AMRICA
1.0.0
AMRICA(교차 언어 정렬을 위한 AMR 검사기)는 이중 언어 컨텍스트 및 단일 언어 주석자 간 합의를 위해 AMR(Banarescu, 2013)을 정렬하고 시각적으로 표현하기 위한 간단한 도구입니다. 이는 AMR 주석자 간 합의를 식별하기 위한 Smatch 시스템(Cai, 2012)을 기반으로 확장합니다.
AMRICA를 사용하여 직접 편집하거나 컴파일한 수동 정렬을 시각화할 수도 있습니다(공통 플래그 참조).
github에서 Python 소스를 다운로드하세요.
우리는 당신이 pip 가지고 있다고 가정합니다. 종속성을 설치하려면(아래에 언급된 graphviz 종속성이 이미 있다고 가정) 다음을 실행하세요.
pip install argparse_config networkx==1.8 pygraphviz pynlpl
pygraphviz 작동하려면 graphviz가 필요합니다. Linux에서는 graphviz libgraphviz-dev pkg-config 설치해야 할 수도 있습니다. 또한 이중 언어 정렬 데이터를 준비하려면 GIZA++ 및 JAMR이 필요할 수도 있습니다.
./disagree.py -i sample.amr -o sample_out_dir/
이 명령은 sample.amr (빈 줄로 구분)에서 AMR을 읽고 해당 graphviz 시각화를 sample_out_dir/ 에 있는 .png 파일에 저장합니다.
Smatch 정렬의 시각화를 생성하려면 토큰화된 문장을 포함하는 각 ::tok 또는 ::snt 필드, 문장 ID가 있는 ::id 필드, 주석 ID가 있는 ::annotator 또는 ::anno 필드가 있는 AMR 입력 파일이 필요합니다. 특정 문장에 대한 주석은 순차적으로 나열되며 첫 번째 주석은 시각화 목적의 최적 표준으로 간주됩니다.
주석 간 일치 없이 문장당 단일 주석만 시각화하려는 경우 단일 주석만 포함된 AMR 파일을 사용할 수 있습니다. 이 경우 주석 및 문장 ID 필드는 선택 사항입니다. 결과 그래프는 모두 검은색이 됩니다.
이중 언어 정렬의 경우 두 개의 AMR 파일로 시작합니다. 하나는 대상 주석을 포함하고 다른 하나는 동일한 순서의 소스 주석을 포함하며 각 주석에 대한 ::tok 및 ::id 필드가 있습니다. 어느 쪽이든 JAMR 정렬을 원할 경우 이를 ::alignments 필드에 포함합니다.
문장 정렬은 두 개의 GIZA++ 정렬 .NBEST 파일(하나는 소스-대상, 하나는 대상-소스) 형식이어야 합니다. 이를 생성하려면 원하는 nbest 개수로 설정된 GIZA++ 구성 파일의 --nbestalignments 플래그를 사용하세요.
플래그는 명령줄이나 구성 파일에서 설정할 수 있습니다. 구성 파일의 위치는 명령줄에서 -c CONF_FILE 사용하여 설정할 수 있습니다.
--conf_file 외에도 단일 언어 및 이중 언어 텍스트 모두에 적용되는 몇 가지 다른 플래그가 있습니다. --outdir DIR 유일한 필수 항목이며 이미지 파일을 쓸 디렉터리를 지정합니다.
선택적 공유 플래그는 다음과 같습니다.
--verbose 문장을 정렬하면서 문장을 인쇄합니다.--no-verbose 자세한 기본 설정을 무시합니다.--json FILE.json 정렬 그래프를 .json 파일에 작성합니다.--num_restarts N Smatch가 실행해야 하는 무작위 재시작 횟수를 지정합니다.--align_out FILE.csv - 정렬을 파일에 기록합니다.--align_in FILE.csv Smatch를 실행하는 대신 디스크에서 정렬을 읽습니다.--layout 레이아웃 매개변수를 graphviz로 수정합니다.정렬 .csv 파일은 각 그래프 일치 집합이 빈 줄로 구분되고 집합 내의 각 줄에 주석이나 정렬을 나타내는 줄이 포함되는 형식입니다. 예를 들어:
3 它 - 1 it
2 多长 - -1
-1 - 2 take
탭으로 구분된 필드는 테스트 노드 인덱스(Smatch에서 처리됨), 테스트 노드 레이블, 골드 노드 인덱스 및 골드 노드 레이블입니다.
단일 언어 정렬에는 하나의 추가 플래그 --infile FILE.amr 필요하며 FILE.amr 은 AMR 파일 위치로 설정됩니다.
다음은 구성 파일의 예입니다.
[default]
infile: data/events_amr.txt
outdir: data/events_png/
json: data/events.json
verbose
이중 언어 정렬에는 더 많은 필수 플래그가 있습니다.
--src_amr FILE (소스 주석 AMR 파일용)--tgt_amr FILE (대상 주석 AMR 파일용)--align_tgt2src FILE.A3.NBEST (대상-소스 정렬(대상은 vcb1), --nbestalignments N 으로 생성된 GIZA++ .NBEST 파일용)--align_src2tgt FILE.A3.NBEST 소스-대상 정렬)(소스를 vcb1로), --nbestalignments N 으로 생성된 GIZA++ .NBEST 파일용 이제 --nbestalignments N >1로 설정된 경우 --num_aligned_in_file 사용하여 지정해야 합니다. 상위만 계산하고 싶다면 --num_align_read 도 설정합니다.
--nbestalignments 최종 정렬 실행 시에만 생성되므로 사용하기 까다로운 플래그입니다. 나는 기본 GIZA++ 설정으로만 작동하도록 할 수 있었습니다.
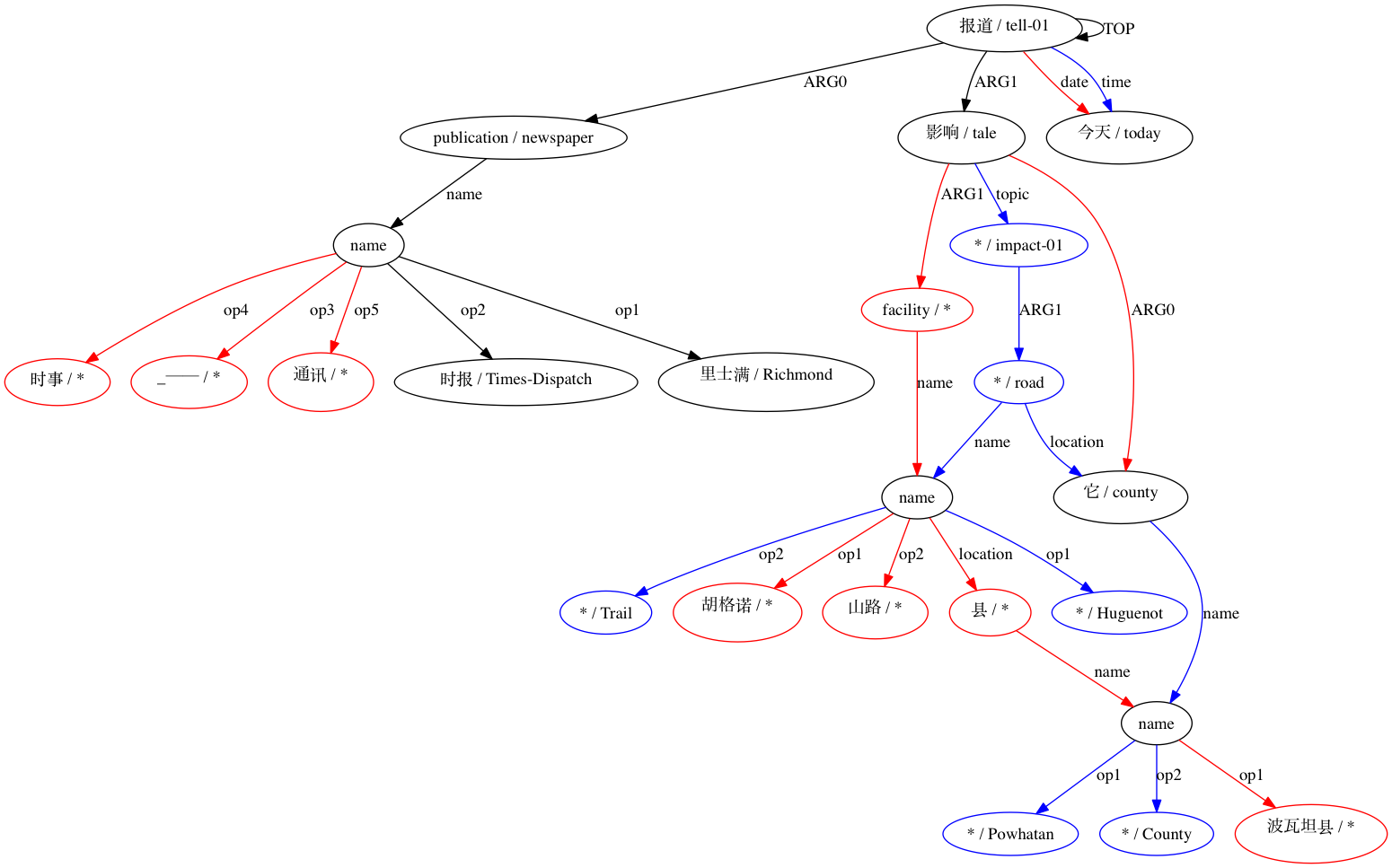
AMRICA는 Smatch의 변형이므로 Smatch를 이해하는 것부터 시작해야 합니다. Smatch는 주석자 간 일치를 측정하기 위해 동일한 문장의 두 AMR 표현의 변수 노드 간의 일치를 식별하려고 시도합니다. Smatch 점수를 최대화하기 위해 일치를 선택해야 합니다. Smatch 점수는 두 그래프에 나타나는 각 가장자리에 포인트를 할당하여 세 가지 범주로 분류됩니다. 각 카테고리는 "오래 걸리지 않았습니다."라는 다음 주석에 설명되어 있습니다.
(t / take-10
:ARG0 (i / it)
:ARG1 (l2 / long
:polarity -))
(instance, t, take-10) 과 같은 인스턴스 라벨(ARG0, t, i) 와 같은 가변-변수 모서리(polarity, l2, -) 와 같은 가변 상수 에지Smatch 점수를 최대화하는 매칭을 찾는 문제는 NP-완전이므로 Smatch는 최적의 솔루션을 근사화하기 위해 언덕 오르기 알고리즘을 사용합니다. 가능한 경우 각 노드를 해당 레이블을 공유하는 노드와 일치시키고 더 작은 그래프(이하 대상)의 나머지 노드를 무작위로 일치시키는 방식으로 시드됩니다. 그런 다음 Smatch는 두 대상 노드의 일치 항목을 전환하거나 일치 항목을 소스 노드에서 일치하지 않는 소스 노드로 이동하여 점수를 가장 많이 높이는 작업을 찾는 단계를 수행합니다. Smatch 점수를 즉시 높일 수 있는 단계가 없을 때까지 이 단계를 반복합니다.
로컬 최적화를 피하기 위해 Smatch는 일반적으로 5번 다시 시작됩니다.
AMRICA의 내부 작업에 대한 기술적인 세부 사항을 보려면 NAACL 데모 문서를 읽는 것이 더 유용할 수 있습니다.
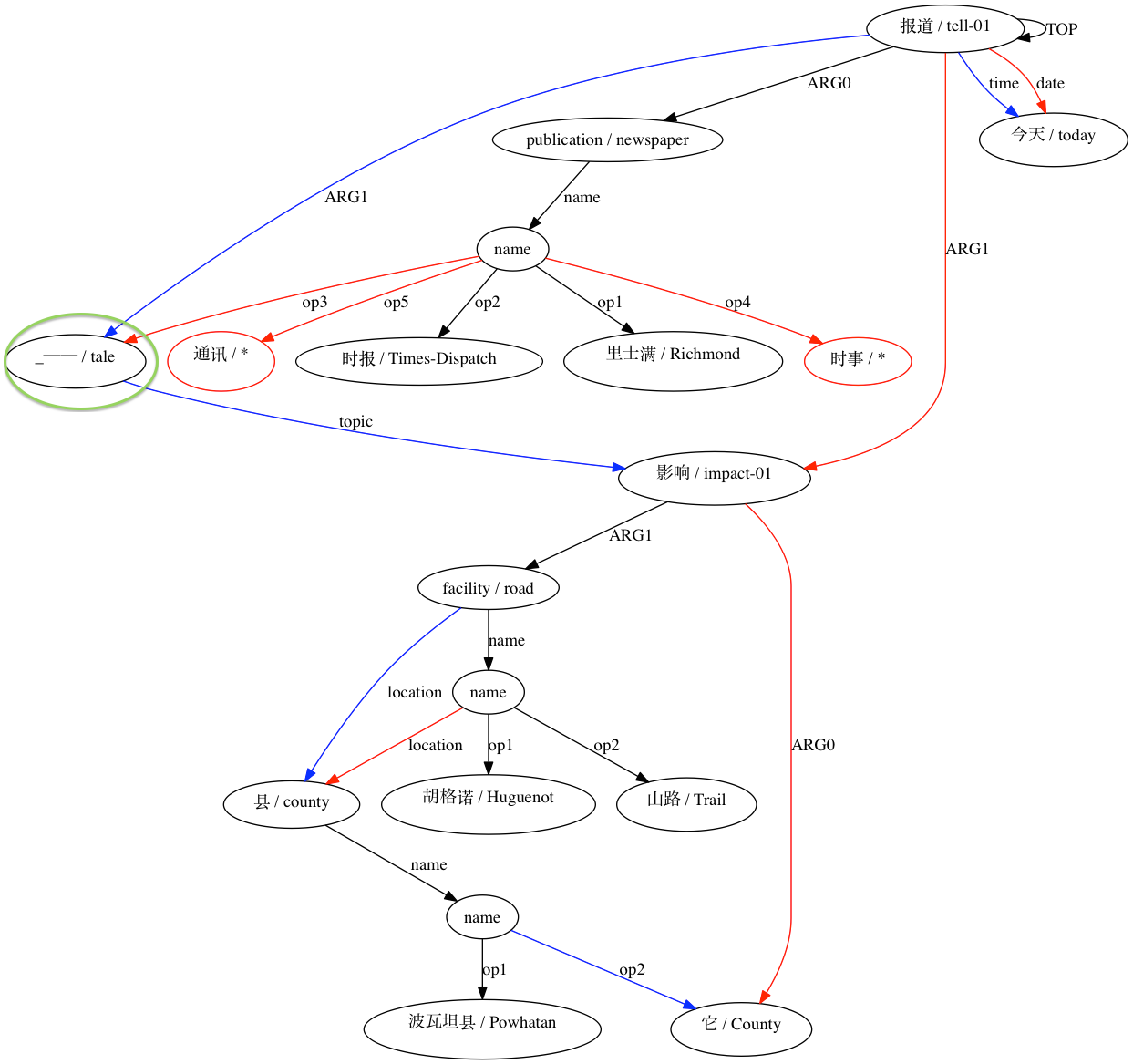
AMRICA는 모든 상수 노드를 상수 레이블의 인스턴스인 변수 노드로 바꾸는 것으로 시작합니다. 이는 상수 노드와 변수를 정렬하는 데 필요합니다. 따라서 AMRICA 점수에 추가되는 유일한 포인트는 일치하는 변수-변수 모서리와 인스턴스 레이블에서 나옵니다.
Smatch는 작은 그래프의 모든 노드를 큰 그래프의 일부 노드와 일치시키려고 시도하지만 AMRICA는 수정된 Smatch 점수, 즉 AMRICA 점수를 늘리지 않는 일치 항목을 제거합니다.
그런 다음 AMRICA는 정렬의 그래프 시각화 그래프에서 이미지 파일을 생성합니다. 노드나 에지가 골드 데이터에만 나타나면 빨간색입니다. 해당 노드나 에지가 테스트 데이터에만 나타나면 파란색입니다. 노드나 가장자리가 최종 정렬에서 일치하는 경우 검은색입니다.
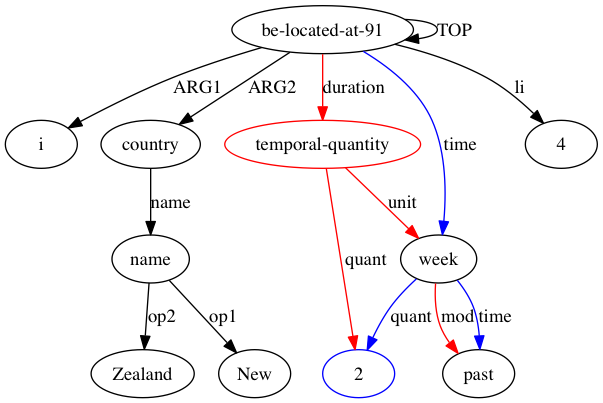
AMRICA에서는 완벽하게 일치하는 각 인스턴스 레이블에 대해 하나의 포인트를 추가하는 대신 해당 레이블이 정렬되는 가능성 점수를 기반으로 포인트를 추가합니다. 대상 레이블 세트 Lt, 소스 레이블 세트 Ls, 대상 문장 Wt, 소스 문장 Ws 및 정렬 aLt,Ls[i] 매핑 Lt[를 사용한 우도 점수 ℓ(aLt,Ls[i]|Lt,Wt,Ls,Ws) i]를 일부 레이블 Ls[aLt,Ls[i]]에 추가하는 것은 다음 규칙에 의해 정의된 가능성으로부터 계산됩니다.
일반적으로 이중 언어 AMRICA가 제대로 작동하려면 단일 언어 AMRICA보다 더 많은 무작위 재시작이 필요한 것으로 보입니다. 이 재시작 횟수는 --num_restarts 플래그를 사용하여 수정할 수 있습니다.
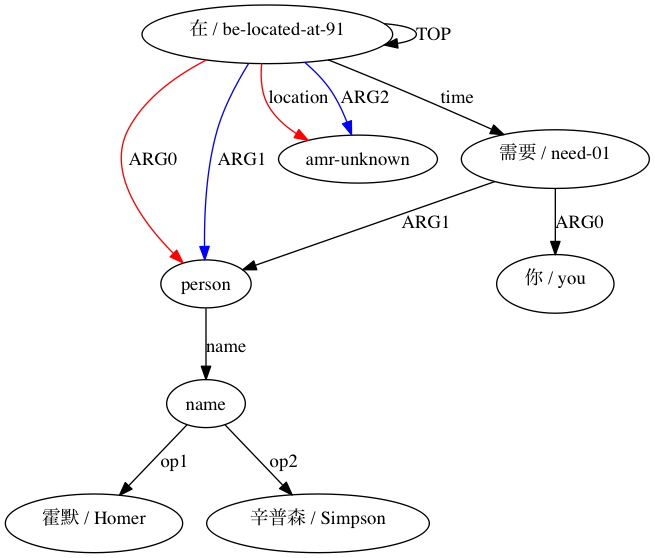
Smatch와 유사한 근사값(여기서는 20번의 무작위 초기화)을 사용하면 원시 정렬 데이터에서 일치할 가능성이 있는 항목을 선택하는 것(스마트 초기화)에 비해 정확도가 어느 정도 향상되는지 관찰할 수 있습니다. (Xue 2014)에 의해 구조적으로 호환 가능하다고 선언된 페어링의 경우.
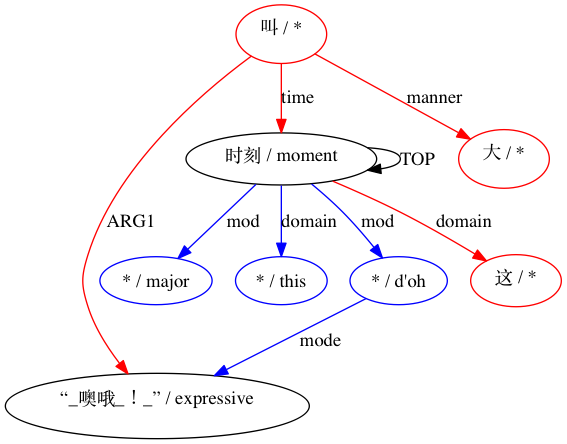
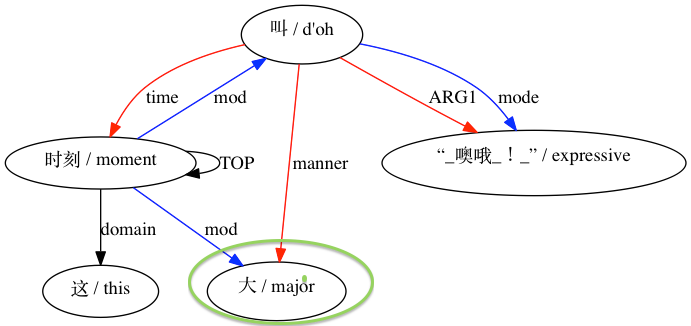
호환되지 않는 것으로 간주되는 페어링의 경우:
이 소프트웨어는 부분적으로 미국 국립과학재단(National Science Foundation, USA)의 지원을 받아 어워드 1349902 및 0530118에 따라 개발되었습니다. University of Edinburgh는 스코틀랜드에 등록된 자선 기관으로 등록 번호 SC005336입니다.


