TEMPO
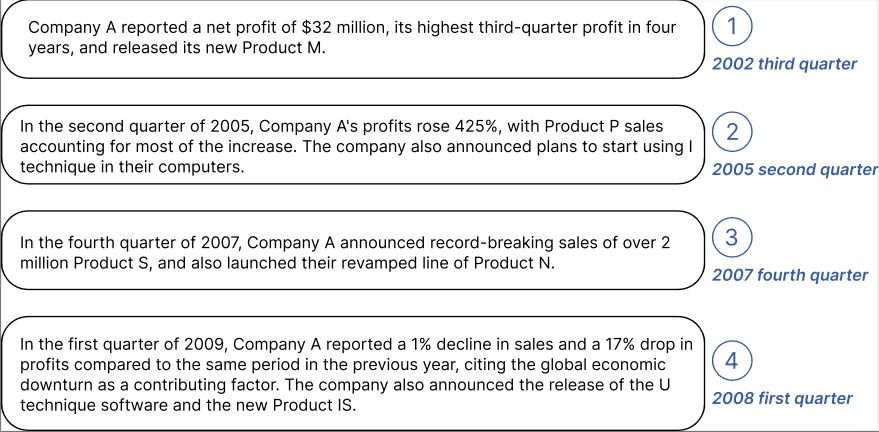
1.0.0

["TEMPO: 시계열 예측을 위한 프롬프트 기반 생성적 사전 훈련된 변환기(ICLR 2024)"]의 공식 코드입니다.
TEMPO는 예측 작업 v1.0 버전을 위한 최초의 오픈 소스 시계열 기반 모델 중 하나입니다.
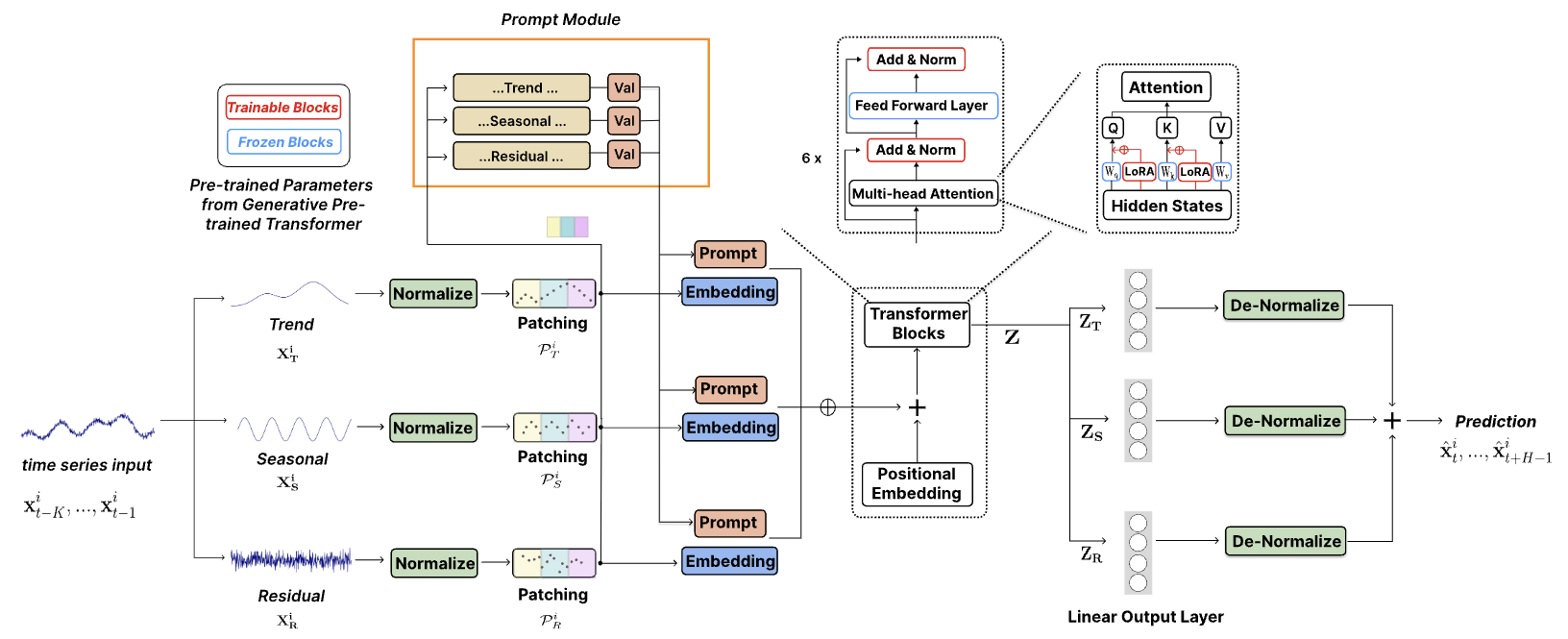
2024년 10월 : 사용자가 사전 훈련된 모델을 다운로드하고 코드 한 줄로 제로샷 추론을 수행할 수 있도록 코드 구조를 간소화했습니다! 자세한 내용은 데모를 확인하세요. 이제 HuggingFace에서 모델의 다운로드 횟수를 추적할 수 있습니다!
2024년 6월 : Colab에서 제로샷 실험을 재현하기 위한 데모를 추가했습니다. 또한 고객 데이터 세트를 구축하고 사전 학습된 기초 모델인 Colab을 통해 직접 추론을 수행하는 데모도 추가했습니다.
2024년 5월 : TEMPO는 사용자가 기초 모델과 직접 상호 작용할 수 있는 GUI 기반 온라인 데모를 출시했습니다!
2024년 5월 : TEMPO는 HuggingFace에 80M 사전 학습된 기초 모델을 게시했습니다!
2024년 5월 : ? 사전 훈련 및 추론 TEMPO 모델을 위한 코드를 추가했습니다. 이 폴더에서 사전 학습 스크립트 데모를 찾을 수 있습니다. 추론 데모를 위한 스크립트도 추가했습니다.
2024년 3월 : ? TEMPO의 다중 모드 실험에 사용되는 S&P 500의 TETS 데이터 세트를 출시했습니다.
2024년 3월 : ? TEMPO가 프로젝트 코드와 사전 학습된 체크포인트를 온라인에 공개했습니다!
2024년 1월 : TEMPO 논문이 ICLR에 승인되었습니다!
2023년 10월 : Arxiv에 TEMPO 논문이 공개되었습니다!
conda create -n tempo python=3.8
conda activate tempo
pip install -r requirements.txt
TEMPO를 사용하여 예측을 수행하는 방법을 보여주는 간소화된 예:
# Third-party library imports
import numpy as np
import torch
from numpy . random import choice
# Local imports
from models . TEMPO import TEMPO
model = TEMPO . load_pretrained_model (
device = torch . device ( 'cuda:0' if torch . cuda . is_available () else 'cpu' ),
repo_id = "Melady/TEMPO" ,
filename = "TEMPO-80M_v1.pth" ,
cache_dir = "./checkpoints/TEMPO_checkpoints"
)
input_data = np . random . rand ( 336 ) # Random input data
with torch . no_grad ():
predicted_values = model . predict ( input_data , pred_length = 96 )
print ( "Predicted values:" )
print ( predicted_values )ETTh2[여기 Colab]에서 제로샷 실험을 재현해 보세요.
다음 Colab 페이지를 사용하여 고객 데이터 세트 구축 데모를 보여주고 사전 훈련된 기초 모델을 통해 직접 추론을 수행합니다. [Colab]
[여기]에서 기초 모델 데모를 사용해 보세요.
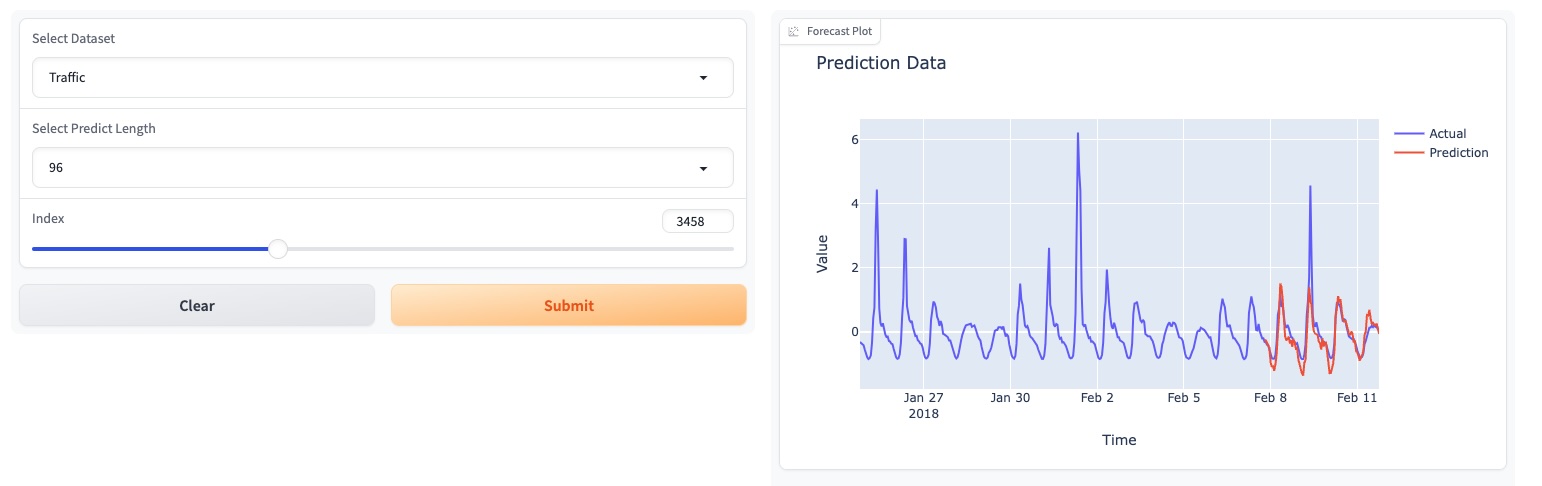
HuggingFace: [Melady/TEMPO]에서도 모델을 업데이트했습니다.
[Google Drive] 또는 [Baidu Drive]에서 데이터를 다운로드하고, 다운로드한 데이터를 ./dataset 폴더에 넣습니다. [Google Drive]에서 STL 결과를 다운로드할 수도 있으며, 다운로드한 데이터를 ./stl 폴더에 넣을 수도 있습니다.
bash [ecl, etth1, etth2, ettm1, ettm2, traffic, weather].sh
훈련 후에는 제로샷 설정에서 TEMPO 모델을 테스트할 수 있습니다.
bash [ecl, etth1, etth2, ettm1, ettm2, traffic, weather]_test.sh
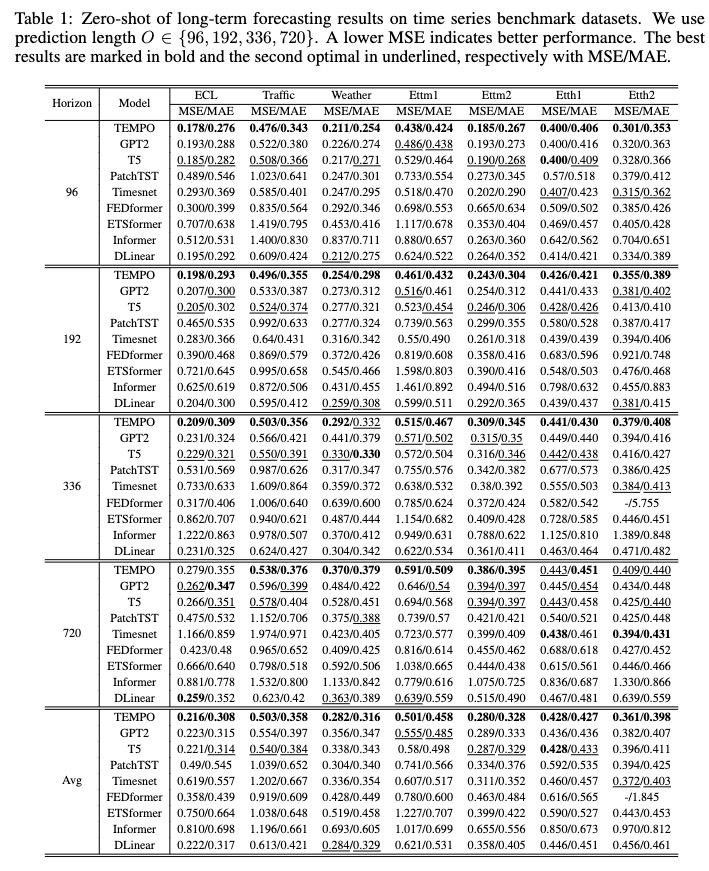
[Google Drive]에서 사전 학습된 모델을 다운로드한 후 테스트 스크립트를 재미있게 실행할 수 있습니다.
다음은 [OPENAI ChatGPT-3.5 API]를 통해 시계열의 해당 텍스트 정보를 생성하는 데 사용되는 프롬프트입니다.

시계열 데이터는 [S&P 500]에서 가져왔습니다. 다음은 데이터세트에 있는 한 회사의 EBITDA 사례입니다.
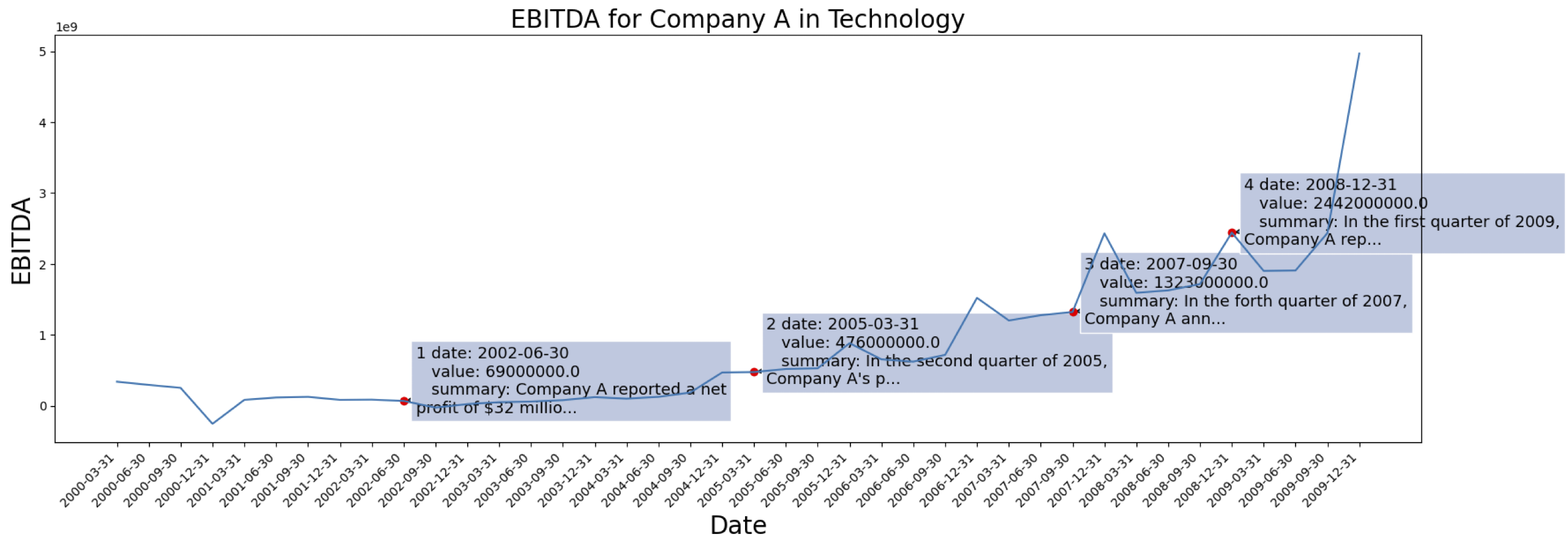
위에 표시된 회사에 대해 생성된 상황 정보의 예:
GPT2에서 텍스트 삽입이 포함된 처리된 데이터를 [TETS]에서 다운로드할 수 있습니다.
실제 응용 프로그램에 TEMPO를 적용하는 데 관심이 있다면 언제든지 [email protected] / [email protected]에 연결하세요.
@inproceedings{
cao2024tempo,
title={{TEMPO}: Prompt-based Generative Pre-trained Transformer for Time Series Forecasting},
author={Defu Cao and Furong Jia and Sercan O Arik and Tomas Pfister and Yixiang Zheng and Wen Ye and Yan Liu},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=YH5w12OUuU}
}
@article{
Jia_Wang_Zheng_Cao_Liu_2024,
title={GPT4MTS: Prompt-based Large Language Model for Multimodal Time-series Forecasting},
volume={38},
url={https://ojs.aaai.org/index.php/AAAI/article/view/30383},
DOI={10.1609/aaai.v38i21.30383},
number={21},
journal={Proceedings of the AAAI Conference on Artificial Intelligence},
author={Jia, Furong and Wang, Kevin and Zheng, Yixiang and Cao, Defu and Liu, Yan},
year={2024}, month={Mar.}, pages={23343-23351}
}


