ke dialogue
1.0.0


이것은 논문의 구현입니다:
작업 중심 대화 시스템을 위한 매개 변수를 사용하여 지식 기반 학습 . Andrea Madotto , Samuel Cahyawijaya, Genta Indra Winata, Yan Xu, Zihan Liu, Zhaojiang Lin, Pascale Fung EMNLP 2020 결과 [PDF]
이 툴킷에 포함된 소스 코드나 데이터세트를 작업에 사용하는 경우 다음 논문을 인용해 주세요. Bibtex는 다음과 같습니다.
@article{madotto2020learning,
title={과제 중심 대화 시스템을 위한 매개변수를 사용하여 지식 기반 학습},
저자={Madotto, Andrea 및 Cahyawijaya, Samuel 및 Winata, Genta Indra 및 Xu, Yan 및 Liu, Zihan 및 Lin, Zhaojiang 및 Fung, Pascale},
저널={arXiv 사전 인쇄 arXiv:2009.13656},
연도={2020}
}
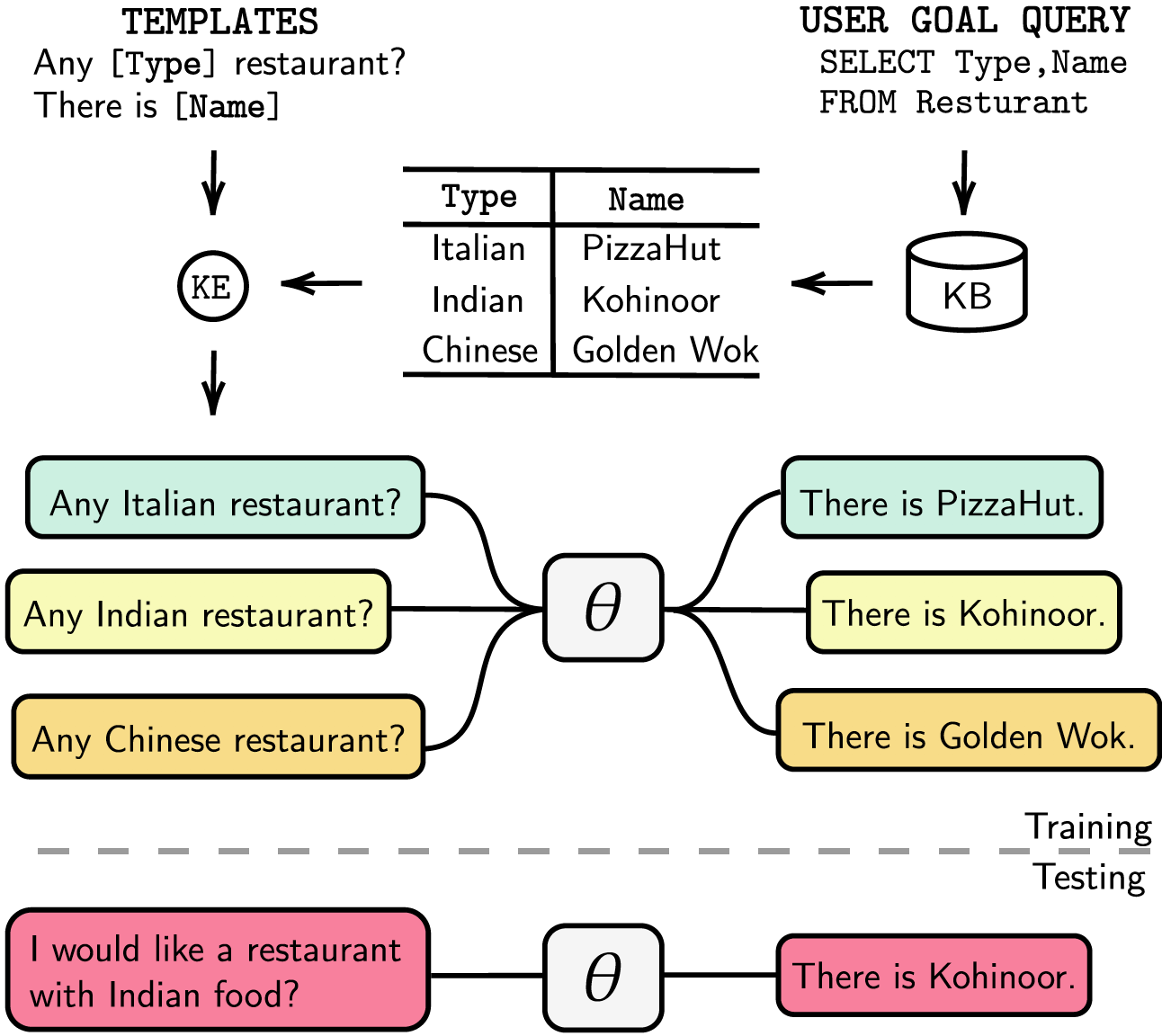
작업 지향 대화 시스템은 별도의 대화 상태 추적(DST) 및 관리 단계로 모듈화되거나 엔드투엔드 학습이 가능합니다. 두 경우 모두 지식 베이스(KB)는 사용자 요청을 이행하는 데 필수적인 역할을 합니다. 모듈화된 시스템은 DST를 사용하여 KB와 상호작용하는데, 이는 주석 및 추론 시간 측면에서 비용이 많이 듭니다. 엔드 투 엔드 시스템은 KB를 입력으로 직접 사용하지만 KB가 수백 항목보다 큰 경우 확장할 수 없습니다. 본 논문에서는 모든 크기의 KB를 모델 매개변수에 직접 삽입하는 방법을 제안합니다. 결과 모델에는 DST나 템플릿 응답이 필요하지 않으며 KB도 입력으로 필요하지 않으며 미세 조정을 통해 KB를 동적으로 업데이트할 수 있습니다. 우리는 소형, 중형, 대형 KB 크기의 5가지 작업 중심 대화 데이터 세트에서 솔루션을 평가합니다. 우리의 실험은 엔드투엔드 모델이 매개변수에 지식 기반을 효과적으로 포함하고 평가된 모든 데이터 세트에서 경쟁력 있는 성능을 달성할 수 있음을 보여줍니다.
requirements.txt 에 대한 종속성을 나열했습니다. 다음을 실행하여 종속성을 설치할 수 있습니다.
❱❱❱ pip install -r requirements.txt 또한 우리 코드에는 apex 에 대한 fp16 지원도 포함되어 있습니다. https://github.com/NVIDIA/apex에서 패키지를 찾을 수 있습니다.
데이터세트 전처리된 데이터세트를 다운로드하고 zip 파일을 ./knowledge_embed/babi5 폴더에 넣습니다. 다음을 실행하여 zip 파일을 추출합니다.
❱❱❱ cd ./knowledge_embed/babi5
❱❱❱ unzip dialog-bAbI-tasks.zip다음을 통해 bAbI-5 데이터세트에서 어휘화된 대화를 생성합니다.
❱❱❱ python3 generate_delexicalization_babi.py다음을 통해 bAbI-5 데이터세트에서 어휘화된 데이터를 생성합니다.
❱❱❱ python generate_dialogues_babi5.py --dialogue_path ./dialog-bAbI-tasks/dialog-babi-task5trn_record-delex.txt --knowledge_path ./dialog-bAbI-tasks/dialog-babi-kb-all.txt --output_folder ./dialog-bAbI-tasks --num_augmented_knowledge <num_augmented_knowledge> --num_augmented_dialogue <num_augmented_dialogues> --random_seed 0 여기서 최대 <num_augmented_knowledge> 는 558(권장)이고 <num_augmented_dialogues> 는 264입니다. 이는 bAbI-5 데이터세트의 지식 수와 대화 수에 해당하기 때문입니다.
GPT-2 미세 조정
bAbI 훈련 세트에서 미세 조정된 GPT-2 모델의 체크포인트를 제공합니다. 다음 명령을 사용하여 직접 모델을 학습하도록 선택할 수도 있습니다.
❱❱❱ cd ./modeling/babi5
❱❱❱ python main.py --model_checkpoint gpt2 --dataset BABI --dataset_path ../../knowledge_embed/babi5/dialog-bAbI-tasks --n_epochs <num_epoch> --kbpercentage <num_augmented_dialogues> --kbpercentage 값은 어휘화에서 나온 <num_augmented_dialogues> 값과 같습니다. 이 매개변수는 열차 데이터세트에 삽입할 보강 파일을 선택하는 데 사용됩니다.
다음 스크립트를 실행하여 모델을 평가할 수 있습니다.
❱❱❱ python evaluate.py --model_checkpoint <model_checkpoint_folder> --dataset BABI --dataset_path ../../knowledge_embed/babi5/dialog-bAbI-tasks bAbI-5 채점 bAbI-5 작업 모델에 대한 채점기를 실행하려면 다음 명령을 실행할 수 있습니다. 득점자는 evaluate.py 에서 생성된 runs 폴더 아래의 모든 result.json 읽습니다.
python scorer_BABI5.py --model_checkpoint <model_checkpoint> --dataset BABI --dataset_path ../../knowledge_embed/babi5/dialog-bAbI-tasks --kbpercentage 0데이터세트
전처리된 데이터세트를 다운로드하고 zip 파일을 ./knowledge_embed/camrest 폴더에 넣습니다. 다음을 실행하여 zip 파일의 압축을 푼다.
❱❱❱ cd ./knowledge_embed/camrest
❱❱❱ unzip CamRest.zip다음을 통해 CamRest 데이터세트에서 어휘 해제된 대화를 생성합니다.
❱❱❱ python3 generate_delexicalization_CAMREST.py다음을 통해 CamRest 데이터세트에서 어휘화된 데이터를 생성합니다.
❱❱❱ python generate_dialogues_CAMREST.py --dialogue_path ./CamRest/train_record-delex.txt --knowledge_path ./CamRest/KB.json --output_folder ./CamRest --num_augmented_knowledge <num_augmented_knowledge> --num_augmented_dialogue <num_augmented_dialogues> --random_seed 0 여기서 최대 <num_augmented_knowledge> 는 201(권장)이고 <num_augmented_dialogues> 는 156입니다. 이는 CamRest 데이터 세트의 지식 수와 대화 수에 해당하므로 상당히 큽니다.
GPT-2 미세 조정
CamRest 학습 세트에서 미세 조정된 GPT-2 모델의 체크포인트를 제공합니다. 다음 명령을 사용하여 직접 모델을 학습하도록 선택할 수도 있습니다.
❱❱❱ cd ./modeling/camrest/
❱❱❱ python main.py --model_checkpoint gpt2 --dataset CAMREST --dataset_path ../../knowledge_embed/camrest/CamRest --n_epochs <num_epoch> --kbpercentage <num_augmented_dialogues> --kbpercentage 값은 어휘화에서 나온 <num_augmented_dialogues> 값과 같습니다. 이 매개변수는 열차 데이터세트에 삽입할 보강 파일을 선택하는 데 사용됩니다.
다음 스크립트를 실행하여 모델을 평가할 수 있습니다.
❱❱❱ python evaluate.py --model_checkpoint <model_checkpoint_folder> --dataset CAMREST --dataset_path ../../knowledge_embed/camrest/CamRest CamRest 채점 bAbI 5 작업 모델에 대한 채점기를 실행하려면 다음 명령을 실행할 수 있습니다. 득점자는 evaluate.py 에서 생성된 runs 폴더 아래의 모든 result.json 읽습니다.
python scorer_CAMREST.py --model_checkpoint <model_checkpoint> --dataset CAMREST --dataset_path ../../knowledge_embed/camrest/CamRest --kbpercentage 0데이터세트
전처리된 데이터 세트를 다운로드하여 ./knowledge_embed/smd 폴더에 넣습니다.
❱❱❱ cd ./knowledge_embed/smd
❱❱❱ unzip SMD.zipGPT-2 미세 조정
SMD 트레이닝 세트로 미세 조정된 GPT-2 모델의 체크포인트를 제공합니다. 체크포인트를 다운로드하여 ./modeling 폴더에 넣습니다.
❱❱❱ cd ./knowledge_embed/smd
❱❱❱ mkdir ./runs
❱❱❱ unzip ./knowledge_embed/smd/SMD_gpt2_graph_False_adj_False_edge_False_unilm_False_flattenKB_False_historyL_1000000000_lr_6.25e-05_epoch_10_weighttie_False_kbpercentage_0_layer_12.zip -d ./runs다음 명령을 사용하여 직접 모델을 학습하도록 선택할 수도 있습니다.
❱❱❱ cd ./modeling/smd
❱❱❱ python main.py --dataset SMD --lr 6.25e-05 --n_epochs 10 --kbpercentage 0 --layers 12지식이 내장된 대화 준비
먼저, SQL 쿼리를 위한 데이터베이스를 구축해야 합니다.
❱❱❱ cd ./knowledge_embed/smd
❱❱❱ python generate_dialogues_SMD.py --build_db --split test 그런 다음 도메인별로 미리 디자인된 템플릿을 기반으로 대화 상자를 생성합니다. 다음 명령을 사용하면 weather 도메인에서 대화를 생성할 수 있습니다. 다른 두 도메인에서 대화를 생성하려면 dialogue_path 및 domain 인수에서 weather navigate 또는 schedule 으로 바꾸십시오. num_augmented_dialogue 인수를 변경하여 재 어휘화 프로세스에 사용되는 템플릿 수를 변경할 수도 있습니다.
❱❱❱ python generate_dialogues_SMD.py --split test --dialogue_path ./templates/weather_template.txt --domain weather --num_augmented_dialogue 100 --output_folder ./SMD/test미세 조정된 GPT-2 모델을 테스트 세트에 적용
❱❱❱ python evaluate_finetune.py --dataset SMD --model_checkpoint runs/SMD_gpt2_graph_False_adj_False_edge_False_unilm_False_flattenKB_False_historyL_1000000000_lr_6.25e-05_epoch_10_weighttie_False_kbpercentage_0_layer_12 --top_k 1 --eval_indices 0,303 --filter_domain ""실험을 병렬로 실행하여 미세 조정 프로세스의 속도를 높일 수도 있습니다. 코드 #L14에서 GPU 설정을 수정하세요.
❱❱❱ python runner_expe_SMD.py 데이터세트
전처리된 데이터세트를 다운로드하여 ./knowledge_embed/mwoz 폴더에 넣습니다.
❱❱❱ cd ./knowledge_embed/mwoz
❱❱❱ unzip mwoz.zip지식이 포함된 대화 준비(위의 zip 파일을 다운로드한 경우 이 단계를 건너뛸 수 있습니다)
다음을 실행하여 데이터세트를 준비할 수 있습니다.
❱❱❱ bash generate_MWOZ_all_data.sh셸 스크립트는 다음을 호출하여 MWOZ 데이터세트에서 어휘 해제된 대화를 생성합니다.
❱❱❱ python generate_delex_MWOZ_ATTRACTION.py
❱❱❱ python generate_delex_MWOZ_HOTEL.py
❱❱❱ python generate_delex_MWOZ_RESTAURANT.py
❱❱❱ python generate_delex_MWOZ_TRAIN.py
❱❱❱ python generate_redelex_augmented_MWOZ.py
❱❱❱ python generate_MWOZ_dataset.pyGPT-2 미세 조정
MWOZ 훈련 세트에서 미세 조정된 GPT-2 모델의 체크포인트를 제공합니다. 체크포인트를 다운로드하여 ./modeling 폴더에 넣습니다.
❱❱❱ cd ./knowledge_embed/mwoz
❱❱❱ mkdir ./runs
❱❱❱ unzip ./mwoz.zip -d ./runs다음 명령을 사용하여 직접 모델을 학습하도록 선택할 수도 있습니다.
❱❱❱ cd ./modeling/mwoz
❱❱❱ python main.py --model_checkpoint gpt2 --dataset MWOZ_SINGLE --max_history 50 --train_batch_size 6 --kbpercentage 100 --fp16 O2 --gradient_accumulation_steps 3 --balance_sampler --n_epochs 10 시작하기 우리는 그래프 데이터 처리를 위해 neo4j 커뮤니티 서버 에디션과 apoc 라이브러리를 사용합니다. apoc neo4j 에서 쿼리를 병렬화하는 데 사용되므로 대규모 그래프를 더 빠르게 처리할 수 있습니다.
데이터 세트 섹션으로 진행하기 전에 neo4j (https://neo4j.com/download-center/#community) 및 apoc (https://neo4j.com/developer/neo4j-apoc/)이 설치되어 있는지 확인해야 합니다. 귀하의 시스템에서.
CYPHER 및 apoc 구문에 익숙하지 않은 경우 https://neo4j.com/developer/cypher/ 및 https://neo4j.com/blog/intro-user-defined-procedures-apoc/ 의 튜토리얼을 따를 수 있습니다.
데이터세트 원본 데이터세트를 다운로드하고 zip 파일을 ./knowledge_embed/opendialkg 폴더에 넣습니다. 다음을 실행하여 zip 파일을 추출합니다.
❱❱❱ cd ./knowledge_embed/opendialkg
❱❱❱ unzip https://drive.google.com/file/d/1llH4-4-h39sALnkXmGR8R6090xotE0PE/view?usp=sharing.zip다음을 통해 opendialkg 데이터세트에서 어휘화된 대화를 생성합니다( 경고 : 실행하는 데 약 12시간이 필요함).
❱❱❱ python3 generate_delexicalization_DIALKG.py 이 스크립트는 어휘화된 대화를 생성하는 데 사용되는 ./opendialkg/dialogkg_train_meta.pt 를 생성합니다. 그런 다음 다음을 통해 opendialkg 데이터세트에서 어휘화된 대화를 생성할 수 있습니다.
❱❱❱ python generate_dialogues_DIALKG.py --random_seed <random_seed> --batch_size 100 --max_iteration <max_iter> --stop_count <stop_count> --connection_string bolt://localhost:7687 이 스크립트는 최대 batch_size * max_iter 샘플의 대화 샘플을 생성하지만 모든 배치에는 유효한 후보가 없어 샘플 수가 줄어들 가능성이 있습니다. 생성 수는 생성된 샘플 수가 지정된 stop_count 보다 크면 생성을 중지하는 stop_count 라는 또 다른 요소에 의해 제한됩니다. 파일은 4개의 파일을 생성합니다: ./opendialkg/db_count_records_{random_seed}.csv , ./opendialkg/used_count_records_{random_seed}.csv 및 ./opendialkg/generation_iteration_{random_seed}.csv Generation_iteration_{random_seed}.csv 이는 배포 이동을 확인하는 데 사용됩니다. DB에 포함됩니다. 및 생성된 샘플이 포함된 ./opendialkg/generated_dialogue_bs100_rs{random_seed}.json .
참고 사항 :
generate_delexicalization_DIALKG.py 및 generate_dialogues_DIALKG.py 내에서 neo4j 비밀번호를 수동으로 변경해야 할 수도 있습니다.GPT-2 미세 조정
opendialkg training set에서 미세 조정된 GPT-2 모델의 체크포인트를 제공합니다. 다음 명령을 사용하여 직접 모델을 학습하도록 선택할 수도 있습니다.
❱❱❱ cd ./modeling/opendialkg
❱❱❱ python main.py --dataset_path ../../knowledge_embed/opendialkg/opendialkg --model_checkpoint gpt2 --dataset DIALKG --n_epochs 50 --kbpercentage <random_seed> --train_batch_size 8 --valid_batch_size 8 --kbpercentage 값은 어휘화에서 나온 <random_seed> 값과 같습니다. 이 매개변수는 열차 데이터세트에 삽입할 보강 파일을 선택하는 데 사용됩니다.
다음 스크립트를 실행하여 모델을 평가할 수 있습니다.
❱❱❱ python evaluate.py --model_checkpoint <model_checkpoint_folder> --dataset DIALKG --dataset_path ../../knowledge_embed/opendialkg/opendialkg OpenDialKG 채점 bAbI-5 작업 모델에 대한 채점기를 실행하려면 다음 명령을 실행할 수 있습니다. 득점자는 evaluate.py 에서 생성된 runs 폴더 아래의 모든 result.json 읽습니다.
python scorer_DIALKG5.py --model_checkpoint <model_checkpoint> --dataset DIALKG ../../knowledge_embed/opendialkg/opendialkg --kbpercentage 0 실험, 하이퍼파라미터, 평가 결과에 대한 자세한 내용은 본 연구의 주요 논문과 보충 자료에서 확인할 수 있습니다.


