GGS
1.0.0
GGS(Greedy Gaussian Segmentation)는 다변량 시계열 데이터를 효율적으로 분할하기 위한 Python 솔버입니다. 구현에 대한 자세한 내용은 http://stanford.edu/~boyd/papers/ggs.html의 논문을 참조하세요.
GGS 솔버는 nxT 데이터 행렬을 사용하고 n차원 벡터의 T 타임스탬프를 데이터가 다변량 가우스 분포의 독립 샘플로 잘 설명되는 세그먼트로 나눕니다. 이는 공분산 정규화 최대 우도 문제를 공식화하고 논문에 설명된 자세한 내용과 함께 욕심 많은 휴리스틱을 사용하여 문제를 해결함으로써 수행됩니다.
git clone [email protected]:davidhallac/GGS.git
cd GGS
python helloworld.py
ggs.py 새 파일과 동일한 디렉터리에 있는지 확인한 후 스크립트 시작 부분에 다음 코드를 추가하세요. from ggs import *
GGS 패키지에는 세 가지 주요 기능이 있습니다.
bps, objectives = GGS(data, Kmax, lamb)
특정 정규화 매개변수 람다에 대한 데이터에서 K개의 중단점을 찾습니다.
입력
데이터 - n차원 벡터의 T 타임스탬프가 있는 nxT 데이터 행렬
Kmax - 찾을 중단점 수
Lamb - 정규화된 공분산을 위한 정규화 매개변수
보고
bps - 목록 목록. 여기서 더 큰 목록의 요소 i 는 GGS 알고리즘의 K = i 에서 발견된 중단점 집합입니다.
목표 - 각 중간 단계의 목표 값 목록( K = 0 ~ Kmax의 경우)
meancovs = GGSMeanCov(data, breakpoints, lamb)
일련의 중단점을 고려하여 각 세그먼트의 평균과 정규화된 공분산을 찾습니다.
입력
데이터 - n차원 벡터의 T 타임스탬프가 있는 nxT 데이터 행렬
중단점 - 중단점 위치 목록
Lamb - 정규화된 공분산을 위한 정규화 매개변수
보고
meancovs - 데이터의 각 세그먼트에 대한 (평균, 공분산) 튜플 목록
cvResults = GGSCrossVal(data, Kmax=25, lambList = [0.1, 1, 10])
10겹 교차 검증을 실행하고 모든 (K, 람다) 쌍에 대한 학습 및 테스트 세트 가능성을 Kmax까지 반환합니다.
입력
데이터 - n차원 벡터의 T 타임스탬프가 있는 nxT 데이터 행렬
Kmax - GGS를 실행할 최대 중단점 수
LambList - 테스트할 정규화 매개변수 목록
보고
cvResults - LambList의 각 정규화 매개변수에 대한 (lamb, ([TrainLL],[TestLL])) 튜플 목록입니다. 여기서 TrainLL과 TestLL은 0에서 Kmax까지 모든 K 에 대한 10겹 교차 검증에 대한 평균 샘플당 로그 우도입니다.
추가 선택적 매개변수(위의 세 가지 기능 모두에 대한):
기능 = [] - 작업할 데이터의 특정 열 하위 집합을 선택합니다.
verbose = False - 알고리즘 실행 시 중간 단계를 인쇄합니다.
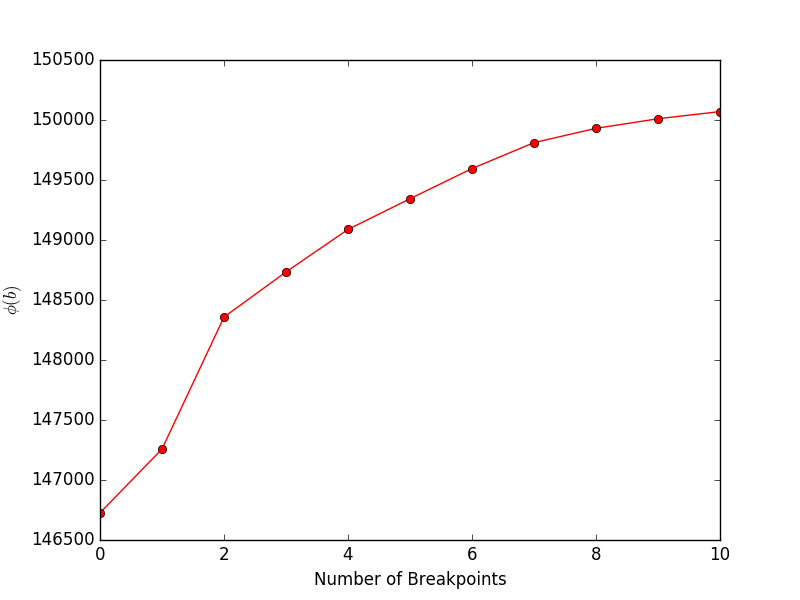
financeExample.py 실행하면 목표(논문의 방정식 4)와 중단점 수를 보여주는 다음 플롯이 생성됩니다.
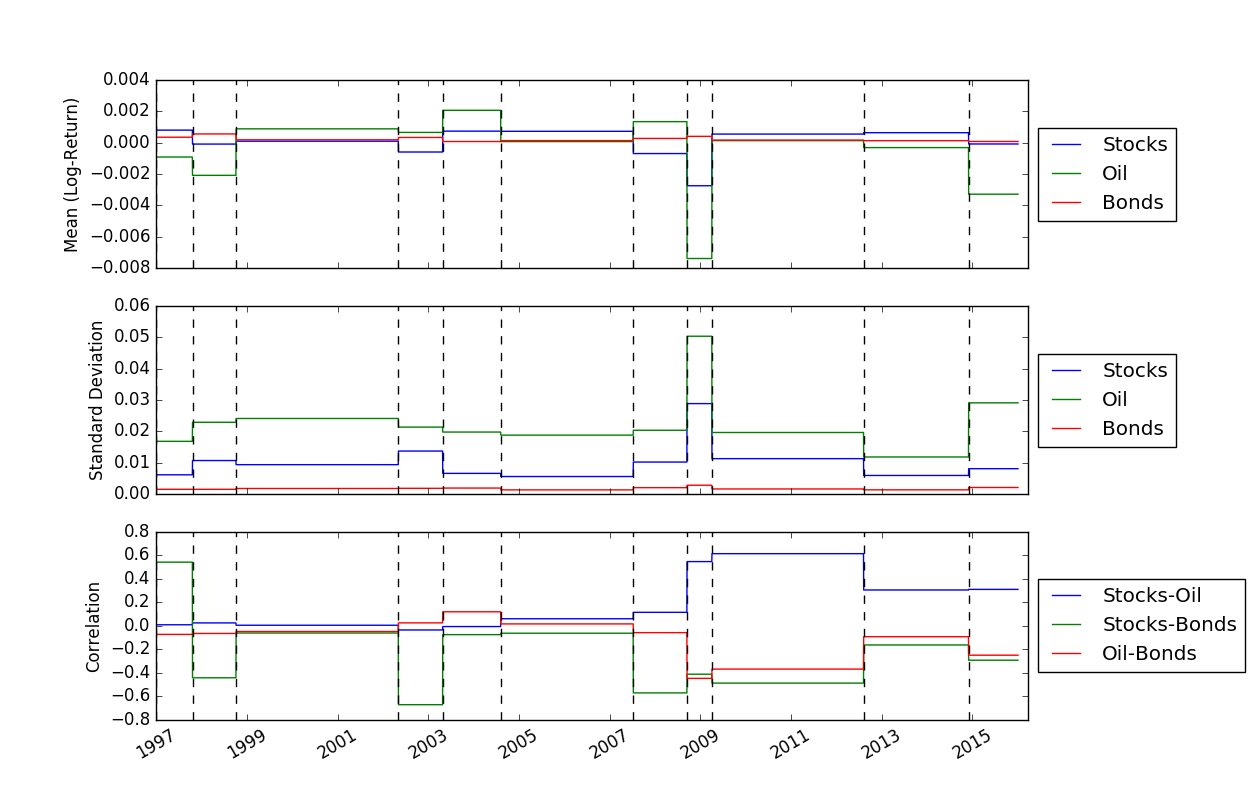
중단점 위치를 파악한 후에는 FindMeanCovs() 함수를 사용하여 각 세그먼트의 평균과 공분산을 찾을 수 있습니다. helloworld.py 의 예에서 세 신호의 평균, 분산, 공분산을 플로팅하면 다음과 같은 결과가 나옵니다.
K와 람다의 최적 값을 결정하는 데 유용할 수 있는 교차 검증을 실행하려면 다음 코드를 사용하여 데이터를 로드하고 교차 검증을 실행한 다음 테스트 및 훈련 가능성을 플로팅할 수 있습니다.
from ggs import *
import numpy as np
import matplotlib.pyplot as plt
filename = "Returns.txt"
data = np.genfromtxt(filename,delimiter=' ')
feats = [0,3,7]
#Run cross-validaton up to Kmax = 30, at lambda = 1e-4
maxBreaks = 30
lls = GGSCrossVal(data, Kmax=maxBreaks, lambList = [1e-4], features = feats, verbose = False)
trainLikelihood = lls[0][1][0]
testLikelihood = lls[0][1][1]
plt.plot(range(maxBreaks+1), testLikelihood)
plt.plot(range(maxBreaks+1), trainLikelihood)
plt.legend(['Test LL','Train LL'], loc='best')
plt.show()
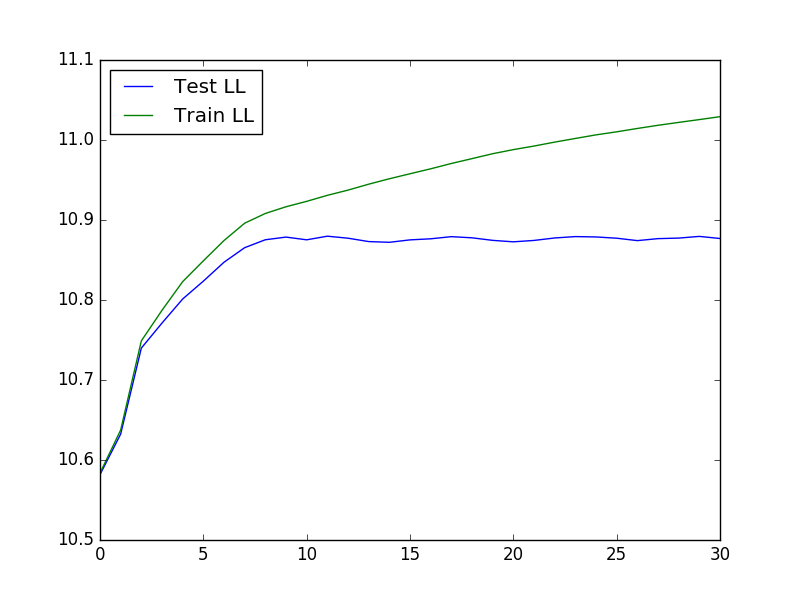
결과 플롯은 다음과 같습니다.
시계열 데이터의 그리디 가우스 분할 - D. Hallac, P. Nystrup 및 S. Boyd
데이비드 할락(David Hallac), 피터 니스트럽(Peter Nystrup), 스티븐 보이드(Stephen Boyd).


