T2M GPT
1.0.0
논문 "T2M-GPT: 개별 표현을 사용하여 텍스트 설명에서 인간 동작 생성"의 Pytorch 구현
[프로젝트 페이지] [페이퍼] [노트북 데모] [HuggingFace] [스페이스 데모] [T2M-GPT+]

우리 프로젝트가 귀하의 연구에 도움이 된다면 다음을 인용해 보십시오.
@inproceedings{zhang2023generating,
title={T2M-GPT: Generating Human Motion from Textual Descriptions with Discrete Representations},
author={Zhang, Jianrong and Zhang, Yangsong and Cun, Xiaodong and Huang, Shaoli and Zhang, Yong and Zhao, Hongwei and Lu, Hongtao and Shen, Xi},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2023},
}
| 텍스트: 한 남자가 앞으로 나와 물구나무서기를 합니다. | ||||
|---|---|---|---|---|
| GT | T2M | MDM | 모션 디퓨즈 | 우리 것 |
 | 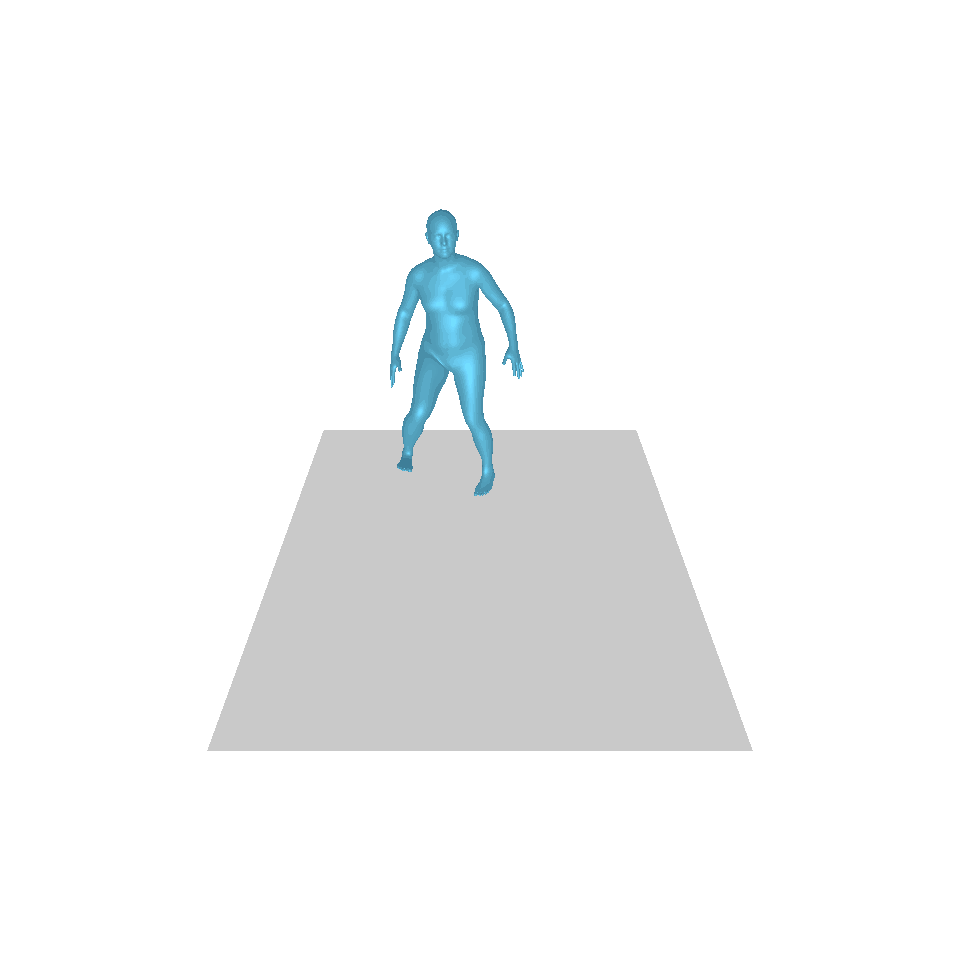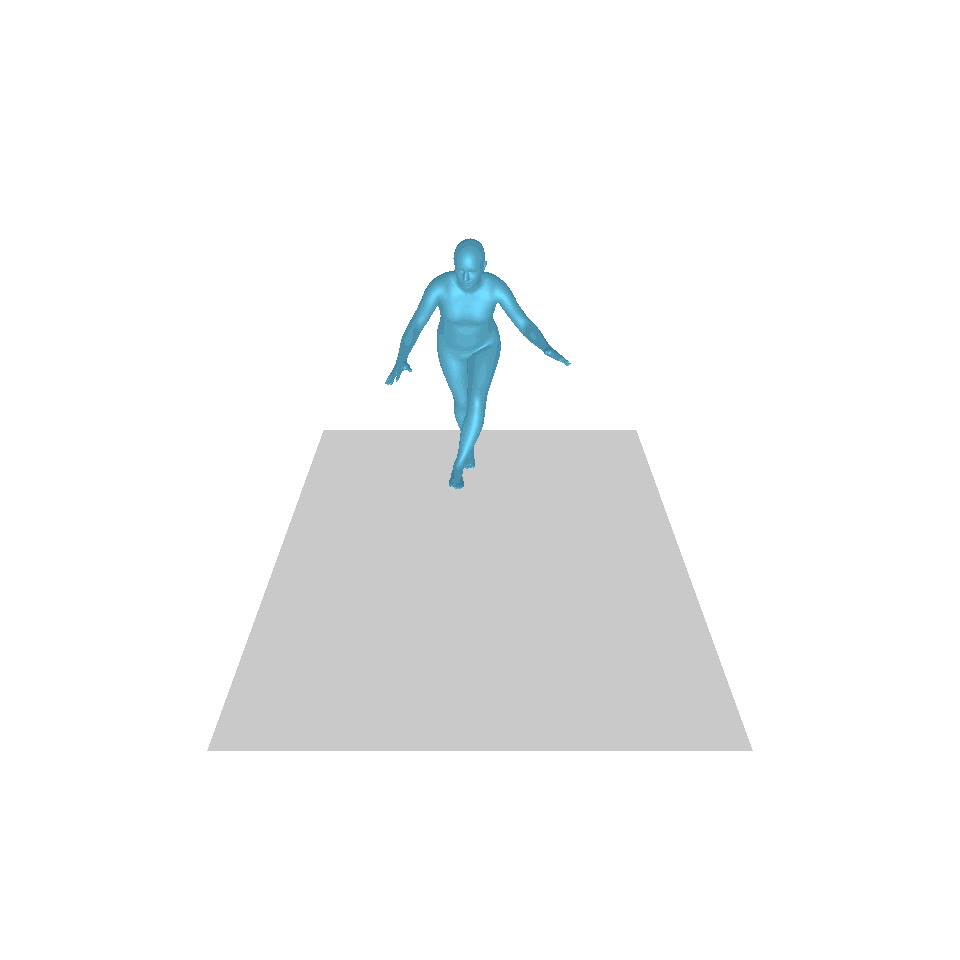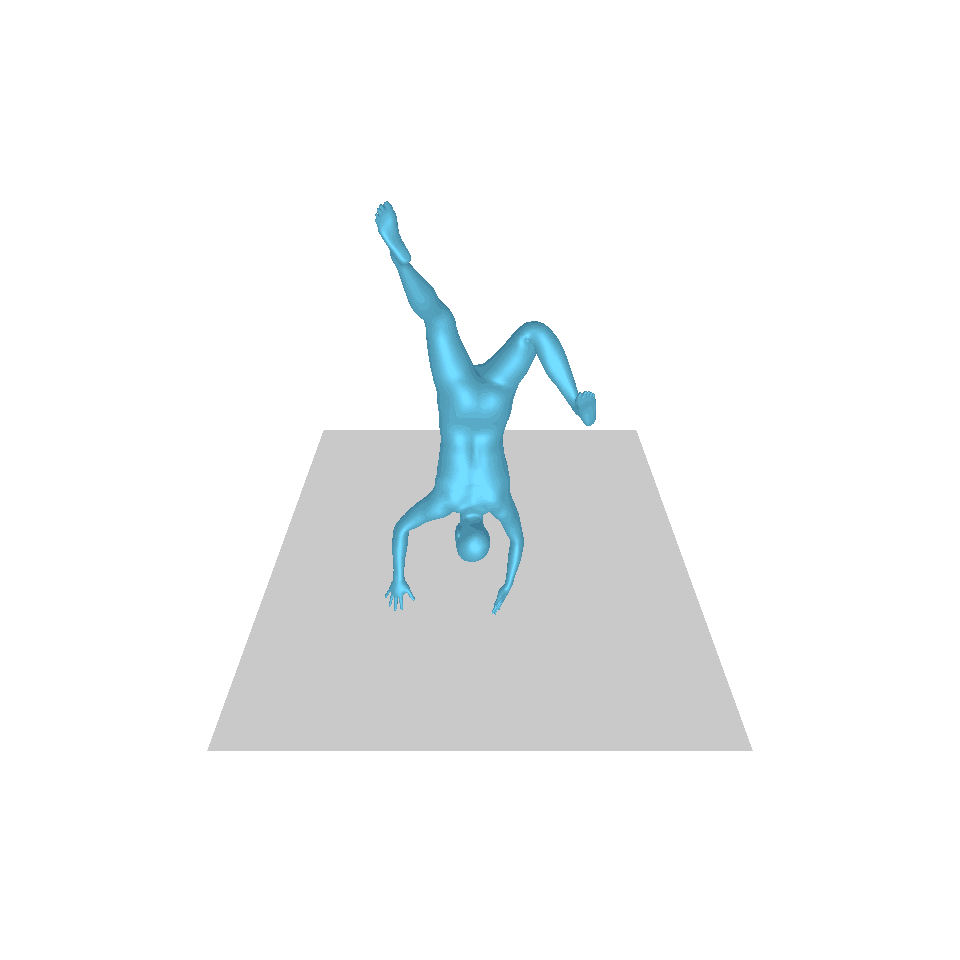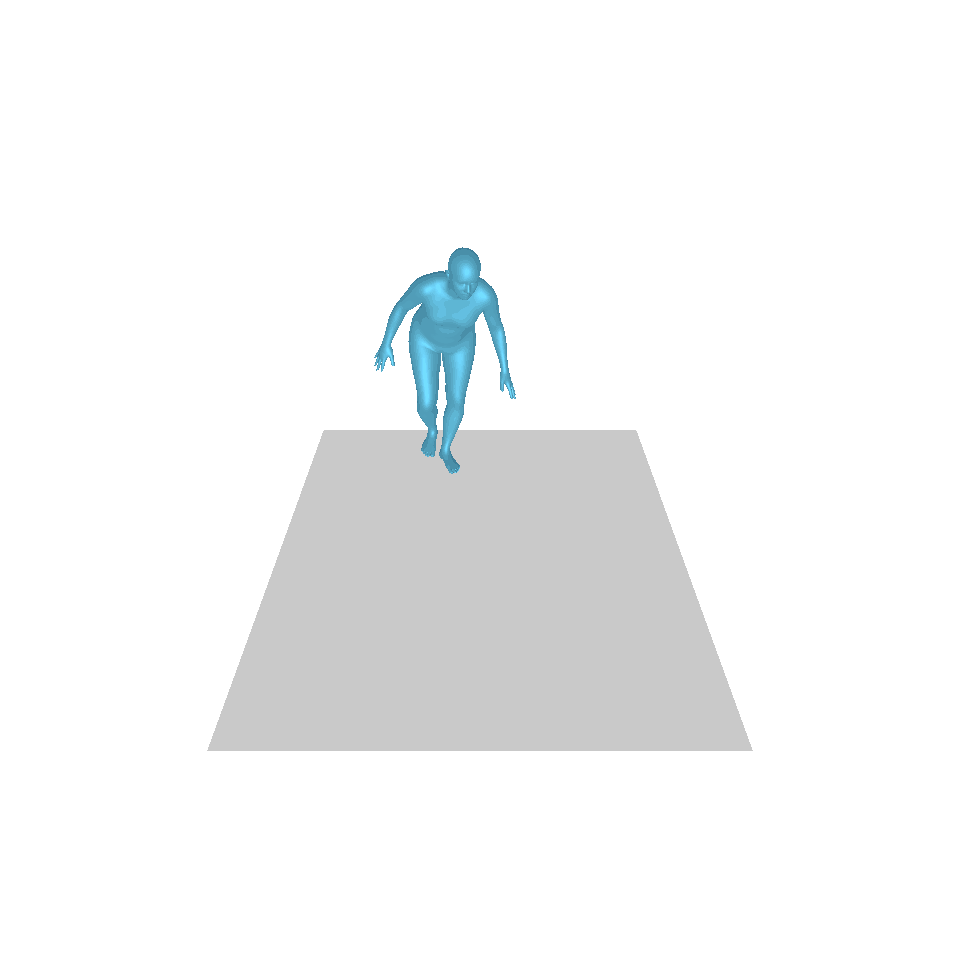 |  | 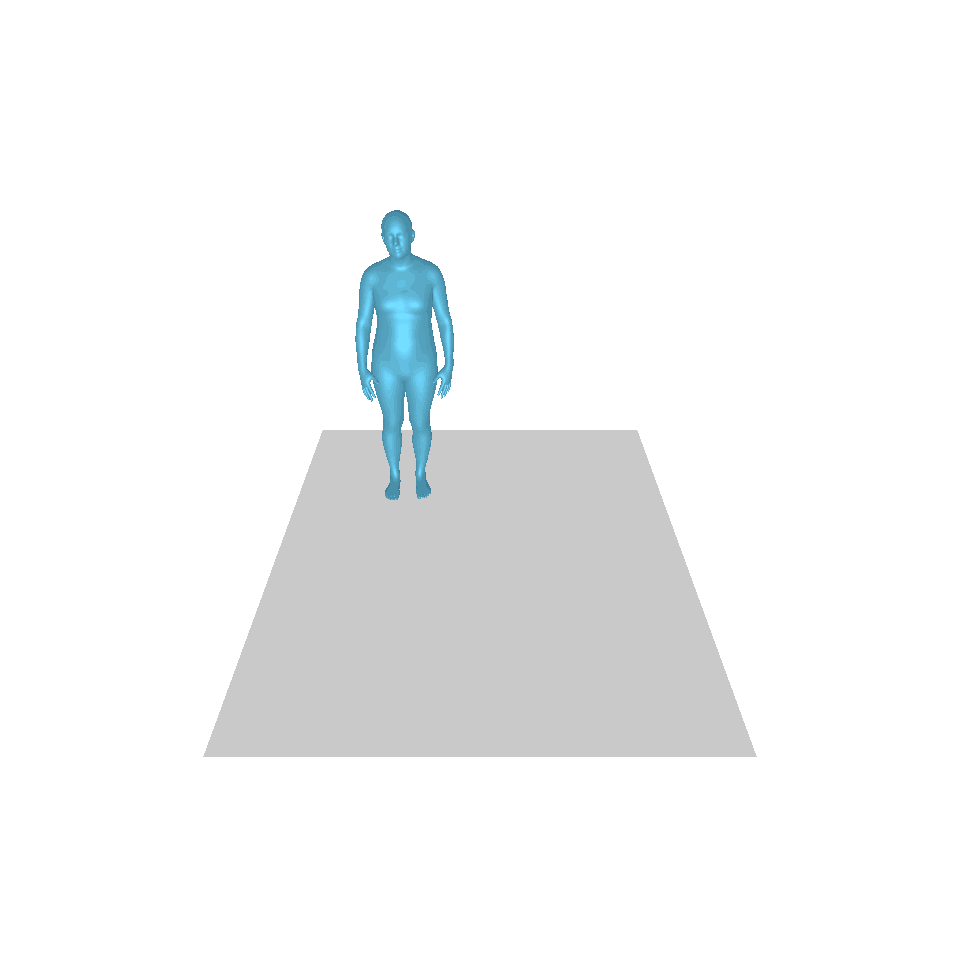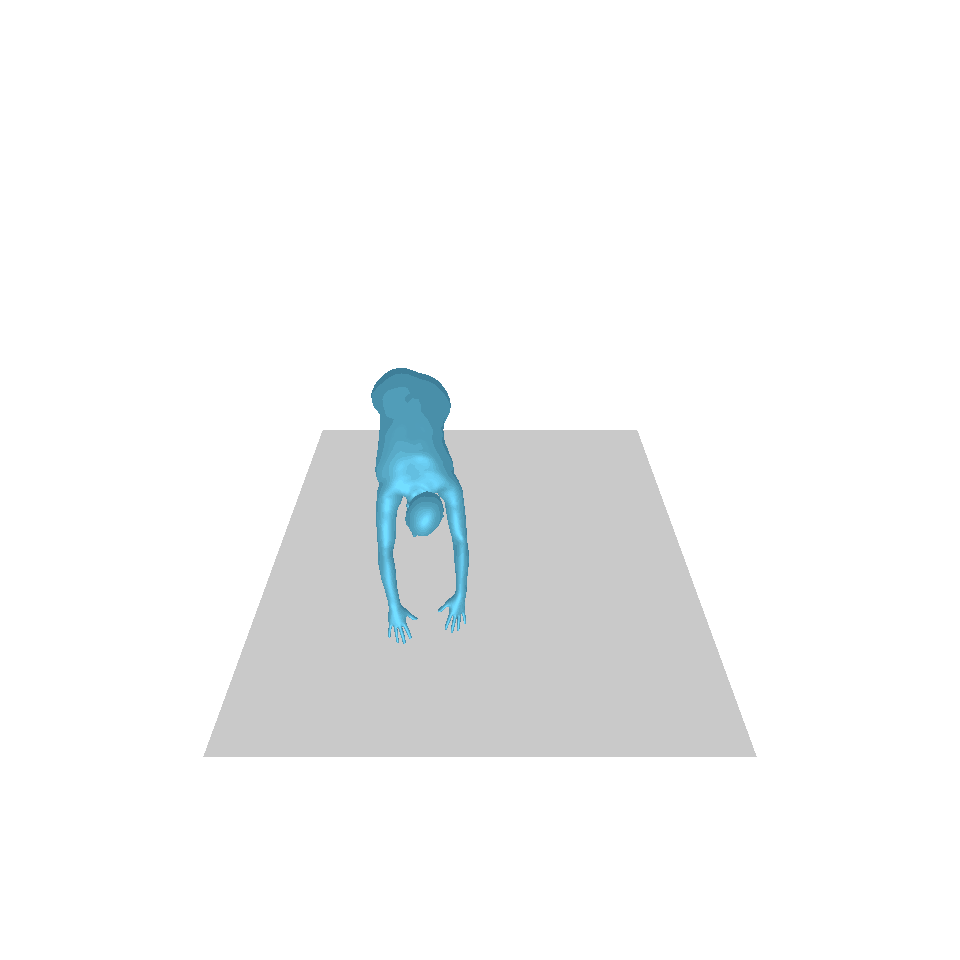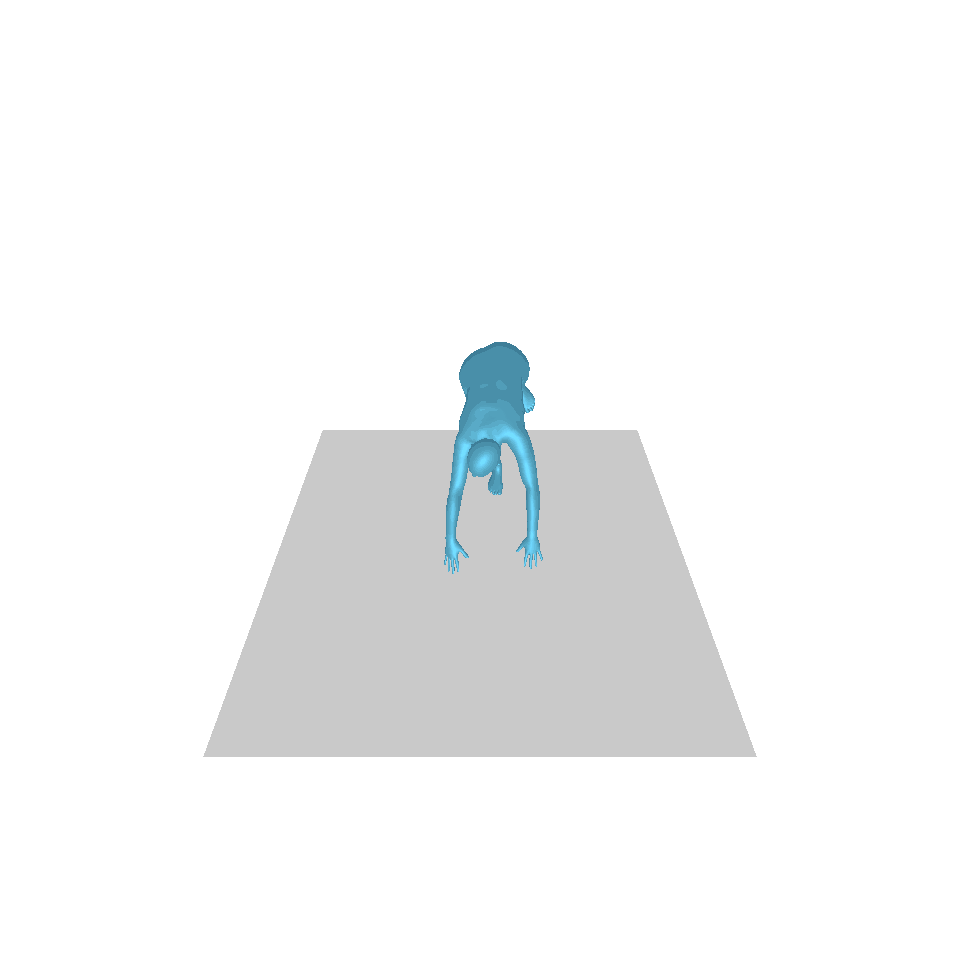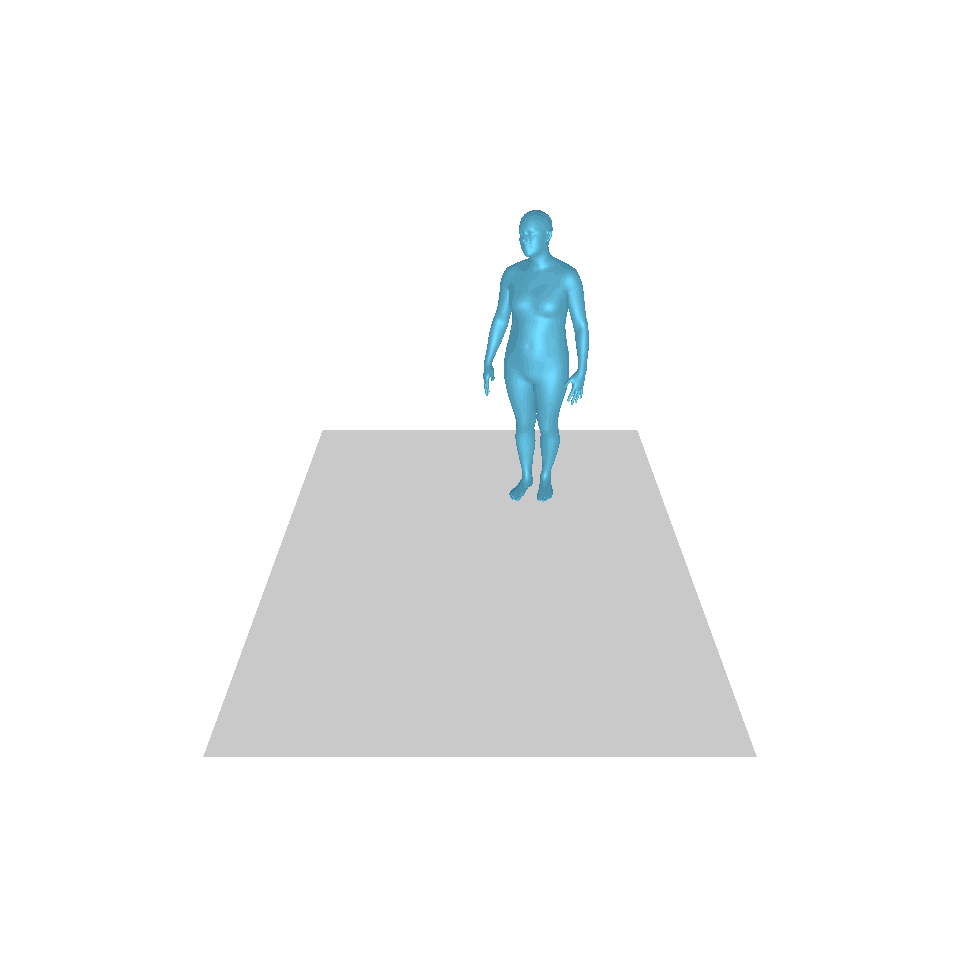 | 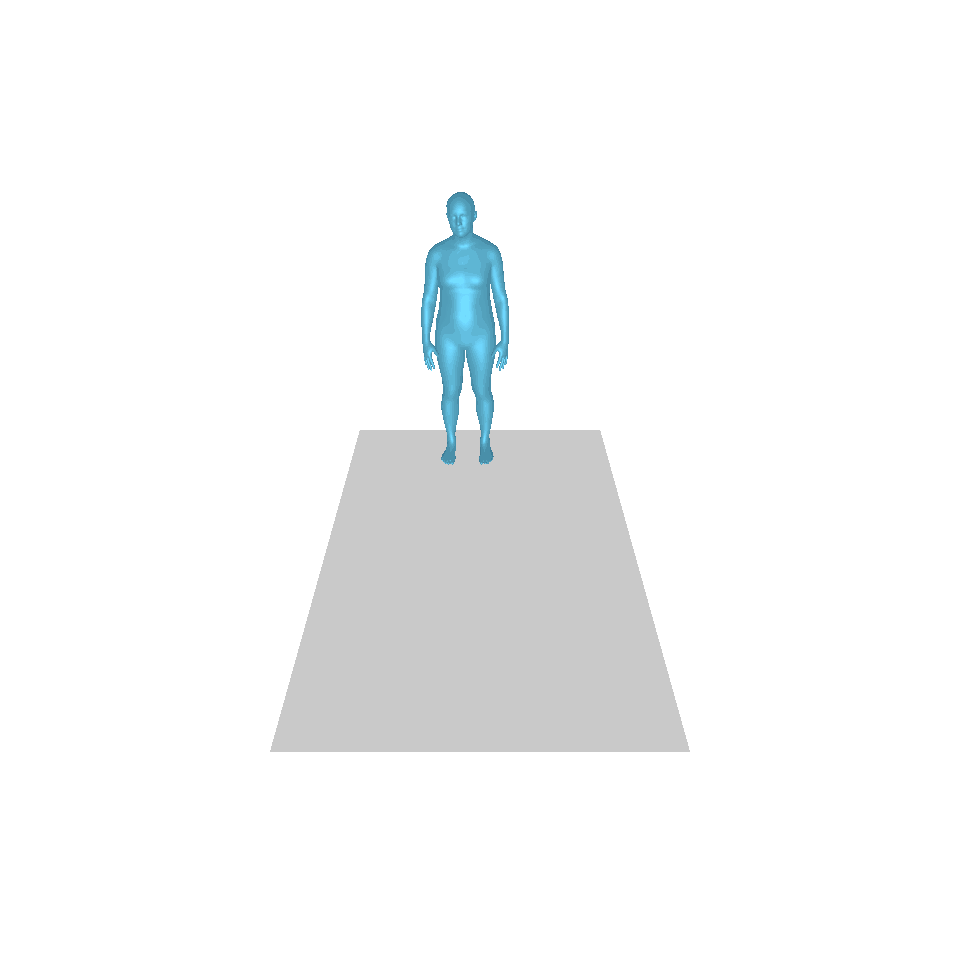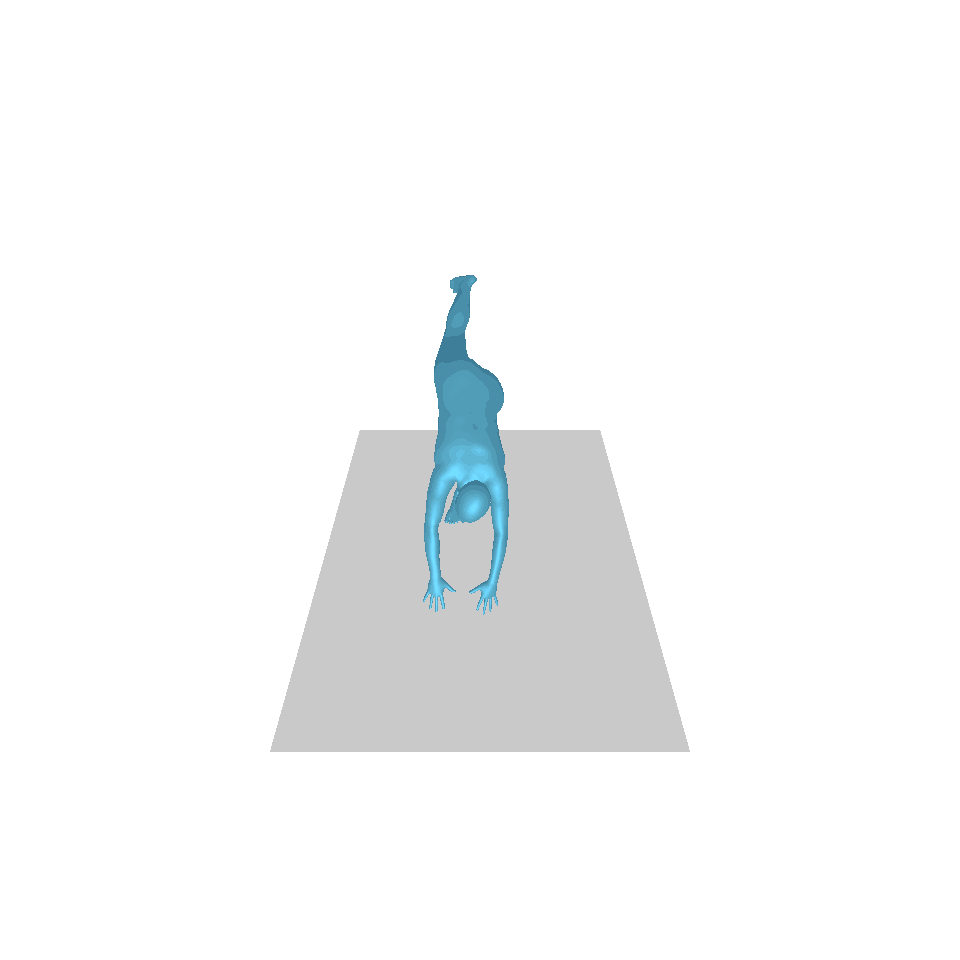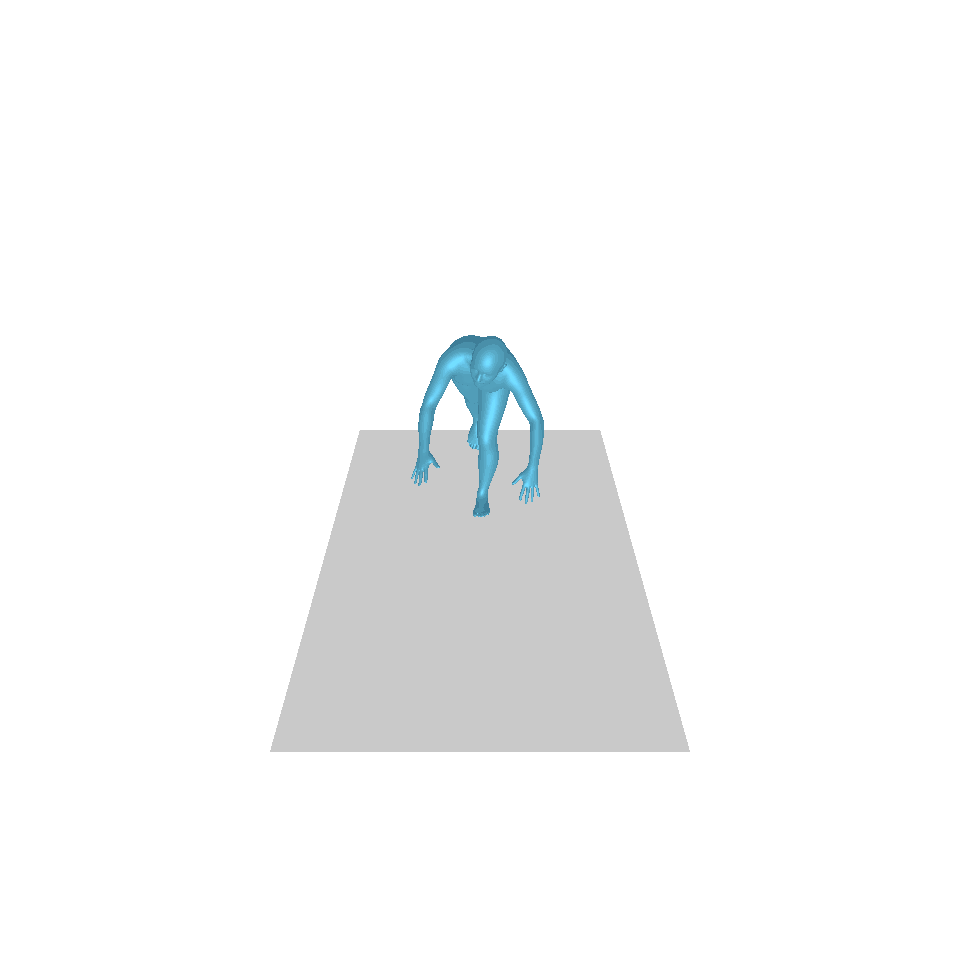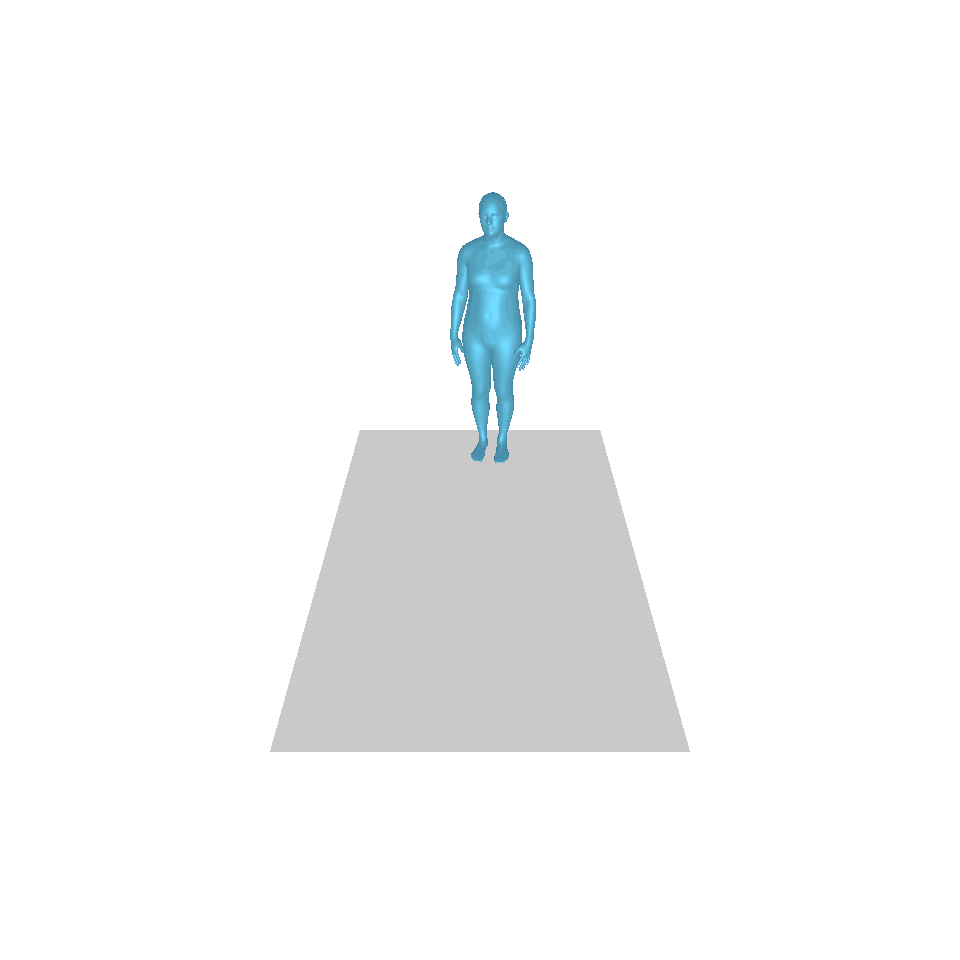 |
| 텍스트: 한 남자가 땅에서 일어나 원을 그리며 걷다가 다시 땅에 앉습니다. | ||||
| GT | T2M | MDM | 모션 디퓨즈 | 우리 것 |
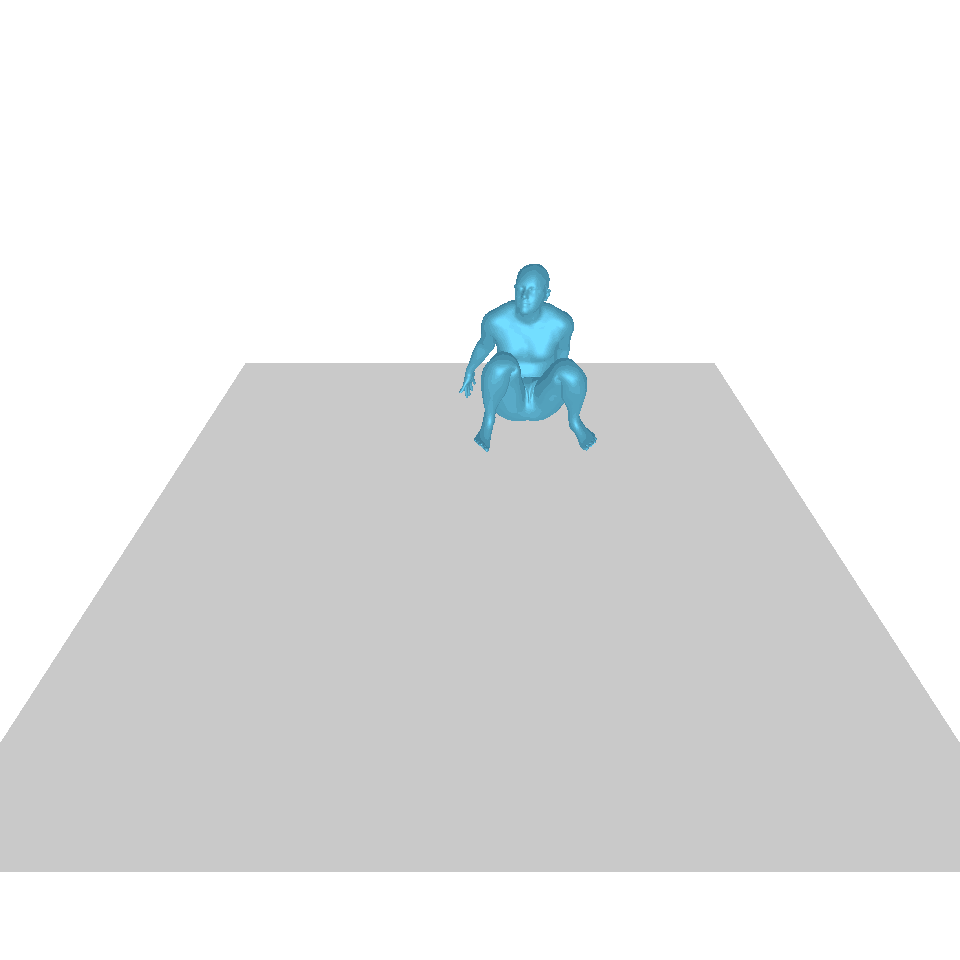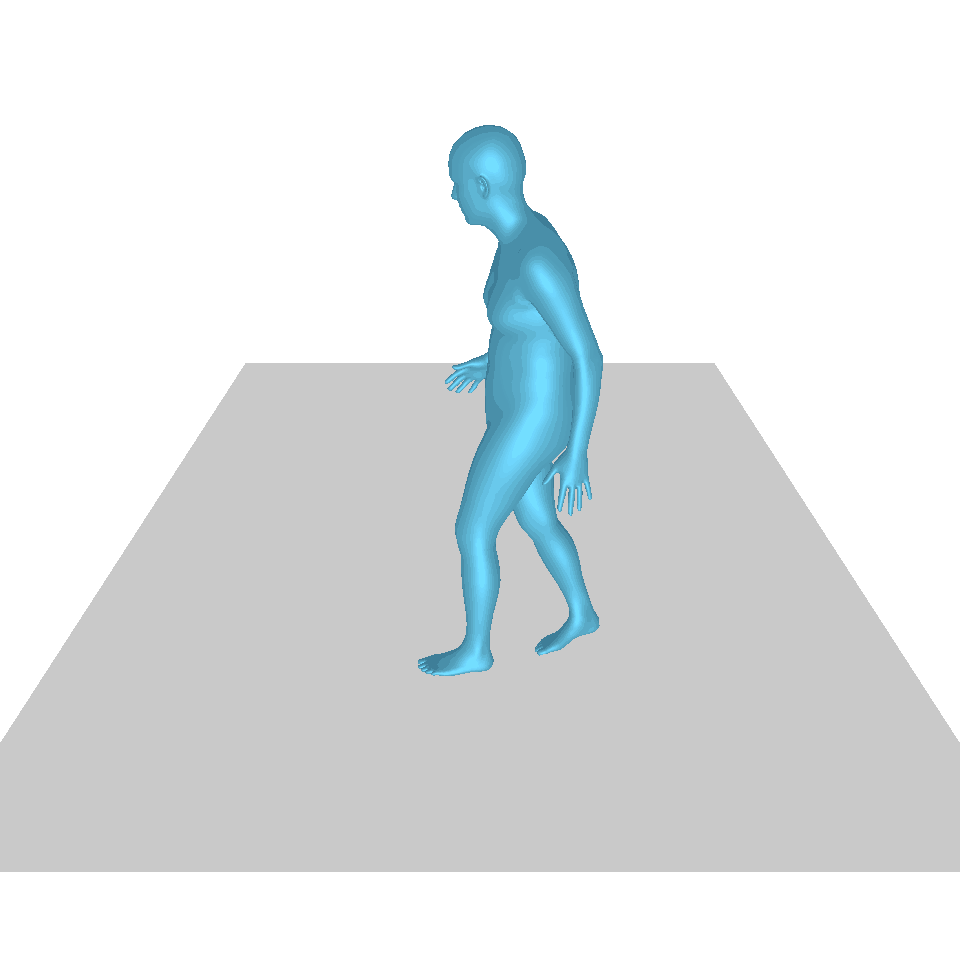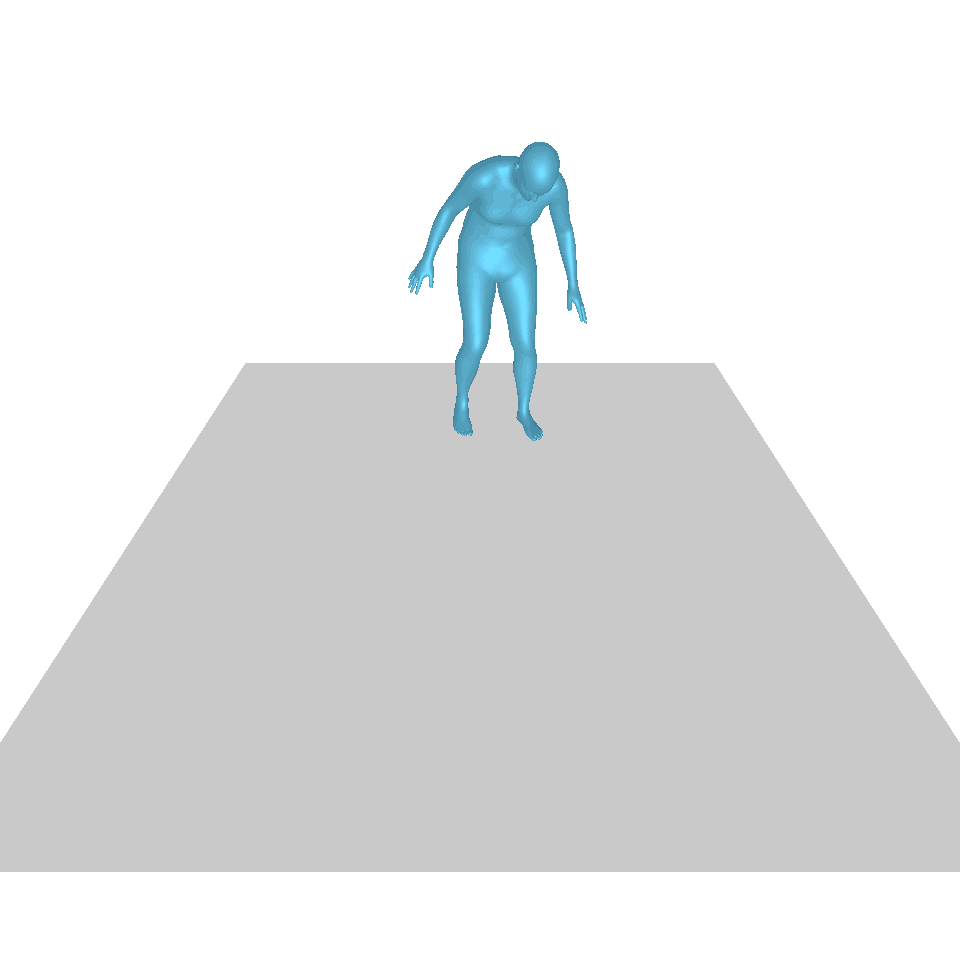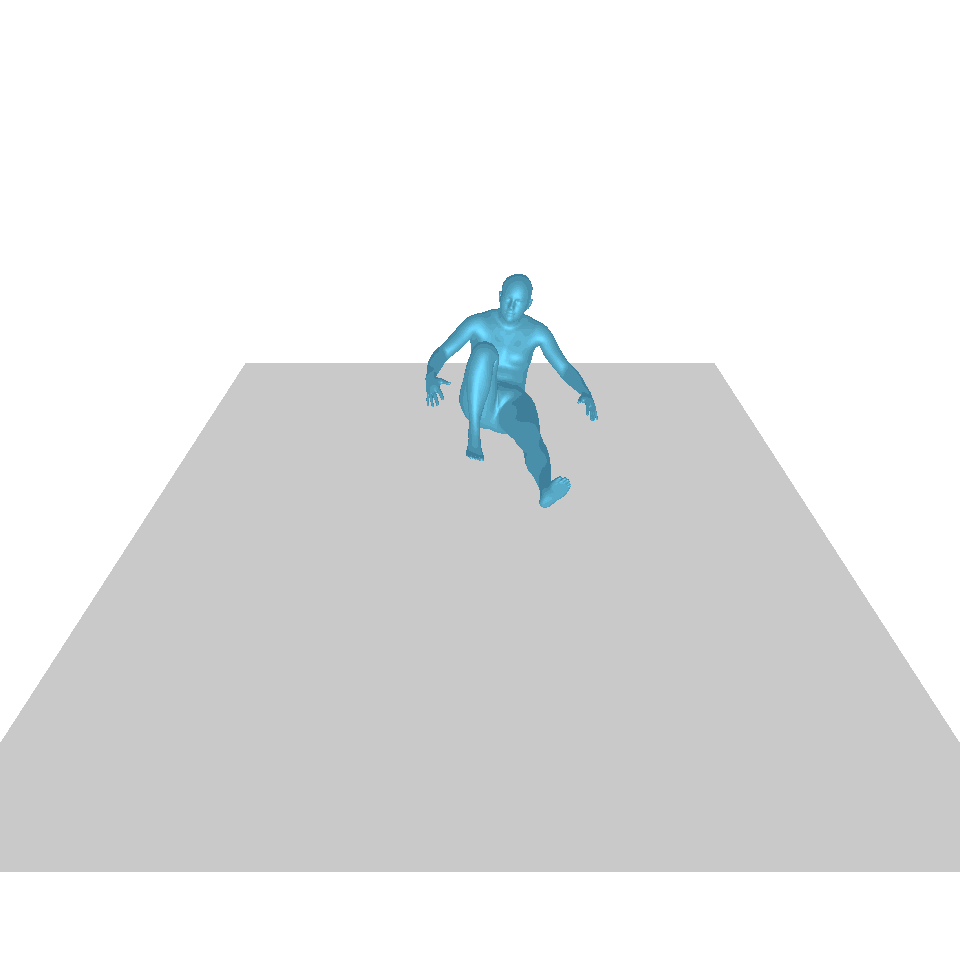 | 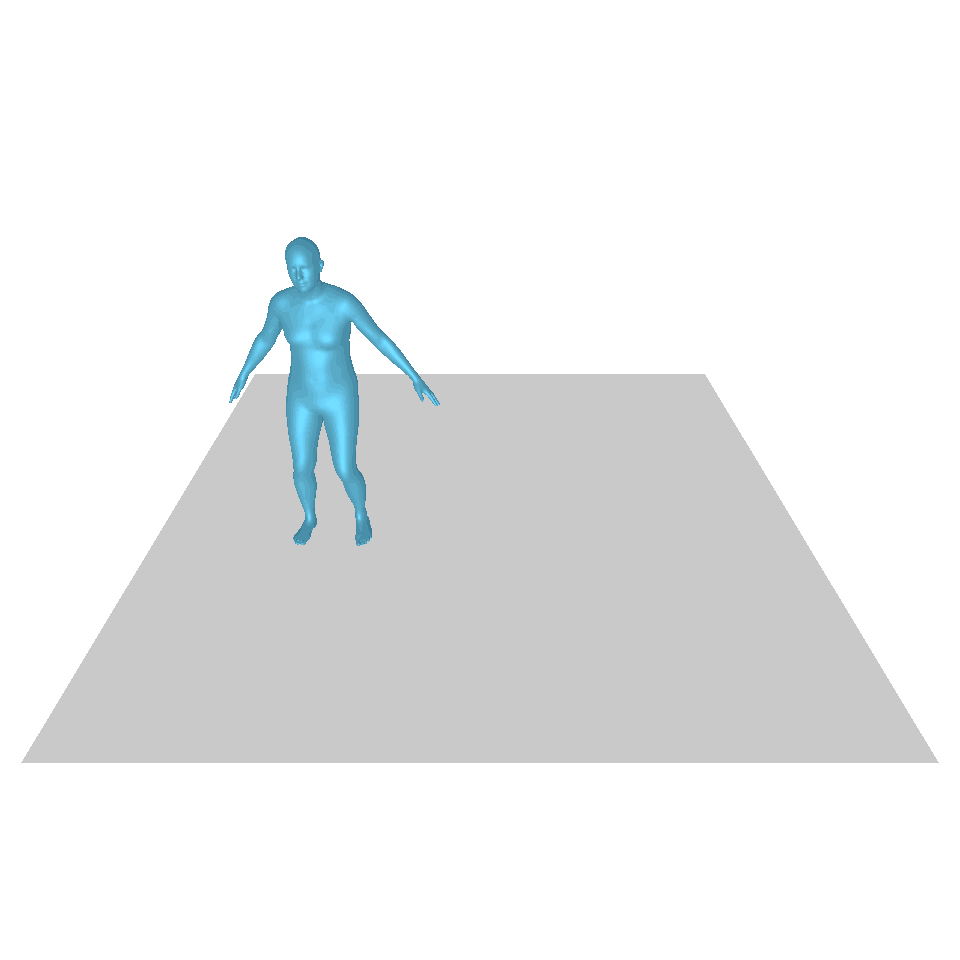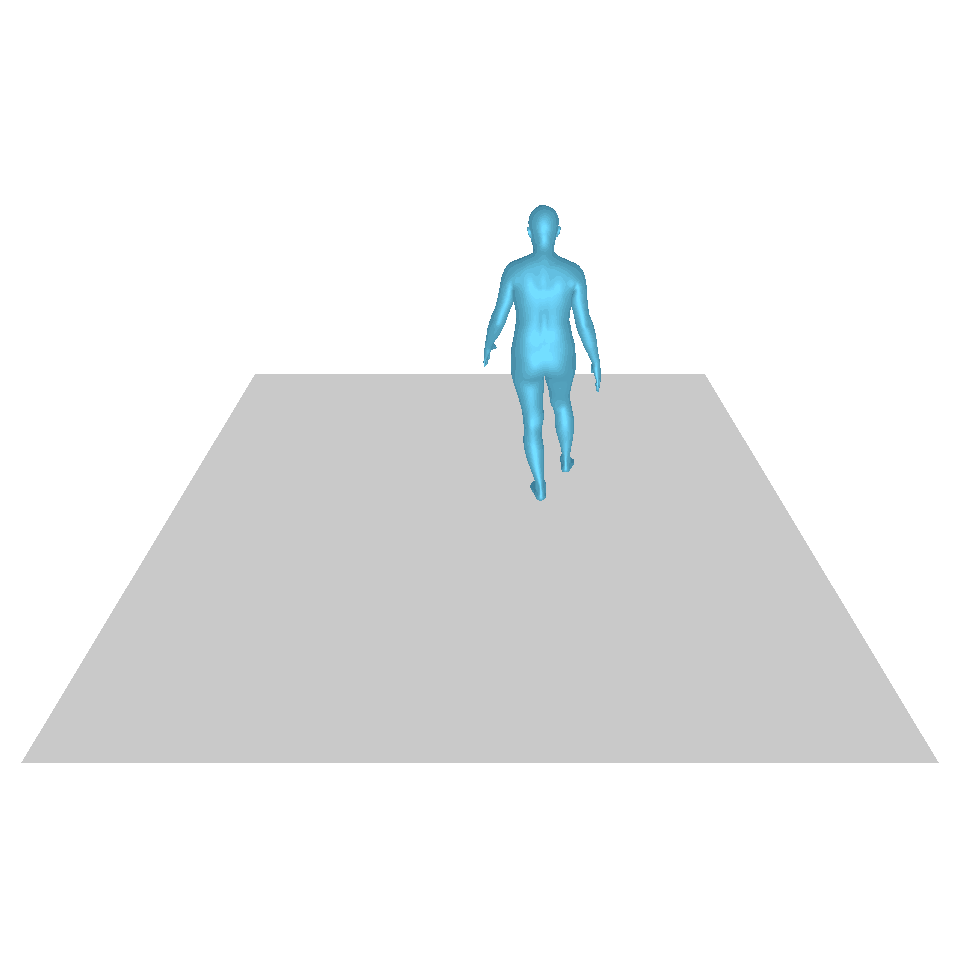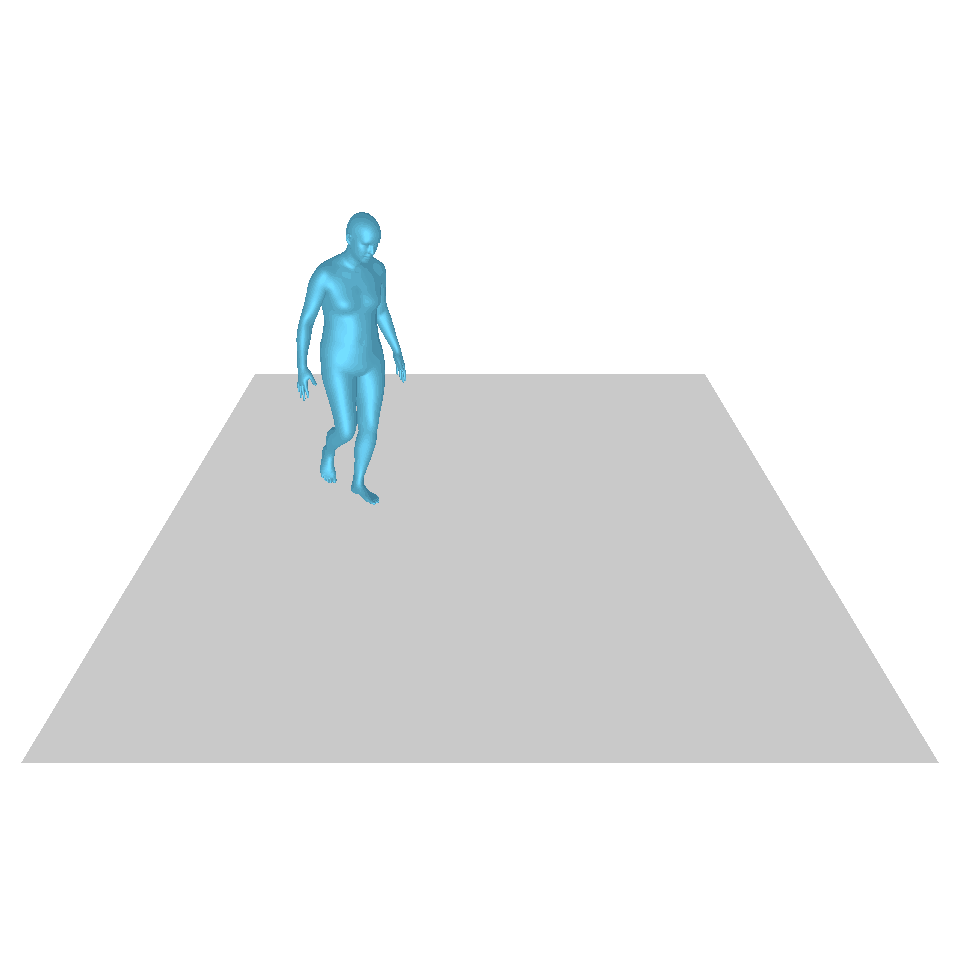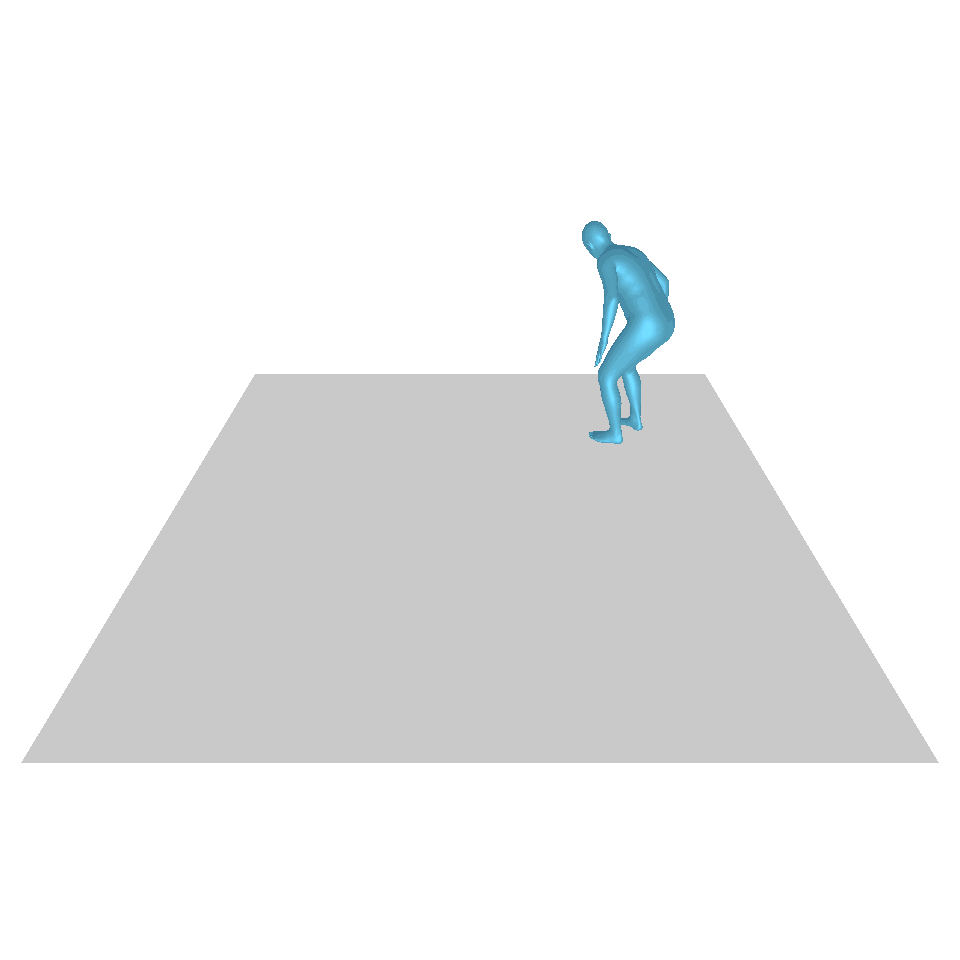 | 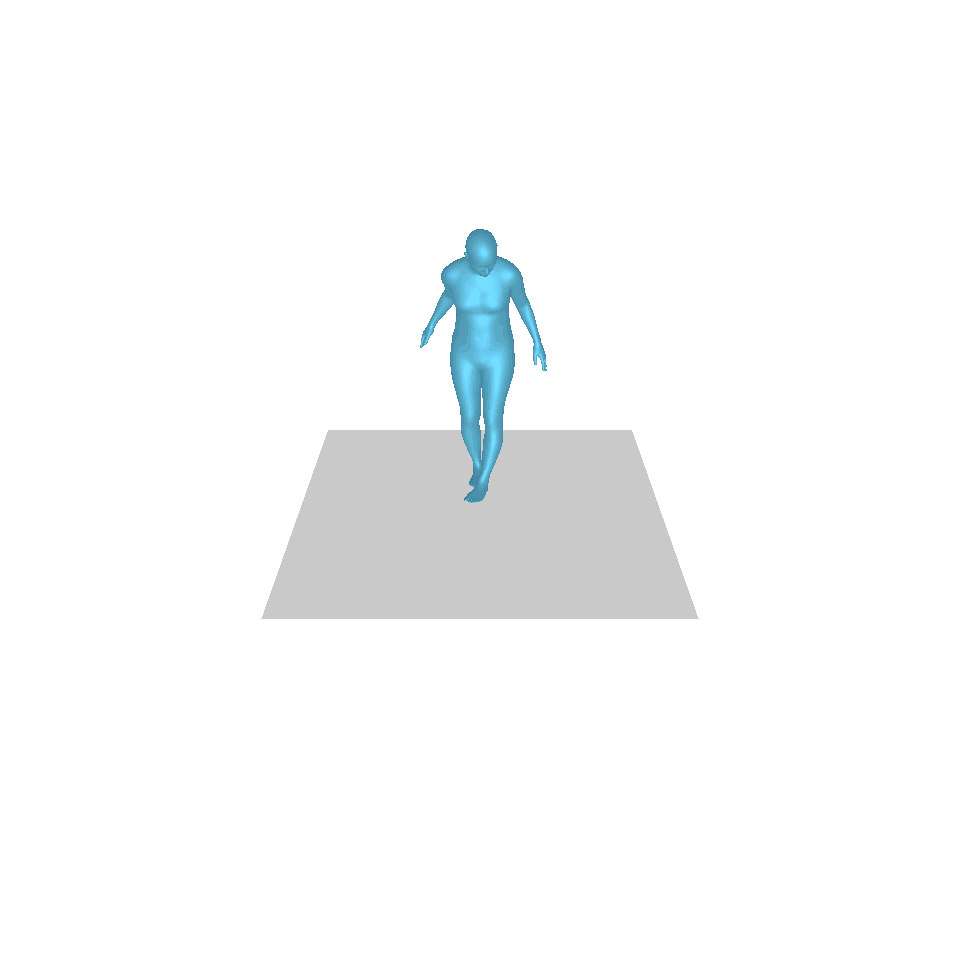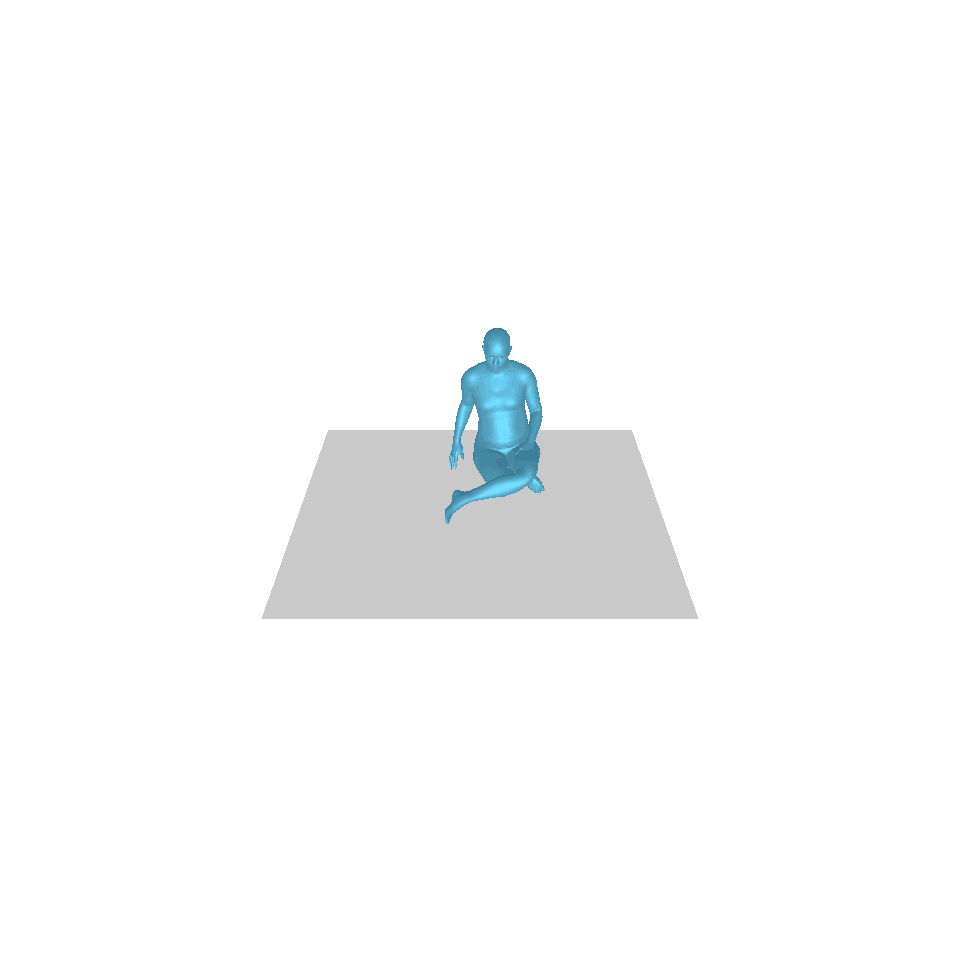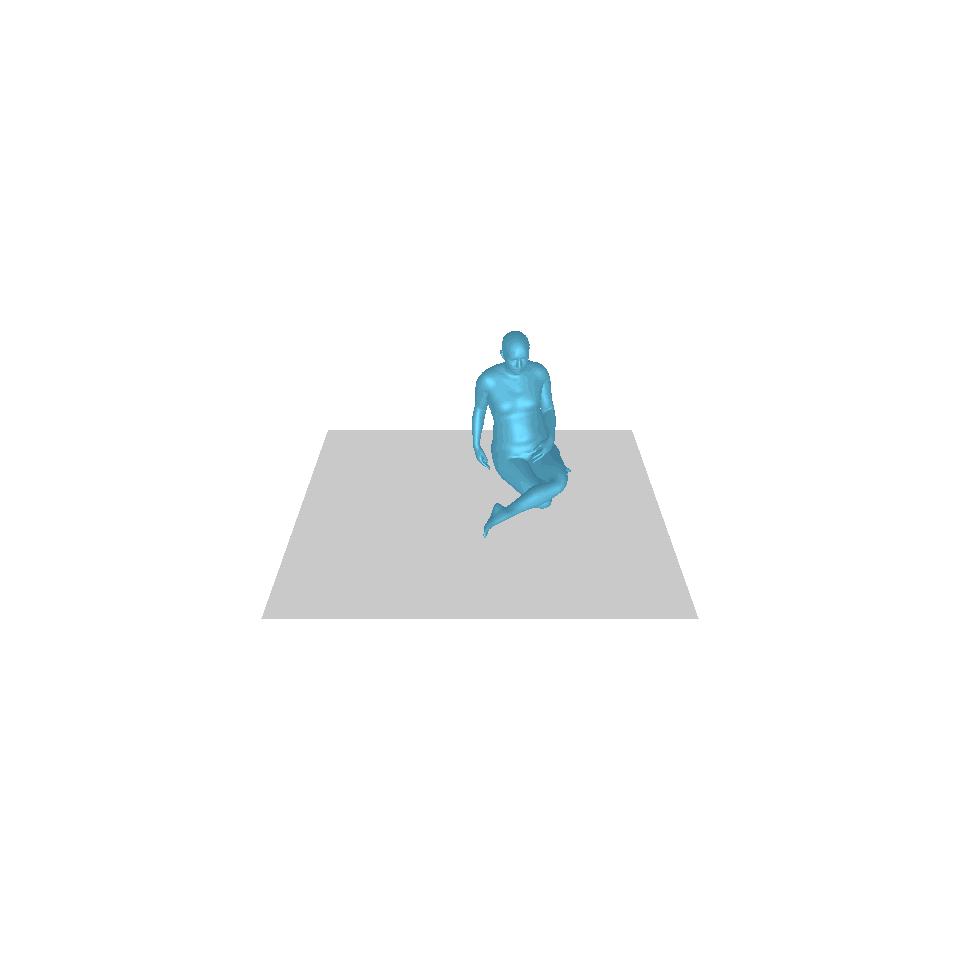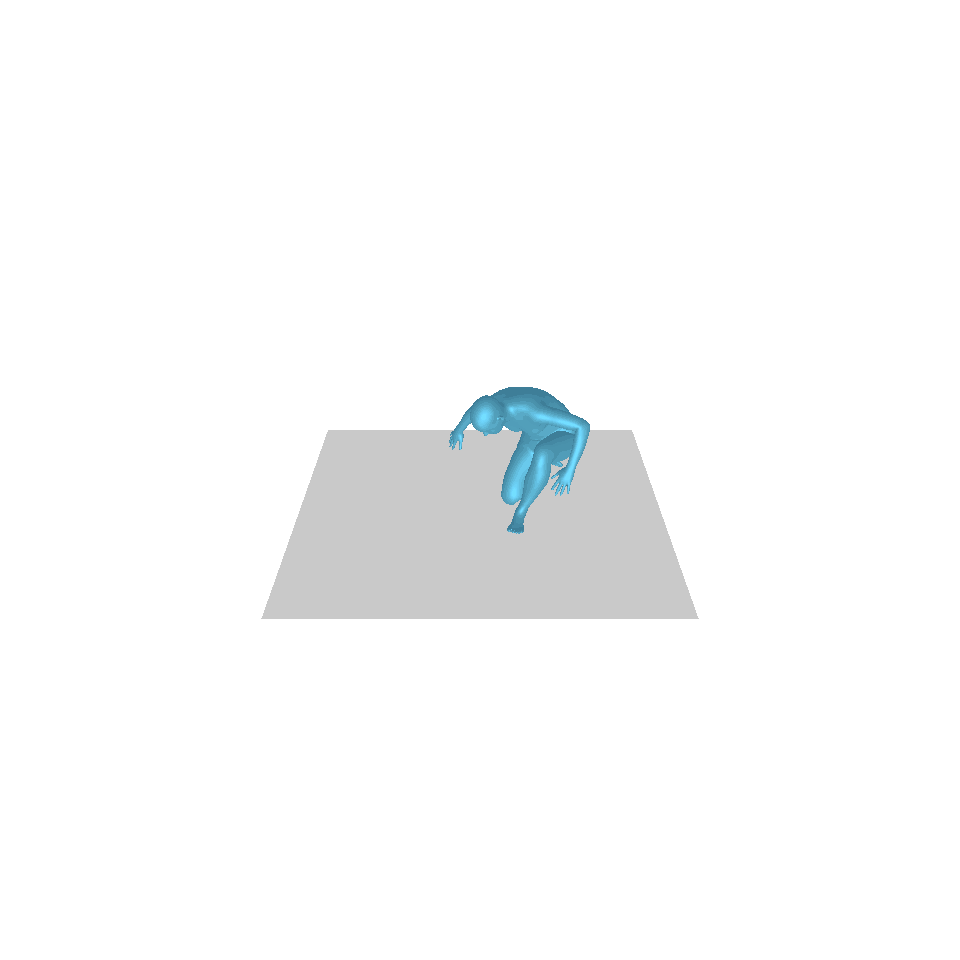 |  |  |
우리 모델은 단일 GPU V100-32G 에서 학습 가능
conda env create -f environment.yml
conda activate T2M-GPT코드는 Python 3.8 및 PyTorch 1.8.1에서 테스트되었습니다.
bash dataset/prepare/download_glove.sh우리는 HumanML3D와 KIT-ML이라는 두 가지 3D 인간 동작 언어 데이터 세트를 사용하고 있습니다. 두 데이터 세트 모두 [여기]에서 세부 정보와 다운로드 링크를 찾을 수 있습니다.
HumanML3D를 예로 들면 파일 디렉터리는 다음과 같아야 합니다.
./dataset/HumanML3D/
├── new_joint_vecs/
├── texts/
├── Mean.npy # same as in [HumanML3D](https://github.com/EricGuo5513/HumanML3D)
├── Std.npy # same as in [HumanML3D](https://github.com/EricGuo5513/HumanML3D)
├── train.txt
├── val.txt
├── test.txt
├── train_val.txt
└── all.txt
생성된 모션을 평가하기 위해 t2m에서 제공하는 것과 동일한 추출기를 사용합니다. 추출기를 다운로드해 주세요.
bash dataset/prepare/download_extractor.sh사전 학습된 모델 파일은 'pretrained' 폴더에 저장됩니다.
bash dataset/prepare/download_model.sh생성된 모션을 렌더링하려면 다음을 설치해야 합니다.
sudo sh dataset/prepare/download_smpl.sh
conda install -c menpo osmesa
conda install h5py
conda install -c conda-forge shapely pyrender trimesh mapbox_earcut코드 사용 방법에 대한 빠른 시작 가이드는 데모.ipynb에서 확인할 수 있습니다.
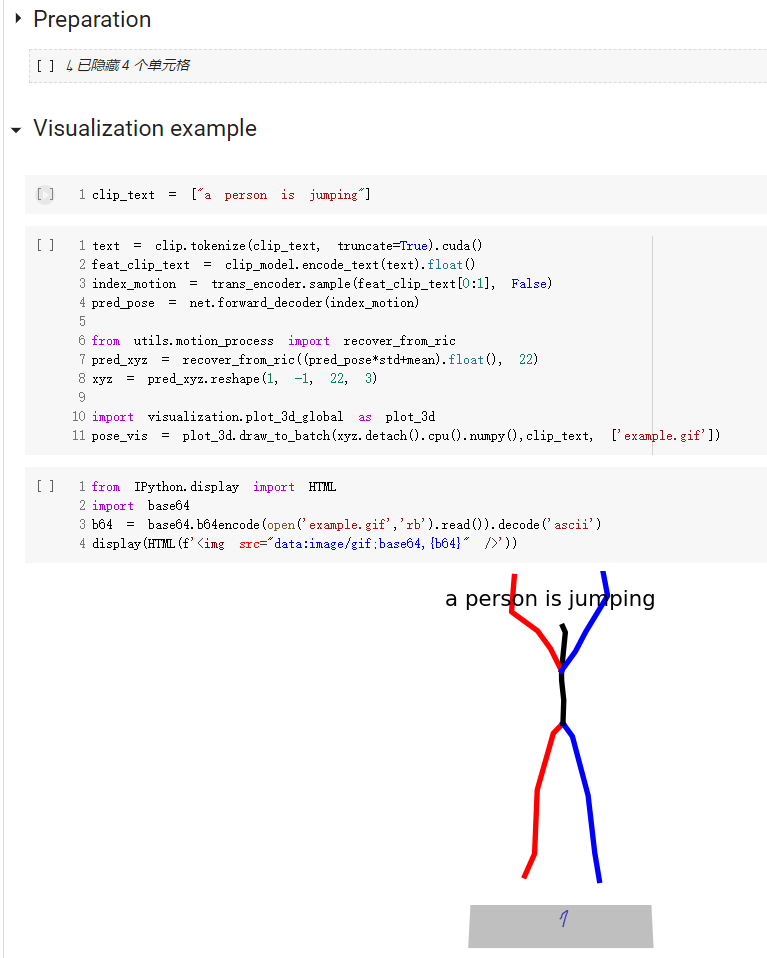
키트 데이터세트의 경우 '--dataname kit'만 설정하면 됩니다.
결과는 폴더 출력에 저장됩니다.
python3 train_vq.py
--batch-size 256
--lr 2e-4
--total-iter 300000
--lr-scheduler 200000
--nb-code 512
--down-t 2
--depth 3
--dilation-growth-rate 3
--out-dir output
--dataname t2m
--vq-act relu
--quantizer ema_reset
--loss-vel 0.5
--recons-loss l1_smooth
--exp-name VQVAE결과는 폴더 출력에 저장됩니다.
python3 train_t2m_trans.py
--exp-name GPT
--batch-size 128
--num-layers 9
--embed-dim-gpt 1024
--nb-code 512
--n-head-gpt 16
--block-size 51
--ff-rate 4
--drop-out-rate 0.1
--resume-pth output/VQVAE/net_last.pth
--vq-name VQVAE
--out-dir output
--total-iter 300000
--lr-scheduler 150000
--lr 0.0001
--dataname t2m
--down-t 2
--depth 3
--quantizer ema_reset
--eval-iter 10000
--pkeep 0.5
--dilation-growth-rate 3
--vq-act relupython3 VQ_eval.py
--batch-size 256
--lr 2e-4
--total-iter 300000
--lr-scheduler 200000
--nb-code 512
--down-t 2
--depth 3
--dilation-growth-rate 3
--out-dir output
--dataname t2m
--vq-act relu
--quantizer ema_reset
--loss-vel 0.5
--recons-loss l1_smooth
--exp-name TEST_VQVAE
--resume-pth output/VQVAE/net_last.pthText-to-Motion의 평가 설정에 따라 모델을 20회 평가하고 평균 결과를 보고합니다. 동일한 텍스트에서 30개의 모션을 생성해야 하는 다중 모드 부분으로 인해 평가에 오랜 시간이 걸립니다.
python3 GPT_eval_multi.py
--exp-name TEST_GPT
--batch-size 128
--num-layers 9
--embed-dim-gpt 1024
--nb-code 512
--n-head-gpt 16
--block-size 51
--ff-rate 4
--drop-out-rate 0.1
--resume-pth output/VQVAE/net_last.pth
--vq-name VQVAE
--out-dir output
--total-iter 300000
--lr-scheduler 150000
--lr 0.0001
--dataname t2m
--down-t 2
--depth 3
--quantizer ema_reset
--eval-iter 10000
--pkeep 0.5
--dilation-growth-rate 3
--vq-act relu
--resume-trans output/GPT/net_best_fid.pthnpy 폴더 주소와 모션 이름을 입력해야 합니다. 예는 다음과 같습니다.
python3 render_final.py --filedir output/TEST_GPT/ --motion-list 000019 005485다음 분들의 도움에 감사드립니다.


