Awesome Attention Heads
vey on LLM attention heads
중요한
이 저장소에 대해. 이것은 다양한 종류의 LLM Attention Heads에 대한 최신 연구를 얻을 수 있는 플랫폼입니다. 또한, 우리는 이러한 환상적인 작품을 바탕으로 설문 조사를 발표했습니다.
우리 작업을 인용 하려면 여기에 bibtex 항목인 CITATION.bib를 입력하세요.
관련 논문 목록 만 보시려면 여기로 바로 이동해주세요.
이 repo에 기여하고 싶다면 여기를 참고하세요.
LLM(대형 언어 모델)의 개발과 함께 기본 네트워크 구조인 Transformer가 광범위하게 연구되고 있습니다. Transformer 구조를 연구하면 이 "블랙박스"에 대한 이해를 높이고 모델 해석성을 향상시키는 데 도움이 됩니다. 최근에는 모델에 행동, 추론, 분석에 사용되는 주의 메커니즘과 지식 저장을 위한 FFN(Feed-Forward Network)이라는 두 가지 별개의 파티션이 포함되어 있음을 시사하는 연구가 늘어나고 있습니다. 전자는 모델의 기능적 능력을 드러내는 데 중요하며, 이를 Attention Head Mining 이라고 부르는 주의 메커니즘 내의 다양한 기능을 탐구하는 일련의 연구로 이어집니다.
이 설문 조사에서 우리는 LLM의 관심 머리가 추론 과정에 어떻게 기여하는지에 대한 잠재적인 메커니즘을 조사합니다.
하이라이트:
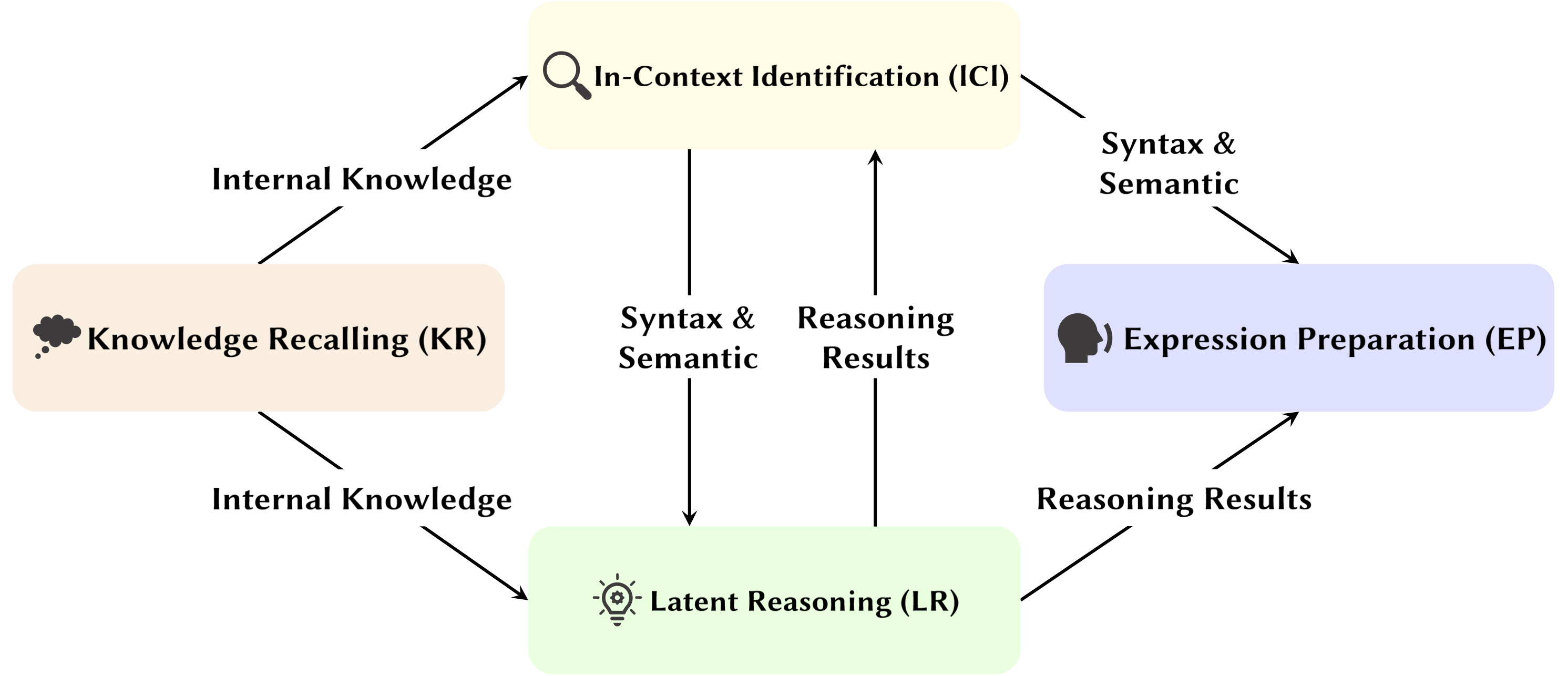
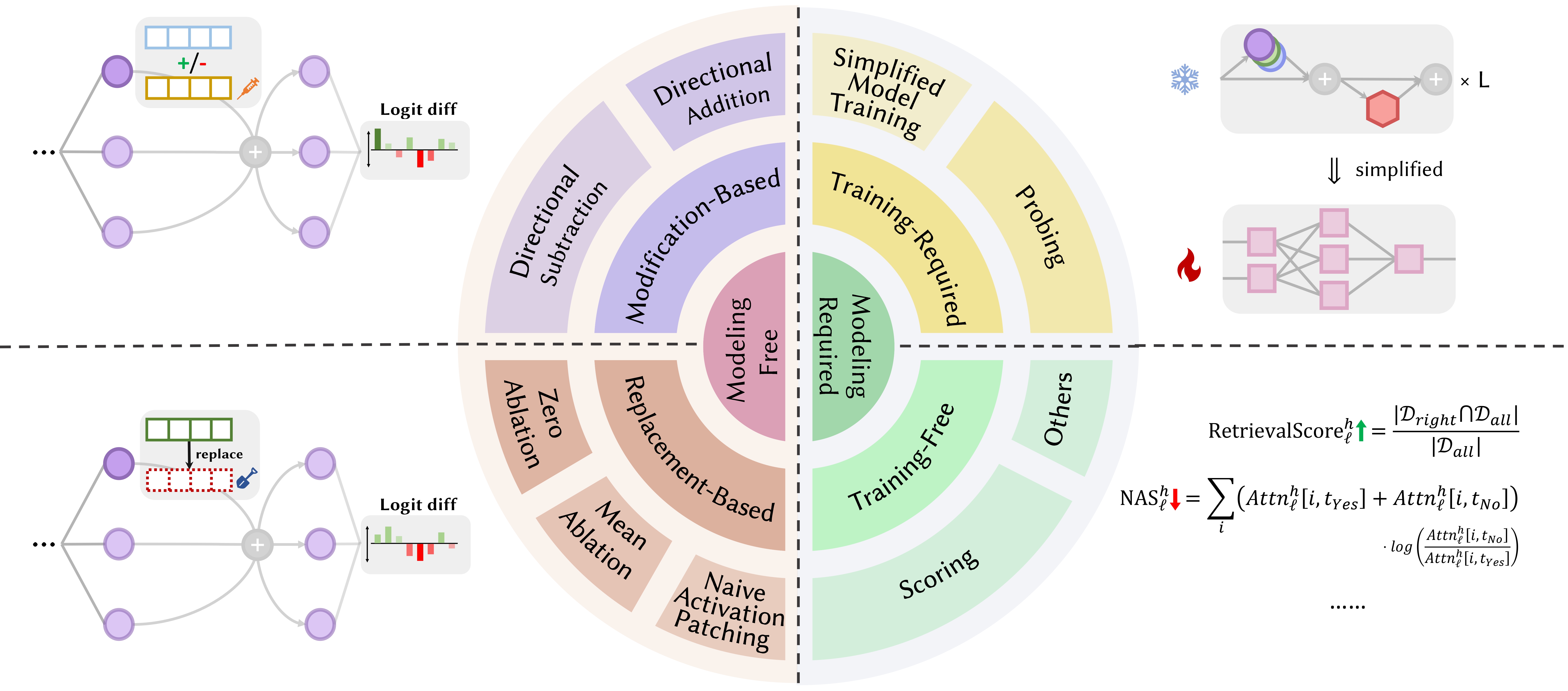
아래 논문은 출판 날짜순 으로 정렬됩니다.
2024년
| 날짜 | 논문 및 요약 | 태그 | 모래밭 |
| 2024-11-15 | SEEKR: 대규모 언어 모델의 지속적인 학습을 위한 선택적 주의 유도 지식 보유 | ||
| • 효율적인 증류를 위해 핵심 관심 헤드에 초점을 맞춘 LLM의 지속적인 학습을 위한 선택적 주의 유도 지식 보유 방법인 SEEKR을 제안합니다. • 지속적인 학습 벤치마크인 TRACE 및 SuperNI에서 평가되었습니다. • SEEKR은 다른 방법에 비해 단 1%의 재생 데이터만으로 유사하거나 더 나은 성능을 달성했습니다. | |||
| 2024-11-06 | Transformer가 명제 논리 문제를 해결하는 방법: 기계적 분석 | ||
| • "계획" 및 "추론" 메커니즘에 중점을 두고 명제 논리 문제를 해결하는 변압기의 특정 주의 회로를 식별합니다. • 추론 경로를 밝히기 위해 활성화 패치를 사용하여 소형 변압기 및 Mistral-7B를 분석했습니다. • 논리적 추론에서 규칙 위치, 사실 처리 및 의사 결정을 전문으로 하는 뚜렷한 주의 헤드를 찾았습니다. | |||
| 2024-11-01 | 주의 추적기: LLM에서 즉각적인 주입 공격 감지 | ||
| • 식별된 중요 헤드를 기반으로 즉각적인 주입 공격을 탐지하는 간단하면서도 효과적인 훈련이 필요 없는 가드인 주의 추적기를 제안합니다. • 순진한 무시 공격과 결합된 LLM 생성 임의 문장의 작은 집합을 사용하여 중요한 헤드를 식별했습니다. • Attention Tracker는 소규모 및 대규모 LM 모두에 효과적이며 이전의 훈련 없는 감지 방법의 중요한 한계를 해결합니다. | |||
| 2024-10-28 | 알고리즘 없는 산술: 언어 모델은 휴리스틱으로 수학을 해결합니다. | ||
| • 기본 산술 논리에 대한 모델 동작의 대부분을 설명하고 해당 기능을 검사하는 모델(회로)의 하위 집합을 식별했습니다. • 아라비아 숫자와 4개의 기본 연산자(+, −, ×, ¼)가 포함된 2개의 피연산자 산술 프롬프트를 사용하여 주의 패턴을 분석했습니다. • 덧셈, 뺄셈, 나눗셈의 경우 6개의 어텐션 헤드가 높은 충실도(평균 97%)를 산출하는 반면, 곱셈은 90%를 초과하려면 20개의 헤드가 필요합니다. | |||
| 2024-10-21 | 인수 역할에 대한 언어 모델의 민감도에 대한 심리언어학적 평가 | ||
| • 좀 더 일반화된 환경에서 피사체의 머리를 관찰했습니다. • 교환인수와 대체인수 조건에서 주의 패턴을 분석했습니다. • 역할을 구별할 수 있음에도 불구하고 모델은 논증 역할 정보를 올바르게 사용하는 데 어려움을 겪을 수 있습니다. 문제는 이 정보가 동사 표현으로 인코딩되는 방식에 있어 역할 민감도가 약해지기 때문입니다. | |||
| 2024-10-17 | 활성-휴면 주의 헤드: LLM의 극단적인 토큰 현상을 기계적으로 이해하기 | ||
| • 사전 훈련 중 상호 강화 메커니즘과 결합된 주의 헤드의 활성 휴면 메커니즘에서 극단적인 토큰 현상이 발생한다는 것이 입증되었습니다. • BB(Bigram-Backcopy) 작업에 대해 교육된 단순 변환기를 사용하여 극단적인 토큰 현상을 분석하고 이를 사전 교육된 LLM으로 확장합니다. • BB 작업에 의해 예측된 극단적인 토큰 현상의 정적 및 동적 속성 중 다수는 사전 훈련된 LLM의 관찰과 일치합니다. | |||
| 2024-10-17 | 대형 언어 모델 안전에서 주의 머리의 역할 | ||
| • 모델 안전에 대한 개별 헤드의 기여도를 평가하기 위해 다중 헤드 주의에 맞춘 새로운 측정 기준인 안전 헤드 중요 점수(선박)를 제안했습니다. • 이러한 안전 주의 헤드의 기능에 대한 분석을 수행하고 그 특성과 메커니즘을 조사했습니다. • 특정 주의 헤드는 안전에 매우 중요하며, 안전 헤드는 미세 조정된 모델 전반에 걸쳐 겹치며, 이러한 헤드를 제거해도 유용성에 최소한의 영향을 미칩니다. | |||
| 2024-10-14 | DuoAttention: 검색 및 스트리밍 헤드를 사용한 효율적인 장기 컨텍스트 LLM 추론 | ||
| • LLM 내의 검색 헤드 및 스트리밍 헤드 검색을 기반으로 장기 컨텍스트 기능을 손상시키지 않으면서 LLM의 디코딩과 메모리 사전 채우기 및 대기 시간을 모두 줄이는 프레임워크인 DuoAttention을 도입했습니다. • 단기 컨텍스트 및 장기 컨텍스트 작업 모두에서 LLM의 성능과 추론 효율성에 대한 프레임워크의 영향을 테스트합니다. • 검색 헤드에만 전체 KV 캐시를 적용함으로써 DuoAttention은 긴 컨텍스트 애플리케이션에서 디코딩 및 사전 채우기 모두에 대한 메모리 사용량과 대기 시간을 크게 줄입니다. | |||
| 2024-10-14 | 미세 조정된 LLM 안전 잠금 | ||
| • LLM 내의 안전 헤드 검색을 기반으로 다양한 위험 수준과 공격 시나리오에서 미세 조정된 대규모 언어 모델의 안전을 유지하기 위한 새롭고 효율적인 방법인 SafetyLock을 도입했습니다. • 모델 안전성과 추론 효율성을 향상시키는 데 있어 SafetyLock의 효과를 평가합니다. • SafetyLock은 안전 헤드에 개입 벡터를 적용하여 추론 중에 무해한 방향으로 모델의 내부 활성화를 수정하여 반응에 미치는 영향을 최소화하면서 정밀한 안전 정렬을 달성할 수 있습니다. | |||
| 2024-10-11 | 동일하지만 다름: 다국어 언어 모델링의 구조적 유사점과 차이점 | ||
| • 언어별 형태학적 프로세스가 필요한 작업을 수행할 때 다국어 모델이 의존하는 특정 구성 요소에 대한 심층적인 연구를 수행했습니다. • 영어와 중국어로 작업을 수행할 때 내부 모델 구성 요소의 기능적 차이점을 조사합니다. • 카피 헤드는 두 언어 모두에서 비슷하게 높은 활성화 빈도를 갖는 반면, 과거 시제 헤드는 영어에서만 자주 활성화됩니다. | |||
| 2024-10-08 | 빙글빙글 우리는 간다! 로터리 위치 인코딩이 유용한 이유는 무엇입니까? | ||
| • RoPE가 기계 수준에서 어떻게 사용되는지 이해하기 위해 훈련된 Gemma 7B 모델의 내부에 대한 심층 분석을 제공합니다. • 쿼리와 키의 다양한 빈도 사용을 이해했습니다. • RoPE의 가장 높은 주파수는 특별한 '위치' 어텐션 헤드(대각선 헤드, 이전 토큰 헤드)를 구성하기 위해 Gemma 7B에서 교묘하게 사용되는 반면, 낮은 주파수는 아포스트로피 헤드에서 사용된다는 사실을 발견했습니다. | |||
| 2024-10-06 | 대규모 언어 모델에서 상황 내 학습 추론 회로 재검토 | ||
| • ICL의 추론 프로세스를 특성화하기 위한 포괄적인 3단계 추론 회로를 제안했습니다. • ICL을 요약, 의미 병합, 기능 검색 및 복사의 세 단계로 나누어 각 단계가 ICL에서 수행하는 역할과 운영 메커니즘을 분석합니다. • Induction 헤드 이전에 Forerunner Token Heads는 먼저 데모와 레이블 의미 간의 호환성을 기반으로 Forerunner 토큰의 데모 텍스트 표현을 해당 레이블 토큰에 선택적으로 병합한다는 사실을 발견했습니다. | |||
| 2024-10-01 | 희소 주의 분해(Sparse Attention Decomposition)를 회로 추적에 적용 | ||
| • GPT-2 모델에서 통신 경로를 추적하기 위해 주의 헤드 매트릭스에 SVD를 사용하는 희소 주의 분해(Sparse Attention Decomposition)를 도입합니다. • IOI(간접 개체 식별) 작업을 위해 GPT-2 소형의 회로 추적에 적용됩니다. • 주의 헤드 간의 희소하고 기능적으로 중요한 통신 신호를 식별하여 해석 가능성을 향상시킵니다. | |||
| 2024-09-09 | 인덕션 헤드 공개: 변압기의 입증 가능한 훈련 역학 및 기능 학습 | ||
| • 이 논문에서는 일반화된 유도 헤드 메커니즘을 소개하고 변환기 구성 요소가 협력하여 n-gram Markov 체인에서 ICL(in-context learning)을 수행하는 방법을 설명합니다. • Markov 체인의 토큰을 예측하기 위해 경사 흐름을 사용하여 2개의 주의 계층 변환기를 분석합니다. • 그라데이션 흐름이 수렴되어 학습된 기능 기반 유도 헤드 메커니즘을 통해 ICL이 가능해집니다. | |||
| 2024-08-16 | 자동 회귀 언어 모델의 삼단논법 추론에 대한 기계적 해석 | ||
| • 이 연구는 LM의 삼단논법 추론에 대한 기계적인 해석을 소개하고 내용 독립적인 추론 회로를 식별합니다. • 어텐션 헤드의 신념 편향 오염을 추론하고 조사하기 위한 회로 발견. • 삼단논법 체계를 통해 전환할 수 있지만 사전 훈련된 세계 지식으로 인해 오염되기 쉬운 필수 추론 회로를 식별했습니다. | |||
| 2024-08-01 | 모델 편집을 통해 대규모 언어 모델의 의미적 일관성 강화: 해석 가능성 중심 접근 방식 | ||
| • 광범위한 매개변수 변경 없이 LLM의 의미론적 일관성을 향상시키기 위해 주의 헤드에 초점을 맞춘 비용 효율적인 모델 편집 접근 방식을 도입합니다. • 어텐션 헤드를 분석하고 편향을 주입했으며 NLU 및 NLG 데이터 세트에서 테스트했습니다. • 추가 작업 전반에 걸쳐 강력한 일반화를 통해 의미론적 일관성과 작업 성능이 눈에 띄게 향상되었습니다. | |||
| 2024-07-31 | 부정적인 주의 점수 정렬을 통해 대규모 언어 모델의 부정적인 편견 수정 | ||
| • 언어 모델의 부정적인 편견을 정량화하고 수정하기 위해 NAS(Negative Attention Score)를 도입했습니다. • 부정적으로 편향된 주의 헤드를 식별하고 미세 조정을 위해 NASA(Negative Attention Score Alignment)를 제안했습니다. • NASA는 이진 결정 작업에서 일반화를 유지하면서 정밀도-재현율 격차를 효과적으로 줄였습니다. | |||
| 2024-07-29 | 기계적 해석을 통한 언어 모델의 취약점 감지 및 이해 | ||
| • LLM의 취약성, 특히 적대적 공격을 감지하고 이해하기 위해 MI(Mechanistic Interpretability)를 사용하는 방법을 소개합니다. • 3글자 약어 예측의 취약점에 대해 GPT-2 Small을 분석합니다. • 작업과 관련된 모델의 특정 취약점을 성공적으로 식별하고 설명합니다. | |||
| 2024-07-22 | RazorAttention: 검색 헤드를 통한 효율적인 KV 캐시 압축 | ||
| • 중요한 토큰 정보를 보존하기 위해 검색 헤드와 보상 토큰을 사용하는 교육이 필요 없는 KV 캐시 압축 기술인 RazorAttention을 도입했습니다. • 효율성을 위해 대규모 언어 모델(LLM)에서 RazorAttention을 평가했습니다. • 눈에 띄는 성능 영향 없이 KV 캐시 크기를 70% 이상 줄였습니다. | |||
| 2024-07-21 | 답변, 조립, 에이스: Transformer가 객관식 질문에 답변하는 방법 이해 | ||
| • 이 논문에서는 올바른 MCQA 답변을 예측하는 숨겨진 상태를 지역화하기 위한 어휘 투영 및 활성화 패치를 소개합니다. • 변환기에서 답변 선택을 담당하는 핵심 주의 헤드 및 계층을 식별했습니다. • 중간 계층 주의 헤드는 정확한 답변 예측에 중요하며, 희박한 헤드 세트가 고유한 역할을 수행합니다. | |||
| 2024-07-09 | 상황 내 학습에서 패턴 매칭을 위한 필수 메커니즘인 유도 헤드 | ||
| • 이 기사에서는 유도 헤드가 상황 내 학습(ICL)의 패턴 일치에 매우 중요하다고 식별합니다. • 추상 패턴 인식 및 NLP 작업에 대해 Llama-3-8B 및 InternLM2-20B를 평가했습니다. • 유도 헤드를 제거하면 ICL 성능이 최대 32%까지 감소하여 패턴 인식이 무작위에 가까워집니다. | |||
| 2024-07-02 | 비교 뉴런 분석을 통한 대규모 언어 모델의 산술 메커니즘 해석 | ||
| • 대규모 언어 모델의 Attention Head에서 산술 메커니즘을 매핑하기 위해 CNA(Comparative Neuron Analysis)를 도입합니다. • 산술 능력 분석, 산술 작업을 위한 모델 가지치기, 모델 편집을 통해 성별 편견을 줄였습니다. • 산술을 담당하는 특정 뉴런을 식별하여 표적화된 뉴런 조작을 통해 성능 개선 및 편향 완화를 가능하게 합니다. | |||
| 2024-07-01 | 다국어 정보 검색을 위한 대규모 언어 모델 조정 | ||
| • 향상된 교차 언어 정보 검색을 위해 LLM을 안내하기 위해 조정 활성화를 사용하는 ASMR(Activation Steered Multilingual Retrieval)을 도입합니다. • 정확성과 언어 일관성에 영향을 미치는 LLM의 주의 헤드를 식별하고 조정 활성화를 적용했습니다. • ASMR은 XOR-TyDi QA 및 MKQA와 같은 CLIR 벤치마크에서 최첨단 성능을 달성했습니다. | |||
| 2024-06-25 | Transformer가 경사하강법을 사용하여 인과 구조를 학습하는 방법 | ||
| • 변환기가 경사 기반 훈련 알고리즘을 통해 인과 구조를 학습하는 방법에 대한 설명을 제공했습니다. • 인과 구조가 있는 무작위 시퀀스라는 작업에서 2층 변환기의 성능을 분석했습니다. • 단순화된 2계층 변환기의 경사하강법은 첫 번째 Attention 계층의 잠재 인과 그래프를 인코딩하여 이 작업을 해결하는 방법을 학습합니다. 특별한 경우로, 컨텍스트 내 Markov 체인에서 시퀀스가 생성되면 변환기는 유도 헤드를 개발하는 방법을 학습합니다. | |||
| 2024-06-21 | MoA: 자동 대형 언어 모델 압축을 위한 Sparse Attention의 혼합 | ||
| • 이 백서에서는 다양한 헤드와 레이어에 대해 고유한 희소 주의 구성을 맞춤화하고 메모리, 처리량 및 정확도-지연 시간 균형을 최적화하는 MoA(Mixture of Attention)를 소개합니다. • MoA는 모델을 프로파일링하고 주의 구성을 탐색하며 LLM 압축을 개선합니다. • MoA는 유효 컨텍스트 길이를 3.9배 늘리는 동시에 GPU 메모리 사용량을 1.2~1.4배 줄입니다. | |||
| 2024-06-19 | 대규모 언어 모델에서 충실한 사고 사슬 추론의 어려움 | ||
| • LLM의 CoT(사고 사슬) 추론 충실도를 향상시키기 위해 상황 내 학습, 미세 조정 및 활성화 편집을 위한 새로운 전략을 도입했습니다. • 여러 벤치마크에서 이러한 전략을 테스트하여 효율성을 평가했습니다. • CoT 충실도를 향상시키는 데 제한적인 성공을 거두었으며 LLM에서 진정으로 충실한 추론을 달성하는 데 어려움이 있음을 강조합니다. | |||
| 2024-06-04 | 반복 헤드: 사고 사슬의 기계적 연구 | ||
| • CoT(사고 사슬) 작업을 위해 변환기에서 반복적 추론을 가능하게 하는 특수 주의 헤드인 "반복 헤드"를 도입합니다. • 주의 메커니즘 분석, CoT 출현 추적 및 CoT 기술의 작업 간 이전 가능성 테스트. • 반복 헤드는 CoT 추론을 효과적으로 지원하여 모델 해석 가능성 및 작업 성능을 향상시킵니다. | |||
| 2024-06-03 | LoFiT: LLM 표현의 현지화된 미세 조정 | ||
| • 주어진 작업의 중요한 주의 헤드를 식별하고 식별된 헤드의 표현에 개입하기 위한 작업별 오프셋 벡터를 학습하는 2단계 프레임워크인 LoFiT(Localized Fine-tuning on LLM Representation)를 도입합니다. • 진실성과 추론에 대한 다운스트림 정확성을 향상시키기 위해 중요한 어텐션 헤드의 희박한 세트를 식별했습니다. • LoFiT는 LLM의 전체 주의 헤드 중 10%에만 개입했음에도 불구하고 다른 표현 개입 방법보다 성능이 뛰어나며 TruthfulQA, CLUTRR 및 MQuAKE에서 PEFT 방법과 비슷한 성능을 달성했습니다. | |||
| 2024-05-28 | 사전 훈련된 변환기의 지식 회로 | ||
| • 변환기에 "지식 회로"를 도입하여 주의 헤드, 관계 헤드 및 MLP 간의 상호 작용을 통해 특정 지식이 인코딩되는 방식을 보여줍니다. • 지식 회로를 식별하기 위해 GPT-2 및 TinyLLAMA를 분석했습니다. 지식 편집 기술을 평가했습니다. • 지식 회로가 환각 및 상황 내 학습과 같은 모델 행동에 어떻게 기여하는지 입증했습니다. | |||
| 2024-05-23 | 트랜스포머의 상황 내 학습을 인간의 일화 기억에 연결 | ||
| • Transformer 모델의 상황 내 학습을 인간 일화 기억에 연결하여 유도 헤드와 상황별 유지 관리 및 검색(CMR) 모델 간의 유사성을 강조합니다. • 주의 머리에서 CMR과 유사한 동작을 보여주기 위한 Transformer 기반 LLM 분석. • CMR과 유사한 머리는 인간의 기억 편향을 반영하여 중간 계층에 나타납니다. | |||
| 2024-05-07 | GPT-2는 어떻게 약어를 예측합니까? 기계적 해석을 통한 회로 추출 및 이해 | ||
| • Attention Head를 사용하여 다중 토큰 약어를 예측하기 위한 GPT-2에 대한 최초의 기계적 해석 가능성 연구. • 약어 예측을 담당하는 8개의 어텐션 헤드 회로를 식별하고 해석했습니다. • 이 8개의 머리글(전체의 ~5%)이 약어 예측 기능에 집중되어 있음을 보여주었습니다. | |||
| 2024-05-02 | 산술 계산에서 대규모 언어 모델 해석 및 개선 | ||
| • '식별-분석-미세 조정' 파이프라인에 따라 수학적 작업을 통해 LLM의 내부 메커니즘에 대한 자세한 조사를 소개합니다. • 덧셈, 뺄셈, 곱셈, 나눗셈 등 두 개의 피연산자를 포함하는 산술 작업을 수행하는 모델의 기능을 분석했습니다. • LLM에는 계산 프로세스 중 피연산자와 연산자에 초점을 맞추는 데 중추적인 역할을 하는 작은 부분(5% 미만)의 주의 헤드가 포함되는 경우가 많다는 사실을 발견했습니다. | |||
| 2024-05-02 | 인덕션 헤드에 적합해야 하는 것은 무엇입니까? 상황 내 학습 회로 및 그 형성에 대한 기계적 연구 | ||
| • 변압기의 유도 헤드(IH) 형성을 연구하기 위해 광유전학에서 영감을 받은 인과 프레임워크를 도입했습니다. • 합성 데이터를 사용하여 변압기의 IH 출현을 분석하고 IH 형성을 담당하는 세 가지 기본 하위 회로를 식별했습니다. • 이러한 하위 회로가 상호 작용하여 모델 손실의 위상 변화와 동시에 IH 형성을 유도한다는 사실을 발견했습니다. | |||
| 2024-04-24 | 검색 헤드는 장기 맥락 사실성을 기계적으로 설명합니다. | ||
| • 긴 컨텍스트에 걸쳐 정보 검색을 담당하는 변환기 모델에서 "검색 헤드"를 식별했습니다. • 일련의 사고 추론에서의 역할 분석을 포함하여 다양한 모델에 걸쳐 검색 헤드를 체계적으로 조사합니다. • 회수용 머리를 가지치기하면 환각이 발생하고, 회수되지 않는 머리를 가지치기해도 회수 능력에는 영향을 미치지 않습니다. | |||
| 2024-03-27 | 비선형 추론 시간 개입: LLM 진실성 향상 | ||
| • NL-ITI(비선형 추론 시간 개입)를 도입하여 미세 조정 없이 멀티 토큰 조사 및 개입을 통해 LLM 진실성을 향상시켰습니다. • TruthfulQA를 포함한 객관식 데이터세트에서 NL-ITI를 평가했습니다. • 기준 ITI에 비해 TruthfulQA의 MC1 정확도가 16% 상대적으로 향상되었습니다. | |||
| 2024-02-28 | 단계별 사고 방법: 사고 연쇄 추론에 대한 기계론적 이해 | ||
| • 신경 기능 구성 요소 측면에서 LLM의 CoT 매개 추론에 대한 심층 분석을 제공합니다. • 의사 결정, 복사 및 귀납적 추론이 필요한 고정된 수의 하위 작업으로 구성된 가상 추론에 대한 CoT 기반 추론을 분석하고 해당 메커니즘을 별도로 분석합니다. • 어텐션 헤드는 존재론적으로 관련된(또는 부정적으로 관련된) 토큰 사이에서 정보 이동을 수행하여 이러한 토큰 쌍에 대해 명확하게 식별 가능한 표현을 생성한다는 사실을 발견했습니다. | |||
| 2024-02-28 | 머리를 자르면 갈등이 끝납니다: 언어 모델의 지식 갈등을 해석하고 완화하기 위한 메커니즘 | ||
| • 매개변수 업데이트 없이 언어 모델의 지식 충돌을 완화하여 충돌하는 주의 헤드를 정리하는 PH3 방법을 도입합니다. • 내부 메모리와 외부 컨텍스트에 대한 LM의 의존도를 제어하기 위해 PH3를 적용하고 개방형 도메인 QA 작업에 대한 효율성을 테스트했습니다. • PH3은 내부 메모리 사용량을 44.0%, 외부 컨텍스트 사용량을 38.5% 향상시켰습니다. | |||
| 2024-02-27 | 정보 흐름 경로: 대규모 언어 모델 자동 해석 | ||
| • 활성화 패치를 피하면서 언어 모델의 그래프 기반 해석을 위한 속성을 사용하는 "정보 흐름 경로"를 도입합니다. • Llama 2를 실험하여 다양한 영역과 작업 전반에 걸쳐 주요 관심 헤드와 행동 패턴을 식별합니다. • 발견된 특수 모델 구성요소; 동일한 품사의 토큰을 처리하는 등 주의 헤드에 대한 일관된 역할을 식별했습니다. | |||
| 2024-02-20 | 상황 내 학습을 이해하기 위한 의미론적 유도 헤드 식별 | ||
| • 상황 내 학습 능력과 상관관계가 있는 LLM(대형 언어 모델)의 "의미론적 유도 헤드"를 식별하고 연구합니다. • 구문 종속성과 지식 그래프 관계를 인코딩하기 위해 주의 헤드를 분석했습니다. • 특정 어텐션 헤드는 LLM의 상황 내 학습을 이해하는 데 중요한 관련 토큰을 회수하여 출력 로짓을 향상시킵니다. | |||
| 2024-02-16 | 통계적 귀납 헤드의 진화: 상황 내 학습 마르코프 체인 | ||
| • ICL(상황 내 학습) 기능이 변압기에서 어떻게 나타나는지 분석하여 "통계적 유도 헤드"를 형성하는 Markov Chain 시퀀스 모델링 작업을 소개합니다. • Markov Chain 작업에 대한 변압기의 다단계 교육에 대한 경험적 및 이론적 조사. • 변환기 레이어 상호 작용의 영향을 받아 유니그램에서 바이그램 예측으로의 위상 전환을 보여줍니다. | |||
| 2024-02-11 | 사실 요약: LLM의 사실 회상 이면에 있는 추가 메커니즘 | ||
| • LLM이 사실을 회상하기 위해 건설적으로 간섭하는 여러 독립적인 메커니즘을 사용하는 사실적 회상에서 "추가 모티브"를 식별하고 설명합니다. • 주의 헤드를 분석하고 혼합 헤드의 행동을 분석하기 위해 확장된 직접 로짓 속성을 확장했습니다. • LLM의 사실적 회상은 독립적으로 불충분한 여러 기여의 합으로 인해 발생함을 입증했습니다. | |||
| 2024-02-05 | 대규모 언어 모델은 어떻게 상황에 맞게 학습합니까? 컨텍스트 내 헤드의 쿼리 및 키 매트릭스는 측정 학습을 위한 두 개의 타워입니다. | ||
| • 컨텍스트 내 헤드의 쿼리 및 키 행렬이 메트릭 학습을 위한 "두 개의 타워"로 작동하여 레이블 기능 간의 유사성 계산을 용이하게 한다는 개념을 소개합니다. • 상황에 맞는 학습 메커니즘을 분석했습니다. ICL에 중요한 특정 관심 헤드를 식별했습니다. • 이러한 헤드 중 1%에만 개입하여 ICL 정확도를 87.6%에서 24.4%로 줄였습니다. | |||
| 2024-01-23 | 상황 내 언어 학습: 아키텍처 및 알고리즘 | ||
| • 특수 Transformer 어텐션 헤드인 "n-gram 헤드"를 도입하여 입력 조건부 토큰 예측을 통해 ICLL(상황 내 언어 학습)을 향상시킵니다. • 무작위 유한 오토마타의 일반 언어에 대한 신경 모델을 평가했습니다. • 하드 와이어링 n-gram 헤드는 SlimPajama 데이터세트에서 복잡성을 6.7% 향상시켰습니다. | |||
| 2024-01-16 | 상황 내 분류 작업에서 데이터 의존성과 갑작스러운 학습의 기계적 기초 | ||
| • 이 논문은 주의 전용 네트워크에서 유도 헤드의 갑작스러운 형성을 통해 상황 내 학습(ICL)의 기계적 기반을 모델링합니다. • 단순화된 입력 데이터와 2계층 주의 기반 네트워크를 사용하여 ICL 작업을 시뮬레이션했습니다. • 유도 헤드 형성은 중첩된 비선형성을 통해 추적되는 ICL로의 갑작스러운 전환을 유도합니다. | |||
| 2024-01-16 | Transformer 언어 모델의 작업 전반에서 회로 구성 요소 재사용 | ||
| • 이 논문에서는 GPT-2의 특정 회로가 다양한 작업에 걸쳐 일반화될 수 있음을 보여 주면서 이러한 회로가 작업별로 다르다는 개념에 도전합니다. • 색상 개체 작업의 간접 개체 식별(IOI) 작업에서 회로 재사용을 검사합니다. • 4개의 주의 헤드를 조정하면 색상 개체 작업의 정확도가 49.6%에서 93.7%로 향상됩니다. | |||
| 2024-01-16 | 후속 헤드: 야생에서 반복적이고 해석 가능한 주의 헤드 | ||
| • 이 백서에서는 일이나 숫자와 같은 자연스러운 순서로 토큰을 증가시키는 LLM의 관심 헤드인 "후속 헤드"를 소개합니다. • GPT-2 및 Llama-2와 같은 다양한 모델 크기 및 아키텍처에 걸쳐 후속 헤드의 형성을 분석합니다. • 후속 헤드는 31M에서 12B 매개변수 범위의 모델에서 발견되며 추상적이고 반복되는 숫자 표현을 나타냅니다. | |||
| 2024-01-16 | 대규모 언어 모델의 함수 벡터 | ||
| • 이 기사에서는 자기회귀 변환기 모델 내의 작업에 대한 간략한 인과 표현인 "함수 벡터(FV)"를 소개합니다. • FV는 다양한 ICL(상황 내 학습) 작업, 모델 및 계층에서 테스트되었습니다. • FV를 합산하여 새롭고 복잡한 작업을 트리거하는 벡터를 생성하고 내부 벡터 구성을 보여줄 수 있습니다. | |||
| 날짜 | 논문 및 요약 | 태그 | 모래밭 |
| 2023-12-23 | 사실 찾기: 뉴런 수준에서 리버스 엔지니어링 사실 회상 시도 | ||
| • Pythia 2.8B의 초기 MLP 레이어가 중첩 및 멀티 토큰 임베딩에 중점을 두고 분산 회로를 사용하여 사실 재현을 어떻게 인코딩하는지 조사했습니다. • MLP 레이어에서 사실 조회를 탐색하고 토큰 해제 및 해싱 메커니즘에 대한 가설을 테스트했습니다. • 쉽게 해석할 수 있는 내부 메커니즘 없이 분산 조회 테이블과 같은 사실적 회상 기능을 수행합니다. | |||
| 2023-11-07 | 해석 가능한 시퀀스 연속을 향하여: 대규모 언어 모델에서 공유 회로 분석 | ||
| • 유사한 시퀀스 연속 작업을 위한 공유 회로의 존재를 입증했습니다. • 아라비아 숫자, 숫자 단어 및 월의 증가하는 순서를 포함하는 유사한 순서 연속 작업에 대해 회로를 분석하고 비교했습니다. • 의미론적으로 관련된 시퀀스는 유사한 역할을 가진 공유 회로 하위 그래프와 유사한 기능을 가진 모델 전체에서 유사한 하위 회로를 찾는 데 의존합니다. | |||
| 2023-10-23 | 대규모 언어 모델에서 감정의 선형 표현 | ||
| • 이 논문은 LLM(대형 언어 모델)에서 감정 표현을 캡처하는 활성화 공간의 선형 방향을 식별합니다. • 그들은 이 감정 방향을 분리하고 Stanford Sentiment Treebank를 포함한 작업에서 테스트했습니다. • 이러한 감정 방향을 제거하면 분류 정확도가 76% 감소하여 그 중요성이 강조됩니다. | |||
| 2023-10-06 | 복사 억제: 어텐션 헤드에 대한 포괄적인 이해 | ||
| • 이 논문에서는 순진한 토큰 복사를 줄이고 모델 보정을 향상시키는 GPT-2 Small Attention Head(L10H7)의 복사 억제 개념을 소개합니다. • 이 문서에서는 복사 억제 메커니즘과 자가 복구 에서의 역할을 조사하고 설명합니다. • GPT-2 Small에 대한 L10H7의 영향 중 76.9%가 설명되어 있어 주의 헤드 역할에 대한 가장 포괄적인 설명이 됩니다. | |||
| 2023-09-22 | 추론 시간 개입: 언어 모델에서 진실한 답변 도출 | ||
| • 엄선된 어텐션 헤드의 모델 활성화를 조정하여 LLM 진실성을 강화하기 위해 ITI(추론 시간 개입)를 도입했습니다. • TruthfulQA 벤치마크에서 LLaMA 모델 성능이 향상되었습니다. • ITI는 Alpaca 모델의 진실성을 32.5%에서 65.1%로 높였습니다. | |||
| 2023-09-22 | 트랜스포머의 탄생: 기억의 관점 | ||
| • 이 논문은 변환기에 대한 메모리 기반 관점을 제시하고 가중치 행렬의 연관 메모리와 경사 기반 학습을 강조합니다. • 합성 데이터를 사용하여 단순화된 변환기 모델의 훈련 역학에 대한 실증적 분석. • 신속한 글로벌 바이그램 학습 발견 및 상황 내 바이그램에 대한 "유도 헤드"의 느린 출현. | |||
| 2023-09-13 | 손실의 급격한 감소: MLM의 구문 획득, 단계 전환 및 단순성 편향 | ||
| • MLM(Masked Language Model)에서 자연스럽게 나타나는 속성인 SAS(Syntactic Attention Structure)와 구문 획득에서의 역할을 식별합니다. • 훈련 중에 SAS를 분석하고 조작하여 문법 능력에 대한 인과 효과를 연구합니다. • SAS는 문법 개발에 필요하지만 이를 간략하게 억제하면 모델 성능이 향상됩니다. | |||
| 2023-07-18 | 회로 분석 해석 가능성이 확장됩니까? 친칠라의 객관식 능력에 대한 증거 | ||
| • 객관식 질문 응답을 이해하기 위해 70B Chinchilla 언어 모델에 적용되는 확장 가능한 회로 분석. • 주요 관심 헤드를 식별하고 분류하기 위한 로짓 속성, 주의 패턴 시각화 및 활성화 패치. • 어텐션 헤드에서 "열거의 N번째 항목" 기능을 식별했지만 부분적인 설명일 뿐입니다. | |||
| 2023-02-02 | 실제 해석 가능성: GPT-2 소형의 간접 객체 식별을 위한 회로 | ||
| • 이 논문에서는 GPT-2 small이 7개 클래스로 그룹화된 28개의 주의 헤드가 포함된 대형 회로를 사용하여 간접 개체 식별(IOI)을 수행하는 방법에 대한 자세한 설명을 소개합니다. • 인과적 개입과 예측을 사용하여 GPT-2 소규모의 IOI 작업을 역설계했습니다. • 이 연구는 대규모 언어 모델의 기계적 해석 가능성이 가능하다는 것을 보여줍니다. | |||
| 날짜 | 논문 및 요약 | 태그 | 모래밭 |
| 2022-03-08 | 상황 내 학습 및 유도 헤드 | ||
| • 이 논문에서는 시퀀스의 패턴을 인식하고 복사하여 상황에 맞는 학습을 가능하게 하는 Transformer 모델의 "유도 헤드"를 식별합니다. • 다양한 Transformer 모델의 다양한 계층에 걸쳐 주의 패턴과 유도 헤드를 분석합니다. • Transformers가 상황에 맞는 학습 작업을 효과적으로 일반화하고 수행할 수 있도록 유도 헤드가 중요하다는 사실을 발견했습니다. | |||
| 2021-12-22 | 변압기 회로를 위한 수학적 프레임워크 | ||
| • Attention Head를 독립적인 추가 구성 요소로 이해하는 데 중점을 두고 소형 Attention-Only 변환기를 리버스 엔지니어링하기 위한 수학적 프레임워크를 소개합니다. • 정보 이동 및 구성에서 주의 헤드의 역할을 식별하기 위해 0층, 1층, 2층 변환기를 분석했습니다. • 2층 변압기의 상황별 학습에 중요한 "유도 헤드"를 발견했습니다. | |||
| 2021-05-18 | 헤드 가설: BERT의 다중 방향 주의를 이해하기 위한 통일된 통계적 접근 방식 | ||
| • 본 논문에서는 중요한 토큰에 선택적으로 집중하여 Attention 메커니즘의 계산 복잡성을 줄이는 "Sparse Attention"이라는 새로운 방법을 제안합니다. • 이 방법은 기계 번역 및 텍스트 분류 작업에 대해 평가되었습니다. • 희소 주의 모델은 계산 비용을 크게 줄이면서 밀도 주의에 필적하는 정확도를 달성합니다. | |||
| 2021-04-01 | BERT 학습된 선거구 문법에 주의가 집중되어 있습니까? | ||
| • 이 연구에서는 BERT 및 RoBERTa 어텐션 헤드의 구성 문법을 분석하기 위한 구문적 거리 방법을 소개합니다. • SMS 및 NLI 작업에 대한 사전 및 사후 미세 조정을 통해 구성 문법을 추출하고 분석했습니다. • NLI 작업은 구성 문법 유도 능력을 증가시키는 반면 SMS 작업은 상위 계층에서 이를 감소시킵니다. | |||
| 2019-11-27 | BERT의 어텐션 헤드는 구문 종속성을 추적합니까? | ||
| • 이 논문은 종속성 관계를 추출하기 위해 주의 가중치를 사용하여 BERT의 개별 주의 헤드가 구문 종속성을 포착하는지 여부를 조사합니다. • 최대 주의 가중치와 최대 스패닝 트리를 사용하여 BERT의 주의 헤드를 분석하고 이를 범용 종속성 트리와 비교했습니다. • 일부 어텐션 헤드는 기준선보다 특정 구문 종속성을 더 잘 추적하지만 전체적인 구문 분석을 훨씬 더 잘 수행하는 헤드는 없습니다. | |||
| 2019-11-01 | 적응 적으로 희소 한 변압기 | ||
| •주의 헤드에서 유연하고 컨텍스트 의존적 희소성을 허용하기 위해 Alpha-Entmax를 사용하여 적응 적으로 드문 변압기를 도입했습니다. • 해석 가능성 및 헤드 다양성을 평가하기 위해 기계 번역 데이터 세트에 적용됩니다. • 정확도를 손상시키지 않고 다양한주의 분포와 개선 된 해석 성을 달성했습니다. | |||
| 2019-08-01 | Bert는 무엇을 봅니까? Bert의 관심 분석 | ||
| •이 논문은 Bert의주의 메커니즘을 분석하는 방법을 소개하여 구문 및 코퍼레이션과 같은 언어 구조와 일치하는 패턴을 드러냅니다. •주의 헤드 분석, 구문 및 핵심 패턴의 식별 및주의 기반 프로빙 분류기의 개발. • Bert의주의 헤드는 특히 직접적인 개체 및 코어 회의를 식별하는 것과 같은 작업에서 상당한 구문 정보를 캡처합니다. | |||
| 2019-07-01 | 멀티 헤드 자체 변환 분석 : 특수 헤드는 무거운 리프팅을 수행하고 나머지는 잘릴 수 있습니다. | ||
| •이 논문은 주요 성능 손실없이 덜 중요한 헤드를 선택적으로 제거하는 다중 헤드 자체 변환을위한 새로운 가지 치기 방법을 도입합니다. • 개별주의 헤드 분석, 특수한 역할 식별 및 변압기 모델에서 가지 치기 방법의 적용. • 인코더에서 48 개의 헤드 중 38 개를 가지 치면 0.15 BLEU 점수가 떨어졌습니다. | |||
| 2018-11-01 | 변압기 기반 기계 번역에서 인코더 표현의 분석 | ||
| •이 논문은 자체 정보 헤드에 의해 학습 된 구문 및 의미 론적 정보에 중점을 둔 변압기 인코더 층의 내부 표현을 분석합니다. • 프로브 작업, 종속성 관계 추출 및 전송 학습 시나리오. • 하위 계층 캡처 구문을 캡처하고 높은 계층은 더 많은 의미 정보를 인코딩합니다. | |||
| 2016-03-21 | 순서 대 시퀀스 학습에 복사 메커니즘을 통합합니다 | ||
| • 입력 토큰을 직접 복사하여 희귀 단어의 취급을 개선 할 수 있도록 서열-시퀀스 모델에 복사 메커니즘을 소개합니다. • 기계 번역 및 요약 작업에 적용됩니다. • 표준 시퀀스-시퀀스 모델과 비교하여 번역 정확도, 특히 희귀 단어 번역에서 상당한 개선을 달성했습니다. | |||
템플릿 발행 :
Title: [paper's title]
Head: [head name1] (, [head name2] ...)
Published: [arXiv / ACL / ICLR / NIPS / ...]
Summary:
- Innovation:
- Tasks:
- Significant Result:


