gpt neox
GPT-NeoX 2.0
이 저장소는 GPU에서 대규모 언어 모델을 훈련하기 위한 EleutherAI의 라이브러리를 기록합니다. 우리의 현재 프레임워크는 NVIDIA의 Megatron 언어 모델을 기반으로 하며 DeepSpeed의 기술과 몇 가지 새로운 최적화를 통해 강화되었습니다. 우리는 이 저장소를 대규모 자동 회귀 언어 모델 훈련을 위한 기술을 수집하고 대규모 훈련에 대한 연구를 가속화할 수 있는 중앙 집중화되고 접근 가능한 장소로 만드는 것을 목표로 합니다. 이 라이브러리는 Oak Ridge 국립 연구소, CarperAI, Stability AI, Together.ai, 고려 대학교, 카네기 멜론 대학교, 도쿄 대학교 등의 연구원을 포함하여 학계, 산업 및 정부 연구소에서 널리 사용되고 있습니다. 유사한 라이브러리 중에서 GPT-NeoX는 Slurm, MPI 및 IBM Job Step Manager를 통한 실행을 포함하여 다양한 시스템과 하드웨어를 지원하며 AWS, CoreWeave, ORNL Summit, ORNL Frontier, LUMI 및 다른 사람.
수십억 개의 매개변수가 포함된 모델을 처음부터 훈련하려는 것이 아니라면 이 라이브러리는 사용하기에 잘못된 라이브러리일 가능성이 높습니다. 일반적인 추론이 필요한 경우 GPT-NeoX 모델을 지원하는 Hugging Face transformers 라이브러리를 사용하는 것이 좋습니다.
GPT-NeoX는 인기 있는 Megatron-DeepSpeed 라이브러리와 동일한 기능과 기술을 많이 활용하지만 유용성이 크게 향상되고 새로운 최적화가 이루어졌습니다. 주요 기능은 다음과 같습니다:
[2024/9/9] 이제 DPO, KTO 및 보상 모델링을 통한 선호 학습을 지원합니다.
[2024/9/9] 이제 기계 학습 모니터링 플랫폼인 Comet ML과의 통합을 지원합니다.
[2024년 5월 21일] 이제 파이프라인 병렬 처리로 RWKV를 지원합니다!. RWKV 및 RWKV+파이프라인에 대한 PR 보기
[2024/3/21] 이제 MoE(Mixture-of-Experts)를 지원합니다.
[2024/3/17] 이제 AMD MI250X GPU를 지원합니다.
[2024/3/15] 이제 텐서 병렬 처리로 Mamba를 지원합니다! 홍보 보기
[2023년 8월 10일] 이제 AWS S3에서 체크포인트를 지원합니다! s3_path 구성 옵션으로 활성화(자세한 내용은 PR 참조)
[2023/9/20] #1035부터 Flash Attention 0.x 및 1.x를 더 이상 사용하지 않으며 지원을 Flash Attention 2.x로 마이그레이션했습니다. 이것이 문제를 일으킬 것이라고는 생각하지 않지만, 최신 GPT-NeoX를 사용하여 이전 플래시 지원이 필요한 특정 사용 사례가 있는 경우 문제를 제기해 주세요.
[2023년 8월 10일] 이번 달 말에 업스트림될 math-lm 프로젝트에서는 LLaMA 2 및 Flash Attention v2에 대한 실험적 지원이 지원됩니다.
[2023년 5월 17일] 기타 버그를 수정한 후 이제 bf16을 완전히 지원합니다.
[2023년 4월 11일] 이제 Alibi 위치 임베딩을 지원하도록 Flash Attention 구현을 업그레이드했습니다.
[2023년 3월 9일] 최신 DeepSpeed를 기반으로 한 업그레이드 버전인 GPT-NeoX 2.0.0을 출시했으며 앞으로 정기적으로 동기화될 예정입니다.
2023년 3월 9일 이전에 GPT-NeoX는 이전 버전의 DeepSpeed(0.3.15)를 기반으로 하는 DeeperSpeed에 의존했습니다. 사용자가 이전 버전의 GPT-NeoX 및 DeeperSpeed에 액세스할 수 있도록 허용하면서 최신 업스트림 DeepSpeed 버전으로 마이그레이션하기 위해 두 라이브러리 모두에 대해 두 가지 버전의 릴리스를 도입했습니다.
이 코드베이스는 주로 Python 3.8-3.10 및 PyTorch 1.8-2.0용으로 개발 및 테스트되었습니다. 이는 엄격한 요구 사항이 아니며 다른 버전과 라이브러리 조합이 작동할 수 있습니다.
나머지 기본 종속성을 설치하려면 다음을 실행하세요.
pip install -r requirements/requirements.txt
pip install -r requirements/requirements-wandb.txt # optional, if logging using WandB
pip install -r requirements/requirements-tensorboard.txt # optional, if logging via tensorboard
pip install -r requirements/requirements-comet.txt # optional, if logging via Comet저장소 루트에서.
경고
우리의 코드베이스는 몇 가지 추가된 변경 사항이 포함된 DeepSpeed 라이브러리의 포크인 DeeperSpeed를 사용합니다. 계속하기 전에 Anaconda, 가상 머신 또는 다른 형태의 환경 격리를 사용하는 것이 좋습니다. 그렇지 않으면 DeepSpeed에 의존하는 다른 리포지토리가 중단될 수 있습니다.
이제 JIT 융합 커널 컴파일을 통해 AMD GPU(MI100, MI250X)를 지원합니다. 융합 커널은 필요에 따라 빌드되고 로드됩니다. 작업 시작 중에 기다리지 않으려면 수동 사전 빌드에 대해 다음을 수행할 수도 있습니다.
python
from megatron . fused_kernels import load
load () 이는 플랫폼별 코드 변경 없이 다양한 GPU 공급업체(AMD, NVIDIA)에 대한 구축 프로세스를 자동으로 조정합니다. pytest 사용하여 융합 커널을 추가로 테스트하려면 pytest tests/model/test_fused_kernels.py 사용하세요.
Flash-Attention을 사용하려면 ./requirements/requirements-flashattention.txt 에 추가 종속성을 설치하고 이에 따라 구성에서 주의 유형을 설정하세요(configs 참조). 이는 Ampere GPU(예: A100)를 포함한 특정 GPU 아키텍처에 대한 정기적인 관심에 비해 상당한 속도 향상을 제공할 수 있습니다. 자세한 내용은 저장소를 참조하세요.
NeoX 및 Deep(er)Speed는 여러 다른 노드에 대한 교육을 지원하며 다양한 시작 프로그램을 사용하여 다중 노드 작업을 조정할 수 있는 옵션이 있습니다.
일반적으로 다음 형식으로 액세스할 수 있는 "호스트 파일"이 있어야 합니다.
node1_ip slots=8
node2_ip slots=8 여기서 첫 번째 열에는 설정에 있는 각 노드의 IP 주소가 포함되고 슬롯 수는 노드가 액세스할 수 있는 GPU 수입니다. 구성에서 "hostfile": "/path/to/hostfile" 사용하여 호스트 파일 경로를 전달해야 합니다. 또는 호스트 파일 경로가 환경 변수 DLTS_HOSTFILE 에 있을 수 있습니다.
pdsh 기본 실행 프로그램이며, pdsh 사용하는 경우 (pdsh가 환경에 설치되어 있는지 확인하는 것 외에) 구성 파일에 {"launcher": "pdsh"} 설정하기만 하면 됩니다.
MPI를 사용하는 경우 MPI 라이브러리(DeepSpeed/GPT-NeoX는 현재 mvapich , openmpi , mpich 및 impi 지원하지만 openmpi 가장 일반적으로 사용되고 테스트됨)를 지정하고 구성 파일에 deepspeed_mpi 플래그를 전달해야 합니다.
{
"launcher" : " openmpi " ,
"deepspeed_mpi" : true
} 환경이 올바르게 설정되고 올바른 구성 파일이 있으면 일반 Python 스크립트처럼 deepy.py 를 사용하고 다음을 사용하여 교육 작업을 시작할 수 있습니다.
python3 deepy.py train.py /path/to/configs/my_model.yml
Slurm을 사용하는 것은 약간 더 복잡할 수 있습니다. MPI와 마찬가지로 구성에 다음을 추가해야 합니다.
{
"launcher" : " slurm " ,
"deepspeed_slurm" : true
} Slurm 클러스터의 컴퓨팅 노드에 대한 SSH 액세스 권한이 없는 경우 {"no_ssh_check": true} 추가해야 합니다.
위의 기본 실행 옵션으로는 충분하지 않은 경우가 많습니다
이러한 경우 사용 사례를 지원하도록 DeepSpeed 다중 노드 실행기 유틸리티를 수정해야 합니다. 대체로 이러한 향상된 기능은 두 가지 범주에 속합니다.
이 경우 deepspeed/launcher/multinode_runner.py 에 새로운 다중 노드 실행기 클래스를 추가하고 이를 GPT-NeoX의 구성 옵션으로 노출해야 합니다. Summit JSRun에서 이를 수행한 방법에 대한 예는 각각 이 DeeperSpeed 커밋과 이 GPT-NeoX 커밋에 있습니다.
최적화 또는 디버그(예: Slurm srun CPU 바인딩 수정 또는 MPI 로그에 순위 태그 지정)를 위해 MPI/Slurm 실행 명령을 수정하려는 경우가 많이 있습니다. 이 경우 get_cmd 메서드(예: OpenMPI의 경우 mpirun_cmd)에서 다중 노드 실행기 클래스의 실행 명령을 수정해야 합니다. Stability 클러스터용 Slurm 및 OpenMPI를 사용하여 최적화되고 순위 태그가 지정된 실행 명령을 제공하기 위해 이를 수행한 방법에 대한 예는 DeeperSpeed 분기에 있습니다.
일반적으로 단일 고정 호스트 파일을 가질 수 없으므로 작업이 시작될 때 이를 동적으로 생성하는 스크립트가 필요합니다. Slurm과 노드당 8개의 GPU를 사용하여 호스트 파일을 동적으로 생성하는 예제 스크립트는 다음과 같습니다.
#! /bin/bash
GPUS_PER_NODE=8
mkdir -p /sample/path/to/hostfiles
# need to add the current slurm jobid to hostfile name so that we don't add to previous hostfile
hostfile=/sample/path/to/hostfiles/hosts_ $SLURM_JOBID
# be extra sure we aren't appending to a previous hostfile
rm $hostfile & > /dev/null
# loop over the node names
for i in ` scontrol show hostnames $SLURM_NODELIST `
do
# add a line to the hostfile
echo $i slots= $GPUS_PER_NODE >> $hostfile
done $SLURM_JOBID 및 $SLURM_NODELIST Slurm이 자동으로 생성하는 환경 변수입니다. 작업 생성 시 설정된 사용 가능한 Slurm 환경 변수의 전체 목록은 sbatch 문서를 참조하세요.
그런 다음 GPT-NeoX 작업을 시작할 sbatch 스크립트를 생성할 수 있습니다. 노드당 8개의 GPU가 있는 Slurm 기반 클러스터의 기본 sbatch 스크립트는 다음과 같습니다.
#! /bin/bash
# SBATCH --job-name="neox"
# SBATCH --partition=your-partition
# SBATCH --nodes=1
# SBATCH --ntasks-per-node=8
# SBATCH --gres=gpu:8
# Some potentially useful distributed environment variables
export HOSTNAMES= ` scontrol show hostnames " $SLURM_JOB_NODELIST " `
export MASTER_ADDR= $( scontrol show hostnames " $SLURM_JOB_NODELIST " | head -n 1 )
export MASTER_PORT=12802
export COUNT_NODE= ` scontrol show hostnames " $SLURM_JOB_NODELIST " | wc -l `
# Your hostfile creation script from above
./write_hostfile.sh
# Tell DeepSpeed where to find our generated hostfile via DLTS_HOSTFILE
export DLTS_HOSTFILE=/sample/path/to/hostfiles/hosts_ $SLURM_JOBID
# Launch training
python3 deepy.py train.py /sample/path/to/your/configs/my_model.yml
그런 다음 sbatch my_sbatch_script.sh 사용하여 훈련 실행을 시작할 수 있습니다.
또한 컨테이너에서 NeoX를 실행하려는 경우 Dockerfile 및 docker-compose 구성을 제공합니다.
컨테이너를 실행하기 위한 요구 사항은 적절한 GPU 드라이버, 최신 Docker 설치 및 nvidia-container-toolkit이 설치되어 있어야 합니다. 설치가 양호한지 테스트하려면 다음과 같은 "샘플 워크로드"를 사용할 수 있습니다.
docker run --rm --runtime=nvidia --gpus all ubuntu nvidia-smi
실행되는 경우 환경에서 NEOX_DATA_PATH 및 NEOX_CHECKPOINT_PATH를 내보내 체크포인트를 저장하고 로드하기 위한 데이터 디렉터리와 디렉터리를 지정해야 합니다.
export NEOX_DATA_PATH=/mnt/sda/data/enwiki8 #or wherever your data is stored on your system
export NEOX_CHECKPOINT_PATH=/mnt/sda/checkpoints
그런 다음 gpt-neox 디렉터리에서 이미지를 빌드하고 다음을 사용하여 컨테이너에서 셸을 실행할 수 있습니다.
docker compose run gpt-neox bash
빌드 후에는 다음을 수행할 수 있습니다.
mchorse@537851ed67de:~$ echo $(pwd)
/home/mchorse
mchorse@537851ed67de:~$ ls -al
total 48
drwxr-xr-x 1 mchorse mchorse 4096 Jan 8 05:33 .
drwxr-xr-x 1 root root 4096 Jan 8 04:09 ..
-rw-r--r-- 1 mchorse mchorse 220 Feb 25 2020 .bash_logout
-rw-r--r-- 1 mchorse mchorse 3972 Jan 8 04:09 .bashrc
drwxr-xr-x 4 mchorse mchorse 4096 Jan 8 05:35 .cache
drwx------ 3 mchorse mchorse 4096 Jan 8 05:33 .nv
-rw-r--r-- 1 mchorse mchorse 807 Feb 25 2020 .profile
drwxr-xr-x 2 root root 4096 Jan 8 04:09 .ssh
drwxrwxr-x 8 mchorse mchorse 4096 Jan 8 05:35 chk
drwxrwxrwx 6 root root 4096 Jan 7 17:02 data
drwxr-xr-x 11 mchorse mchorse 4096 Jan 8 03:52 gpt-neox
장기 실행 작업의 경우 다음을 실행해야 합니다.
docker compose up -d
분리 모드에서 컨테이너를 실행한 다음 별도의 터미널 세션에서 다음을 실행합니다.
docker compose exec gpt-neox bash
그런 다음 컨테이너 내부에서 원하는 작업을 실행할 수 있습니다.
장시간 실행하거나 분리 모드에서 실행할 때 고려해야 할 사항은 다음과 같습니다.
dockerhub에서 사전 빌드된 컨테이너 이미지를 실행하려는 경우 대신 -f docker-compose-dockerhub.yml 사용하여 docker compose 명령을 실행할 수 있습니다. 예:
docker compose run -f docker-compose-dockerhub.yml gpt-neox bash
모든 기능은 deepspeed 실행 프로그램 주변의 래퍼인 deepy.py 사용하여 실행되어야 합니다.
현재 우리는 세 가지 주요 기능을 제공합니다:
train.py 는 모델 훈련 및 미세 조정에 사용됩니다.eval.py 는 언어 모델 평가 도구를 사용하여 훈련된 모델을 평가하는 데 사용됩니다.generate.py 는 훈련된 모델에서 텍스트를 샘플링하는 데 사용됩니다.다음을 사용하여 시작할 수 있습니다.
./deepy.py [script.py] [./path/to/config_1.yml] [./path/to/config_2.yml] ... [./path/to/config_n.yml]예를 들어 교육을 시작하려면 다음을 실행하세요.
./deepy.py train.py ./configs/20B.yml ./configs/local_cluster.yml각 진입점에 대한 자세한 내용은 훈련 및 미세 조정, 추론 및 평가를 각각 참조하세요.
GPT-NeoX 매개변수는 deepy.py 실행 프로그램에 전달되는 YAML 구성 파일에 정의됩니다. 우리는 다양한 기능과 모델 크기를 보여주는 몇 가지 예제 .yml 파일을 구성에 제공했습니다.
이러한 파일은 일반적으로 완전하지만 최적이 아닙니다. 예를 들어, 특정 GPU 구성에 따라 병렬화 정도를 늘리거나 줄이기 위해 pipe-parallel-size , model-parallel-size 배치 크기를 수정하기 위해 train_micro_batch_size_per_gpu 또는 gradient-accumulation-steps 와 같은 일부 설정을 변경해야 할 수도 있습니다. 관련 설정 또는 zero_optimization dict는 최적화 프로그램 상태가 작업자 간에 병렬화되는 방식을 수정합니다.
사용 가능한 기능과 구성 방법에 대한 자세한 안내는 구성 README를 참조하고, 가능한 모든 인수에 대한 문서는 configs/neox_arguments.md를 참조하세요.
GPT-NeoX에는 MoE를 위한 여러 전문가 구현이 포함되어 있습니다. 둘 중 하나를 선택하려면 moe_type of megablocks (기본값) 또는 deepspeed 지정하십시오.
둘 다 텐서-전문가-데이터 병렬 처리를 지원하는 DeepSpeed MoE 병렬 처리 프레임워크를 기반으로 합니다. 두 가지 모두 토큰 삭제와 삭제 없이 전환할 수 있습니다(기본값이며 이것이 Megablocks의 목적입니다). Sinkhorn 라우팅이 곧 제공될 예정입니다!
기본 전체 구성의 예는 configs/125M-dmoe.yml(Megablocks 드롭리스의 경우) 또는 configs/125M-moe.yml을 참조하세요.
대부분의 MoE 관련 구성 인수에는 moe 접두사가 붙습니다. 일부 공통 구성 매개변수와 해당 기본값은 다음과 같습니다.
moe_type: megablocks
moe_num_experts: 1 # 1 disables MoE. 8 is a reasonable value.
moe_loss_coeff: 0.1
expert_interval: 2 # See details below
enable_expert_tensor_parallelism: false # See details below
moe_expert_parallel_size: 1 # See details below
moe_token_dropping: false
DeepSpeed는 다음과 같이 추가로 구성할 수 있습니다.
moe_top_k: 1
moe_min_capacity: 4
moe_train_capacity_factor: 1.0 # Setting to 1.0
moe_eval_capacity_factor: 1.0 # Setting to 1.0
하나의 MoE 레이어는 첫 번째 레이어를 포함하여 모든 expert_interval 변환기 레이어에 존재하므로 총 12개의 레이어가 있습니다.
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11
전문가는 다음 레이어에 속합니다.
0, 2, 4, 6, 8, 10
기본적으로 전문가-데이터 병렬성을 사용하므로 사용 가능한 모든 텐서 병렬성( model_parallel_size )이 전문가 라우팅에 사용됩니다. 예를 들어 다음과 같은 경우가 있습니다.
expert_parallel_size: 4
model_parallel_size: 2 # aka tensor parallelism
32개의 GPU를 사용하면 동작은 다음과 같습니다.
expert_parallel_size == model_parallel_size 를 확인하세요. enable_expert_tensor_parallelism 설정하면 TED(텐서-전문가-데이터) 병렬 처리가 활성화됩니다. 위의 내용을 해석하는 방법은 다음과 같습니다.
expert_parallel_size == 1 또는 model_parallel_size == 1 확인하세요.따라서 DP는 (MP * EP)로 나눌 수 있어야 합니다. 자세한 내용은 TED 문서를 참조하세요.
파이프라인 병렬 처리는 아직 지원되지 않습니다. 곧 지원될 예정입니다!
prepare_data.py 진입점을 사용한 간단한 토큰화를 위해 Pile의 대부분 구성 요소와 Pile 열차 세트 자체를 포함하여 사전 구성된 여러 데이터 세트를 사용할 수 있습니다.
EG, GPT2 Tokenizer를 사용하여 enwik8 데이터 세트를 다운로드하고 토큰화하여 ./data 에 저장하려면 다음을 실행할 수 있습니다.
python prepare_data.py -d ./data
또는 GPT-NeoX-20B 토크나이저를 사용하는 파일의 단일 샤드( pile_subset )( ./20B_checkpoints/20B_tokenizer.json 20B_tokenizer.json에 저장했다고 가정):
python prepare_data.py -d ./data -t HFTokenizer --vocab-file ./20B_checkpoints/20B_tokenizer.json pile_subset
토큰화된 데이터는 [data-dir]/[dataset-name]/[dataset-name]_text_document.bin 및 [data-dir]/[dataset-name]/[dataset-name]_text_document.idx 두 파일에 저장됩니다. [data-dir]/[dataset-name]/[dataset-name]_text_document.idx . 이 두 파일이 공유하는 접두사를 data-path 필드 아래의 교육 구성 파일에 추가해야 합니다. 예:
" data-path " : " ./data/enwik8/enwik8_text_document " , 사용자 정의 데이터로 교육할 자체 데이터 세트를 준비하려면 사전 목록의 각 항목이 별도의 문서인 하나의 큰 jsonl 형식 파일로 형식을 지정하세요. 문서 텍스트는 하나의 JSON 키, 즉 "text" 아래에 그룹화되어야 합니다. 다른 필드에 저장된 보조 데이터는 사용되지 않습니다.
다음으로 GPT2 토크나이저 어휘를 다운로드하고 다음 링크에서 파일을 병합하세요.
또는 20B 토크나이저를 사용하십시오(단일 Vocab 파일만 필요함):
(또는 Tokenizer.from_pretrained() 명령을 사용하여 Hugging Face의 토크나이저 라이브러리에서 로드할 수 있는 토크나이저 파일을 제공할 수 있습니다)
이제 tools/datasets/preprocess_data.py 사용하여 데이터를 사전 토큰화할 수 있습니다. 해당 인수는 아래에 자세히 설명되어 있습니다.
usage: preprocess_data.py [-h] --input INPUT [--jsonl-keys JSONL_KEYS [JSONL_KEYS ...]] [--num-docs NUM_DOCS] --tokenizer-type {HFGPT2Tokenizer,HFTokenizer,GPT2BPETokenizer,CharLevelTokenizer} [--vocab-file VOCAB_FILE] [--merge-file MERGE_FILE] [--append-eod] [--ftfy] --output-prefix OUTPUT_PREFIX
[--dataset-impl {lazy,cached,mmap}] [--workers WORKERS] [--log-interval LOG_INTERVAL]
optional arguments:
-h, --help show this help message and exit
input data:
--input INPUT Path to input jsonl files or lmd archive(s) - if using multiple archives, put them in a comma separated list
--jsonl-keys JSONL_KEYS [JSONL_KEYS ...]
space separate listed of keys to extract from jsonl. Default: text
--num-docs NUM_DOCS Optional: Number of documents in the input data (if known) for an accurate progress bar.
tokenizer:
--tokenizer-type {HFGPT2Tokenizer,HFTokenizer,GPT2BPETokenizer,CharLevelTokenizer}
What type of tokenizer to use.
--vocab-file VOCAB_FILE
Path to the vocab file
--merge-file MERGE_FILE
Path to the BPE merge file (if necessary).
--append-eod Append an <eod> token to the end of a document.
--ftfy Use ftfy to clean text
output data:
--output-prefix OUTPUT_PREFIX
Path to binary output file without suffix
--dataset-impl {lazy,cached,mmap}
Dataset implementation to use. Default: mmap
runtime:
--workers WORKERS Number of worker processes to launch
--log-interval LOG_INTERVAL
Interval between progress updates
예를 들어:
python tools/datasets/preprocess_data.py
--input ./data/mydataset.jsonl.zst
--output-prefix ./data/mydataset
--vocab ./data/gpt2-vocab.json
--merge-file gpt2-merges.txt
--dataset-impl mmap
--tokenizer-type GPT2BPETokenizer
--append-eod그런 다음 구성 파일에 다음 설정을 추가하여 교육을 실행합니다.
" data-path " : " data/mydataset_text_document " , 학습은 DeepSpeed 런처의 래퍼인 deepy.py 사용하여 시작됩니다. 이 래퍼는 여러 GPU/노드에서 동일한 스크립트를 병렬로 실행합니다.
일반적인 사용 패턴은 다음과 같습니다.
python ./deepy.py train.py [path/to/config1.yml] [path/to/config2.yml] ...런타임에 모두 병합될 임의 개수의 구성을 전달할 수 있습니다.
선택적으로 구성 접두사를 전달할 수도 있습니다. 그러면 모든 구성이 동일한 폴더에 있다고 가정하고 해당 접두사를 해당 경로에 추가합니다.
예를 들어:
python ./deepy.py train.py -d configs 125M.yml local_setup.yml 그러면 GPU당 하나의 프로세스가 있는 모든 노드에 train.py 스크립트가 배포됩니다. 작업자 노드 및 GPU 수는 /job/hostfile 파일에 지정되거나(매개변수 설명서 참조) 단일 노드 설정에서 실행 중인 경우 num_gpus 인수로 간단히 전달할 수 있습니다.
이것이 반드시 필요한 것은 아니지만 하나의 구성 파일(예: configs/125M.yml )에서 모델 매개변수를 정의하고 다른 구성 파일(예: configs/local_setup.yml )에서 데이터 경로 매개변수를 정의하는 것이 유용하다는 것을 알았습니다.
GPT-NeoX-20B는 Pile에서 훈련된 200억 개의 매개변수 자동 회귀 언어 모델입니다. GPT-NeoX-20B에 대한 기술적인 세부 사항은 관련 논문에서 확인할 수 있습니다. 이 모델의 구성 파일은 ./configs/20B.yml 에서 사용할 수 있으며 아래 다운로드 링크에도 포함되어 있습니다.
슬림한 가중치 - (최적화 상태 없음, 추론 또는 미세 조정용, 39GB)
명령줄에서 20B_checkpoints 폴더로 다운로드하려면 다음 명령을 사용하십시오.
wget --cut-dirs=5 -nH -r --no-parent --reject " index.html* " https://the-eye.eu/public/AI/models/GPT-NeoX-20B/slim_weights/ -P 20B_checkpoints전체 가중치 - (최적화 상태 포함, 268GB)
명령줄에서 20B_checkpoints 폴더로 다운로드하려면 다음 명령을 사용하십시오.
wget --cut-dirs=5 -nH -r --no-parent --reject " index.html* " https://the-eye.eu/public/AI/models/GPT-NeoX-20B/full_weights/ -P 20B_checkpoints가중치는 BitTorrent 클라이언트를 사용하여 다운로드할 수도 있습니다. 토렌트 파일은 여기에서 다운로드할 수 있습니다: slim Weights, Full Weights.
또한 학습 전반에 걸쳐 1,000단계마다 하나씩 150개의 체크포인트가 저장되어 있습니다. 우리는 대규모로 이러한 서비스를 가장 잘 제공할 수 있는 방법을 찾기 위해 노력하고 있지만, 그 동안 부분적으로 훈련된 체크포인트와 협력하는 데 관심이 있는 사람들은 [email protected]로 이메일을 보내 액세스를 조정할 수 있습니다.
Pythia Scaling Suite는 대규모 언어 모델의 해석 가능성 및 훈련 역학에 대한 연구를 촉진하기 위해 Pile에서 훈련된 70M 매개변수에서 12B 매개변수에 이르는 모델 제품군입니다. 프로젝트에 대한 자세한 내용과 모델 링크는 논문 및 프로젝트 GitHub에서 확인할 수 있습니다.
Polyglot 프로젝트는 강력한 비영어 사전 학습 언어 모델을 훈련하여 지배적인 기계 학습 강국 외부의 연구자에게 이 기술의 접근성을 촉진하려는 노력입니다. EleutherAI는 1.3B, 3.8B 및 5.8B 매개변수 한국어 언어 모델을 훈련하고 출시했으며, 이 중 가장 큰 모델은 한국어 작업에 대해 공개적으로 사용 가능한 다른 모든 언어 모델보다 뛰어납니다. 프로젝트에 대한 자세한 내용과 모델 링크는 여기에서 확인할 수 있습니다.
대부분의 경우 추론에 더 잘 최적화된 Hugging Face Transformers 라이브러리를 통해 GPT-NeoX 라이브러리를 사용하여 훈련된 모델을 배포하는 것이 좋습니다.
우리는 사전 학습된 모델에서 세 가지 유형의 생성을 지원합니다.
세 가지 유형의 텍스트 생성은 모두 python ./deepy.py generate.py -d configs 125M.yml local_setup.yml text_generation.yml 통해 시작될 수 있으며 configs/text_generation.yml 에 적절한 값이 설정되어 있습니다.
GPT-NeoX는 언어 모델 평가 하네스를 통해 다운스트림 작업에 대한 평가를 지원합니다.
평가 하네스에서 훈련된 모델을 평가하려면 다음을 실행하면 됩니다.
python ./deepy.py eval.py -d configs your_configs.yml --eval_tasks task1 task2 ... taskn 여기서 --eval_tasks 는 평가 작업 목록이고 그 뒤에 공백이 옵니다(예: --eval_tasks lambada hellaswag piqa sciq . 사용 가능한 모든 작업에 대한 자세한 내용은 lm-evaluation-harness 저장소를 참조하세요.
GPT-NeoX는 훈련에만 최적화되어 있으며 GPT-NeoX 모델 체크포인트는 다른 딥 러닝 라이브러리와 기본적으로 호환되지 않습니다. 모델을 최종 사용자와 쉽게 로드하고 공유할 수 있도록 하고, 추가로 다양한 다른 프레임워크로 내보낼 수 있도록 GPT-NeoX는 Hugging Face Transformers 형식으로의 체크포인트 변환을 지원합니다.
NeoX는 AliBi 위치 임베딩을 포함하여 다양한 아키텍처 구성을 지원하지만 이러한 모든 구성이 Hugging Face Transformers 내에서 지원되는 구성에 깔끔하게 매핑되는 것은 아닙니다.
NeoX는 호환 모델을 다음 아키텍처로 내보내기를 지원합니다.
이러한 Hugging Face Transformers 아키텍처 중 하나에 맞지 않는 모델을 훈련하려면 내보낸 모델에 대한 사용자 정의 모델링 코드를 작성해야 합니다.
GPT-NeoX 라이브러리 체크포인트를 Hugging Face 로드 가능 형식으로 변환하려면 다음을 실행하세요.
python ./tools/ckpts/convert_neox_to_hf.py --input_dir /path/to/model/global_stepXXX --config_file your_config.yml --output_dir hf_model/save/location --precision {auto,fp16,bf16,fp32} --architecture {neox,mistral,llama}그런 다음 Hugging Face Hub에 모델을 업로드하려면 다음을 실행하세요.
huggingface-cli login
python ./tools/ckpts/upload.pyHF 허브 사용자 토큰을 포함하여 요청된 정보를 입력합니다.
NeoX는 사전 학습된 모델 체크포인트를 라이브러리 내에서 학습할 수 있는 형식으로 변환하기 위한 여러 유틸리티를 제공합니다.
다음 모델 또는 모델군을 GPT-NeoX에 로드할 수 있습니다.
우리는 두 가지 다른 체크포인트 형식을 GPT-NeoX와 호환되는 형식으로 변환하기 위한 두 가지 유틸리티를 제공합니다.
Meta AI가 배포한 Llama 1 또는 Llama 2 체크포인트를 원본 파일 형식(여기 또는 여기에서 다운로드 가능)에서 GPT-NeoX 라이브러리로 변환하려면 다음을 실행하세요.
python tools/ckpts/convert_raw_llama_weights_to_neox.py --input_dir /path/to/model/parent/dir/7B --model_size 7B --output_dir /path/to/save/ckpt --num_output_shards <TENSOR_PARALLEL_SIZE> (--pipeline_parallel if pipeline-parallel-size >= 1)
Hugging Face 모델을 NeoX 로드 가능 모델로 변환하려면 tools/ckpts/convert_hf_to_sequential.py 실행하세요. 추가 옵션은 해당 파일 내의 설명서를 참조하세요.
로그를 로컬에 저장하는 것 외에도 우리는 널리 사용되는 두 가지 실험 모니터링 프레임워크인 Weights & Biases, TensorBoard 및 Comet에 대한 기본 지원을 제공합니다.
실험을 기록하는 가중치 및 편향은 기계 학습 모니터링 플랫폼입니다. wandb를 사용하여 gpt-neox 실험을 모니터링하려면 다음을 수행하세요.
wandb login 실행하면 됩니다. 귀하의 달리기는 자동으로 기록됩니다../requirements/requirements-wandb.txt 에서 찾아 설치할 수 있습니다. 예제 구성은 ./configs/local_setup_wandb.yml 에 제공됩니다.wandb_group 사용하면 실행 그룹의 이름을 지정할 수 있고 wandb_team 사용하면 실행을 조직 또는 팀 계정에 할당할 수 있습니다. 예제 구성은 ./configs/local_setup_wandb.yml 에 제공됩니다. tensorboard-dir 필드를 통해 TensorBoard 사용을 지원합니다. TensorBoard 모니터링에 필요한 종속성은 ./requirements/requirements-tensorboard.txt 에서 찾아 설치할 수 있습니다.
Comet은 머신러닝 모니터링 플랫폼입니다. Comet을 사용하여 gpt-neox 실험을 모니터링하려면:
comet login 실행하거나 export COMET_API_KEY=<your-key-here> 전달하여 런타임 시 API 키를 연결하세요.pip install -r requirements/requirements-comet.txt 통해 comet_ml 및 모든 종속성 라이브러리를 설치합니다.use_comet: True 로 Comet을 활성화합니다. comet_workspace 및 comet_project 사용하여 데이터가 기록되는 위치를 사용자 정의할 수도 있습니다. Comet이 활성화된 전체 예제 구성은 configs/local_setup_comet.yml 에 제공됩니다. MPI 기반 DeepSpeed 런처와 함께 사용할 호스트 파일을 제공해야 하는 경우 호스트 파일을 가리키도록 환경 변수 DLTS_HOSTFILE 설정할 수 있습니다.
Nsight Systems, PyTorch 프로파일러 및 PyTorch 메모리 프로파일링을 사용한 프로파일링을 지원합니다.
Nsight 시스템 프로파일링을 사용하려면 구성 옵션 profile , profile_step_start 및 profile_step_stop 설정하십시오(인수 사용법은 여기를 참조하고 샘플 구성은 여기를 참조하십시오).
nsys 측정항목을 채우려면 다음을 사용하여 교육을 시작하세요.
nsys profile -s none -t nvtx,cuda -o <path/to/profiling/output> --force-overwrite true
--capture-range=cudaProfilerApi --capture-range-end=stop python $TRAIN_PATH/deepy.py
$TRAIN_PATH/train.py --conf_dir configs <config files>
생성된 출력 파일은 Nsight Systems GUI를 통해 볼 수 있습니다.
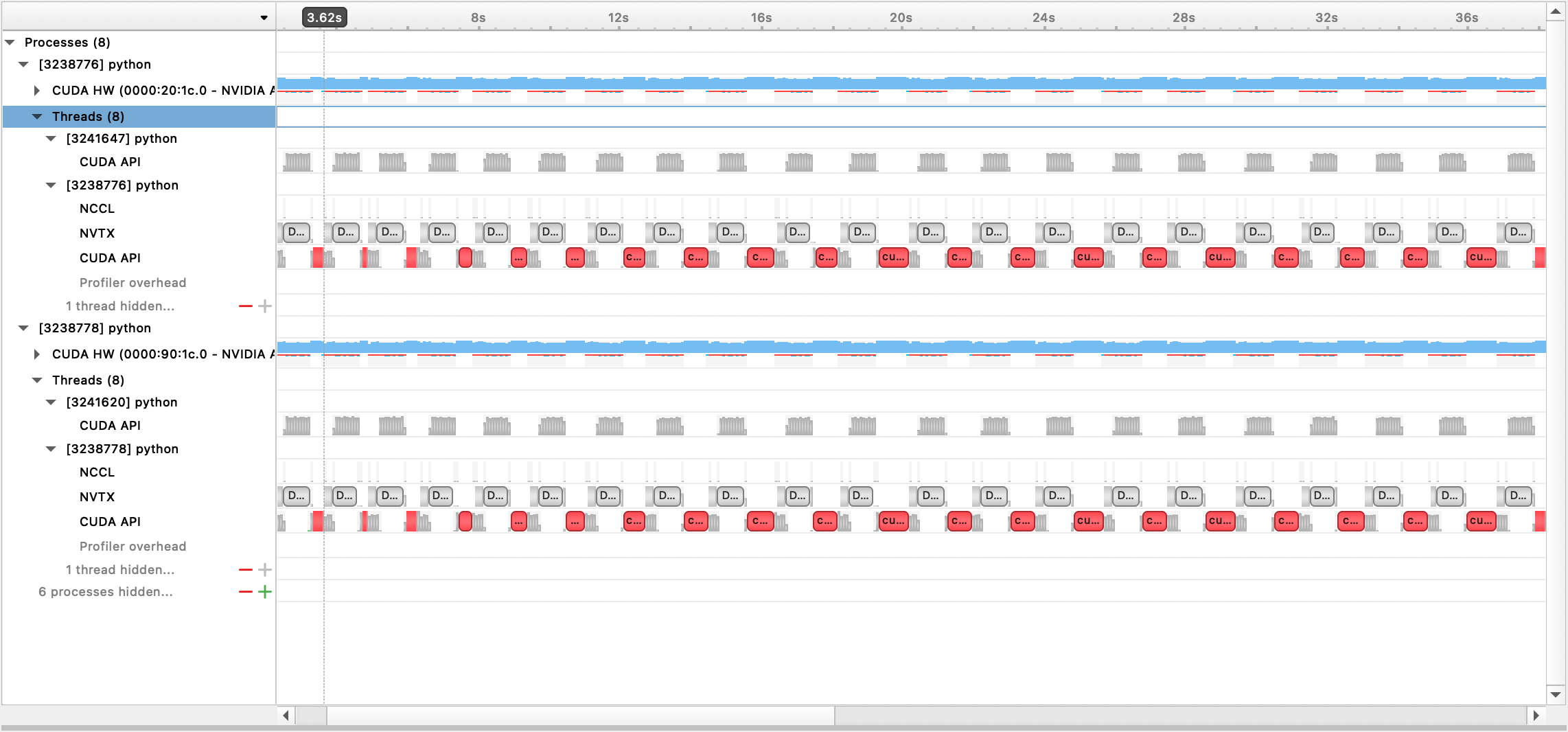
내장된 PyTorch 프로파일러를 사용하려면 구성 옵션 profile , profile_step_start 및 profile_step_stop 설정하십시오(인수 사용법은 여기를 참조하고 샘플 구성은 여기를 참조하십시오).
PyTorch 프로파일러는 tensorboard 로그 디렉터리에 추적을 저장합니다. 여기의 단계에 따라 TensorBoard 내에서 이러한 추적을 볼 수 있습니다.
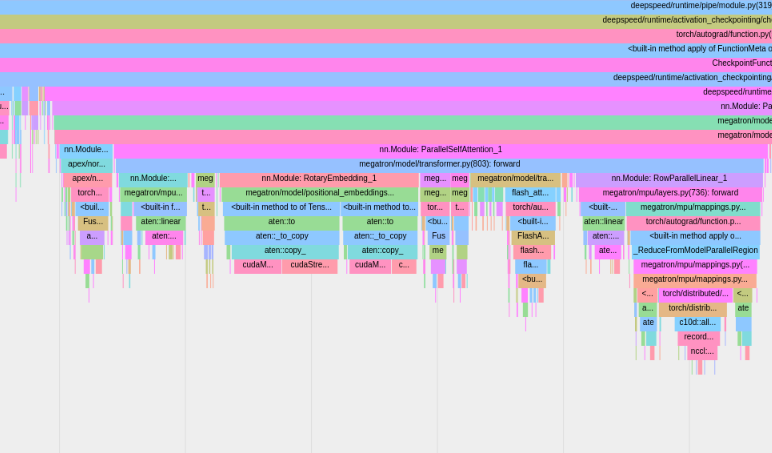
PyTorch 메모리 프로파일링을 사용하려면 구성 옵션 memory_profiling 및 memory_profiling_path 설정하세요(인수 사용법은 여기를 참조하고 샘플 구성은 여기를 참조하세요).
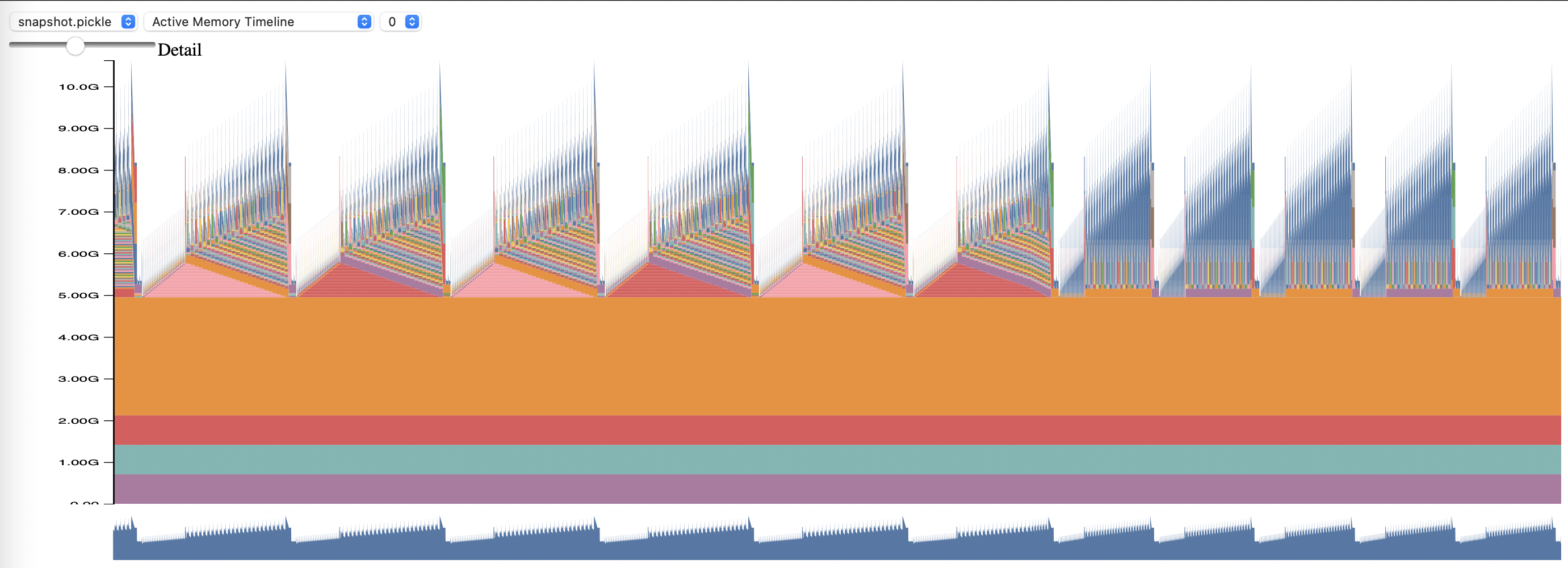
memory_viz.py 스크립트를 사용하여 생성된 프로필을 봅니다. 다음으로 실행:
python _memory_viz.py trace_plot <generated_profile> -o trace.html
GPT-NeoX 라이브러리는 학계 및 업계 연구자들에 의해 널리 채택되었으며 많은 HPC 시스템에 이식되었습니다.
이 라이브러리가 연구에 유용하다고 생각되면 연락하여 알려주십시오! 우리는 당신을 우리 목록에 추가하고 싶습니다.
EleutherAI와 우리의 협력자들은 다음 간행물에서 이를 사용했습니다.
다른 연구 그룹의 다음 출판물에서는 이 라이브러리를 사용합니다.


