DreamerGPT
1.0.0
 DreamerGPT: 중국어 모델 지침 미세 조정
DreamerGPT: 중국어 모델 지침 미세 조정DreamerGPT는 Xu Hao, Chi Huixuan, Bei Yuanchen 및 Liu Danyang이 시작한 중국어 대형 언어 모델 교육 미세 조정 프로젝트입니다.
영어 버전으로 읽어보세요 .

 1. 프로젝트 소개
1. 프로젝트 소개이 프로젝트의 목표는 보다 수직적인 현장 시나리오에서 중국어 대형 언어 모델의 적용을 촉진하는 것입니다.
우리의 목표는 대형 모델을 더 작게 만들고 모든 사람이 자신의 수직 분야에서 개인화된 전문 조력자를 훈련하고 가질 수 있도록 돕는 것입니다. 그는 심리 상담사, 코드 조수, 개인 조수 또는 자신의 언어 교사가 될 수 있습니다. DreamerGPT는 최상의 결과를 제공하고, 교육 비용이 가장 낮으며, 중국어에 더욱 최적화된 언어 모델입니다. DreamerGPT 프로젝트는 반복적 언어 모델 핫스타트 훈련(LLaMa, BLOOM 포함), 명령 훈련, 강화 학습, 수직장 미세 조정을 계속해서 개방하고 신뢰할 수 있는 훈련 데이터 및 평가 대상을 계속 반복할 것입니다. 제한된 프로젝트 인력과 리소스로 인해 현재 V0.1 버전은 LLaMa-7B 및 LLaMa-13B용 중국어 LLaMa에 최적화되어 중국어 기능, 언어 정렬 및 기타 기능이 추가되었습니다. 현재로서는 긴 대화 기능과 논리적 추론에 여전히 부족한 부분이 있습니다. 더 많은 반복 계획은 다음 버전의 업데이트를 참조하세요.
다음은 8b를 기반으로 한 양자화 데모입니다(동영상은 가속되지 않습니다). 현재 추론 가속화 및 성능 최적화도 반복되고 있습니다.
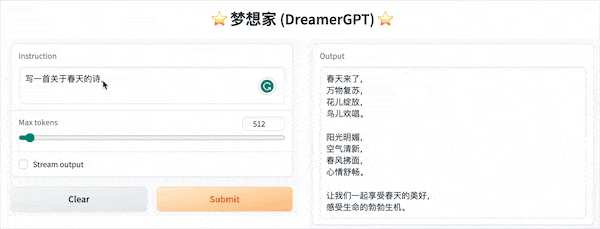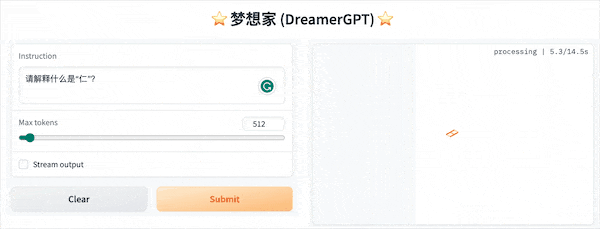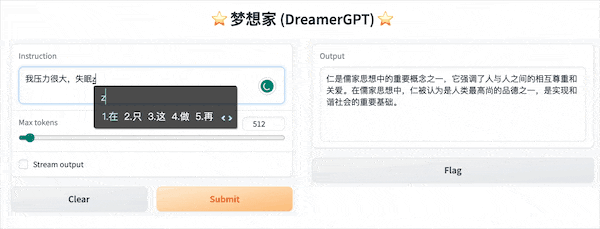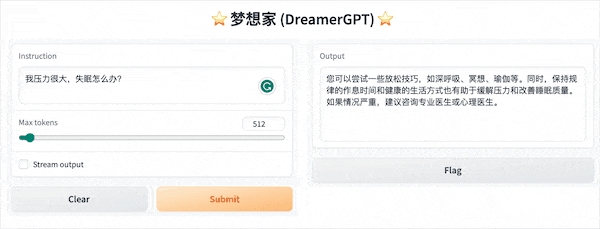
더 많은 데모 디스플레이:
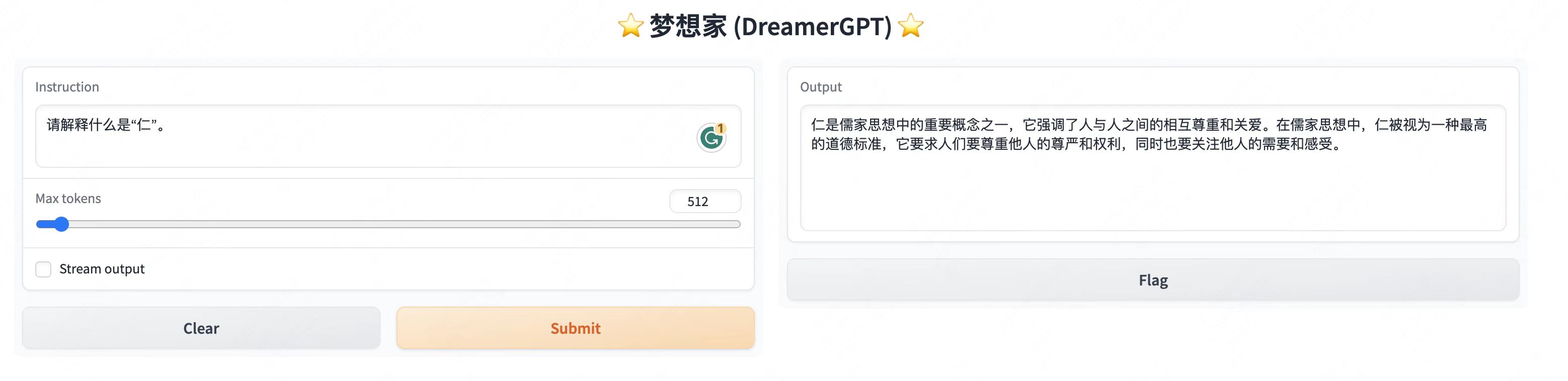

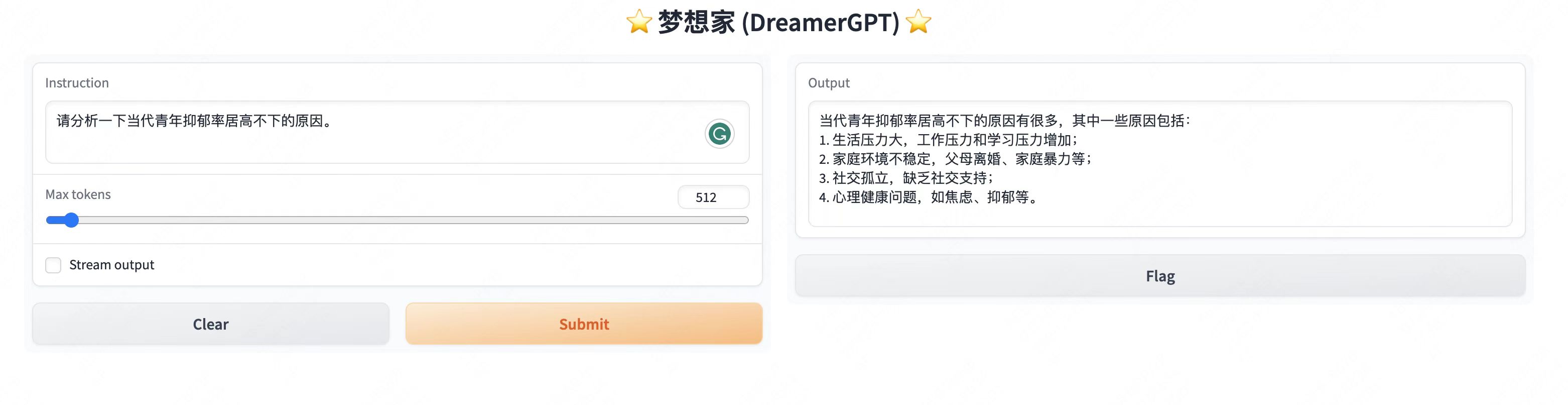
 2. 최신 업데이트
2. 최신 업데이트  [2023/06/17] V0.2 버전 업데이트: LLaMa 반딧불 증분 훈련 버전, BLOOM-LoRA 버전(
[2023/06/17] V0.2 버전 업데이트: LLaMa 반딧불 증분 훈련 버전, BLOOM-LoRA 버전( finetune_bloom.py , generate_bloom.py ).
[2023/04/23] 공식 오픈 소스 중국어 명령 미세 조정 대형 모델 Dreamer(DreamerGPT) , 현재 V0.1 버전 다운로드 경험 제공
기존 모델(지속적인 증분 학습, 더 많은 모델 업데이트 예정):
| 모델명 | 훈련 데이터= | 체중 다운로드 |
|---|---|---|
| V0.2 | --- | --- |
| D13b-3-3 | D13b-2-3 + 반딧불열차-1 | [껴안는 얼굴] |
| D7b-5-1 | D7b-4-1 + 반딧불열차-1 | [껴안는 얼굴] |
| V0.1 | --- | --- |
| D13b-1-3-1 | 중국어-알파카-로라-13b-핫 스타트 + COIG-part1, COIG-번역 + PsyQA-5 | [구글드라이브] [허깅페이스] |
| D13b-2-2-2 | 차이니즈-알파카-로라-13b-핫스타트 + 반딧불열차-0 + COIG-part1, COIG-번역 | [구글드라이브] [허깅페이스] |
| D13b-2-3 | 중국어-알파카-로라-13b-핫 스타트 + 반딧불-열차-0 + COIG-part1, COIG-번역 + PsyQA-5 | [구글드라이브] [허깅페이스] |
| D7b-4-1 | 중국어-알파카-로라-7b-hotstart+반딧불-기차-0 | [구글드라이브] [허깅페이스] |
모델 평가 미리보기
 3. 모델 및 데이터 준비
3. 모델 및 데이터 준비모델 중량 다운로드:
데이터는 다음 json 형식으로 균일하게 처리됩니다.
{
" instruction " : " ... " ,
" input " : " ... " ,
" output " : " ... "
}데이터 다운로드 및 전처리 스크립트:
| 데이터 | 유형 |
|---|---|
| 알파카-GPT4 | 영어 |
| Firefly(여러 사본으로 전처리, 형식 정렬) | 중국인 |
| 코이그 | 중국어, 코드, 중국어, 영어 |
| PsyQA(여러 사본으로 전처리됨, 형식 정렬) | 중국어 심리상담 |
| 미인 | 중국인 |
| 베이즈 | 중국어 회화 |
| 커플릿(여러 사본으로 사전 처리됨, 형식 정렬) | 중국인 |
참고: 데이터는 오픈 소스 커뮤니티에서 제공되며 링크를 통해 액세스할 수 있습니다.
 4. 훈련 코드 및 스크립트
4. 훈련 코드 및 스크립트코드 및 스크립트 소개:
finetune.py : 핫 스타트/증분 훈련 코드를 미세 조정하기 위한 지침generate.py : 추론/테스트 코드scripts/ : 스크립트 실행scripts/rerun-2-alpaca-13b-2.sh . 각 매개변수에 대한 설명은 scripts/README.md 참조하세요.  5. 사용방법
5. 사용방법자세한 내용 및 관련 문의사항은 Alpaca-LoRA를 참고해주세요.
pip install -r requirements.txt가중치 융합(alpaca-lora-13b를 예로 들어):
cd scripts/
bash merge-13b-alpaca.sh매개변수 의미(관련 경로를 직접 수정하십시오):
--base_model , 라마 원래 무게--lora_model , 차이니즈 라마/알파카-로라 가중치--output_dir , 출력 융합 가중치에 대한 경로실행 중인 스크립트를 보여주기 위해 다음 교육 프로세스를 예로 들어 보겠습니다.
| 시작 | f1 | f2 | f3 |
|---|---|---|---|
| 차이니즈-알파카-로라-13b-핫스타트, 실험번호: 2 | 데이터: 반딧불이-열차-0 | 데이터: COIG-part1, COIG-번역 | 데이터: PsyQA-5 |
cd scripts/
# 热启动f1
bash run-2-alpaca-13b-1.sh
# 增量训练f2
bash rerun-2-alpaca-13b-2.sh
bash rerun-2-alpaca-13b-2-2.sh
# 增量训练f3
bash rerun-2-alpaca-13b-3.sh중요한 매개변수에 대한 설명(관련 경로를 직접 수정하십시오):
--resume_from_checkpoint '前一次执行的LoRA权重路径'--train_on_inputs False 수정하세요.--val_set_size 2000 데이터 세트 자체가 상대적으로 작은 경우 500, 200 등 적절하게 줄일 수 있습니다.추론을 위해 미세 조정된 가중치를 직접 다운로드하고 싶다면 5.3을 무시하고 5.4로 바로 진행하면 된다는 점 참고하세요.
예를 들어, rerun-2-alpaca-13b-2.sh 미세 조정한 결과를 평가하고 싶습니다.
1. 웹 버전 상호 작용:
cd scripts/
bash generate-2-alpaca-13b-2.sh2. 일괄 추론 및 결과 저장:
cd scripts/
bash save-generate-2-alpaca-13b-2.sh중요한 매개변수에 대한 설명(관련 경로를 직접 수정하십시오):
--is_ui False : 웹 버전인지 여부, 기본값은 True--test_input_path 'xxx.json' : 입력 명령어 경로test.json 에 저장됩니다.  6. 평가보고서
6. 평가보고서 현재 평가 샘플에는 8가지 유형의 테스트 과제(평가할 숫자 윤리 및 쌍륜 대화)가 있으며, 각 범주에는 10개의 샘플이 있으며, 8비트 정량화 버전은 GPT-4/GPT 3.5를 호출하는 인터페이스에 따라 점수가 매겨집니다( 수량화되지 않은 버전의 점수가 더 높음), 각 샘플은 0-10 범위에서 점수가 매겨집니다. 평가 샘플은 test_data/ 참조하세요.
以下是五个类似 ChatGPT 的系统的输出。请以 10 分制为每一项打分,并给出解释以证明您的分数。输出结果格式为:System 分数;System 解释。
Prompt:xxxx。
答案:
System1:xxxx。
System2:xxxx。
System3:xxxx。
System4:xxxx。
System5:xxxx。참고: 점수는 참고용일 뿐입니다. (GPT 3.5와 비교) GPT 4의 점수가 더 정확하고 유익합니다.
| 테스트 작업 | 자세한 예 | 샘플 수 | D13b-1-3-1 | D13b-2-2-2 | D13b-2-3 | D7b-4-1 | 채팅GPT |
|---|---|---|---|---|---|---|---|
| 각 항목별 총점 | --- | 80 | 100 | 100 | 100 | 100 | 100 |
| 하찮은 일 | 01qa.json | 10 | 80* | 78 | 78 | 68 | 95 |
| 번역하다 | 02translate.json | 10 | 77* | 77* | 77* | 64 | 86 |
| 텍스트 생성 | 03generate.json | 10 | 56 | 65* | 55 | 61 | 91 |
| 감정 분석 | 04분석.json | 10 | 91 | 91 | 91 | 88* | 88* |
| 독해력 | 05이해.json | 10 | 74* | 74* | 74* | 76.5 | 96.5 |
| 중국의 특성 | 06중국어.json | 10 | 69* | 69* | 69* | 43 | 86 |
| 코드 생성 | 07code.json | 10 | 62* | 62* | 62* | 57 | 96 |
| 윤리, 답변 거부 | 08alignment.json | 10 | 87* | 87* | 87* | 71 | 95.5 |
| 수학적 추론 | (평가 예정) | -- | -- | -- | -- | -- | -- |
| 여러 라운드의 대화 | (평가 예정) | -- | -- | -- | -- | -- | -- |
| 테스트 작업 | 자세한 예 | 샘플 수 | D13b-1-3-1 | D13b-2-2-2 | D13b-2-3 | D7b-4-1 | 채팅GPT |
|---|---|---|---|---|---|---|---|
| 각 항목별 총점 | --- | 80 | 100 | 100 | 100 | 100 | 100 |
| 하찮은 일 | 01qa.json | 10 | 65 | 64 | 63 | 67* | 89 |
| 번역하다 | 02translate.json | 10 | 79 | 81 | 82 | 89* | 91 |
| 텍스트 생성 | 03generate.json | 10 | 65 | 73* | 63 | 71 | 92 |
| 감정 분석 | 04분석.json | 10 | 88* | 91 | 88* | 85 | 71 |
| 독해력 | 05이해.json | 10 | 75 | 77 | 76 | 85* | 91 |
| 중국의 특성 | 06중국어.json | 10 | 82* | 83 | 82* | 40 | 68 |
| 코드 생성 | 07code.json | 10 | 72 | 74 | 75* | 73 | 96 |
| 윤리, 답변 거부 | 08alignment.json | 10 | 71* | 70 | 67 | 71* | 94 |
| 수학적 추론 | (평가 예정) | -- | -- | -- | -- | -- | -- |
| 여러 라운드의 대화 | (평가 예정) | -- | -- | -- | -- | -- | -- |
전반적으로 모델은 번역 , 감정 분석 , 독해 등에서 좋은 성능을 보였습니다.
두 사람이 수동으로 채점한 후 평균을 계산했습니다.
| 테스트 작업 | 자세한 예 | 샘플 수 | D13b-1-3-1 | D13b-2-2-2 | D13b-2-3 | D7b-4-1 | 채팅GPT |
|---|---|---|---|---|---|---|---|
| 각 항목별 총점 | --- | 80 | 100 | 100 | 100 | 100 | 100 |
| 하찮은 일 | 01qa.json | 10 | 83* | 82 | 82 | 69.75 | 96.25 |
| 번역하다 | 02translate.json | 10 | 76.5* | 76.5* | 76.5* | 62.5 | 84 |
| 텍스트 생성 | 03generate.json | 10 | 44 | 51.5* | 43 | 47 | 81.5 |
| 감정 분석 | 04분석.json | 10 | 89* | 89* | 89* | 85.5 | 91 |
| 독해력 | 05이해.json | 10 | 69* | 69* | 69* | 75.75 | 96 |
| 중국의 특성 | 06중국어.json | 10 | 55* | 55* | 55* | 37.5 | 87.5 |
| 코드 생성 | 07code.json | 10 | 61.5* | 61.5* | 61.5* | 57 | 88.5 |
| 윤리, 답변 거부 | 08alignment.json | 10 | 84* | 84* | 84* | 70 | 95.5 |
| 수치윤리 | (평가 예정) | -- | -- | -- | -- | -- | -- |
| 여러 라운드의 대화 | (평가 예정) | -- | -- | -- | -- | -- | -- |
 7. 다음 버전 업데이트 내용
7. 다음 버전 업데이트 내용해야 할 일 목록:
 제한 사항, 사용 제한 및 면책 조항
제한 사항, 사용 제한 및 면책 조항현재 데이터와 기본 모델을 기반으로 훈련된 SFT 모델은 효율성 측면에서 여전히 다음과 같은 문제를 안고 있습니다.
사실에 근거한 지시는 사실에 어긋나는 잘못된 답변으로 이어질 수 있습니다.
유해한 지시사항을 제대로 식별할 수 없어 차별적, 유해적, 비윤리적 발언으로 이어질 수 있습니다.
추론, 코딩, 여러 라운드의 대화 등을 포함하는 일부 시나리오에서는 모델의 기능을 여전히 개선해야 합니다.
위 모델의 한계에 근거하여, 본 프로젝트의 콘텐츠와 본 프로젝트에서 생성된 후속 파생물은 학문적 연구 목적으로만 사용할 수 있으며, 상업적 목적이나 사회에 해를 끼치는 용도로 사용할 수 없습니다. 프로젝트 개발자는 본 프로젝트(데이터, 모델, 코드 등을 포함하되 이에 국한되지 않음)의 사용으로 인해 발생하는 어떠한 손해, 손실 또는 법적 책임도 지지 않습니다.
 인용하다
인용하다이 프로젝트의 코드, 데이터 또는 모델을 사용하는 경우 이 프로젝트를 인용해 주세요.
@misc{DreamerGPT,
author = {Hao Xu, Huixuan Chi, Yuanchen Bei and Danyang Liu},
title = {DreamerGPT: Chinese Instruction-tuning for Large Language Model.},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/DreamerGPT/DreamerGPT}},
}
 문의하기
문의하기이 프로젝트에는 아직 부족한 점이 많습니다. 제안이나 질문을 남겨주시면 이 프로젝트를 개선하기 위해 최선을 다하겠습니다.
이메일: [email protected]


