paperchat
1.0.0
arXivchat에 오신 것을 환영합니다!
arXivchat은 arXiv 출판 논문에 대해 대화식으로 이야기할 수 있는 LLM 기반 소프트웨어입니다. CLI 도구, API 공급자 및 ChatGPT 플러그인으로 작동합니다.
정방향 운영자가 제작했습니다. 우리는 LLM 및 ML 관련 프로젝트에서 가장 똑똑한 사람들과 협력하고 있습니다.
기여하는 것을 환영합니다!
arXiv 플러그인을 빠르게 설정하고 실행하려면 다음 단계를 따르세요.
아직 설치되지 않은 경우 Python 3.10을 설치합니다.
저장소 복제: git clone https://github.com/Forward-Operators/arxivchat.git
복제된 저장소 디렉터리로 이동합니다: cd /path/to/arxivchat
시 설치: pip install poetry
Python 3.10으로 새로운 가상 환경 만들기: poetry env use python3.10
가상 환경 활성화: poetry shell
앱 종속성 설치: poetry install
필수 환경 변수를 설정합니다.
export DATABASE= < your_datastore >
export OPENAI_API_KEY= < your_openai_api_key >
# Add the environment variables for your chosen vector DB.
# Pinecone
export PINECONE_API_KEY= < your_pinecone_api_key >
export PINECONE_ENVIRONMENT= < your_pinecone_environment >
export PINECONE_INDEX= < your_pinecone_index >
# Qdrant
export QDRANT_URL= < your_qdrant_url >
export QDRANT_PORT= < your_qdrant_port >
export QDRANT_GRPC_PORT= < your_qdrant_grpc_port >
export QDRANT_API_KEY= < your_qdrant_api_key >
export QDRANT_COLLECTION= < your_qdrant_collection >
# Chroma
export CHROMA_HOST= < your_chroma_host >
export CHROMA_PORT= < your_chroma_port >
export CHROMA_COLLECTION= < your_chroma_collection >
# Embeddings
export EMBEDDINGS= < openai or huggingface >
export CUDA_ENABLED= < True or False > - needed for huggingface
API를 로컬에서 실행합니다: cd app/; gunicorn --worker-class uvicorn.workers.UvicornWorker --config ./gunicorn_conf.py main:app
http://0.0.0.0:8000/docs에서 API 문서에 액세스하고 API 엔드포인트를 테스트하세요.
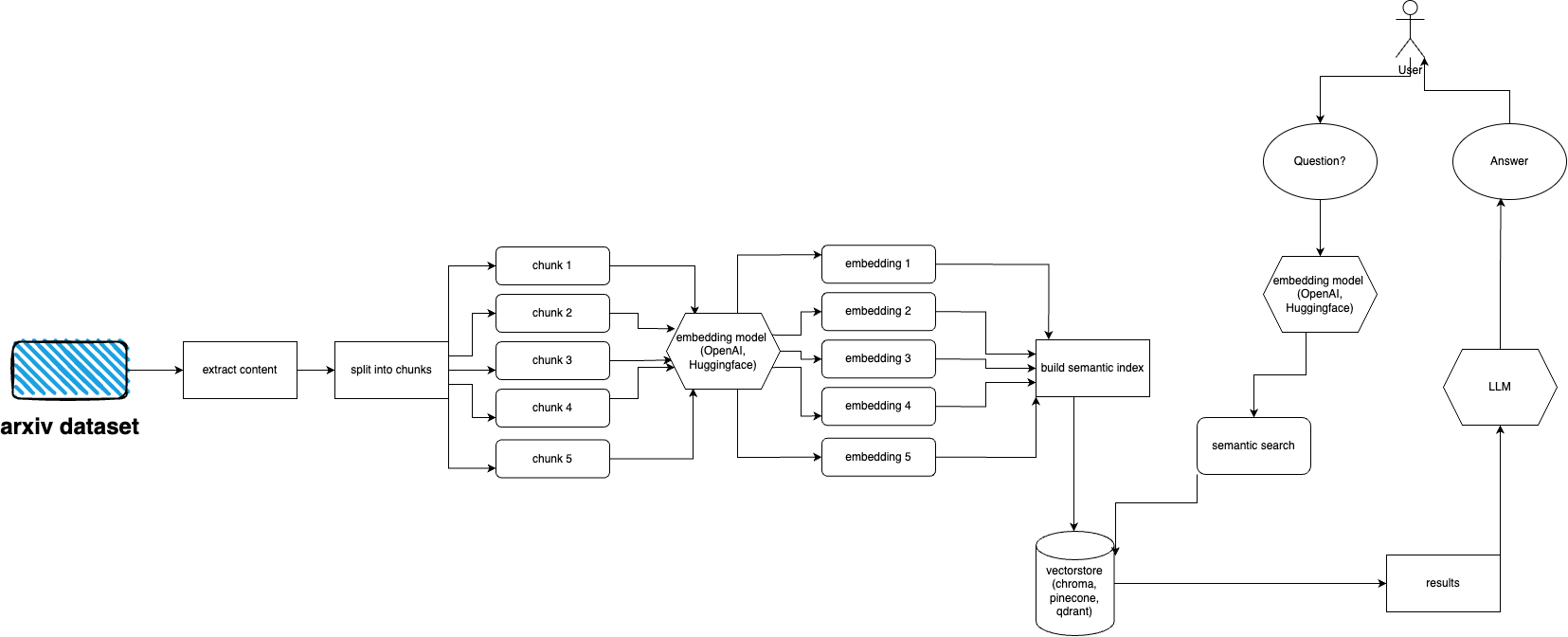
arXiv는 거의 2백만 개의 출판물로 구성된 데이터세트를 보유하고 있습니다. 웹사이트에서 너무 많은 데이터를 가져오는 것은 arXiv의 ToS에 위배됩니다(로드가 생성됨). 다행스럽게도 kaggle의 좋은 사람들과 Cornell University가 함께 사용할 수 있는 공개적으로 사용 가능한 데이터 세트를 만듭니다. 데이터 세트는 Google Cloud Storage 버킷을 통해 무료로 제공되며 매주 업데이트됩니다.
이제 주요 문제는 5테라바이트가 넘는 PDF 파일을 수집하고 싶지 않은 경우 전체 데이터세트의 하위 집합만 가져오는 방법입니다. 데이터 세트는 월별, 연간 디렉터리로 나누어져 있으므로 2021년 9월의 모든 발행물을 가져오려면 다음을 실행하면 됩니다. gsutil cp -r gs://arxiv-dataset/arxiv/pdf/2109/ ./local_directory
전체 데이터세트를 가져오려면 gsutil cp -r gs://arxiv-dataset/arxiv/pdf/ ./a_local_directory/
그러나 특정 카테고리 및 날짜에 대한 하위 집합만 얻으려면 download.py 파일을 살펴보세요.
기본적으로 수집기는 이 파일이 모든 PDF 파일과 함께 /mnt/dataset/arxiv/pdf 에 있을 것으로 예상합니다.
python scripy.py 확인하고 실행하여 데이터를 수집하세요. 무언가가 작동하지 않는 경우 디버깅을 활성화할 수도 있습니다.
TODO: 이를 디렉터리 로더로 변경할 수 있습니다. TODO: 셀러리 배포를 구현하고 수집을 위해 작업자를 사용합니다.
python cli.py 
이전에 데이터베이스에 입력했던 주제에 대해 질문하세요. 소스에 대한 정보도 반환하며 지속적으로 실행됩니다. 또 다른 옵션은 REST API를 사용하거나( app 디렉토리에서 uvicorn main:app --reload --host 0.0.0.0 --port 8000 실행) ChatGPT 플러그인으로 사용하는 것입니다(배포 후).
deployment 디렉터리에 Terraform 파일이 있습니다. 귀하에게 가장 적합한 것을 사용하십시오. 각각의 지침과 함께 README 파일이 있습니다. Docker 이미지를 빌드하고 원하는 곳 어디에서나 실행할 수도 있습니다. 그런데 이미지 파일이 꽤 크네요.
현재는 Docker 이미지를 사용하여 Cloud Run으로 배포할 수 있으므로 API 전용 배포입니다. 데이터 수집은 다른 시스템에서 실행되어야 합니다. 특히 Hugging Face 임베딩을 사용하고 gcsfuse 사용하여 Google Storage에서 직접 데이터를 마운트할 수 있기 때문에 GPU 지원 Compute Engine을 권장합니다. Cloud에서 GCS 버킷을 사용하는 잠재적인 솔루션 달리다
지금은 컨테이너 앱으로 배포할 수 있습니다(API 전용 배포, 수집을 위해 다른 배포가 필요함)
AWS는 아직 지원되지 않습니다. 곧 출시됩니다.
arxivchat은 기본적으로 OpenAI용 text-embedding-ada-002 사용합니다. app/tools/factory.py 에서 이를 변경할 수 있습니다.
지금은 sentence_transformers 와 함께 작동하는 모든 모델을 사용할 수 있습니다. app/tools/factory.py 에서 모델을 변경할 수 있습니다.
문제가 있는 경우 GitHub 문제를 사용하여 보고해 주세요.
arXivchat을 더욱 좋게 만드는 데 여러분의 도움이 되기를 바랍니다! 참여하려면 다음 단계를 따르세요.
arXivchat은 MIT 라이선스에 따라 출시됩니다.


