distrifuser
v0.0.1beta0
[2024년 7월 29일] DistriFusion이 ColossalAI에서 지원됩니다!
[2024년 4월 4일] DistriFusion이 CVPR 2024 하이라이트 포스터로 선정되었습니다!
[2024년 2월 29일] DistriFusion이 CVPR 2024에서 승인되었습니다! 우리 코드는 공개적으로 사용 가능합니다!
 여러 GPU를 활용하여 이미지 품질을 저하시키지 않고 확산 모델 추론을 가속화하는 훈련이 필요 없는 알고리즘인 DistriFusion을 소개합니다. Naïve Patch(개요 (b))는 패치 상호 작용 부족으로 인해 조각화 문제가 발생합니다. 제시된 예제는 1280×1920 해상도에서 50단계 오일러 샘플러를 사용하여 SDXL로 생성되었으며 대기 시간은 A100 GPU에서 측정되었습니다.
여러 GPU를 활용하여 이미지 품질을 저하시키지 않고 확산 모델 추론을 가속화하는 훈련이 필요 없는 알고리즘인 DistriFusion을 소개합니다. Naïve Patch(개요 (b))는 패치 상호 작용 부족으로 인해 조각화 문제가 발생합니다. 제시된 예제는 1280×1920 해상도에서 50단계 오일러 샘플러를 사용하여 SDXL로 생성되었으며 대기 시간은 A100 GPU에서 측정되었습니다.
DistriFusion: 고해상도 확산 모델을 위한 분산 병렬 추론
Muyang Li*, Tianle Cai*, Jiaxin Cao, Qinsheng Zhang, Han Cai, Junjie Bai, Yangqing Jia, Ming-Yu Liu, Kai Li 및 Song Han
MIT, 프린스턴, Lepton AI 및 NVIDIA
CVPR 2024에서.
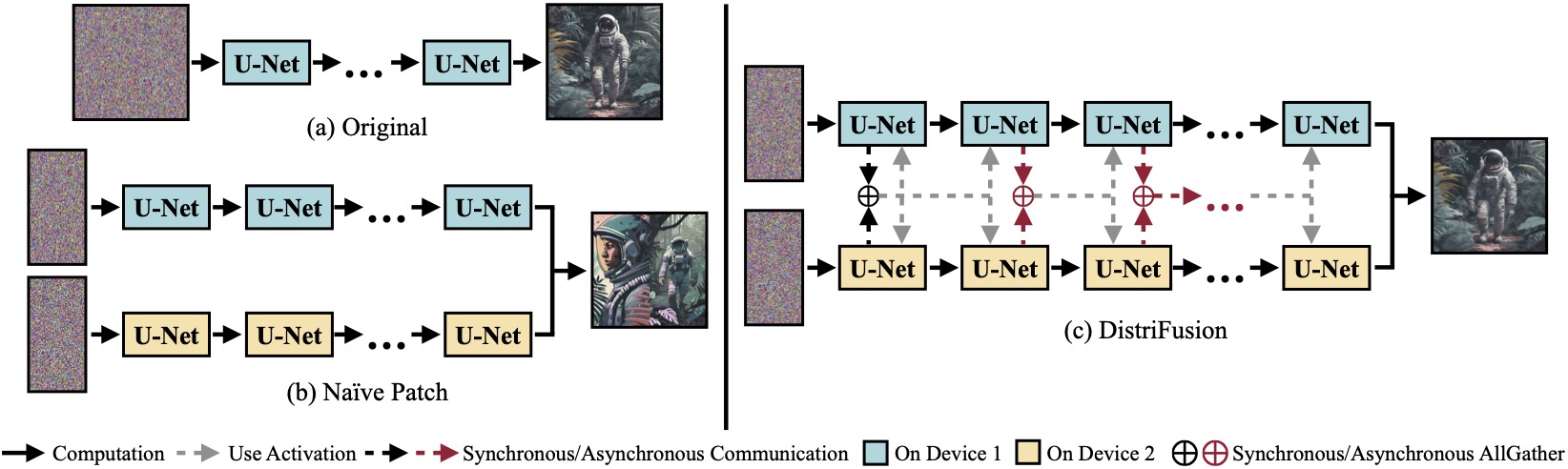 (a) 단일 장치에서 실행되는 원래 확산 모델. (b) 이미지를 2개의 GPU에 걸쳐 2개의 패치로 단순하게 분할하면 패치 간 상호 작용이 없기 때문에 경계에 이음새가 뚜렷하게 나타납니다. (c) DistriFusion은 첫 번째 단계에서 패치 상호 작용을 위해 동기식 통신을 사용합니다. 그런 다음 비동기 통신을 통해 이전 단계의 활성화를 재사용합니다. 이러한 방식으로 통신 오버헤드를 계산 파이프라인에 숨길 수 있습니다.
(a) 단일 장치에서 실행되는 원래 확산 모델. (b) 이미지를 2개의 GPU에 걸쳐 2개의 패치로 단순하게 분할하면 패치 간 상호 작용이 없기 때문에 경계에 이음새가 뚜렷하게 나타납니다. (c) DistriFusion은 첫 번째 단계에서 패치 상호 작용을 위해 동기식 통신을 사용합니다. 그런 다음 비동기 통신을 통해 이전 단계의 활성화를 재사용합니다. 이러한 방식으로 통신 오버헤드를 계산 파이프라인에 숨길 수 있습니다.
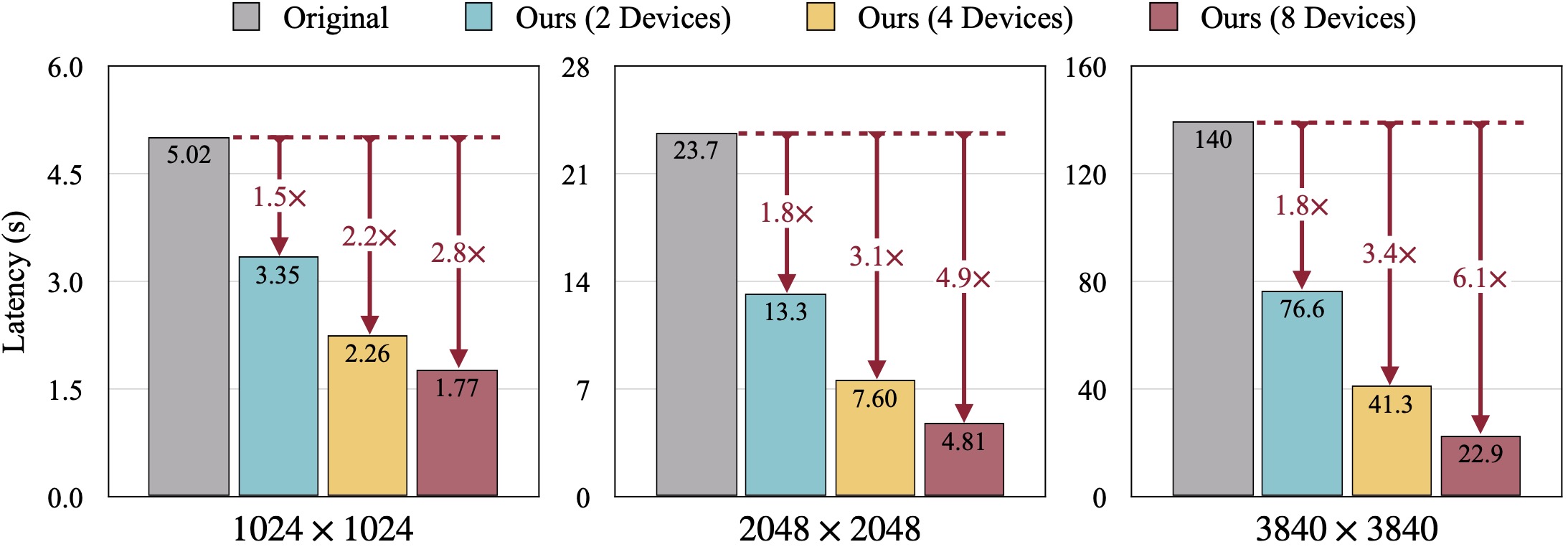
 SDXL의 정성적 결과. FID는 실측 이미지를 기준으로 계산됩니다. DistriFusion은 시각적 충실도를 유지하면서 사용된 장치 수에 따라 대기 시간을 줄일 수 있습니다.
SDXL의 정성적 결과. FID는 실측 이미지를 기준으로 계산됩니다. DistriFusion은 시각적 충실도를 유지하면서 사용된 장치 수에 따라 대기 시간을 줄일 수 있습니다.
참고자료:
PyTorch를 설치한 후 PyPI와 함께 distrifuser 설치할 수 있어야 합니다.
pip install distrifuser또는 GitHub를 통해:
pip install git+https://github.com/mit-han-lab/distrifuser.git아니면 로컬에서 개발을 위해
git clone [email protected]:mit-han-lab/distrifuser.git
cd distrifuser
pip install -e . scripts/sdxl_example.py 에서는 DistriFusion과 함께 SDXL을 실행하기 위한 최소 스크립트를 제공합니다.
import torch
from distrifuser . pipelines import DistriSDXLPipeline
from distrifuser . utils import DistriConfig
distri_config = DistriConfig ( height = 1024 , width = 1024 , warmup_steps = 4 )
pipeline = DistriSDXLPipeline . from_pretrained (
distri_config = distri_config ,
pretrained_model_name_or_path = "stabilityai/stable-diffusion-xl-base-1.0" ,
variant = "fp16" ,
use_safetensors = True ,
)
pipeline . set_progress_bar_config ( disable = distri_config . rank != 0 )
image = pipeline (
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k" ,
generator = torch . Generator ( device = "cuda" ). manual_seed ( 233 ),
). images [ 0 ]
if distri_config . rank == 0 :
image . save ( "astronaut.png" ) 특히, 우리의 distrifuser 디퓨저와 동일한 API를 공유하며 비슷한 방식으로 사용할 수 있습니다. DistriConfig 정의하고 래핑된 DistriSDXLPipeline 사용하여 사전 훈련된 SDXL 모델을 로드하기만 하면 됩니다. 그런 다음 디퓨저에서 StableDiffusionXLPipeline 과 같은 이미지를 생성할 수 있습니다. 실행 명령은
torchrun --nproc_per_node= $N_GPUS scripts/sdxl_example.py 여기서 $N_GPUS 는 사용하려는 GPU 수입니다.
또한 scripts/sd_example.py 에서 DistriFusion과 함께 SD1.4/2를 실행하기 위한 최소 스크립트를 제공합니다. 사용법은 동일합니다.
벤치마크 결과는 PyTorch 2.2 및 디퓨저 0.24.0을 사용하고 있습니다. 먼저 몇 가지 추가 종속성을 설치해야 할 수도 있습니다.
pip install git+https://github.com/zhijian-liu/torchprofile datasets torchmetrics dominate clean-fid scripts/generate_coco.py 사용하여 COCO 캡션이 포함된 이미지를 생성할 수 있습니다. 명령은
torchrun --nproc_per_node=$N_GPUS scripts/generate_coco.py --no_split_batch
여기서 $N_GPUS 는 사용하려는 GPU 수입니다. 기본적으로 생성된 결과는 results/coco 에 저장됩니다. --output_root 사용하여 사용자 정의할 수도 있습니다. 조정할 수 있는 몇 가지 추가 인수는 다음과 같습니다.
--num_inference_steps : 추론 단계 수입니다. 기본적으로 50을 사용합니다.--guidance_scale : 분류자가 없는 안내 척도입니다. 기본적으로 5를 사용합니다.--scheduler : 확산 샘플러. 기본적으로 DDIM 샘플러를 사용합니다. 오일러 샘플러에는 euler , DPM 솔버에는 dpm-solver 사용할 수도 있습니다.--warmup_steps : 추가 준비 단계 수(기본값은 4)입니다.--sync_mode : 다양한 GroupNorm 동기화 모드. 기본적으로 수정된 비동기 GroupNorm을 사용합니다.--parallelism : 사용하는 병렬성 패러다임입니다. 기본적으로 이는 패치 병렬성입니다. 텐서 병렬 처리에는 tensor 사용하고 단순 패치에는 naive_patch 사용할 수 있습니다. 모든 이미지를 생성한 후 스크립트 scripts/compute_metrics.py 사용하여 PSNR, LPIPS 및 FID를 계산할 수 있습니다. 사용법은
python scripts/compute_metrics.py --input_root0 $IMAGE_ROOT0 --input_root1 $IMAGE_ROOT1 여기서 $IMAGE_ROOT0 및 $IMAGE_ROOT1 은 비교하려는 이미지 폴더의 경로입니다. IMAGE_ROOT0 이 실측 폴더인 경우 크기 조정을 위해 --is_gt 플래그를 추가하세요. 또한 실제 이미지를 덤프하기 위한 scripts scripts/dump_coco.py 도 제공합니다.
scripts/run_sdxl.py 사용하여 다양한 방법으로 대기 시간을 벤치마킹할 수 있습니다. 명령은
torchrun --nproc_per_node= $N_GPUS scripts/run_sdxl.py --mode benchmark --output_type latent 여기서 $N_GPUS 는 사용하려는 GPU 수입니다. scripts/generate_coco.py 와 유사하게 일부 인수를 변경할 수도 있습니다.
--num_inference_steps : 추론 단계 수입니다. 기본적으로 50을 사용합니다.--image_size : 생성된 이미지 크기입니다. 기본적으로 1024×1024입니다.--no_split_batch : 분류자 없는 지침을 위해 일괄 분할을 비활성화합니다.--warmup_steps : 추가 준비 단계 수(기본값은 4)입니다.--sync_mode : 다양한 GroupNorm 동기화 모드. 기본적으로 수정된 비동기 GroupNorm을 사용합니다.--parallelism : 사용하는 병렬성 패러다임입니다. 기본적으로 이는 패치 병렬성입니다. 텐서 병렬 처리에는 tensor 사용하고 단순 패치에는 naive_patch 사용할 수 있습니다.--warmup_times / --test_times : 준비/테스트 실행 횟수입니다. 기본적으로 각각 5와 20입니다. 연구에 이 코드를 사용하는 경우 논문을 인용해 주세요.
@inproceedings { li2023distrifusion ,
title = { DistriFusion: Distributed Parallel Inference for High-Resolution Diffusion Models } ,
author = { Li, Muyang and Cai, Tianle and Cao, Jiaxin and Zhang, Qinsheng and Cai, Han and Bai, Junjie and Jia, Yangqing and Liu, Ming-Yu and Li, Kai and Han, Song } ,
booktitle = { Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) } ,
year = { 2024 }
}우리 코드는 Huggingface/diffusers 및 lmxyy/sige를 기반으로 개발되었습니다. MAC 측정을 위한 torchprofile, FID 계산을 위한 clean-fid, PSNR 및 LPIPS를 위한 Lightning-AI/torchmetrics에 감사드립니다.
유용한 토론과 귀중한 피드백을 주신 Jun-Yan Zhu와 Ligeng Zhu에게 감사드립니다. 이 프로젝트는 MIT-IBM Watson AI Lab, Amazon, MIT Science Hub 및 National Science Foundation의 지원을 받습니다.


