llmjudge
1.0.0
개방형 시나리오에서 LLM을 평가하는 것은 어렵습니다. 기존 벤치마크가 부족하고 숙련된 실무자가 검증 모델 자체를 선호한다는 공감대가 커지고 있습니다. 저는 제가 신뢰하는 개발자와 연구자들의 일화적인 평가에 의지했으며 Chatbot Arena는 훌륭한 보완책이었습니다. 이 저장소의 동기는 강력한 LLM을 모델 심사위원으로 사용하는 방법이 점점 더 대중화되고 있기 때문입니다. 이 방법은 JudgeLM과 최근에는 MT-Bench와 같은 모델에서 몇 달 동안 사용되었습니다.
이 스레드를 보셨을 수도 있고 안 보셨을 수도 있습니다. Arize AI의 트윗 작성자에 따르면 LLM을 판사로 사용하는 것은 특히 숫자 점수 평가 사용과 관련하여 서버 주의가 필요하다고 합니다. LLM은 연속 범위를 처리하는 데 매우 부족한 것 같습니다. 이는 1에서 10까지 X를 평가하라는 메시지를 표시할 때 눈에 띄게 분명해집니다. 이 저장소는 이 문제의 들쭉날쭉한 경계를 이해하고 포착하려는 실험의 살아있는 문서입니다. 최근 연구에서는 MT-Bench와 Human Judgment(Arena Elo) 사이에 강력한 상관관계가 확립되었습니다. 이는 LLM이 심사위원이 될 수 있다는 것을 의미합니다. 그렇다면 여기서 무슨 일이 일어나고 있나요?
아래는 전체 내용과 결과입니다.
비용 제약으로 인해 처음에는 트윗에 설명된 철자/철자 오류 작업에 집중하겠습니다. 이 작업의 정량적 X가 이 실험의 통찰을 오염시키지 않을까 약간 걱정되지만 두고 보겠습니다. 나는 이 현상에 대한 보다 완전한 분석을 환영합니다. 제한된 실험을 고려하여 내 결과를 받아들여야 합니다.
Paul Graham의 에세이에서 어떤 이름이 더 적절한지 확실하지 않은 철자 또는 철자 오류 데이터 세트를 생성했습니다. 이 선택은 이전에 컨텍스트 창을 압력 테스트할 때 데이터 세트를 사용했기 때문에 대부분 편리하지 않았습니다. 에세이에서 3,000단어의 맥락을 추출하고, 원하는 맞춤법 오류 비율에 따라 임의의 단어에 맞춤법 오류를 삽입했습니다. 의사코드에서:
misspell_ratio
words = split context into words
misspell_count = calculate number of words to misspell based on ratio
FOR word = sample(words, misspell_count)
IF length(word) > 3
extract random character
ELSE:
add random character
END FOR
전체 코드는 노트북으로 쉽게 사용할 수 있습니다.
생성된 데이터 세트가 주어지면 LLM이 다양한 채점 템플릿을 사용하여 맥락에서 철자가 틀린 단어의 양을 평가하도록 유도합니다. 우리는 다음 API를 사용하고 있습니다
GPT-4: gpt-4-0125-preview
GPT-3.5: gpt-3.5-turbo-1106
온도 = 0에서.
테스트 1. LLM이 제로샷 설정에서 숫자 범위를 처리하는 데 어려움을 겪고 있음을 확인해 보겠습니다. 우리는 점수 0에서 10까지의 숫자 점수 템플릿을 사용하여 GPT-3.5 및 GPT-4를 프롬프트합니다.
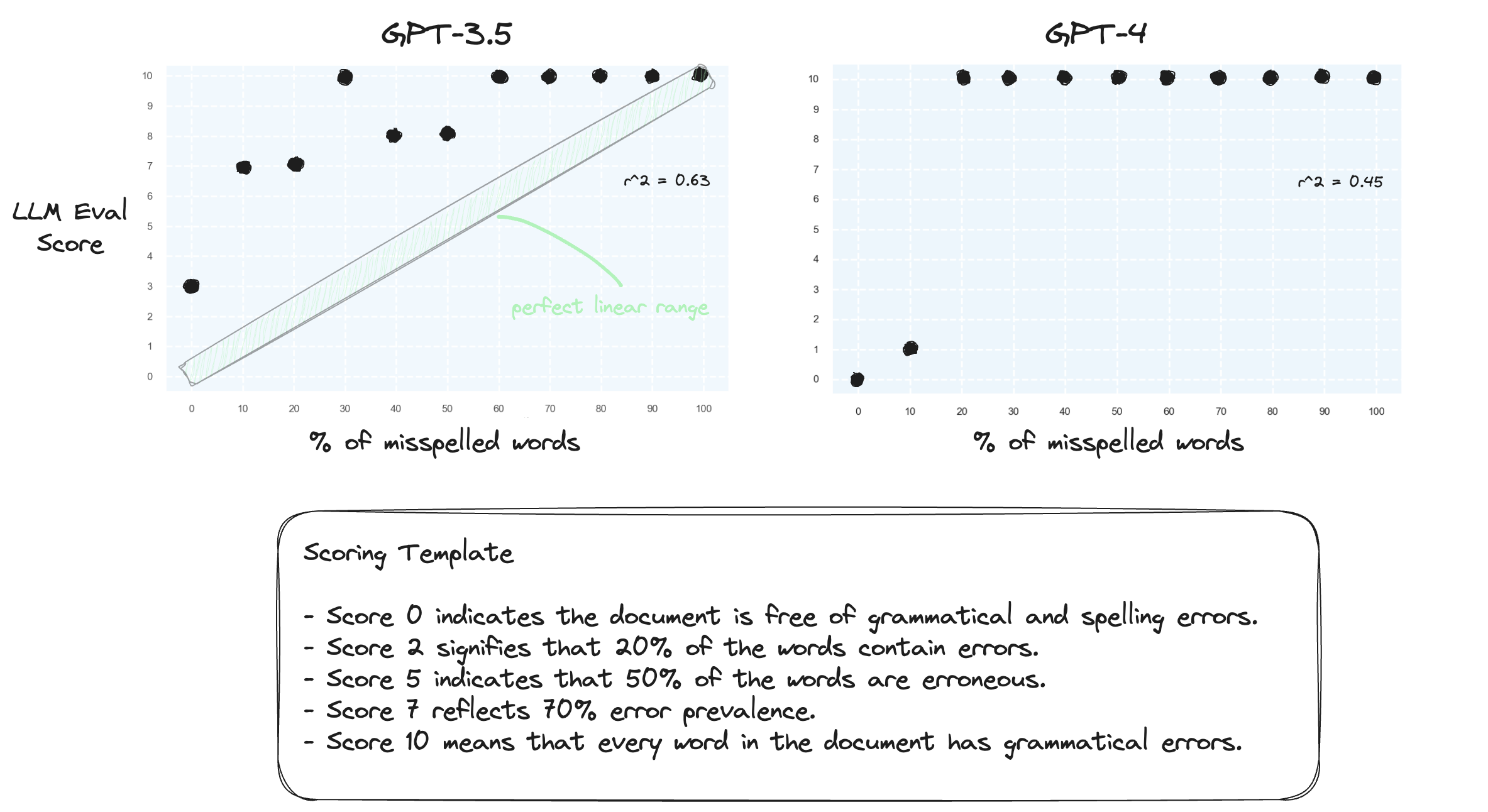
예상대로 둘 다 심각하게 잘못 판단합니다.
테스트 2. 점수 범위를 반대로 바꾸면 어떻게 되나요? 이제 10점은 철자가 완벽한 문서를 나타냅니다.
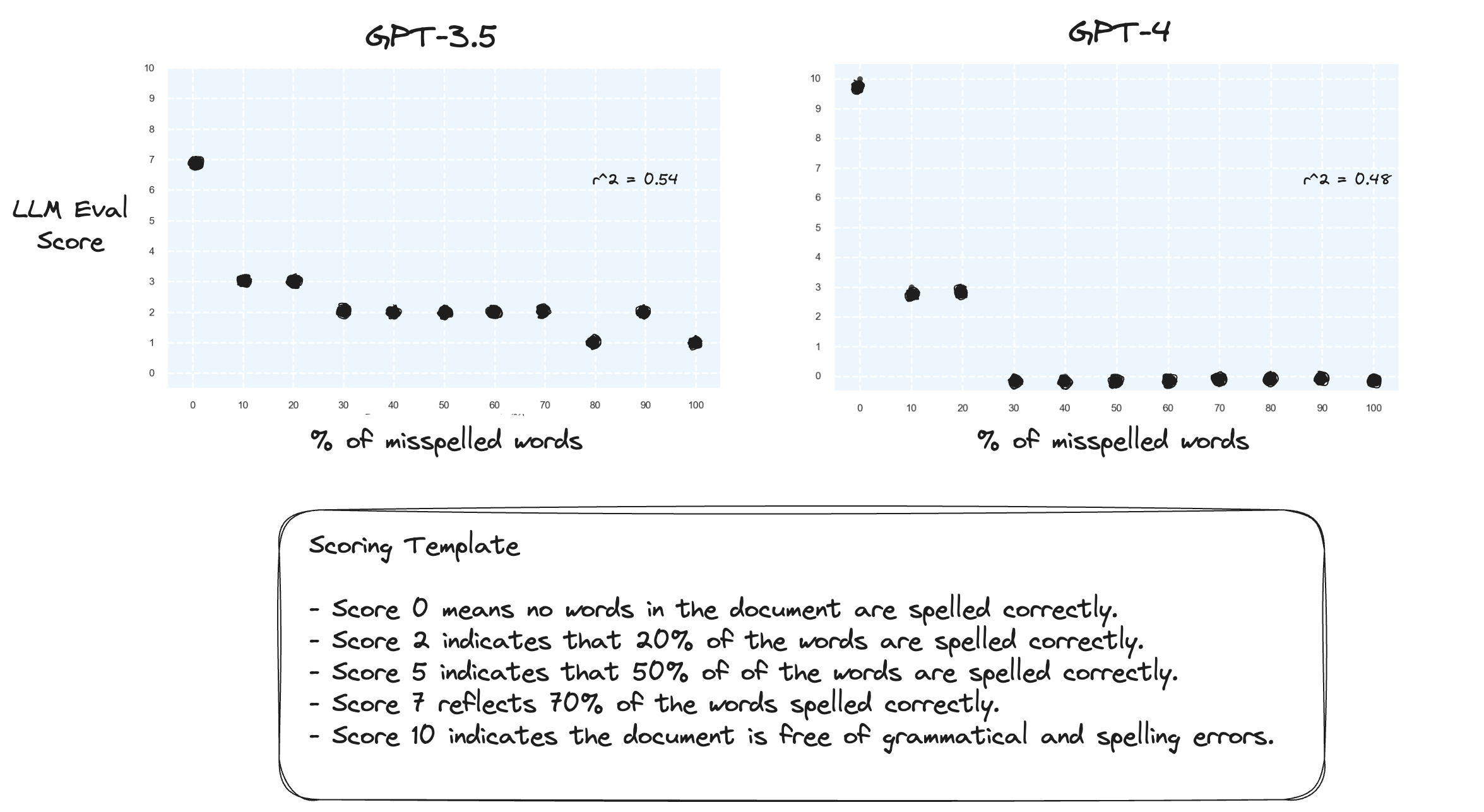
이것은 큰 차이가 없는 것 같습니다.
테스트 3. Arize의 가설을 믿는다면 채점 기준표를 피하고 대신 '표시된 성적'을 사용하면 개선을 볼 수 있습니다. 이 경우에는 5점 채점 기준으로 낮추기로 결정했습니다.
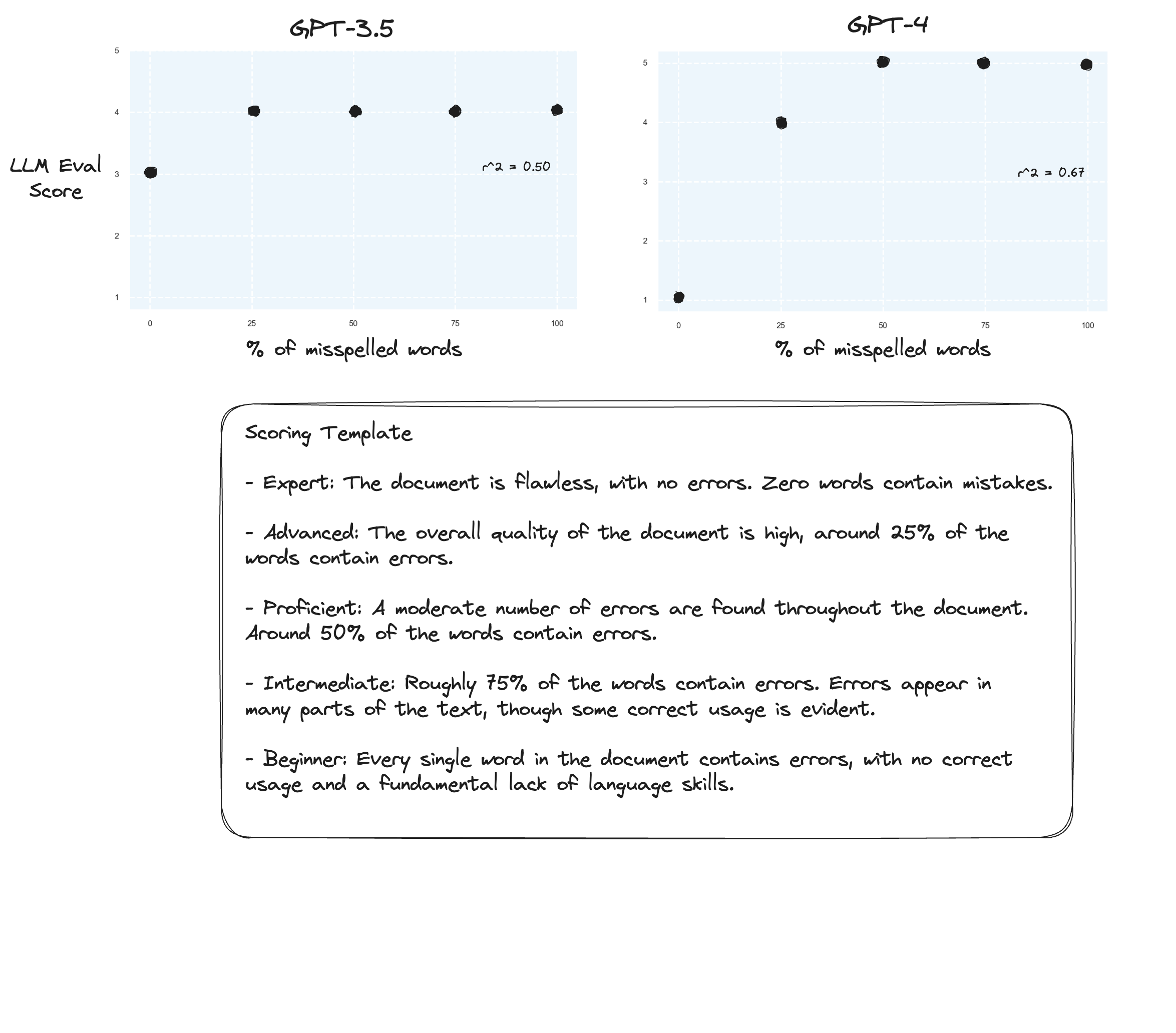
아마도 약간의 개선이 있을 것입니다. 솔직하게 말하기는 어렵습니다. 나는 감동받지 않았습니다.
테스트 4. 제로샷 연쇄 사고는 어떻습니까?

gpt-3.5는 두 가지 프롬프트에 대해 횡설수설로 바뀌었습니다. 예상한 대로, gpt-4는 곰곰이 생각하라는 메시지가 표시되면 개선이 나타납니다. 10점을 할당하는 것이 얼마나 주저되는지 주목하세요.
테스트 5. 프로메테우스의 저자가 제안한 대로; 각 점수를 자체 설명으로 매핑하면 전체 숫자 범위에 걸쳐 채점하는 LLM 능력이 향상될 가능성이 높습니다. 이는 CoT와 결합되어 다음과 같은 결과를 낳습니다.

gpt-4에 대한 지속적인 개선이 이루어졌습니다. 경계 점수를 0과 10으로 할당하는 것은 여전히 매우 꺼려집니다.
테스트 6. MT Bench에 대해 자세히 읽은 후 나는 격리된 채점 대신 쌍별 비교를 사용하여 대체 접근 방식을 테스트하기로 결정했습니다. 이제 일반적으로 O(n * log N) 비교가 필요하지만 순서를 이미 알고 있기 때문에 가장 어려운 경우만 테스트하겠다고 생각했습니다. 철자 오류 0% 대 철자 오류 10%, 철자 오류 10% 대 20% 등을 비교하는 것입니다. 총 10번의 비교를 위해 제로샷 CoT도 사용했다는 점에 주목하세요.
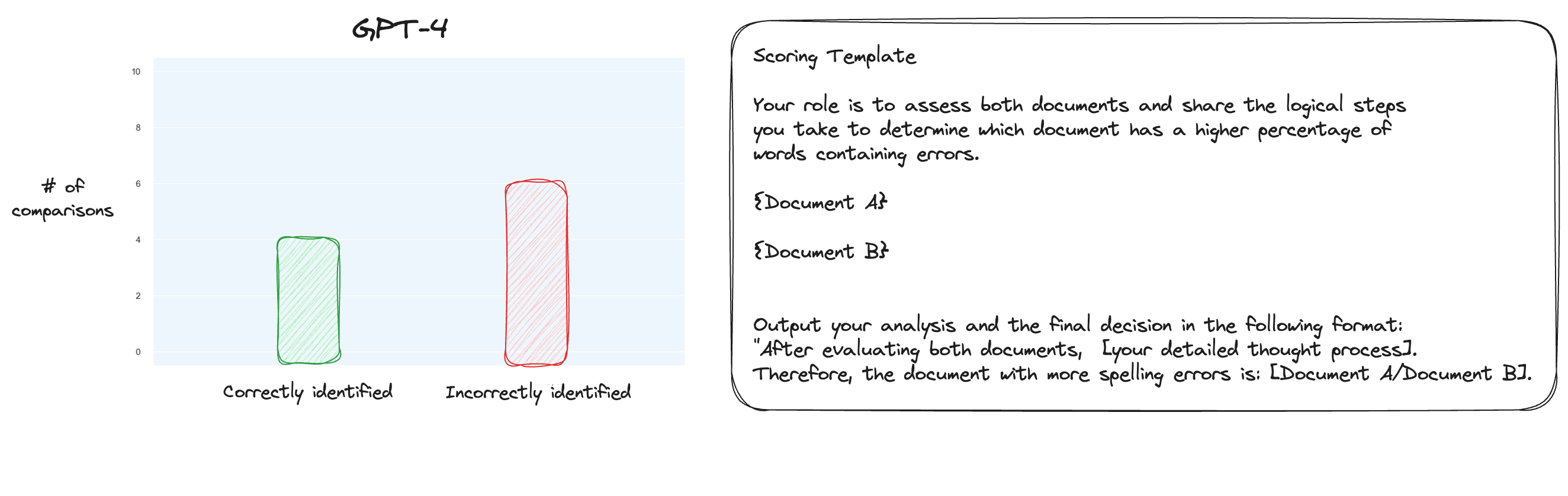
내 가설은 GPT-4가 컨텍스트 창 내부의 두 텍스트를 비교해야 하는 시나리오에서 탁월했을 것이라는 것이었지만 내 생각은 틀렸습니다. 놀랍게도 이것은 실제로 상황을 전혀 개선하지 못했습니다. 물론, 이것은 가능한 모든 비교 중에서 가장 어려운 것이지만, 전체적으로 이 작업은 여전히 간단한 작업입니다. 어쩌면 이 작업의 정량적 측면은 LLM에게 본질적으로 매우 어려울 수도 있습니다. 흠, 아마도 더 나은 프록시 작업을 찾아야 할 것 같습니다...
(31/1) 저는 MT-Bench의 내부를 살펴보았는데 그들이 단순히 GPT-4에 1~10점 척도로 출력 점수를 매기도록 요청한다는 사실에 매우 놀랐습니다. 기준선에 대한 쌍별 비교와 같은 대체 채점 옵션을 제공하지만 권장되는 옵션은 숫자 옵션입니다. 판단 프롬프트도 의외로 간단합니다.
공정한 판단자로서 아래 표시된 사용자 질문에 대해 AI 보조자가 제공하는 응답의 품질을 평가하십시오. 평가에서는 응답의 유용성, 관련성, 정확성, 깊이, 창의성, 세부 수준과 같은 요소를 고려해야 합니다. 간단한 설명을 제공하여 평가를 시작하세요. 최대한 객관적이세요. 설명을 제공한 후 [등급] 형식을 엄격히 준수하여 1부터 10까지 응답을 평가해야 합니다(예: "등급: 5"). [질문] {질문} [어시스턴트 답변 시작] {답변} [어시스턴트 답변 끝]
이것이 MT-Bench에서 판단하는 전부라고 생각한다면 철자 오류 작업을 대리 작업으로 사용하는 것에 의문이 들기 시작합니다.
(2/2) 저는 GPT-4가 개별 채점 대신 쌍별 비교를 통해 철자가 틀린 텍스트를 판단하도록 만들고 싶습니다. 이는 MT Bench의 대체 판단 방법 중 하나이며(단독 채점을 권장하지만) 이 작업에 더 적합하다고 생각됩니다. CoT + 전체 매핑 결과는 확실히 개선되었지만 아직 해야 할 일이 남아 있다고 생각합니다. 물론 쌍별 점수 매기기의 단점은 전체 순위를 설정하려면(실제로) 훨씬 더 많은 API 호출이 필요하다는 것입니다.


