EpiOS
1.0.0
이 프로젝트는 모집단을 샘플링하고 다양한 방법을 평가하는 다양한 방법으로 구성됩니다. 무응답자, 위양성/음성 비율, 감염 기간 동안 환자의 전염 프로필 능력 등을 포함하여 샘플을 기반으로 한 감염 수준 추정에 편향을 일으킬 수 있는 많은 상황을 포함합니다. EpiABM 모델을 기반으로 하는 이 패키지는 질병 전파 시뮬레이션을 실행하여 각 샘플링 방법의 예측 오류를 확인함으로써 최상의 샘플링 방법을 출력할 수도 있습니다.
EpiOS는 아직 PyPI에서 사용할 수 없지만 모듈을 로컬로 pip 설치할 수 있습니다. 디렉터리는 먼저 로컬 컴퓨터에 다운로드되어야 하며 다음 명령을 사용하여 설치할 수 있습니다.
pip install -e .또한 감염 시뮬레이션 데이터를 생성하려면 EpiABM 모델을 설치하는 것이 좋습니다. 먼저 pyEpiabm을 컴퓨터의 어느 위치에나 다운로드한 후 다음 명령을 사용하여 설치할 수 있습니다.
pip install -e path/to/pyEpiabm 위의 docs 배지를 통해 문서에 액세스할 수 있습니다.
다음은 우리 프로젝트의 UML 클래스 다이어그램입니다. 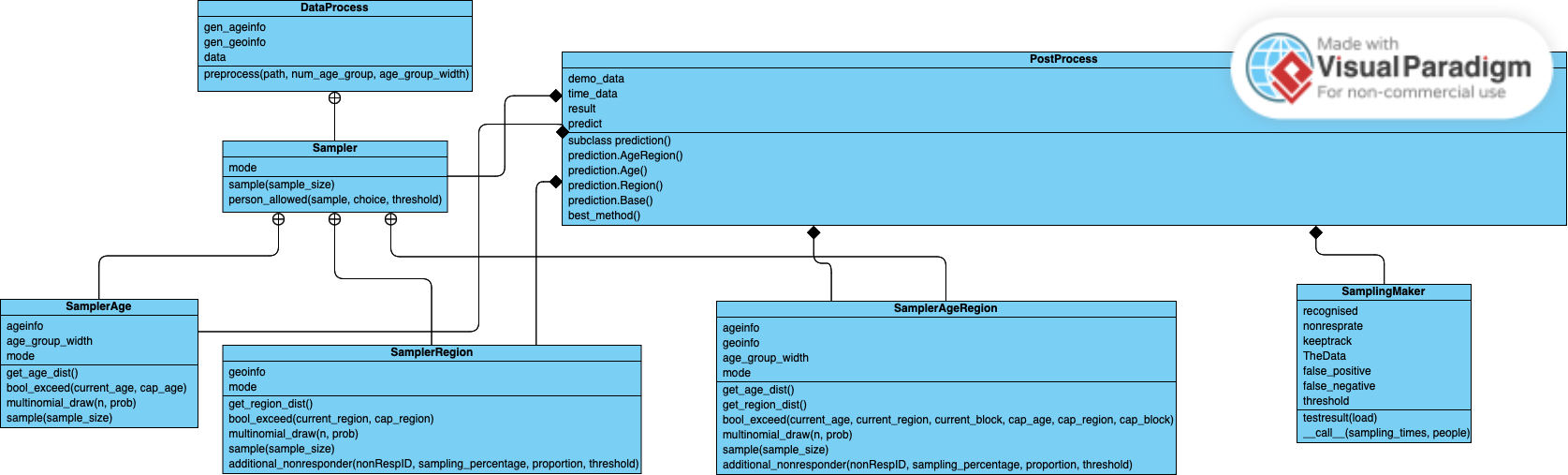
params.py 파일에는 이 모델에 필요한 모든 매개변수가 포함되어 있습니다. 또한, input 폴더에 있는 파일들은 데이터 전처리 과정에서 생성된 임시 파일의 예시입니다. 샘플러 클래스에서 사용됩니다. 각 샘플러 클래스의 data_store_path 매개변수는 이러한 파일을 저장하는 경로입니다.
PostProcess 사용하여 플롯 생성 먼저, 새로운 PostProcess 개체를 정의하고 pyEpiabm에서 생성된 인구통계 데이터 demodata 와 감염 데이터 timedata 입력해야 합니다. 둘째, PostProcess.predict를 사용하여 다양한 샘플링 방법을 기반으로 예측을 수행할 수 있습니다. 메소드로 사용하려는 샘플링 메소드를 직접 호출할 수 있습니다. 그런 다음 샘플 및 샘플 크기에 대한 시점을 지정합니다. 여기서는 샘플링 방법으로 AgeRegion 사용하고, 샘플링할 시점으로 [0, 1, 2, 3, 4, 5] 사용하고, 샘플 크기로 3 사용합니다. 마지막으로 non_responder 및 comparison 매개변수를 지정하여 비응답자를 고려할지 여부와 결과를 실제 데이터와 비교할지 여부를 지정할 수 있습니다.
코드 예제의 경우 다음을 볼 수 있습니다.
python import epios
postprocess = epios . PostProcess ( time_data = timedata , demo_data = demodata )
res , diff = postprocess . predict . AgeRegion (
time_sample = [ 0 , 1 , 2 , 3 , 4 , 5 ], sample_size = 3 ,
non_responders = False ,
comparison = True ,
gen_plot = True ,
saving_path_sampling = 'path/to/save/sampled/predicted/infection/plot' ,
saving_path_compare = 'path/to/save/comparison/plot'
)이제 주어진 경로에 피규어가 저장됩니다!
PostProcess 사용하여 최상의 샘플링 방법 선택 먼저, 새로운 PostProcess 개체를 정의하고 pyEpiabm에서 생성된 인구통계 데이터 demodata 와 감염 데이터 timedata 입력해야 합니다. 둘째, PostProcess.best_method를 사용하여 다양한 샘플링 방법의 성능을 비교할 수 있습니다. 비교하려는 방법을 제공할 수 있습니다. 그런 다음 표본 추출 간격과 표본 크기를 지정합니다. 셋째, non_responder 및 comparison 매개변수를 지정하여 비응답자를 고려할지 여부와 결과를 실제 데이터와 비교할지 여부를 지정할 수 있습니다. 또한 샘플링 방법은 확률적이므로 평균 성능을 얻기 위해 실행되는 반복 횟수를 지정할 수 있습니다. 또한, parallel_computation 켜서 속도를 높일 수도 있습니다. 마지막으로, hyperparameter_autotune 켜서 최적의 하이퍼파라미터 조합을 자동으로 찾을 수 있습니다.
코드 예제의 경우 다음을 볼 수 있습니다.
python import epios
postprocess = epios . PostProcess ( time_data = timedata , demo_data = demodata )
# Define the input keywards for finding the best method
best_method_kwargs = {
'age_group_width_range' : [ 14 , 17 , 20 ]
}
# Suppose we want to compare among methods Age-Random, Base-Same,
# Base-Random, Region-Random and AgeRegion-Random
# And suppose we want to turn on the parallel computation to speed up
if __name__ == '__main__' :
# This 'if' statement can be omitted when not using parallel computation
postprocess . best_method (
methods = [
'Age' ,
'Base-Same' ,
'Base-Random' ,
'Region-Random' ,
'AgeRegion-Random'
],
sample_size = 3 ,
hyperparameter_autotune = True ,
non_responder = False ,
sampling_interval = 7 ,
iteration = 1 ,
# When considering non-responders, input the following line
# non_resp_rate=0.1,
metric = 'mean' ,
parallel_computation = True ,
** best_method_kwargs
)
# Then the output will be printed

