CQN
1.0.0
연속 제어를 위한 샘플 효율적인 값 기반 RL 알고리즘 인 CQN(Coarse-to-fine Q-Network) 의 재구현은 다음에서 소개됩니다.
거친 강화 학습을 통한 연속 제어
서영교, 자파르 우루스, 스티븐 제임스
우리의 핵심 아이디어는 연속 작업 공간을 대략적인 방식으로 확대하는 RL 에이전트를 학습하여 각 수준에서 몇 가지 개별 작업을 사용하여 연속 제어를 위한 값 기반 RL 에이전트를 훈련할 수 있도록 하는 것입니다.
자세한 내용은 프로젝트 웹페이지 https://younggyo.me/cqn/을 참조하세요.
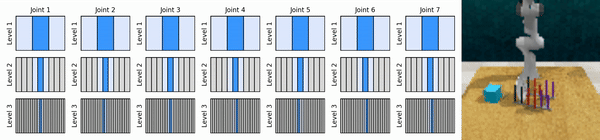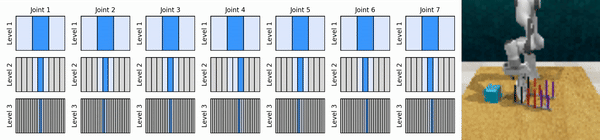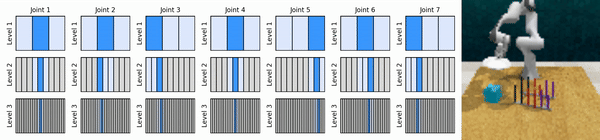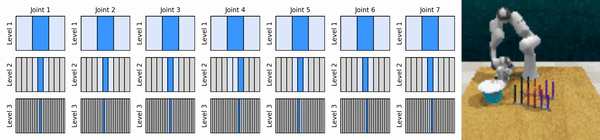
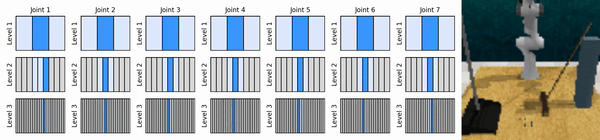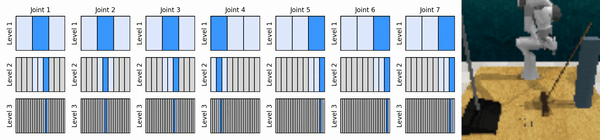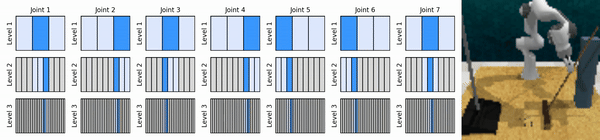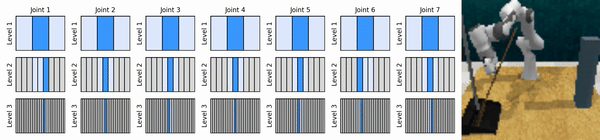
Conda 환경을 설치합니다.
conda env create -f conda_env.yml
conda activate cqn
RLBench 및 PyRep을 설치합니다(2024년 7월 10일자 최신 버전을 사용해야 함). (1) RLBench 및 PyRep 설치 및 (2) 헤드리스 모드 활성화에 대한 원본 리포지토리의 가이드를 따르세요. (RLBench 설치에 대한 자세한 내용은 RLBench 및 Robobase의 README를 참조하세요.)
git clone https://github.com/stepjam/RLBench
git clone https://github.com/stepjam/PyRep
# Install PyRep
cd PyRep
git checkout 8f420be8064b1970aae18a9cfbc978dfb15747ef
pip install .
# Install RLBench
cd RLBench
git checkout b80e51feb3694d9959cb8c0408cd385001b01382
pip install .
사전 수집 시연
cd RLBench/rlbench
CUDA_VISIBLE_DEVICES=0 DISPLAY=:0.0 python dataset_generator.py --save_path=/your/own/directory --image_size 84 84 --renderer opengl3 --episodes_per_task 100 --variations 1 --processes 1 --tasks take_lid_off_saucepan --arm_max_velocity 2.0 --arm_max_acceleration 8.0
실험 실행(CQN):
CUDA_VISIBLE_DEVICES=0 DISPLAY=:0.0 python train_rlbench.py rlbench_task=take_lid_off_saucepan num_demos=100 dataset_root=/your/own/directory
기본 실험 실행(DrQv2+):
CUDA_VISIBLE_DEVICES=0 DISPLAY=:0.0 python train_rlbench_drqv2plus.py rlbench_task=take_lid_off_saucepan num_demos=100 dataset_root=/your/own/directory
실험 실행:
CUDA_VISIBLE_DEVICES=0 python train_dmc.py dmc_task=cartpole_swingup
경고: CQN은 DMC에서 광범위하게 테스트되지 않았습니다.
이 저장소는 DrQ-v2의 공개 구현을 기반으로 합니다.
@article{seo2024continuous,
title={Continuous Control with Coarse-to-fine Reinforcement Learning},
author={Seo, Younggyo and Uru{c{c}}, Jafar and James, Stephen},
journal={arXiv preprint arXiv:2407.07787},
year={2024}
}


