dsub
Release 0.5.0
dsub 는 클라우드에서 배치 스크립트를 쉽게 제출하고 실행할 수 있게 해주는 명령줄 도구입니다.
dsub 사용자 경험은 Grid Engine 및 Slurm과 같은 전통적인 고성능 컴퓨팅 작업 스케줄러를 모델로 합니다. 스크립트를 작성한 다음 로컬 시스템의 셸 프롬프트에서 작업 스케줄러에 제출합니다.
현재 dsub 개발 및 테스트를 위한 로컬 제공업체와 함께 백엔드 일괄 작업 실행자로 Google Cloud를 지원합니다. 커뮤니티의 도움을 받아 Grid Engine, Slurm, Amazon Batch 및 Azure Batch와 같은 다른 백엔드를 추가하고 싶습니다.
dsub Python으로 작성되었으며 Python 3.7 이상이 필요합니다.
dsub 0.4.7이었습니다.dsub 0.4.1을 사용하세요.dsub 0.3.10을 사용하세요.이는 선택 사항이지만 PyPI에서 설치하든 github에서 설치하든 상관없이 Python 가상 환경을 사용하는 것이 좋습니다.
선택한 디렉토리에서 이 작업을 수행할 수 있습니다.
python3 -m venv dsub_libs
source dsub_libs/bin/activate
Python 가상 환경을 사용하면 시스템의 다른 Python 애플리케이션에서 dsub 라이브러리 종속성이 격리됩니다.
dsub 실행하기 전에 모든 셸 세션에서 이 가상 환경을 활성화하세요. 셸에서 가상 환경을 비활성화하려면 다음 명령을 실행하세요.
deactivate
또는 dsub , dstat 및 ddel 호출하기 전에 virutalenv를 활성화하는 편의 스크립트 세트가 제공됩니다. bin 디렉토리에 있습니다. 쉘에서 virtualenv를 명시적으로 활성화하지 않으려면 이 스크립트를 사용할 수 있습니다.
google-batch 또는 google-cls-v2 공급자를 위해 dsub 에서 직접 사용되지는 않지만 Google Cloud SDK에 있는 명령줄 도구를 설치하는 것이 좋습니다.
더 빠른 작업 개발을 위해 local 공급자를 사용하려면 gsutil 사용하여 Google dsub 공급자와 파일 작업 의미가 일치하는지 확인하는 Google Cloud SDK를 설치해야 합니다 .
Google Cloud SDK 설치
달리다
gcloud init
gcloud 기본 프로젝트를 설정하고 Google Cloud SDK에 사용자 인증 정보를 부여하라는 메시지를 표시합니다.
dsub 설치다음 중 하나를 선택하십시오.
필요한 경우 pip를 설치합니다.
dsub 설치
pip install dsub
Git이 설치되어 있는지 확인하세요.
해당 환경에 대한 지침은 Git 웹사이트에서 확인할 수 있습니다.
이 저장소를 복제하세요.
git clone https://github.com/DataBiosphere/dsub
cd dsub
dsub 설치(종속성도 설치됨)
python -m pip install .
Bash 탭 완성을 설정합니다(선택 사항).
source bash_tab_complete
다음을 실행하여 최소한으로 설치를 확인하십시오.
dsub --help
(선택사항) Docker를 설치합니다.
이는 자체 Docker 이미지를 생성하거나 local 공급자를 사용하려는 경우에만 필요합니다.
dsub 저장소를 복제한 후 다음을 실행하여 Makefile을 사용할 수도 있습니다.
make
그러면 Python 가상 환경이 생성되고 dsub_libs 라는 디렉터리에 dsub 설치됩니다.
dsub 작업을 구축할 때 local 공급자가 매우 도움이 될 것이라고 생각합니다. 클라우드 VM에서 명령을 실행하라는 요청을 제출하는 대신 local 공급자는 로컬 시스템에서 dsub 작업을 실행합니다.
local 공급자는 대규모로 실행되도록 설계되지 않았습니다. 빠르게 반복할 수 있도록 클라우드 VM에서 실행을 에뮬레이션하도록 설계되었습니다. 처리 시간이 더 빨라지고 이를 사용하면 클라우드 요금이 부과되지 않습니다.
dsub 작업을 실행하고 완료될 때까지 기다립니다.
다음은 매우 간단한 "Hello World" 테스트입니다.
dsub
--provider local
--logging "${TMPDIR:-/tmp}/dsub-test/logging/"
--output OUT="${TMPDIR:-/tmp}/dsub-test/output/out.txt"
--command 'echo "Hello World" > "${OUT}"'
--wait
참고: TMPDIR 은 일반적으로 대부분의 Unix 시스템에서 기본적으로 /tmp 로 설정되어 있지만 설정되지 않은 채로 남아 있는 경우도 많습니다. 일부 MacOS 버전에서는 TMPDIR이 /var/folders 아래 위치로 설정됩니다.
참고: 위 구문 ${TMPDIR:-/tmp} Bash, zsh, ksh에서 지원되는 것으로 알려져 있습니다. 쉘은 TMPDIR 확장하지만, 설정되지 않은 경우 /tmp 사용됩니다.
출력 파일을 봅니다.
cat "${TMPDIR:-/tmp}/dsub-test/output/out.txt"
dsub 현재 Google Cloud의 Cloud Life Sciences v2beta API를 지원하며 Google Cloud의 Batch API에 대한 지원을 개발 중입니다.
dsub google-cls-v2 공급자를 통해 v2beta API를 지원합니다. google-cls-v2 가 현재 기본 공급자입니다. dsub 향후 릴리스에서 google-batch 기본값으로 전환할 예정입니다.
시작하는 단계는 아래 단계에 표시된 대로 약간 다릅니다.
Google 계정에 가입하고 프로젝트를 생성해 보세요.
API를 활성화합니다.
v2beta API의 경우(공급자: google-cls-v2 ):클라우드 생명 과학, 스토리지, 컴퓨팅 API 활성화
batch API의 경우(공급자: google-batch ):Batch, Storage 및 Compute API를 활성화합니다.
dsub Google API를 호출할 수 있도록 자격 증명을 제공하세요.
gcloud auth application-default login
Google Cloud Storage 버킷을 만듭니다.
dsub 로그와 출력 파일은 버킷에 기록됩니다. 스토리지 브라우저를 사용하여 버킷을 만들거나 Cloud SDK에 포함된 명령줄 유틸리티 gsutil을 실행하세요.
gsutil mb gs://my-bucket
my-bucket 버킷 이름 지정 규칙을 따르는 고유한 이름으로 변경합니다.
(기본적으로 버킷은 미국에 있지만 -l 옵션을 사용하여 위치 설정을 변경하거나 세분화할 수 있습니다.)
매우 간단한 "Hello World" dsub 작업을 실행하고 완료될 때까지 기다립니다.
v2beta API의 경우(공급자: google-cls-v2 ):
dsub
--provider google-cls-v2
--project my-cloud-project
--regions us-central1
--logging gs://my-bucket/logging/
--output OUT=gs://my-bucket/output/out.txt
--command 'echo "Hello World" > "${OUT}"'
--wait
my-cloud-project Google Cloud 프로젝트로 변경하고 my-bucket 위에서 만든 버킷으로 변경합니다.
batch API의 경우(공급자: google-batch ):
dsub
--provider google-batch
--project my-cloud-project
--regions us-central1
--logging gs://my-bucket/logging/
--output OUT=gs://my-bucket/output/out.txt
--command 'echo "Hello World" > "${OUT}"'
--wait
my-cloud-project Google Cloud 프로젝트로 변경하고 my-bucket 위에서 만든 버킷으로 변경합니다.
스크립트 명령어의 출력은 지정한 Cloud Storage의 OUT 파일에 기록됩니다.
출력 파일을 봅니다.
gsutil cat gs://my-bucket/output/out.txt
가능한 경우 dsub 사용자가 로컬에서(빠른 반복을 위해) 개발 및 테스트한 다음 대규모 실행을 진행할 수 있도록 지원하려고 합니다.
이를 위해 dsub 각각 일관된 런타임 환경을 구현하는 여러 "백엔드 공급자"를 제공합니다. 현재 제공업체는 다음과 같습니다.
백엔드 공급자가 구현하는 런타임 환경에 대한 자세한 내용은 dsub 백엔드 공급자에서 확인할 수 있습니다.
google-cls-v2 와 google-batch 의 차이점 google-cls-v2 제공자는 Cloud Life Sciences v2beta API를 기반으로 구축되었습니다. 이 API는 이전 버전인 Genomics v2alpha1 API와 매우 유사합니다. 차이점에 대한 자세한 내용은 마이그레이션 가이드에서 확인할 수 있습니다.
google-batch 공급자는 Cloud Batch API를 기반으로 구축되었습니다. Cloud Life Sciences와 Batch에 대한 자세한 내용은 이 마이그레이션 가이드에서 확인할 수 있습니다.
dsub API 간의 차이점을 크게 숨기지만 주목해야 할 몇 가지 차이점이 있습니다.
google-batch 사용하려면 한 지역에서 작업을 실행해야 합니다. dsub 의 --regions 및 --zones 플래그는 작업이 실행되어야 하는 위치를 지정합니다. google-cls-v2 사용하면 US 와 같은 다중 지역, 여러 지역 또는 지역 간 여러 영역을 지정할 수 있습니다. google-batch 공급자를 사용하면 단일 지역 내에서 하나의 지역 또는 여러 영역을 지정해야 합니다.
dsub 기능다음 섹션에서는 보다 복잡한 작업을 실행하는 방법을 보여줍니다.
위의 hello 예제와 같이 dsub 명령줄에서 직접 쉘 명령을 제공할 수 있습니다.
hello.sh 와 같은 파일에 스크립트를 저장할 수도 있습니다. 그런 다음 다음을 실행할 수 있습니다.
dsub
...
--script hello.sh
스크립트에 Docker 이미지에 저장되지 않은 종속성이 있는 경우 해당 종속성을 로컬 디스크로 전송할 수 있습니다. 입력 및 출력 파일과 폴더 작업에 대한 자세한 내용은 아래 지침을 참조하세요.
보다 쉽게 시작하기 위해 dsub 기본 Ubuntu Docker 이미지를 사용합니다. 이 기본 이미지는 향후 릴리스에서 언제든지 변경될 수 있으므로 재현 가능한 제작 작업 흐름을 위해 항상 이미지를 명시적으로 지정해야 합니다.
--image 플래그를 전달하여 이미지를 변경할 수 있습니다.
dsub
...
--image ubuntu:16.04
--script hello.sh
참고: --image Bash 쉘 해석기가 포함되어야 합니다.
--image 플래그 사용에 대한 자세한 내용은 스크립트, 명령 및 Docker의 이미지 섹션을 참조하세요.
--env 플래그를 사용하여 환경 변수를 스크립트에 전달할 수 있습니다.
dsub
...
--env MESSAGE=hello
--command 'echo ${MESSAGE}'
Docker 컨테이너가 실행될 때 환경 변수 MESSAGE hello 값이 할당됩니다.
스크립트 또는 명령은 ${MESSAGE} 와 같이 다른 Linux 환경 변수와 마찬가지로 변수를 참조할 수 있습니다.
명령 문자열을 큰따옴표가 아닌 작은따옴표로 묶어야 합니다. 큰따옴표를 사용하면 명령이 dsub에 전달되기 전에 로컬 셸에서 확장됩니다. --command 플래그 사용에 대한 자세한 내용은 스크립트, 명령 및 Docker를 참조하세요.
여러 환경 변수를 설정하려면 플래그를 반복하면 됩니다.
--env VAR1=value1
--env VAR2=value2
단일 플래그를 사용하여 공백으로 구분된 여러 변수를 설정할 수도 있습니다.
--env VAR1=value1 VAR2=value2
dsub는 입력 및 출력 파일과 폴더에 대한 클라우드 스토리지 버킷 경로를 사용하여 공유 파일 시스템의 동작을 모방합니다. Cloud Storage 버킷 경로를 지정합니다. 경로는 다음과 같습니다.
gs://my-bucket/my-file 과 같은 파일 경로gs://my-bucket/my-folder 와 같은 폴더 경로gs://my-bucket/my-folder/* 와 같은 와일드카드 경로자세한 내용은 입력 및 출력 문서를 참조하세요.
스크립트에서 Docker 이미지에 아직 포함되지 않은 로컬 입력 파일을 읽어야 하는 경우 해당 파일을 Google Cloud Storage에서 사용할 수 있어야 합니다.
스크립트에 종속 파일이 있는 경우 다음을 수행하여 해당 파일을 스크립트에서 사용할 수 있도록 할 수 있습니다.
Google Cloud Storage에 파일을 업로드하려면 스토리지 브라우저 또는 gsutil을 사용할 수 있습니다. Google Cloud Console에서 찾을 수 있는 이메일 주소인 서비스 계정에 공개되거나 공유된 데이터에 대해서도 실행할 수 있습니다.
입력 및 출력 파일을 지정하려면 --input 및 --output 플래그를 사용하십시오.
dsub
...
--input INPUT_FILE_1=gs://my-bucket/my-input-file-1
--input INPUT_FILE_2=gs://my-bucket/my-input-file-2
--output OUTPUT_FILE=gs://my-bucket/my-output-file
--command 'cat "${INPUT_FILE_1}" "${INPUT_FILE_2}" > "${OUTPUT_FILE}"'
이 예에서는 다음과 같습니다.
gs://my-bucket/my-input-file-1 에서 데이터 디스크의 경로로 복사됩니다.${INPUT_FILE_1} 에 설정됩니다.gs://my-bucket/my-input-file-2 에서 데이터 디스크의 경로로 복사됩니다.${INPUT_FILE_2} 에 설정됩니다. --command 환경 변수를 사용하여 파일 경로를 참조할 수 있습니다.
또한 이 예에서는 다음과 같습니다.
${OUTPUT_FILE} 에 설정됩니다.${OUTPUT_FILE} 에 지정된 위치의 데이터 디스크에 기록됩니다. --command 완료되면 출력 파일이 버킷 경로 gs://my-bucket/my-output-file 에 복사됩니다.
여러 --input 및 --output 매개변수를 지정할 수 있으며 순서에 관계없이 지정할 수 있습니다.
파일이 아닌 폴더를 복사하려면 --input-recursive 및 output-recursive 플래그를 사용하십시오.
dsub
...
--input-recursive FOLDER=gs://my-bucket/my-folder
--command 'find ${FOLDER} -name "foo*"'
여러 --input-recursive 및 --output-recursive 매개변수를 지정할 수 있으며 순서에 관계없이 지정할 수 있습니다.
입력을 명시적으로 지정하면 데이터 출처 추적이 향상되지만 Cloud Storage에서 작업 VM으로의 모든 입력을 명시적으로 현지화하고 싶지 않은 경우가 있습니다.
예를 들어 다음과 같은 경우가 있습니다.
또는
또는
그러면 읽기 전용으로 마운트하여 이 데이터에 액세스하는 것이 더 효율적이고 편리할 수 있습니다.
google-cls-v2 및 google-batch 공급자는 리소스 데이터에 대한 액세스를 제공하는 이러한 방법을 지원합니다.
local 공급자는 로컬 개발을 지원하기 위해 유사한 방식으로 로컬 디렉터리 마운트를 지원합니다.
google-cls-v2 또는 google-batch 제공자가 Cloud Storage FUSE를 사용하여 Cloud Storage 버킷을 마운트하도록 하려면 --mount 명령줄 플래그를 사용하세요.
--mount RESOURCES=gs://mybucket
버킷은 --script 또는 --command 실행하는 Docker 컨테이너에 읽기 전용으로 마운트되며 환경 변수 ${RESOURCES} 통해 위치를 사용할 수 있습니다. 스크립트 내에서 환경 변수를 사용하여 탑재된 경로를 참조할 수 있습니다. Cloud Storage FUSE를 사용하기 전에 POSIX 파일 시스템과 의미 체계의 주요 차이점을 읽어보세요.
google-cls-v2 또는 google-batch 공급자가 미리 만들고 채운 영구 디스크를 마운트하도록 하려면 --mount 명령줄 플래그와 소스 디스크의 URL을 사용하세요.
--mount RESOURCES="https://www.googleapis.com/compute/v1/projects/your-project/zones/your_disk_zone/disks/your-disk"
google-cls-v2 또는 google-batch 공급자가 이미지에서 생성된 영구 디스크를 마운트하도록 하려면 --mount 명령줄 플래그와 소스 이미지의 URL 및 디스크 크기(GB)를 사용하세요.
--mount RESOURCES="https://www.googleapis.com/compute/v1/projects/your-project/global/images/your-image 50"
이미지는 Compute Engine VM에 연결될 새 영구 디스크를 만드는 데 사용됩니다. 디스크는 --script 또는 --command 실행하는 Docker 컨테이너와 환경 변수 ${RESOURCES} 에서 사용할 수 있는 위치에 마운트됩니다. 스크립트 내에서 환경 변수를 사용하여 탑재된 경로를 참조할 수 있습니다.
이미지를 생성하려면 사용자 정의 이미지 생성을 참조하세요.
local 공급자) local 공급자가 디렉터리를 읽기 전용으로 마운트하도록 하려면 --mount 명령줄 플래그와 file:// 접두사를 사용합니다.
--mount RESOURCES=file://path/to/my/dir
로컬 디렉터리는 --script 또는 --command 실행하는 Docker 컨테이너에 마운트되며 해당 위치는 환경 변수 ${RESOURCES} 통해 제공됩니다. 스크립트 내에서 환경 변수를 사용하여 탑재된 경로를 참조할 수 있습니다.
local 공급자를 사용하여 실행되는 dsub 작업은 로컬 컴퓨터에서 사용 가능한 리소스를 사용합니다.
google-cls-v2 또는 google-batch 공급자를 사용하여 실행되는 dsub 작업은 광범위한 CPU, RAM, 디스크 및 하드웨어 가속기(예: GPU) 옵션을 활용할 수 있습니다.
자세한 내용은 컴퓨팅 리소스 설명서를 참조하세요.
기본적으로 dsub job-name--userid--timestamp 형식으로 job-id 생성합니다. 여기서 job-name 10자에서 잘리고 timestamp 는 1/100초 단위로 고유한 YYMMDD-HHMMSS-XX 형식입니다. . 여러 작업을 동시에 제출하는 경우에도 job-id 고유하지 않은 상황이 발생할 수 있습니다. 이 상황에서 고유한 job-id 필요한 경우 --unique-job-id 매개변수를 사용할 수 있습니다.
--unique-job-id 매개변수가 설정된 경우, job-id 대신 https://docs.python.org/3/library/uuid.html에서 생성된 고유한 32자 UUID가 됩니다. 일부 공급자는 job-id 문자로 시작하도록 요구하기 때문에 dsub 고유성을 유지하는 방식으로 모든 시작 숫자를 문자로 바꿉니다.
위의 각 예에서는 단일 변수, 입력 및 출력 세트가 포함된 단일 작업을 제출하는 방법을 보여주었습니다. 일괄 입력이 있고 이에 대해 동일한 작업을 실행하려는 경우 dsub 하면 일괄 작업을 생성할 수 있습니다.
dsub 반복적으로 호출하는 대신 각 작업에 대한 변수, 입력 및 출력을 포함하는 탭으로 구분된 값(TSV) 파일을 만든 다음 dsub 한 번 호출할 수 있습니다. 결과는 여러 작업이 포함된 단일 job-id 됩니다. 작업은 독립적으로 예약되고 실행되지만 그룹으로 모니터링하고 삭제할 수 있습니다.
TSV 파일의 첫 번째 줄은 매개변수의 이름과 유형을 지정합니다. 예를 들어:
--env SAMPLE_ID<tab>--input VCF_FILE<tab>--output OUTPUT_PATH
파일의 각 추가 줄은 각 작업에 대한 변수, 입력 및 출력 값을 제공해야 합니다. 헤더 뒤의 각 줄은 별도의 작업에 대한 값을 나타냅니다.
여러 --env , --input 및 --output 매개변수를 지정할 수 있으며 순서에 관계없이 지정할 수 있습니다. 예를 들어:
--env SAMPLE<tab>--input A<tab>--input B<tab>--env REFNAME<tab>--output O
S1<tab>gs://path/A1.txt<tab>gs://path/B1.txt<tab>R1<tab>gs://path/O1.txt
S2<tab>gs://path/A2.txt<tab>gs://path/B2.txt<tab>R2<tab>gs://path/O2.txt
--tasks 매개변수를 사용하여 TSV 파일을 dsub에 전달합니다. 이 매개변수는 파일 경로와 선택적으로 처리할 작업 범위를 모두 허용합니다. 파일은 로컬 파일 시스템( dsub 호출하는 머신) 또는 Google Cloud Storage의 버킷(파일 이름이 'gs://'로 시작)에서 읽을 수 있습니다.
예를 들어 my-tasks.tsv 에 101줄(한 줄 헤더와 실행할 작업에 대한 100줄 매개 변수)이 포함되어 있다고 가정합니다. 그 다음에:
dsub ... --tasks ./my-tasks.tsv
100개의 작업이 포함된 작업을 생성하고 다음을 수행합니다.
dsub ... --tasks ./my-tasks.tsv 1-10
라인 2부터 11까지 각각 하나씩 10개의 작업이 포함된 작업을 생성합니다.
작업 범위 값은 다음 형식 중 하나를 취할 수 있습니다.
m 작업 m 제출함을 나타냅니다(라인 m+1).m- 작업 m 으로 시작하는 모든 작업을 제출함을 나타냅니다.mn m 부터 n 까지(포함) 모든 작업을 제출함을 나타냅니다. --logging 플래그는 dsub 작업 로그 파일의 위치를 가리킵니다. 로깅 경로를 지정하는 방법에 대한 자세한 내용은 로깅을 참조하세요.
다른 작업을 시작하기 전에 작업이 완료될 때까지 기다릴 수 있습니다. 자세한 내용은 dsub를 사용한 작업 제어를 참조하세요.
dsub 실패한 작업을 자동으로 다시 시도하는 것이 가능합니다. 자세한 내용은 dsub를 사용한 재시도를 참조하세요.
작업 및 태스크에 사용자 정의 라벨을 추가할 수 있으며 이를 통해 자신의 식별자를 사용하여 태스크를 모니터링하고 취소할 수 있습니다. 또한 Google 공급자를 사용하면 작업에 라벨을 지정하면 가상 머신 및 디스크와 같은 관련 컴퓨팅 리소스에 라벨이 지정됩니다.
자세한 내용은 상태 확인 및 작업 문제 해결을 참조하세요.
dstat 명령은 작업 상태를 표시합니다.
dstat --provider google-cls-v2 --project my-cloud-project
추가 인수가 없으면 dstat는 현재 USER 에 대해 실행 중인 작업 목록을 표시합니다.
특정 작업의 상태를 표시하려면 --jobs 플래그를 사용하십시오.
dstat --provider google-cls-v2 --project my-cloud-project --jobs job-id
일괄 작업의 경우 출력에는 실행 중인 모든 작업이 나열됩니다.
dsub가 제출한 각 작업에는 작업 식별 및 작업 제어에 사용할 수 있는 일련의 메타데이터 값이 제공됩니다. 각 작업과 관련된 메타데이터에는 다음이 포함됩니다.
job-name : 기본값은 스크립트 파일 이름이나 스크립트 명령의 첫 번째 단어입니다. --name 매개변수를 사용하여 명시적으로 설정할 수 있습니다.user-id : USER 환경 변수 값입니다.job-id : 작업 모니터링 및 취소를 위해 각각 dstat 및 ddel 호출에 사용할 수 있는 작업 식별자입니다. job-id 형식에 대한 자세한 내용은 작업 식별자를 참조하세요.task-id : 작업이 --tasks 매개변수와 함께 제출되면 각 작업은 "task -n " 형식의 순차적 값을 가져옵니다. 여기서 n 은 1부터 시작합니다.상태 확인 및 작업 문제 해결 가이드에 나열된 "레이블 제한 사항"을 준수하도록 작업 메타데이터 값이 수정됩니다.
메타데이터는 일괄 작업 내의 작업이나 개별 작업을 취소하는 데 사용될 수 있습니다.
자세한 내용은 상태 확인 및 작업 문제 해결을 참조하세요.
기본적으로 dstat는 작업당 한 줄을 출력합니다. 많은 작업이 포함된 일괄 작업을 사용하는 경우 --summary 의 이점을 누릴 수 있습니다.
$ dstat --provider google-cls-v2 --project my-project --status '*' --summary
Job Name Status Task Count
------------- ------------- -------------
my-job-name RUNNING 2
my-job-name SUCCESS 1
이 모드에서 dstat는 (작업 이름, 작업 상태) 쌍당 한 줄을 인쇄합니다. 완료된 작업 수, 아직 실행 중인 작업 수, 실패/취소된 작업 수를 한눈에 확인할 수 있습니다.
ddel 명령은 실행 중인 작업을 삭제합니다.
기본적으로 현재 사용자가 제출한 작업만 삭제됩니다. --users 플래그를 사용하여 다른 사용자를 지정하거나 '*' 를 사용하여 모든 사용자를 지정합니다.
실행 중인 작업을 삭제하려면 다음 안내를 따르세요.
ddel --provider google-cls-v2 --project my-cloud-project --jobs job-id
작업이 일괄 작업인 경우 실행 중인 모든 작업이 삭제됩니다.
특정 작업을 삭제하려면:
ddel
--provider google-cls-v2
--project my-cloud-project
--jobs job-id
--tasks task-id1 task-id2
현재 사용자에 대해 실행 중인 모든 작업을 삭제하려면 다음을 따르세요.
ddel --provider google-cls-v2 --project my-cloud-project --jobs '*'
google-cls-v2 또는 google-batch 공급자를 사용하여 dsub 명령을 실행할 때 고려해야 할 두 가지 사용자 인증 정보 집합이 있습니다.
pipelines.run() 요청을 제출하는 계정 pipelines.run() 요청을 제출하는 데 사용되는 계정은 일반적으로 최종 사용자 자격 증명입니다. 다음을 실행하여 이를 설정했을 것입니다.
gcloud auth application-default login
VM에 사용되는 계정은 서비스 계정입니다. 아래 이미지는 이를 보여줍니다.
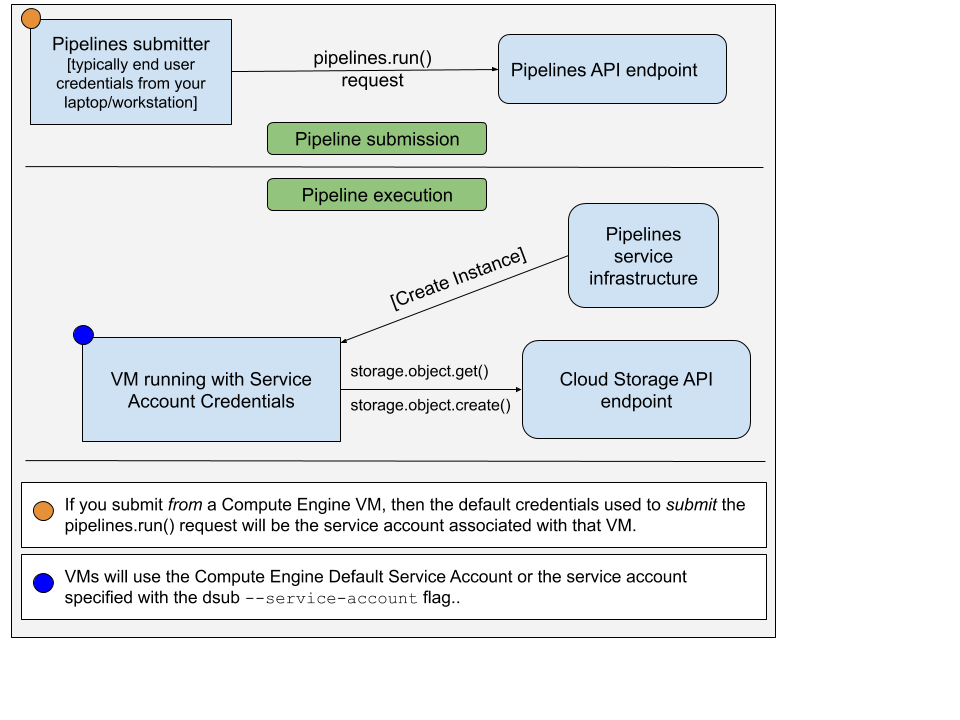
기본적으로 dsub 기본 Compute Engine 서비스 계정을 VM 인스턴스의 승인된 서비스 계정으로 사용합니다. --service-account 사용하여 다른 서비스 계정의 이메일 주소를 지정하도록 선택할 수 있습니다.
기본적으로 dsub 서비스 계정에 다음 액세스 범위를 부여합니다.
또한 API는 항상 다음 범위를 추가합니다.
--scopes 사용하여 범위를 지정하도록 선택할 수 있습니다.
기본 서비스 계정을 사용하는 것은 간단하지만 이 계정에는 기본적으로 광범위한 권한도 부여됩니다. 최소 권한 원칙에 따라 dsub 명령/스크립트를 실행하는 데 충분한 권한만 부여된 서비스 계정을 생성하고 사용할 수 있습니다.
새 서비스 계정을 만들려면 다음 단계를 따르세요.
gcloud iam service-accounts create 명령어를 실행합니다. 서비스 계정의 이메일 주소는 [email protected] 입니다.
gcloud iam service-accounts create "sa-name"
버킷 등에 대한 IAM 액세스 권한을 서비스 계정에 부여합니다.
gsutil iam ch serviceAccount:[email protected]:roles/storage.objectAdmin gs://bucket-name
--service-account 포함하도록 dsub 명령을 업데이트하세요.
dsub
--service-account [email protected]
...
예제를 참조하세요:
다음에 대한 추가 문서를 참조하세요.


