spelltest
v0.0.4
? 이 프로젝트가 유용하다고 생각하시면 별점을 주세요! 귀하의 지원은 제가 계속해서 개선할 수 있도록 동기를 부여합니다! ?
오늘날의 AI 기반 애플리케이션은 혁신적인 솔루션을 제공하기 위해 GPT-4와 같은 LLM(대형 언어 모델)에 크게 의존합니다. 그러나 모든 상황에서 적절하고 정확한 대응을 제공하는 것은 어려운 일입니다. Spelltest는 합성 사용자 페르소나를 사용하여 LLM 응답을 시뮬레이션하고 이러한 응답을 자동으로 평가하는 평가 기술을 통해 이 문제를 해결합니다(그러나 여전히 사람의 감독이 필요함).
spellforge.yaml 파일에서 시뮬레이션을 설명합니다. project_name : ...
# describe users
users :
...
# describe quality metrics
metrics :
...
# describe prompts of your LLM app
prompts :
...
# finally describe simulations
simulations :
...

이제 Google Colab을 통해 웹 기반 대화형 환경에서 이 프로젝트를 시도해 볼 수 있습니다! 설치가 필요하지 않습니다.
시작하려면 위의 배지를 클릭하세요!
보장된 품질 : 최적의 응답을 위해 사용자 상호 작용을 시뮬레이션합니다.
효율성 및 비용 절감 : 수동 테스트 비용을 절감합니다.
원활한 작업 흐름 통합 : 개발 프로세스에 완벽하게 들어맞습니다.
이것은 Spelltest의 초기 버전이라는 점에 유의하시기 바랍니다. 따라서 아직 다양한 환경과 사용 사례에서 광범위하게 테스트되지 않았습니다. 이 버전을 사용하기로 결정하면 귀하는 자신의 책임 하에 Spelltest 프레임워크를 사용한다는 점에 동의하게 됩니다. 프로젝트 개선에 도움이 되도록 사용자가 직면하는 문제나 버그를 보고할 것을 적극 권장합니다.
운영 비용과 관련하여 Spelltest로 시뮬레이션을 실행하면 OpenAI API 사용량에 따라 요금이 부과된다는 점에 유의하는 것이 중요합니다. 현재로서는 예상 비용이나 예산 한도가 없습니다. 상황에 따라 100개의 시뮬레이션 배치를 실행하는 데 드는 비용은 특정 LLM 및 시뮬레이션의 복잡성을 포함한 여러 요소에 따라 약 $0.7~$1.8(gpt-3.5-turbo)일 수 있습니다.
이러한 비용을 감안할 때 초기 비용을 낮추고 향후 비용을 더 잘 예측하는 데 도움이 되도록 더 적은 수의 시뮬레이션으로 시작하는 것이 좋습니다. 프레임워크와 비용 영향에 더 익숙해지면 예산과 필요에 따라 시뮬레이션 수를 조정할 수 있습니다.
Spelltest의 목표는 AI 개발 및 테스트 프로세스에서 가능한 비용 효율성을 유지하면서 LLM의 고품질 응답을 보장하는 것입니다.

Spelltest는 품질 보증에 대해 독특한 접근 방식을 취합니다. 합성 사용자 페르소나를 사용하여 상호 작용을 시뮬레이션할 뿐만 아니라 고유한 사용자 기대치를 포착하여 상황에 맞는 풍부한 테스트 환경을 제공합니다. 이러한 깊이 있는 맥락을 통해 우리는 실제 응용 프로그램을 밀접하게 반영하는 방식으로 LLM 응답의 품질을 평가할 수 있습니다.
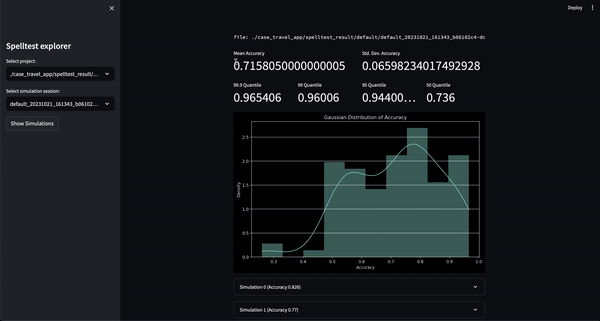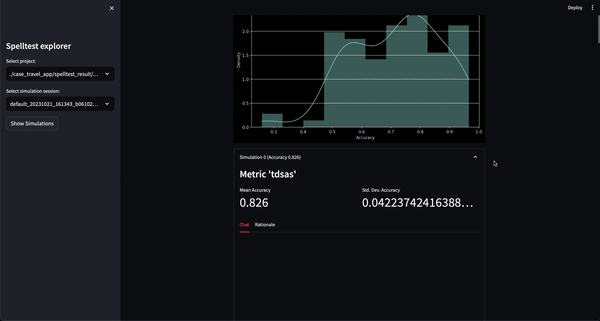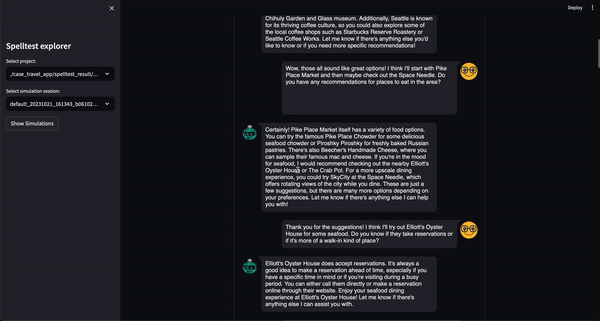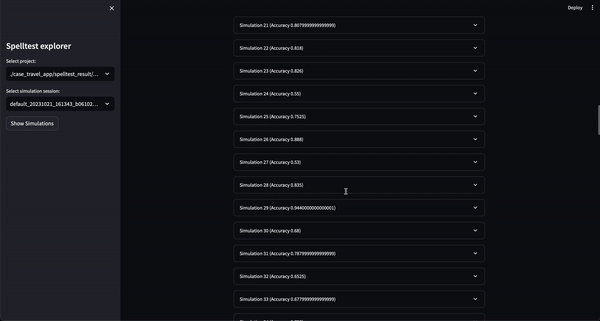
결과는? 0.0에서 1.0 사이의 품질 점수는 앱이 실제 사용자를 만나기 전에 포괄적인 드레스 리허설 역할을 합니다. 채팅 모드에서든 완료 모드에서든 Spelltest는 LLM 응답이 사용자 기대와 밀접하게 일치하는지 확인하여 전반적인 사용자 만족도를 향상시킵니다.
pip를 사용하여 프레임워크를 설치합니다.
pip install spelltest .spellforge.yaml 은 합성 사용자 프로필, 메트릭, 프롬프트 및 시뮬레이션을 포함하는 Spelltest의 핵심입니다. 아래는 그 구조를 분석한 것입니다.
합성 사용자는 각각 고유한 배경, 기대, 앱에 대한 이해를 가진 실제 사용자를 모방합니다. 합성 사용자를 위한 구성에는 다음이 포함됩니다.
하위 프롬프트 : 사용자 프로필에 대한 컨텍스트를 제공하는 설명 요소입니다. 여기에는 다음이 포함됩니다.
description : 합성 사용자에 대한 간략한 설명입니다.expectation : 사용자가 상호작용에서 기대하는 것입니다.user_knowledge_about_app : 앱에 대한 친숙도 수준입니다.각 합성 사용자에게는 다음이 포함됩니다.
name : 합성 사용자의 식별자입니다.llm_name : 사용할 LLM 모델입니다(OpenAI 모델에서만 테스트됨).temperature : ...합성 사용자 구성의 예:
...
nomad :
name : " Busy Nomad in Seattle "
llm_name : gpt-3.5-turbo
temperature : 0.7
description : " You're a very busy nomad who struggles with planning. You're moved to Seattle and looking at how to spend your first Saturday exploring the city "
expectation : " Well-planned objective, detailed, and comprehensive schedule that meets user's requirements "
user_knowledge_about_app : " The app receives text input about travel requirements (i.e., place, preferences, short description of the family and their interests) and returns a travel schedule that accommodates all family members’ needs and interests. "
metrics : __all__
... 측정항목은 LLM의 응답을 평가하고 점수를 매기는 데 사용됩니다. 각 측정항목에는 측정항목이 평가하는 내용에 대한 컨텍스트를 제공하는 하위 프롬프트 description 포함되어 있습니다.
간단한 측정항목 구성의 예:
...
metrics :
accuracy :
description : " Accuracy "
...복합/사용자 지정 지표 구성의 예:
...
metrics :
tpas :
description : " TPAS - The Travel Plan Accuracy Score. This metric measures the accuracy of the generated response by evaluating the inclusion of the expected output, well-scheduled travel plan and nothing else. The TPAS is a numerical value between 0 and 100, with 100 representing a perfect match to the expected output and 0 indicating non-accurate result. "
... 프롬프트는 앱이 제시하는 질문이나 작업입니다. 이는 적절한 응답을 생성하는 LLM의 능력을 테스트하기 위해 시뮬레이션에 사용됩니다. 각 프롬프트는 description 과 실제 prompt 텍스트 또는 작업으로 정의됩니다.
...
prompts :
book_flight :
file : book-flight-prompt.txt
... 시뮬레이션은 테스트 시나리오를 지정합니다. 주요 요소에는 prompt , users , llm_name , temperature , size , chat_mode 및 quality_threshold 포함됩니다.
project_name : " Travel schedule app "
# describe users
users :
nomad :
name : " Busy Nomad in Seattle "
llm_name : gpt-3.5-turbo
temperature : 0.7
description : " You're a very busy nomad who struggles with planning. You're moved to Seattle and looking at how to spend your first Saturday exploring the city "
expectation : " Well-planned objective, detailed, and comprehensive schedule that meets user's requirements "
user_knowledge_about_app : " The app receives text input about travel requirements (i.e., place, preferences, short description of the family and their interests) and returns a travel schedule that accommodates all family members’ needs and interests. "
metrics : __all__
family_weekend :
name : " The Adventurous Family from Chicago "
llm_name : gpt-3.5-turbo
temperature : 0.7
description : " You're a family of four (two adults and two children) based in Chicago looking to plan an exciting, yet relaxed weekend getaway outside the city. The objective is to explore a new environment that is kid-friendly and offers a mix of adventure and downtime. "
expectation : " A balanced travel schedule that combines fun activities suitable for children and relaxation opportunities for the entire family, considering travel times and kid-friendly amenities. "
user_knowledge_about_app : " The app receives text input about travel requirements (i.e., place, preferences, short description of the family and their interests) and returns a travel schedule that accommodates all family members’ needs and interests. "
metrics : __all__
retired_couple :
name : " Retired Couple Exploring Berlin "
llm_name : gpt-3.5-turbo
temperature : 0.7
description : " You're a retired couple from the US, wanting to explore Berlin and soak in its rich history and culture over a 10-day vacation. You’re looking for a mixture of sightseeing, cultural experiences, and leisure activities, with a comfortable pace suitable for your age. "
expectation : " A comprehensive travel plan that provides a relaxed pace, ensuring enough time to explore and enjoy each location, and includes historical and cultural experiences. It should also consider comfort and accessibility. "
user_knowledge_about_app : " The app accepts text input detailing travel requirements (i.e., destination, preferences, duration, and a brief description of travelers) and returns a well-organized travel itinerary tailored to those specifics. "
metrics : __all__
# describe quality metrics
metrics :
tpas : # name of your metric
description : " TPAS - The Travel Plan Accuracy Score. This metric measures the accuracy of the generated response by evaluating the inclusion of the expected output, well-scheduled travel plan and nothing else. The TPAS is a numerical value between 0 and 100, with 100 representing a perfect match to the expected output and 0 indicating non-accurate result. "
# describe prompts
prompts :
smart-prompt :
file : ./smart-prompt # expected that prompt located in this file
# finally describe simulations
simulations :
test1 :
prompt : smart-prompt
users : __all__
llm_name : gpt-3.5-turbo
temperature : 0.7
size : 5
chat_mode : true # completion mode if `false`
quality_threshold : 80
프롬프트 파일을 포함한 전체 구성은 여기에 있습니다.
OpenAI 비용 : 이 프레임워크를 사용하면 특히 광범위한 시뮬레이션을 실행할 때 OpenAI에 대한 요청이 상당히 많아질 수 있습니다. 이로 인해 OpenAI 계정에 상당한 비용이 발생할 수 있습니다. OpenAI 예산을 염두에 두고 가격 책정 모델을 이해하세요. 발생한 비용에 대해서는 책임을 지지 않습니다.
초기 출시 : 이 Spelltest 버전은 초기 단계에 있으므로 안정성이 보장되지 않습니다. 주의해서 사용하시기 바랍니다. 피드백을 제공하거나 문제를 보고해 주시기 바랍니다.
export OPENAI_API_KEYS= < your api keys >
spelltest --config_file .spellforge.yaml시뮬레이션 결과를 확인해보세요.
spelltest --analyzeSpelltest를 릴리스 파이프라인에 통합하면 일관되고 자동화된 테스트를 통합하여 배포 전략이 향상됩니다. 이 중요한 단계는 출시 전에 사용자 상호 작용을 체계적으로 시뮬레이션하고 평가하여 LLM 기반 응용 프로그램이 높은 품질 표준을 유지하도록 보장합니다. 이를 통해 상당한 시간을 절약하고, 수동 오류를 줄이며, 변경 사항이나 새로운 기능이 사용자 경험에 어떤 영향을 미치는지에 대한 주요 통찰력을 제공할 수 있습니다.
이 가이드는 프로젝트에 대한 지속적인 통합을 설정하고 자동화하는 과정을 안내합니다.
시작하기 전에 다음 필수 구성 요소가 갖추어져 있는지 확인하세요.
프로젝트가 포함된 GitHub 저장소.
API 키를 사용하여 SpellForge에 액세스합니다. 없는 경우 SpellForge 웹사이트에서 얻을 수 있습니다.
OpenAI 서비스를 사용하기 위한 OpenAI API 키입니다. 없는 경우 OpenAI 웹사이트에서 구할 수 있습니다.
.spellforge.yaml 생성 및 구성 프로젝트의 루트 디렉터리에 .spellforge.yaml 파일을 생성합니다. 이 파일에는 Spelltest에 대한 지침이 포함되어 있습니다.
SpellForge 테스트를 자동화하려면 GitHub Actions 워크플로 파일(예: .github/workflows/.spelltest.yaml)을 만듭니다. 이 파일에 다음 코드를 삽입합니다.
# .spelltest.yaml
name : Spelltest CI
on :
push :
branches : [ "main" ]
env :
SPELLTEST_CONFIG_PATH : ${{ env.SPELLTEST_CONFIG_PATH }}
OPENAI_API_KEY : ${{ secrets.OPENAI_API_KEY }}
jobs :
test :
runs-on : ubuntu-latest
steps :
- uses : actions/checkout@v3
- name : Install SpellTest library
run : pip install spelltest
- name : Run tests
run : spelltest --config_file $SPELLTEST_CONFIG_PATH이 워크플로는 메인 브랜치에 푸시할 때마다 트리거되며 SpellForge 테스트를 실행합니다.
GitHub 저장소로 이동하여 "설정" 탭으로 이동합니다.
"비밀" 아래에 두 개의 새로운 비밀을 추가합니다.
OPENAI_API_KEY : 이 비밀을 OpenAI API 키로 설정합니다.
GitHub 환경 변수를 추가합니다.
SPELLTEST_CONFIG_PATH : 이 변수를 저장소 내 .spellforge.yaml 파일의 전체 경로로 설정합니다.
이는 특정 특성과 기대치를 바탕으로 실제 사용자 상호 작용을 시뮬레이션합니다.
사용자 배경 ( .spellforge.yaml 의 description 필드): 이 합성 사용자가 누구인지, 앱을 사용하여 해결하려는 문제(예: 일정을 관리하는 여행자)에 대한 개요를 제공하는 하위 프롬프트입니다.
사용자 기대 ( expectation 필드): 합성 사용자가 앱 사용을 통해 성공적인 상호 작용 또는 솔루션으로 기대하는 것이 무엇인지 정의하는 하위 프롬프트입니다.
환경 인식 ( user_knowledge_about_app 필드): 합성 사용자가 애플리케이션의 컨텍스트를 이해하고 현실적인 테스트 시나리오를 보장하도록 하는 하위 프롬프트입니다.
시뮬레이션에서 LLM이 생성한 응답을 평가하고 점수를 매기는 데 사용되는 표준 또는 기준을 나타내는 하위 프롬프트입니다. 측정항목은 일반적인 측정부터 보다 구체적인 애플리케이션별 사용자 지정 측정항목까지 다양합니다.
일반 측정항목의 예:
의미적 유사성 : 제공된 답변이 의미 측면에서 예상 답변과 얼마나 유사한지를 측정합니다.
독성 : 부적절하거나 유해하다고 간주될 수 있는 언어나 콘텐츠에 대한 응답을 평가합니다.
구조적 유사성 : 생성된 응답의 구조 및 형식을 미리 정의된 표준 또는 예상 출력과 비교합니다.
추가 맞춤 측정항목 예시:
TPAS(여행 계획 정확도 점수) : "이 측정항목은 예상 결과의 포함 여부와 제안된 여행 계획의 품질을 평가하여 생성된 응답의 정확성을 측정합니다. TPAS는 0에서 100 사이의 숫자 값으로, 100은 완벽한 여행을 나타냅니다. 예상 출력과 일치하고 0은 정확하지 않은 결과를 나타냅니다."
EES(공감 참여 점수) : "EES는 LLM 응답의 공감적 공명을 평가합니다. 메시지의 이해, 검증 및 지원 요소를 평가하여 전달된 공감 수준에 점수를 매깁니다. EES 범위는 0에서 100까지이며, 여기서 100은 공감적 반응이 매우 높은 반면, 0은 공감적 참여가 부족함을 나타냅니다."
Spelltest로 LLM 기반 지원서를 더 좋게 만드세요!


