visual chatgpt
1.0.0
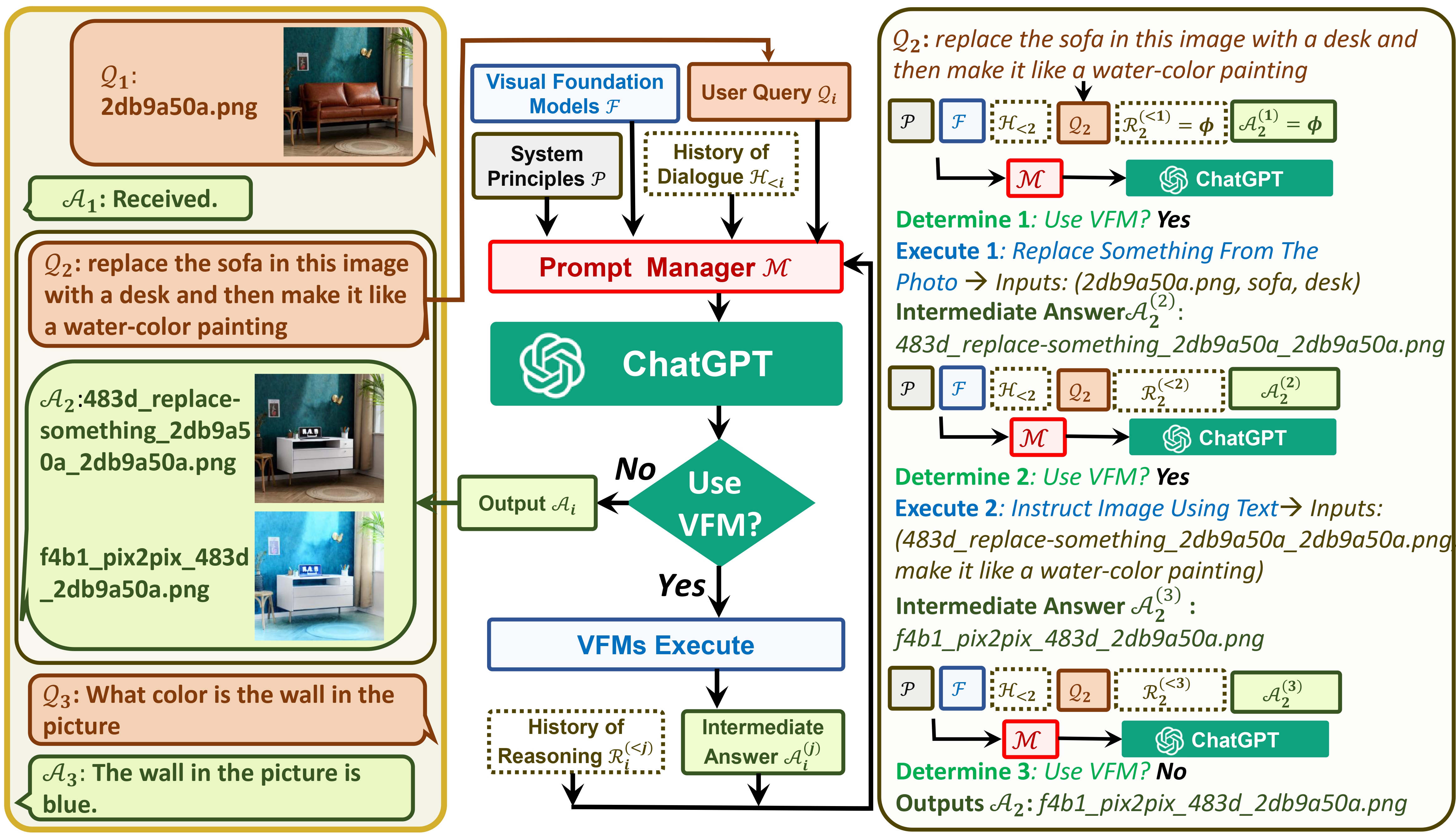
Visual ChatGPT는 ChatGPT와 일련의 Visual Foundation 모델을 연결하여 채팅 중에 이미지를 보내고 받을 수 있도록 합니다.
논문을 참조하세요: Visual ChatGPT: Visual Foundation 모델을 사용한 말하기, 그리기 및 편집
한편으로 ChatGPT(또는 LLM)는 광범위한 주제에 대한 광범위하고 다양한 이해를 제공하는 일반 인터페이스 역할을 합니다. 반면, Foundation Model은 특정 도메인에 대한 깊은 지식을 제공하여 도메인 전문가 역할을 합니다. 일반 지식과 심층 지식을 모두 활용하여 다양한 작업을 처리할 수 있는 AI 구축을 목표로 합니다.

# clone the repo
git clone https://github.com/microsoft/visual-chatgpt.git
# Go to directory
cd visual-chatgpt
# create a new environment
conda create -n visgpt python=3.8
# activate the new environment
conda activate visgpt
# prepare the basic environments
pip install -r requirements.txt
# prepare your private OpenAI key (for Linux)
export OPENAI_API_KEY={Your_Private_Openai_Key}
# prepare your private OpenAI key (for Windows)
set OPENAI_API_KEY={Your_Private_Openai_Key}
# Start Visual ChatGPT !
# You can specify the GPU/CPU assignment by "--load", the parameter indicates which
# Visual Foundation Model to use and where it will be loaded to
# The model and device are sperated by underline '_', the different models are seperated by comma ','
# The available Visual Foundation Models can be found in the following table
# For example, if you want to load ImageCaptioning to cpu and Text2Image to cuda:0
# You can use: "ImageCaptioning_cpu,Text2Image_cuda:0"
# Advice for CPU Users
python visual_chatgpt.py --load ImageCaptioning_cpu,Text2Image_cpu
# Advice for 1 Tesla T4 15GB (Google Colab)
python visual_chatgpt.py --load "ImageCaptioning_cuda:0,Text2Image_cuda:0"
# Advice for 4 Tesla V100 32GB
python visual_chatgpt.py --load "ImageCaptioning_cuda:0,ImageEditing_cuda:0,
Text2Image_cuda:1,Image2Canny_cpu,CannyText2Image_cuda:1,
Image2Depth_cpu,DepthText2Image_cuda:1,VisualQuestionAnswering_cuda:2,
InstructPix2Pix_cuda:2,Image2Scribble_cpu,ScribbleText2Image_cuda:2,
Image2Seg_cpu,SegText2Image_cuda:2,Image2Pose_cpu,PoseText2Image_cuda:2,
Image2Hed_cpu,HedText2Image_cuda:3,Image2Normal_cpu,
NormalText2Image_cuda:3,Image2Line_cpu,LineText2Image_cuda:3"
여기에는 각 시각적 기반 모델의 GPU 메모리 사용량이 나열되어 있으며 원하는 모델을 지정할 수 있습니다.
| 기초 모델 | GPU 메모리(MB) |
|---|---|
| 이미지편집 | 3981 |
| 지시Pix2Pix | 2827 |
| 텍스트2이미지 | 3385 |
| 이미지캡션 | 1209 |
| 이미지2캐니 | 0 |
| CannyText2이미지 | 3531 |
| 이미지2라인 | 0 |
| LineText2이미지 | 3529 |
| Image2Hed | 0 |
| HedText2Image | 3529 |
| Image2스크리블 | 0 |
| 낙서텍스트2이미지 | 3531 |
| Image2Pose | 0 |
| 포즈텍스트2이미지 | 3529 |
| 이미지2세그 | 919 |
| 세그먼트텍스트2이미지 | 3529 |
| 이미지2깊이 | 0 |
| 깊이텍스트2이미지 | 3531 |
| 이미지2일반 | 0 |
| NormalText2이미지 | 3529 |
| 시각적 질문답변 | 1495 |
우리는 다음 프로젝트의 오픈 소스에 감사드립니다.
포옹 얼굴 LangChain 안정적인 확산 ControlNet InstructPix2Pix CLIPSeg BLIP
Visual ChatGPT 사용에 대한 도움이나 문제가 필요한 경우 GitHub 문제를 제출해 주세요.
기타 문의사항은 Chenfei WU([email protected]) 또는 Nan DUAN([email protected])에게 문의하세요.


