ShapeGPT
1.0.0

프로젝트 페이지 • Arxiv 논문 • 데모 • FAQ • 인용
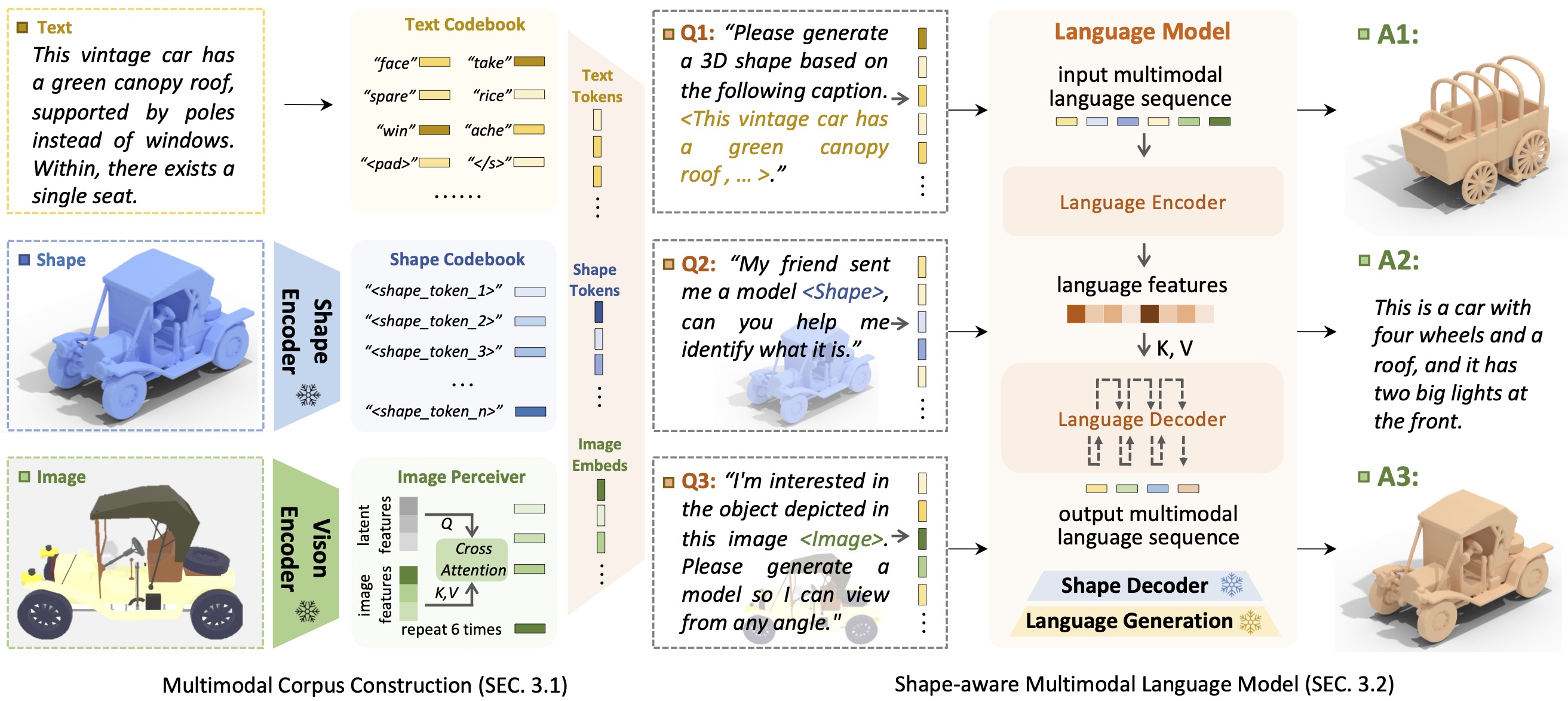
소개 모양GPTShapeGPT는 다중 모드 코퍼스를 구축하고 다중 모양 작업 에 대한 모양 인식 언어 모델을 개발하기 위한 통합 되고 사용자 친화적인 모양 중심 다중 모드 언어 모델입니다.
명령 중심 접근 방식을 통해 유연성을 가능하게 하는 대규모 언어 모델의 출현은 많은 기존 생성 작업에 혁명을 일으켰지만, 특히 다른 양식을 사용하여 3D 모양을 포괄적으로 처리하는 3D 데이터용 대규모 모델은 여전히 과소 탐구되고 있습니다. 명령 기반 형상 생성을 달성함으로써 다목적 다중 모드 생성 형상 모델은 3D 가상 구성 및 네트워크 지원 설계와 같은 다양한 분야에 큰 이점을 줄 수 있습니다. 이 연구에서는 강력한 사전 훈련된 언어 모델을 활용하여 여러 모양 관련 작업을 처리하는 모양 포함 다중 모드 프레임워크인 ShapeGPT를 제시합니다. 구체적으로 ShapeGPT는 단어-문장-단락 프레임워크를 사용하여 연속 모양을 모양 단어로 구분하고 모양 문장을 위해 이러한 단어를 추가로 조합할 뿐만 아니라 모양을 다중 모드 단락용 교육 텍스트와 통합합니다. 이 모양 언어 모델을 학습하기 위해 모양 표현, 다중 모달 정렬, 명령 기반 생성을 포함한 3단계 훈련 체계를 사용하여 모양 언어 코드북을 정렬하고 이러한 양식 간의 복잡한 상관 관계를 학습합니다. 광범위한 실험을 통해 ShapeGPT는 텍스트-모양, 모양-텍스트, 모양 완성, 모양 편집 등 모양 관련 작업 전반에 걸쳐 비슷한 성능을 달성하는 것으로 나타났습니다.
우리의 코드나 문서가 도움이 된다면 다음을 인용해 보세요.
@misc { yin2023shapegpt ,
title = { ShapeGPT: 3D Shape Generation with A Unified Multi-modal Language Model } ,
author = { Fukun Yin and Xin Chen and Chi Zhang and Biao Jiang and Zibo Zhao and Jiayuan Fan and Gang Yu and Taihao Li and Tao Chen } ,
year = { 2023 } ,
eprint = { 2311.17618 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
}
T5 모델, Motion-GPT, Perceiver-IO 및 SDFusion 덕분에 우리 코드는 부분적으로 이들로부터 차용되었습니다. 우리의 접근 방식은 Unified-IO, Michelangelo, ShapeCrafter, Pix2Vox 및 3DShape2VecSet에서 영감을 받았습니다.
이 코드는 MIT 라이센스에 따라 배포됩니다.
우리 코드는 PyTorch3D 및 PyTorch Lightning을 포함한 다른 라이브러리에 의존하며 각각 따라야 하는 고유한 라이선스가 있는 데이터 세트를 사용합니다.


