verslibre
1.0.0
저장소에는 GPT 아키텍처를 갖춘 생성 언어 모델을 사용하여 짧은 시를 생성하기 위한 코드가 포함되어 있습니다.
GPT 아키텍처를 기반으로 한 변형 언어 모델이 사용됩니다. 이 모델은 러시아어의 문법(ruugpt와 같은 언어 모델과 유사)과 운율 규칙 및 시 운율 구성을 포함한 음성학을 모두 고려합니다. 자세한 내용은 프레젠테이션에 나와 있습니다.
모델 바이너리는 inkoziev/verslibre:latest docker 이미지에서 사용할 수 있습니다.
이미지를 다운로드하고 실행합니다.
sudo docker pull inkoziev/verslibre:latest
sudo docker run -it inkoziev/verslibre:latest
실행 후 프로그램은 텔레그램 봇에 대한 토큰을 입력하라는 메시지를 표시합니다.
모든 모델을 로드한 후 /start 명령을 사용하여 채팅에서 봇을 시작할 수 있습니다. 봇은 에세이에 대한 세 가지 무작위 주제 중 하나를 선택하거나 자신의 주제를 입력하도록 요청할 것입니다. 주제는 "시 생성기"와 같이 명사가 주역으로 있는 모든 문구가 될 수 있습니다.
이 봇은 @verslibre_bot으로 텔레그램에서 사용할 수 있습니다.
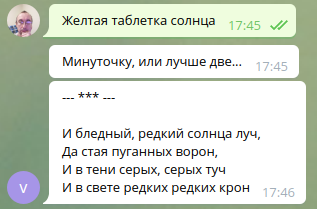
생성 예:
* * *
Любовь - источник вдохновения,
Души непризнанных людей.
И день весеннего цветения,
Омытый зеленью дождей…
* * *
Душа, гонимая страстями,
Тревожит, веет теплотой.
Любовь, хранимая стихами,
И примиренье, и покой.
생성 모델 자체 외에도 모델 훈련을 위한 소스 시를 표시하는 시 전사기는 올바른 작동을 위해 매우 중요합니다. 여기에서 전사자의 작업에 대해 자세히 알아볼 수 있습니다.
도커 이미지 inkoziev/haiku:latest를 사용하여 생성기를 텔레그램 봇으로 실행할 수 있습니다.
이미지를 다운로드하고 다음을 실행합니다.
sudo docker pull inkoziev/haiku:latest
sudo docker run -it inkoziev/haiku
프로그램은 텔레그램 봇 토큰을 입력하라는 메시지를 표시합니다. 그런 다음 모델이 로드되고(약 1분) 봇과 통신할 수 있습니다. 시드(명사 또는 구문)를 입력하세요. CPU에서 여러 옵션을 생성하는 데 약 30초가 걸립니다. 그런 다음 봇은 첫 번째 옵션을 표시하고 이를 평가하거나 다음 옵션을 표시합니다.
이 봇은 텔레그램에서 @haiku_guru_bot으로 제공됩니다.
이는 무작위 생성 모델이므로 일반적으로 동일한 시드를 도입하는 것만으로는 결과를 복제할 수 없습니다. 좋은 결과를 복사하고 ruDALLE와 같은 예시 모델로 보완하여 완전히 고유한 콘텐츠를 얻으세요.

하이쿠의 더 많은 예는 내 블로그에서 볼 수 있습니다.
tmp 하위 디렉터리에는 훈련 데이터의 일부가 포함된 파일이 포함되어 있습니다.
poem_corpus.txt - 필터링된 quatrains의 말뭉치, 기호 | 줄 구분자로; ruGPT 모델의 추가 교육에 사용됩니다.
poem_generator_dataset.dat - 주제(핵심 문구)별로 시 텍스트를 생성하는 ruGPT 학습용 데이터세트입니다.
captions_generator_rugpt.dat - ruGPT 훈련을 위한 데이터 세트로, 내용을 기반으로 구절 제목을 생성합니다.
훈련병 준비 과정에 대한 설명은 여기에서 확인할 수 있습니다.


