multimedia gpt
1.0.0
멀티미디어 GPT는 OpenAI GPT를 비전 및 오디오와 연결합니다. 이제 OpenAI API 키를 사용하여 이미지, 오디오 녹음 및 PDF 문서를 보내고 텍스트 및 이미지 형식으로 응답을 받을 수 있습니다. 현재 비디오에 대한 지원을 추가하고 있습니다. 모든 것은 Microsoft Visual ChatGPT에서 영감을 받아 구축된 프롬프트 관리자에 의해 가능해졌습니다.
Microsoft Visual ChatGPT에 언급된 모든 비전 기반 모델 외에도 멀티미디어 GPT는 OpenAI Whisper 및 OpenAI DALLE를 지원합니다! 즉 , 음성 인식 및 이미지 생성을 위해 더 이상 자체 GPU가 필요하지 않습니다 (아직도 가능하지만!).
기본 채팅 모델은 ChatGPT 및 GPT-4를 포함한 모든 OpenAI LLM 으로 구성할 수 있습니다. 기본값은 text-davinci-003 입니다.
이 프로젝트를 포크하고 자신의 사용 사례에 적합한 모델을 추가할 수 있습니다. 이를 수행하는 간단한 방법은 llama_index를 사용하는 것입니다. model.py 에서 모델에 대한 새 클래스를 생성하고 multimedia_gpt.py 에 실행기 메서드 run_<model_name> 을 추가해야 합니다. 예제는 run_pdf 참조하세요.
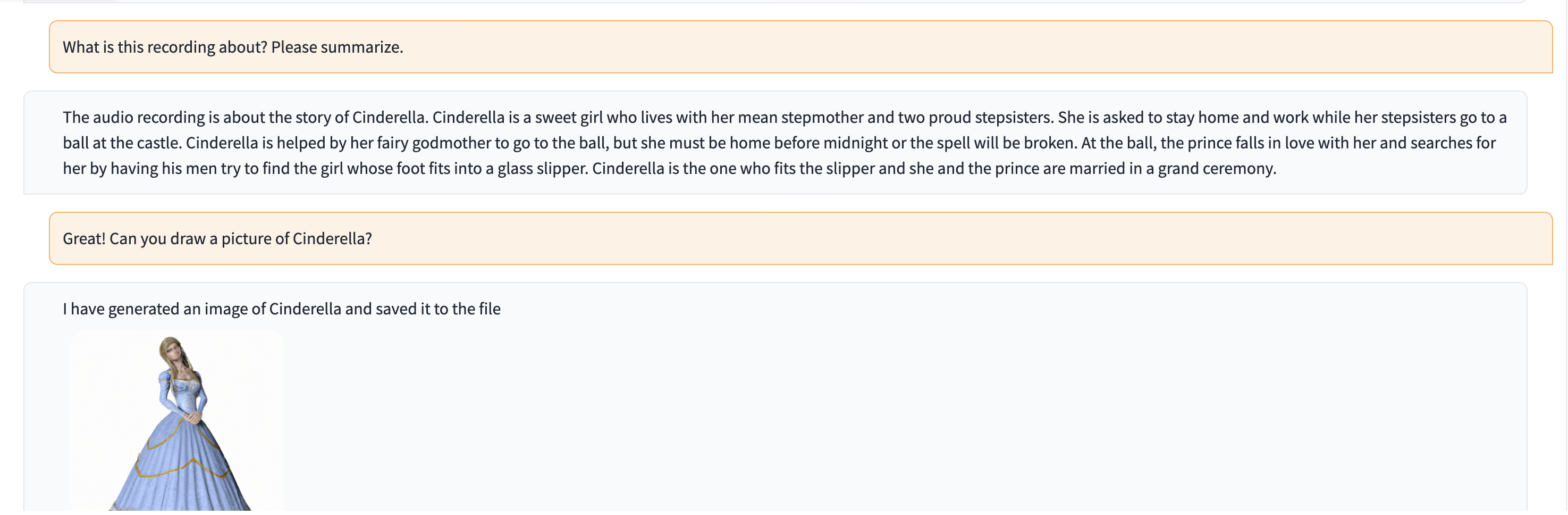
이 데모에서 ChatGPT에는 신데렐라 이야기를 들려주는 사람의 녹음이 제공됩니다.
# Clone this repository
git clone https://github.com/fengyuli2002/multimedia-gpt
cd multimedia-gpt
# Prepare a conda environment
conda create -n multimedia-gpt python=3.8
conda activate multimedia-gptt
pip install -r requirements.txt
# prepare your private OpenAI key (for Linux / MacOS)
echo " export OPENAI_API_KEY='yourkey' " >> ~ /.zshrc
# prepare your private OpenAI key (for Windows)
setx OPENAI_API_KEY “ < yourkey > ”
# Start Multimedia GPT!
# You can specify the GPU/CPU assignment by "--load", the parameter indicates which foundation models to use and
# where it will be loaded to. The model and device are separated by '_', different models are separated by ','.
# The available Visual Foundation Models can be found in models.py
# For example, if you want to load ImageCaptioning to cuda:0 and whisper to cpu
# (whisper runs remotely, so it doesn't matter where it is loaded to)
# You can use: "ImageCaptioning_cuda:0,Whisper_cpu"
# Don't have GPUs? No worry, you can run DALLE and Whisper on cloud using your API key!
python multimedia_gpt.py --load ImageCaptioning_cpu,DALLE_cpu,Whisper_cpu
# Additionally, you can configure the which OpenAI LLM to use by the "--llm" tag, such as
python multimedia_gpt.py --llm text-davinci-003
# The default is gpt-3.5-turbo (ChatGPT). 이 프로젝트는 실험적인 작업이므로 프로덕션 환경에 배포되지 않습니다. 우리의 목표는 속삭임의 힘을 탐구하는 것입니다.


