BabyGPT Build_GPT_From_Scratch
1.0.0
Baby GPT는 GPT와 유사한 언어 모델을 점진적으로 구축하기 위해 설계된 탐색 프로젝트입니다. 이 프로젝트는 간단한 Bigram 모델로 시작하여 점차적으로 Transformer 모델 아키텍처의 고급 개념을 통합합니다.
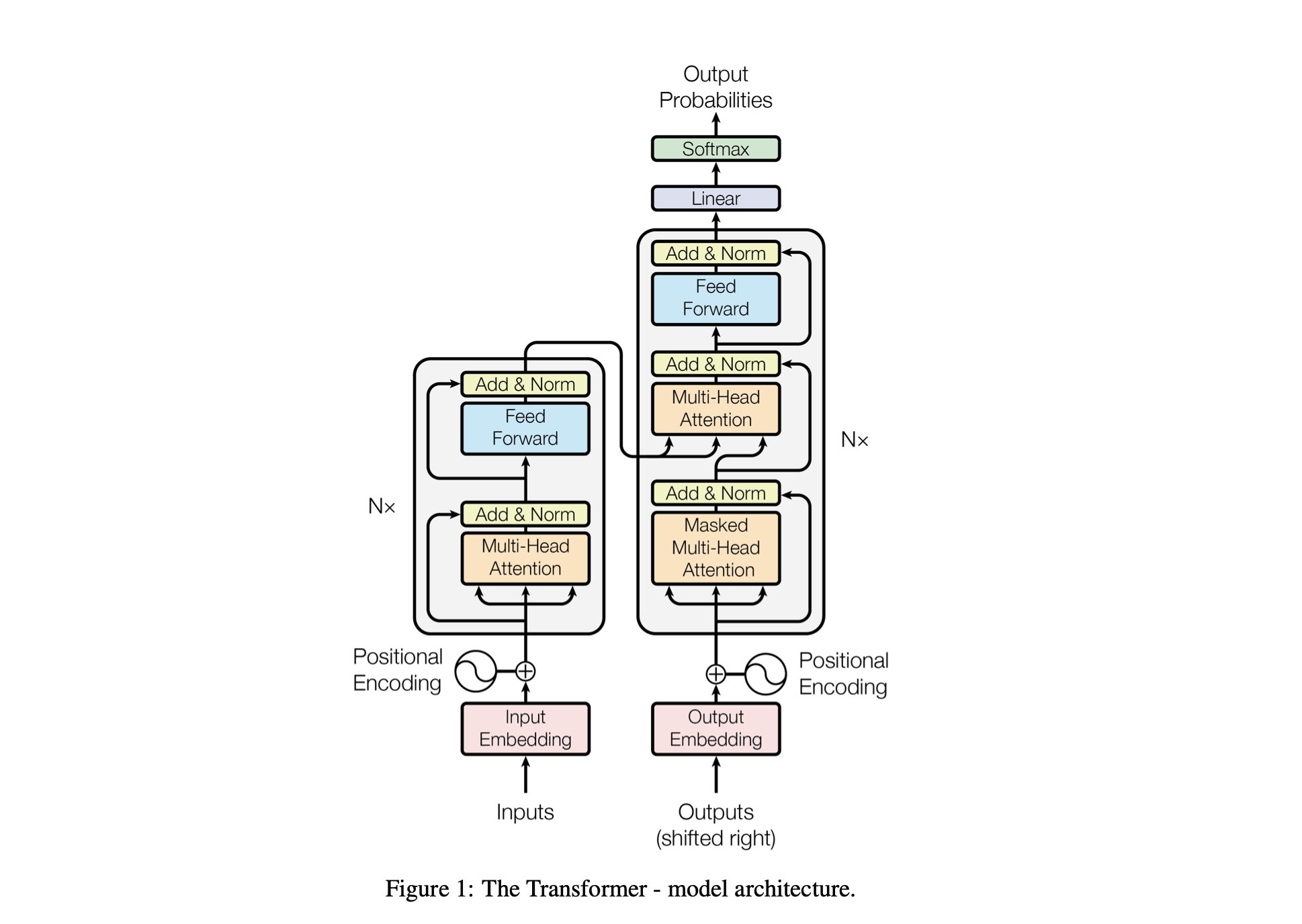
모델의 성능은 다음 하이퍼파라미터를 사용하여 조정됩니다.
batch_size : 훈련 중에 병렬로 처리되는 시퀀스 수block_size : 모델이 처리하는 시퀀스의 길이d_model : 모델의 기능 수(임베딩 크기)d_k : Attention 헤드당 특징 수입니다.num_iter : 모델이 실행할 총 훈련 반복 횟수Nx : 모델의 변압기 블록 또는 레이어 수입니다.eval_interval : 모델의 손실이 계산되고 평가되는 간격입니다.lr_rate : Adam 최적화 프로그램의 학습률device : 호환 가능한 GPU가 있으면 자동으로 'cuda' 로 설정되고, 그렇지 않으면 기본값은 'cpu' 입니다.eval_iters : 평가 손실을 평균화할 반복 횟수입니다.h : 다중 헤드 어텐션 메커니즘의 어텐션 헤드 수dropout_rate : 과적합을 방지하기 위해 훈련 중에 사용되는 드롭아웃 비율이러한 하이퍼파라미터는 과적합 없이 데이터로부터 학습하는 모델 능력의 균형을 맞추고 계산 리소스를 효과적으로 관리하기 위해 신중하게 선택되었습니다.
| 초매개변수 | CPU 모델 | GPU 모델 |
|---|---|---|
device | 'CPU' | 사용 가능한 경우 'cuda', 그렇지 않으면 'cpu' |
batch_size | 16 | 64 |
block_size | 8 | 256 |
num_iter | 10000 | 10000 |
eval_interval | 500 | 500 |
eval_iters | 100 | 200 |
d_model | 16 | 512 |
d_k | 4 | 16 |
Nx | 2 | 6 |
dropout_rate | 0.2 | 0.2 |
lr_rate | 0.005 (5e-3) | 0.001(1e-3) |
h | 2 | 6 |
open('./GPT Series/input.txt', 'r', encoding = 'utf-8')chars_to_int 및 int_to_chars 사용하여 어휘 사전을 생성합니다.encode 함수를 사용하여 문자열을 정수로 변환하고 decode 함수를 사용하여 다시 변환합니다.train_data ) 및 검증( valid_data ) 세트로 나눕니다.get_batch 함수는 학습을 위해 데이터를 미니 배치로 준비합니다.BigramLM 클래스의 모델 아키텍처를 정의합니다.미니 배치는 학습 데이터를 작은 배치로 나누는 기계 학습 기술입니다. 각 미니 배치는 모델 학습 중에 별도로 처리됩니다. 이 접근 방식은 다음에 도움이 됩니다.
# Function to create mini-batches for training or validation.
def get_batch ( split ):
# Select data based on training or validation split.
data = train_data if split == "train" else valid_data
# Generate random start indices for data blocks, ensuring space for 'block_size' elements.
ix = torch . randint ( len ( data ) - block_size , ( batch_size ,))
# Create input (x) and target (y) sequences from data blocks.
x = torch . stack ([ data [ i : i + block_size ] for i in ix ])
y = torch . stack ([ data [ i + 1 : i + block_size + 1 ] for i in ix ])
# Move data to GPU if available for faster processing.
x , y = x . to ( device ), y . to ( device )
return x , y | 요인 | 작은 배치 크기 | 대규모 배치 크기 |
|---|---|---|
| 그라데이션 노이즈 | 높음(업데이트의 차이가 더 많음) | 낮음(보다 일관된 업데이트) |
| 수렴 | 더 평평한 최소값을 포함하여 더 많은 솔루션을 탐색하는 경향이 있습니다. | 종종 더 날카로운 최소값으로 수렴됩니다. |
| 일반화 | 잠재적으로 더 나음(더 평평한 최소값으로 인해) | 잠재적으로 더 나쁠 수 있음(더 날카로운 최소값으로 인해) |
| 편견 | 낮음(훈련 데이터 패턴에 과적합될 가능성이 낮음) | 높음(훈련 데이터 패턴에 과적합될 수 있음) |
| 변화 | 더 높음(솔루션 공간에 대한 더 많은 탐색으로 인해) | 낮음(솔루션 공간에 대한 탐색이 적기 때문에) |
| 계산 비용 | 에포크당 더 높음(더 많은 업데이트) | 에포크당 더 낮음(업데이트 적음) |
| 메모리 사용량 | 낮추다 | 더 높은 |
estimate_loss 함수는 지정된 반복 횟수(eval_iters) 동안 모델의 평균 손실을 계산합니다. 매개변수에 영향을 주지 않고 모델의 성능을 평가하는 데 사용됩니다. 일관된 손실 계산을 위해 드롭아웃과 같은 특정 레이어를 비활성화하도록 모델이 평가 모드로 설정되어 있습니다. 학습 데이터와 검증 데이터 모두에 대한 평균 손실을 계산한 후 모델은 학습 모드로 되돌아갑니다. 이 기능은 훈련 과정을 모니터링하고 필요한 경우 조정하는 데 필수적입니다.
@ torch . no_grad () # Disables gradient calculation to save memory and computations
def estimate_loss ():
result = {} # Dictionary to store the results
model . eval () # Puts the model in evaluation mode
# Iterates over the data splits (training and validation)
for split in [ 'train' , 'valid_date' ]:
# Initializes a tensor to store the losses for each iteration
losses = torch . zeros ( eval_iters )
# Loops over the number of iterations to calculate the average loss
for e in range ( eval_iters ):
X , Y = get_batch ( split ) # Fetches a batch of data
logits , loss = model ( X , Y ) # Gets the model outputs and computes the loss
losses [ e ] = loss . item () # Records the loss for this iteration
# Stores the mean loss for the current split in the result dictionary
result [ split ] = losses . mean ()
model . train () # Sets the model back to training mode
return result # Returns the dictionary with the computed losses 위치 인코딩 : BigramLM 클래스의 positional_encodings_table 을 사용하여 모델에 위치 정보를 추가합니다. 변환기 아키텍처에서와 같이 문자 임베딩에 위치 인코딩을 추가합니다.
여기서는 PyTorch에서 신경망 모델을 훈련하기 위해 AdamW 최적화 프로그램을 설정하고 사용합니다. Adam 최적화 프로그램은 확률적 경사하강법의 다른 두 가지 확장인 AdaGrad와 RMSProp의 장점을 결합하기 때문에 많은 딥 러닝 시나리오에서 선호됩니다. Adam은 각 매개변수에 대한 적응형 학습률을 계산합니다. RMSProp과 같이 과거 제곱 기울기의 기하급수적으로 감소하는 평균을 저장하는 것 외에도 Adam은 운동량과 유사하게 과거 기울기의 기하급수적으로 감소하는 평균도 유지합니다. 이를 통해 최적화 프로그램은 신경망의 각 가중치에 대한 학습률을 조정할 수 있으며, 이는 복잡한 데이터 세트 및 아키텍처에 대한 보다 효과적인 교육으로 이어질 수 있습니다.
AdamW 가중치 감소가 최적화 프로세스에 통합되는 방식을 수정하여 가중치 감소가 그라디언트 업데이트와 잘 분리되지 않아 정규화의 차선 적용으로 이어지는 원래 Adam 최적화 프로그램의 문제를 해결합니다. AdamW를 사용하면 때때로 더 나은 훈련 성능과 보이지 않는 데이터에 대한 일반화가 발생할 수 있습니다. 우리는 표준 Adam 옵티마이저보다 가중치 감소를 더 효과적으로 처리할 수 있는 능력 때문에 AdamW를 선택했으며, 이는 잠재적으로 모델 훈련 및 일반화 개선으로 이어졌습니다.
optimizer = torch . optim . AdamW ( model . parameters (), lr = lr_rate )
for iter in range ( num_iter ):
# estimating the loss for per X interval
if iter % eval_interval == 0 :
losses = estimate_loss ()
print ( f"step { iter } : train loss is { losses [ 'train' ]:.5f } and validation loss is { losses [ 'valid_date' ]:.5f } " )
# sampling a mini batch of data
xb , yb = get_batch ( "train" )
# Forward Pass
logits , loss = model ( xb , yb )
# Zeroing Gradients: Before computing the gradients, existing gradients are reset to zero. This is necessary because gradients accumulate by default in PyTorch.
optimizer . zero_grad ( set_to_none = True )
# Backward Pass or Backpropogation: Computing Gradients
loss . backward ()
# Updating the Model Parameters
optimizer . step ()Self-Attention은 모델이 입력 데이터의 여러 부분의 중요성을 다르게 평가할 수 있도록 하는 메커니즘입니다. 이는 모델이 예측을 위해 입력 시퀀스의 관련 부분에 집중할 수 있도록 하는 Transformer 아키텍처의 핵심 구성 요소입니다.
Dot-Product Attention : 쿼리와 키 간의 내적을 기반으로 값의 가중 합계를 계산하는 간단한 주의 메커니즘입니다.
Scaled Dot-Product Attention : 키의 차원에 따라 내적을 축소하여 훈련 중에 그라데이션이 너무 작아지는 것을 방지하는 내적 주의에 대한 개선입니다.
OneHeadSelfAttention : 모델이 입력 시퀀스의 다양한 위치에 주의를 기울일 수 있도록 하는 단일 방향 self-attention 메커니즘의 구현입니다. SelfAttention 클래스는 Attention 메커니즘과 해당 확장 버전의 직관을 보여줍니다.
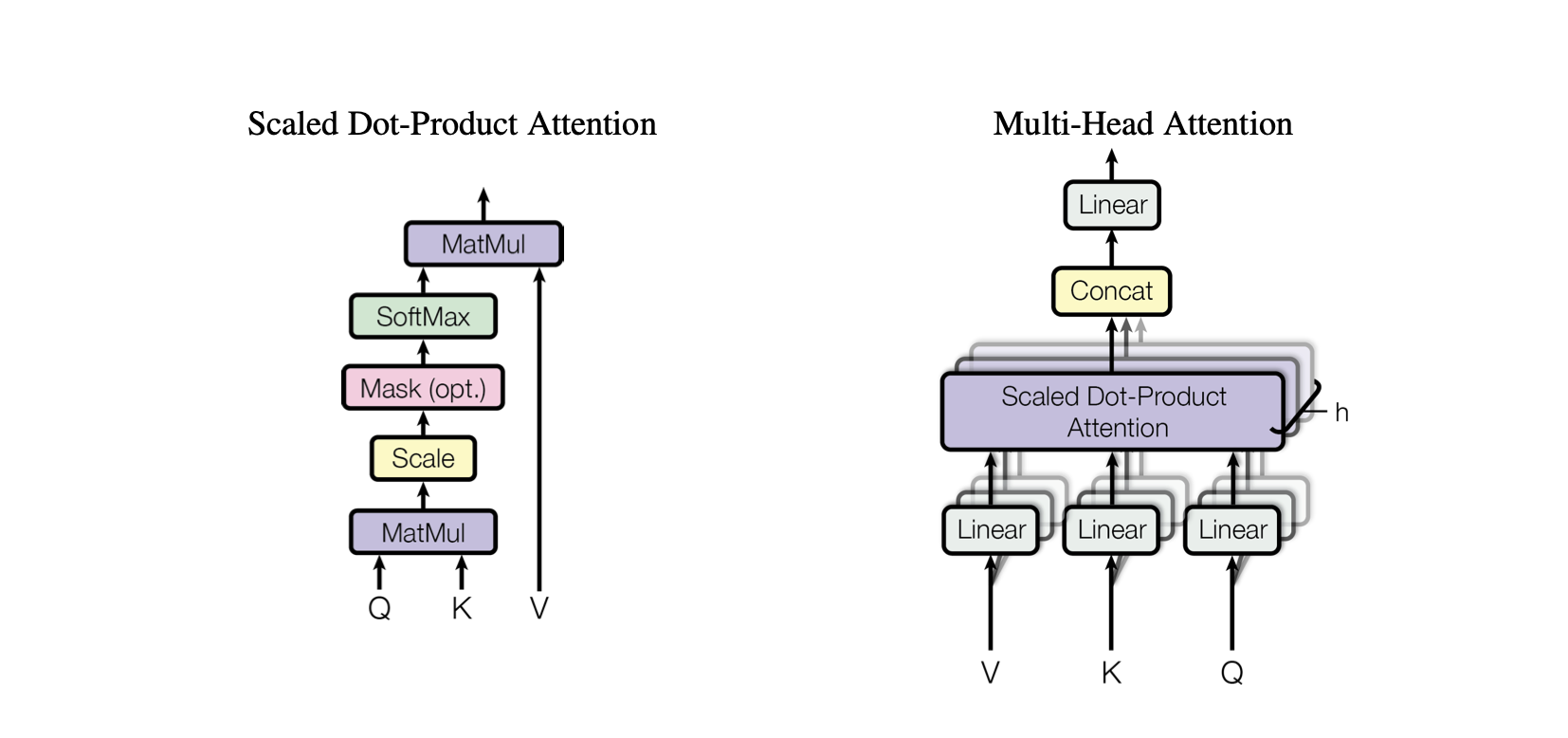
Baby GPT 프로젝트의 각 해당 모델은 Self-Attention 메커니즘 뒤에 있는 직관에서 시작하여 내적 및 스케일링된 내적 관심의 실제 구현이 뒤따르며 이전 모델을 점진적으로 기반으로 구축되어 단일 통합으로 마무리됩니다. 머리 자기 주의 모듈.
class SelfAttention ( nn . Module ):
"""Self Attention (One Head)"""
""" d_k = C """
def __init__ ( self , d_k ):
super (). __init__ () #superclass initialization for proper torch functionality
# keys
self . keys = nn . Linear ( d_model , d_k , bias = False )
# queries
self . queries = nn . Linear ( d_model , d_k , bias = False )
# values
self . values = nn . Linear ( d_model , d_k , bias = False )
# buffer for the model
self . register_buffer ( 'tril' , torch . tril ( torch . ones ( block_size , block_size )))
def forward ( self , X ):
"""Computing Attention Matrix"""
B , T , C = X . shape
# Keys matrix K
K = self . keys ( X ) # (B, T, C)
# Query matrix Q
Q = self . queries ( X ) # (B, T, C)
# Scaled Dot Product
scaled_dot_product = Q @ K . transpose ( - 2 , - 1 ) * 1 / math . sqrt ( C ) # (B, T, T)
# Masking upper triangle
scaled_dot_product_masked = scaled_dot_product . masked_fill ( self . tril [: T , : T ] == 0 , float ( '-inf' ))
# SoftMax transformation
attention_matrix = F . softmax ( scaled_dot_product_masked , dim = - 1 ) # (B, T, T)
# Weighted Aggregation
V = self . values ( X ) # (B, T, C)
output = attention_matrix @ V # (B, T, C)
retur SelfAttention 클래스는 Transformer 모델의 기본 구성 요소를 나타내며 단일 헤드로 self-attention 메커니즘을 캡슐화합니다. 구성 요소와 프로세스에 대한 통찰력은 다음과 같습니다.
초기화 : 생성자 __init__(self, d_k) 는 차원이 d_k 인 키, 쿼리 및 값에 대한 선형 레이어를 초기화합니다. 이러한 선형 변환은 후속 주의 계산을 위해 입력을 다양한 하위 공간에 투영합니다.
버퍼 : self.register_buffer('tril', torch.tril(torch.ones(block_size, block_size))) 하삼각 행렬을 모델 매개변수로 간주되지 않는 영구 버퍼로 등록합니다. 이 행렬은 각 계산 단계에서 미래 위치가 고려되지 않도록 주의 메커니즘에서 마스킹하는 데 사용됩니다(디코더 self-attention에 유용함).
Forward Pass : forward(self, X) 메서드는 self-attention 모듈의 모든 호출에서 수행되는 계산을 정의합니다.
MultiHeadAttention : MultiHeadAttention 클래스의 여러 SelfAttention 헤드 출력을 결합합니다. MultiHeadAttention 클래스는 이전 단계의 헤드 하나를 사용하여 self-attention 메커니즘의 확장된 구현이지만 이제 여러 개의 attention 헤드가 병렬로 작동하며 각각은 입력의 서로 다른 부분에 집중합니다.
class MultiHeadAttention ( nn . Module ):
"""Multi Head Self Attention"""
"""h: #heads"""
def __init__ ( self , h , d_k ):
super (). __init__ ()
# initializing the heads, we want h times attention heads wit size d_k
self . heads = nn . ModuleList ([ SelfAttention ( d_k ) for _ in range ( h )])
# adding linear layer to project the concatenated heads to the original dimension
self . projections = nn . Linear ( h * d_k , d_model )
# adding dropout layer
self . droupout = nn . Dropout ( dropout_rate )
def forward ( self , X ):
# running multiple self attention heads in parallel and concatinate them at channel dimension
combined_attentions = torch . cat ([ h ( X ) for h in self . heads ], dim = - 1 )
# projecting the concatenated heads to the original dimension
combined_attentions = self . projections ( combined_attentions )
# applying dropout
combined_attentions = self . droupout ( combined_attentions )
return combined_attentions
FeedForward : FeedForward 클래스 내에서 ReLU 활성화를 사용하여 피드포워드 신경망을 구현합니다. 원래 Transformer 모델에서와 같이 완전히 연결된 피드포워드를 모델에 추가합니다.
class FeedForward ( nn . Module ):
"""FeedForward Layer with ReLU activation function"""
def __init__ ( self , d_model ):
super (). __init__ ()
self . net = nn . Sequential (
# 2 linear layers with ReLU activation function
nn . Linear ( d_model , 4 * d_model ),
nn . ReLU (),
nn . Linear ( 4 * d_model , d_model ),
nn . Dropout ( dropout_rate )
)
def forward ( self , X ):
# applying the feedforward layer
return self . net ( X ) TransformerBlocks : Block 클래스를 사용하여 변환기 블록을 쌓아 더 깊은 네트워크 아키텍처를 만듭니다. 깊이 및 복잡성: 신경망에서 깊이는 데이터가 처리되는 레이어 수를 나타냅니다. 각각의 추가 레이어(또는 Transformers의 경우 블록)를 통해 네트워크는 입력 데이터의 더 복잡하고 추상적인 기능을 캡처할 수 있습니다.
순차 처리: 각 Transformer 블록은 이전 블록의 출력을 처리하여 점차적으로 입력에 대한 보다 정교한 이해를 구축합니다. 이러한 순차적 처리를 통해 네트워크는 데이터의 심층적이고 계층화된 표현을 개발할 수 있습니다. 변압기 블록의 구성 요소
# ---------------------------------- Blocks ----------------------------------#
class Block ( nn . Module ):
"""Multiple Blocks of Transformer"""
def __init__ ( self , d_model , h ):
super (). __init__ ()
d_k = d_model // h
# Layer 4: Adding Attention layer
self . attention_head = MultiHeadAttention ( h , d_k ) # h heads of d_k dimensional self-attention
# Layer 5: Feed Forward layer
self . feedforward = FeedForward ( d_model )
# Layer Normalization 1
self . ln1 = nn . LayerNorm ( d_model )
# Layer Normalization 2
self . ln2 = nn . LayerNorm ( d_model )
# Adding additional X for Residual Connections
def forward ( self , X ):
X = X + self . attention_head ( self . ln1 ( X ))
X = X + self . feedforward ( self . ln2 ( X ))
return X ResidualConnections : 잔여 연결을 포함하도록 Block 클래스를 강화하여 학습 효율성을 향상시킵니다. 스킵 연결이라고도 알려진 잔여 연결은 심층 신경망 설계, 특히 Transformer 모델의 중요한 혁신입니다. 이는 심층 네트워크 훈련의 주요 과제 중 하나인 Vanishing Gradient 문제를 해결합니다.
# Adding additional X for Residual Connections
def forward ( self , X ):
X = X + self . attention_head ( self . ln1 ( X ))
X = X + self . feedforward ( self . ln2 ( X ))
return X LayerNorm : Block 클래스의 nn.LayerNorm(d_model) 사용하여 Transformer.Normalizing 레이어 출력에 레이어 정규화를 추가합니다.
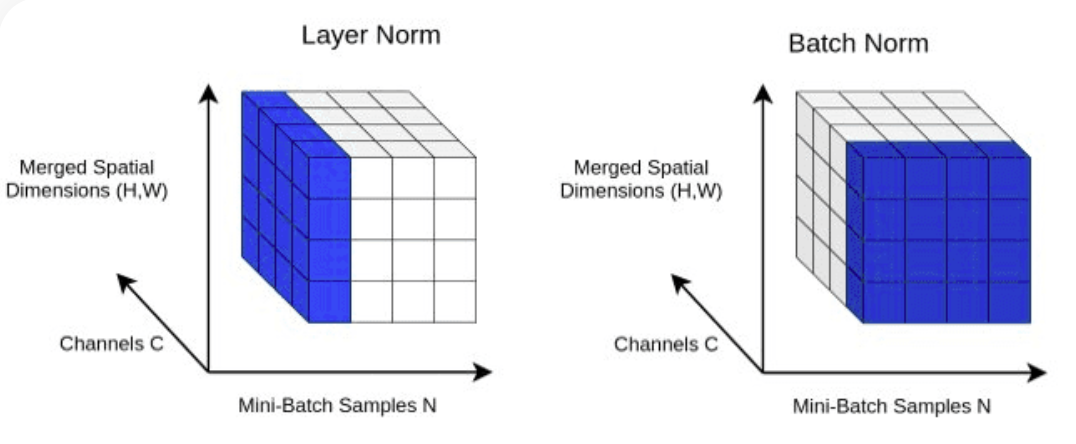
class LayerNorm :
def __init__ ( self , dim , eps = 1e-5 ):
self . eps = eps
self . gamma = torch . ones ( dim )
self . beta = torch . zeros ( dim )
def __call__ ( self , x ):
# orward pass calculaton
xmean = x . mean ( 1 , keepdim = True ) # layer mean
xvar = x . var ( 1 , keepdim = True ) # layer variance
xhat = ( x - xmean ) / torch . sqrt ( xvar + self . eps ) # normalize to unit variance
self . out = self . gamma * xhat + self . beta
return self . out
def parameters ( self ):
return [ self . gamma , self . beta ] Dropout : 과적합을 방지하기 위한 정규화 방법으로 SelfAttention 및 FeedForward 레이어에 추가됩니다. 다음에 드롭아웃을 추가합니다.
ScaleUp : batch_size , block_size , d_model , d_k 및 Nx 를 확장하여 모델의 복잡성을 높입니다. 이 더 큰 모델을 훈련하고 테스트하려면 CUDA 툴킷과 NVIDIA GPU가 장착된 머신이 필요합니다.
GPU 가속을 위해 CUDA를 사용해 보려면 CUDA를 지원하는 적절한 PyTorch 버전이 설치되어 있는지 확인하세요.
import torch
torch . cuda . is_available ()명령줄에서와 같이 PyTorch 설치 명령에 CUDA 버전을 지정하면 됩니다.
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113

