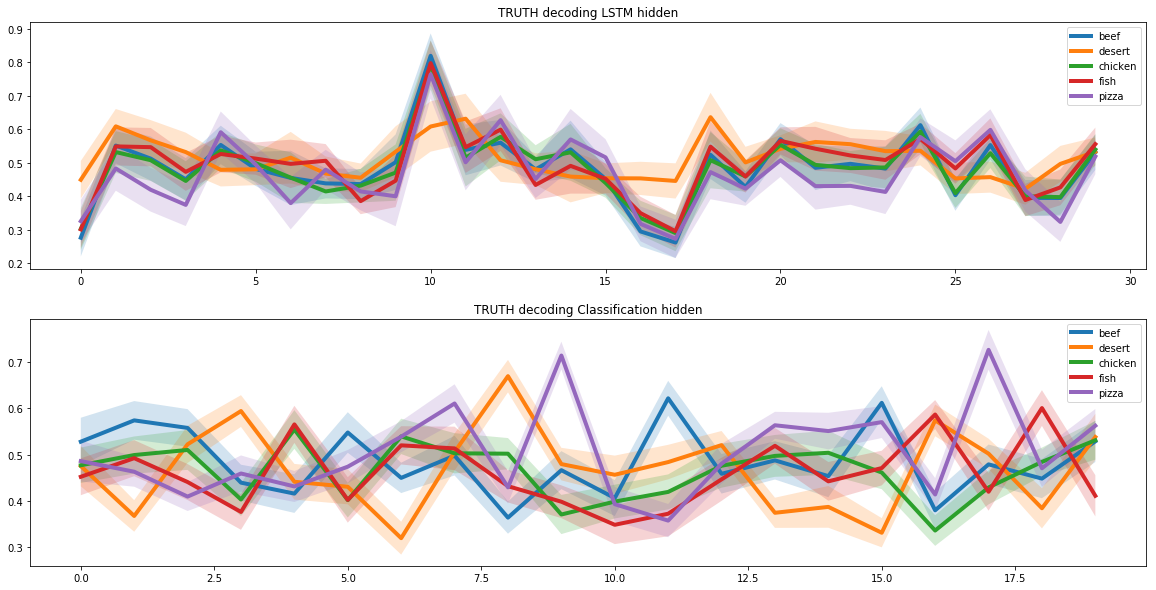
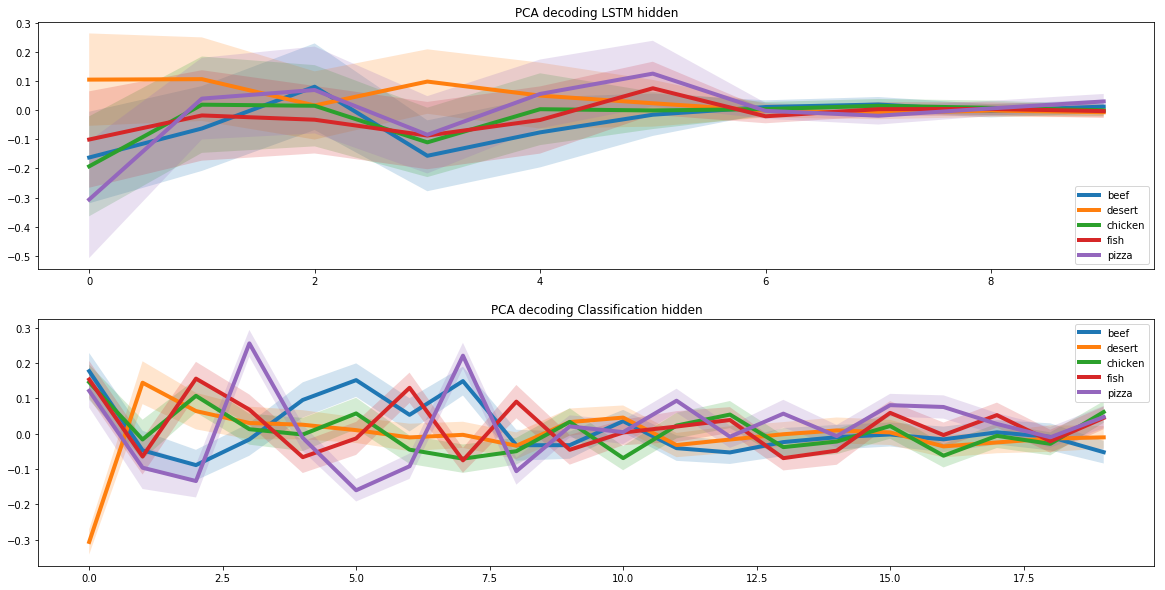
피자 레시피를 만드는 문제를 해결했을 때 모델에 분자 조합 기준을 추가해야 했습니다. 이를 위해 우리는 케임브리지와 미국 여러 대학의 과학자들의 공동 연구 결과를 사용했습니다.
이 연구에서는 가장 일반적인 분자 쌍을 가진 성분이 최상의 조합을 형성한다는 사실을 발견했습니다. 따라서 레시피를 만들 때 신경망은 분자 구조가 비슷한 성분을 선호했습니다.
그 결과, 우리의 신경망은 피자 요리법을 만드는 법을 배웠습니다. 계수를 조정함으로써 신경망은 마가리타나 페퍼로니와 같은 고전적인 요리법과 특이한 요리법을 모두 생성할 수 있으며, 그 중 하나가 오픈소스 피자의 핵심입니다.
| 아니요 | 레시피 |
|---|---|
| 1 | 시금치, 치즈, 토마토, 블랙 올리브, 올리브, 마늘, 후추, 바질, 감귤류, 멜론, 새싹, 버터밀크, 레몬, 베이스, 너트, 루타바가 |
| 2 | 양파, 토마토, 올리브, 후추, 빵, 반죽 |
| 3 | 치킨, 양파, 블랙올리브, 치즈, 소스, 토마토, 올리브오일, 모짜렐라치즈 |
| 4 | 토마토, 버터, 크림치즈, 페퍼, 올리브오일, 치즈, 블랙페퍼, 모짜렐라_치즈 |
오픈 소스 피자는 MIT 라이선스에 따라 라이선스가 부여됩니다.
Golodyayev Arseniy, MIPT, Skoltech, [email protected]
Egor Baryshnikov, Skoltech, [email protected]


