datalens
1.0.0
이는 LLM을 사용하여 사용자가 정의한 기준에 따라 구조화되지 않은 작업 데이터의 순위를 매기는 개인 실험입니다. 전통적인 구직 플랫폼은 엄격한 필터링 시스템에 의존하지만 많은 사용자에게는 그러한 구체적인 기준이 부족합니다. Datalens를 사용하면 보다 자연스러운 방식으로 선호 사항을 정의한 다음 관련성에 따라 각 채용 공고를 평가할 수 있습니다.
일부 기준은 다른 기준보다 더 중요할 수 있으므로 "필수 기준"은 일반 기준보다 두 배 더 가중치가 적용됩니다.
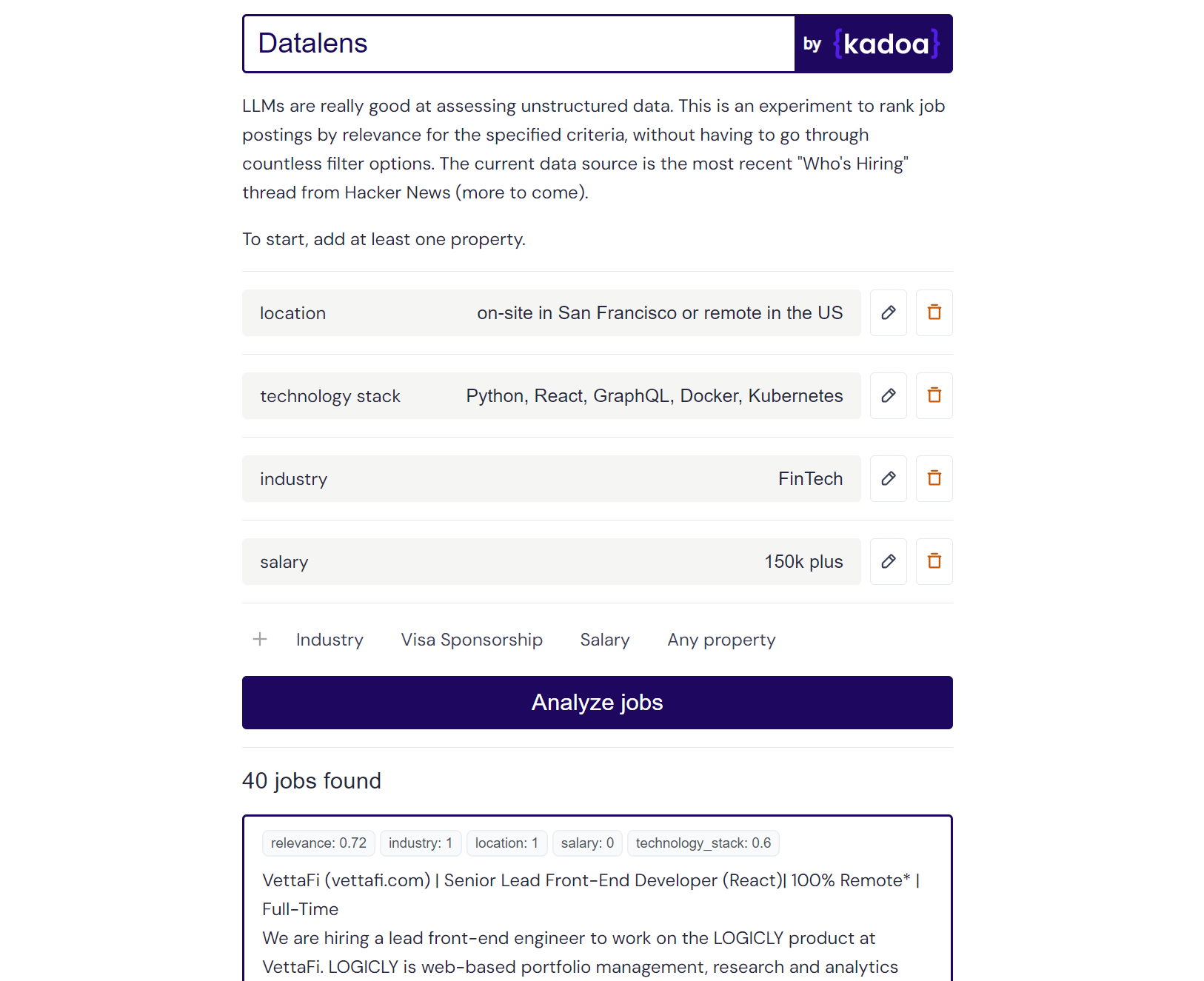
Claude-2 예시 결과:
Here are the scores for the provided job posting:
{
"location": 1.0,
"technology_stack": 0.8,
"industry": 0.0,
"salary": 0.0
}
Explanation:
- Location is a perfect match (1.0) as the role is in San Francisco which meets the "on-site in San Francisco or remote in the US" criteria.
- Technology stack is a partial match (0.8) as Python, React, and Kubernetes are listed which meet some but not all of the specified technologies.
- Industry is no match (0.0) as the company is in the creative/AI space.
- Salary is no match (0.0) as the posting does not mention the salary range. However, the full compensation is variable. Assigned a score of 0.6.
원하는 작업 데이터 소스를 추가할 수 있습니다. Hacker News의 최신 "Who's Hiring" 스레드를 사용하여 미리 구성했지만 자신만의 소스를 추가할 수도 있습니다.
source_config.json을 업데이트하여 새 작업 소스를 추가합니다. 예:
{
"name": "SourceName",
"endpoint": "API_ENDPOINT",
"handler": "handler_function_name",
"headers": {
"x-api-key": "YOUR_API_KEY"
}
}
저는 회사 페이지에서 작업 데이터를 가져오기 위해 자체 도구인 Kadoa를 사용했지만 다른 기존 스크래핑 방법을 사용할 수도 있습니다.
다음은 이러한 회사의 모든 채용 공고를 가져오기 위한 미리 만들어진 공개 엔드포인트입니다(매일 업데이트됨).
{
"name": "Anduril",
"endpoint": "https://services.kadoa.com/jobs/pages/64e74d936addab49669d6319?format=json",
"handler": "fetch_kadoa_data",
"headers": {
"x-api-key": "00000000-0000-0000-0000-000000000000"
}
},
{
"name": "Tesla",
"endpoint": "https://services.kadoa.com/jobs/pages/64eb63f6b91574b2149c0cae?format=json",
"handler": "fetch_kadoa_data",
"headers": {
"x-api-key": "00000000-0000-0000-0000-000000000000"
}
},
{
"name": "SpaceX",
"endpoint": "https://services.kadoa.com/jobs/pages/64eb5f1b7350bf774df35f7f?format=json",
"handler": "fetch_kadoa_data",
"headers": {
"x-api-key": "00000000-0000-0000-0000-000000000000"
}
}
다른 회사를 추가해야 하는지 알려주세요. 또한 Kadoa에 대한 평가판 액세스 권한을 제공하게 되어 기쁘게 생각합니다.
관련성 점수는 0~1 사이의 세분화된 점수를 반환하는 gpt-4-0613 에서 가장 잘 작동합니다. claude-2 에 액세스할 수 있으면 꽤 잘 작동합니다. gpt-3.5-turbo-0613 사용할 수 있지만 기준에 대해 0 또는 1의 이진 점수를 반환하는 경우가 많아 부분 일치와 전체 일치를 구별하는 뉘앙스가 부족합니다.
비용상의 이유로 기본 모델은 gpt-3.5-turbo-0613 입니다. use_claude use_openai 로 바꾸면 GPT에서 Claude로 전환할 수 있습니다.
이 스크립트를 계속 실행하면 API 사용량이 높아질 수 있으므로 책임감 있게 사용하시기 바랍니다. 각 GPT 통화 비용을 기록하고 있습니다.
앱을 실행하려면 다음이 필요합니다.
.env.example 파일을 복사하여 작성합니다.
Flask 서버를 실행합니다:
cd server
cp .env.example .env
pip install -r requirements.txt
py main
클라이언트 디렉터리로 이동하여 노드 종속성을 설치합니다.
cd client
npm install
Next.js 클라이언트를 실행합니다.
cd client
npm run dev


