모든 것-AI
완벽하게 능숙하고 AI 기반의 로컬 챗봇 도우미가 되셨나요?
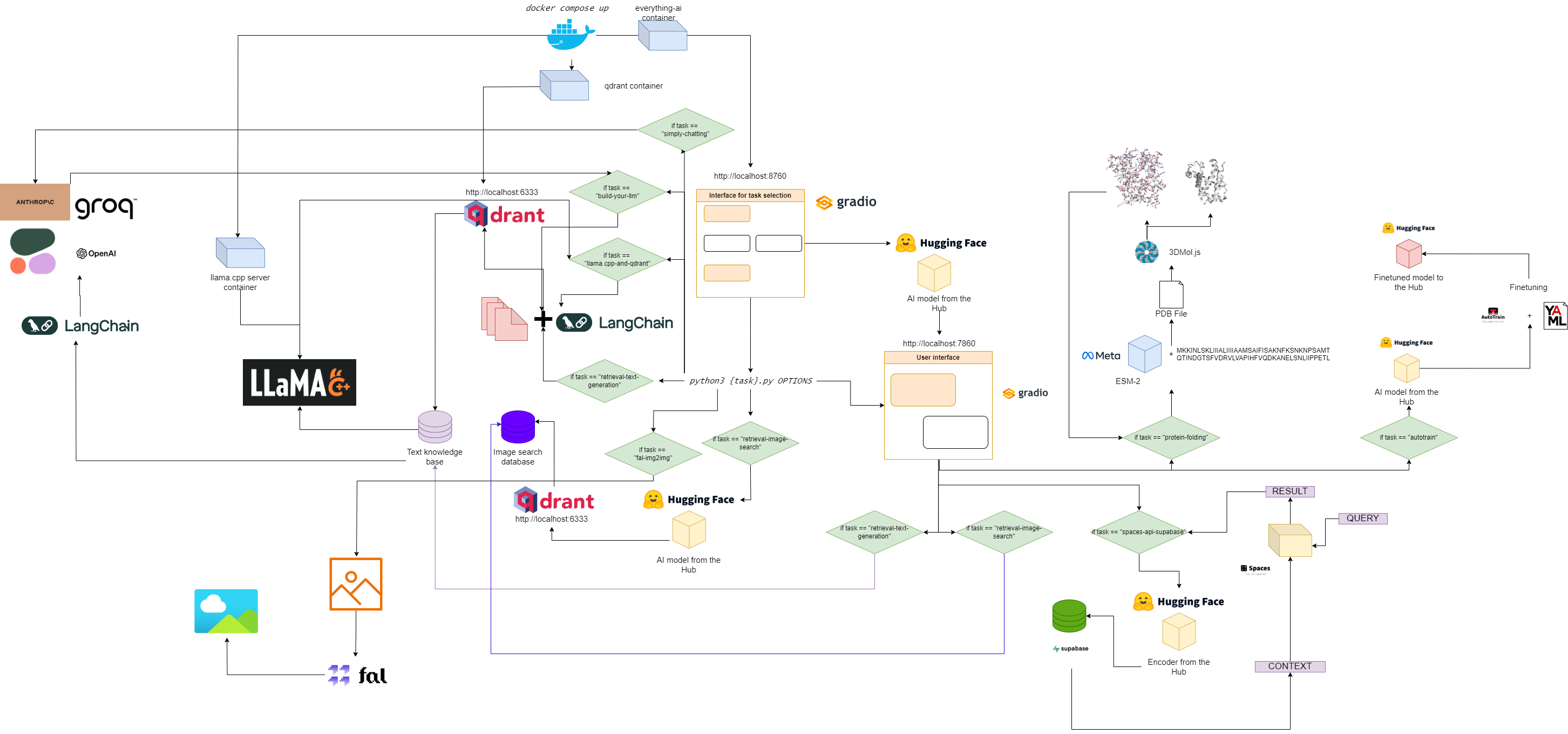
Everything-ai의 흐름도
빠른 시작
1. 이 저장소를 복제하세요.
git clone https://github.com/AstraBert/everything-ai.git
cd everything-ai
2. .env 파일 설정
수정하다:
- 로컬 파일 시스템을 Docker 컨테이너에 마운트할 수 있도록 .env 파일의
VOLUME 변수. - 다운로드한 GGUF 모델을 저장한 위치를 llama.cpp에 알릴 수 있도록 .env 파일의
MODELS_PATH 변수입니다. - llama.cpp에 사용할 모델을 알릴 수 있도록 .env 파일의
MODEL 변수(gguf 파일의 실제 이름을 사용하고 .gguf 확장자를 잊지 마세요!) - llama.cpp가 출력으로 생성할 수 있는 새 토큰 수를 알려줄 수 있도록 .env 파일의
MAX_TOKENS 변수.
.env 파일의 예는 다음과 같습니다.
VOLUME= " c:/Users/User/:/User/ "
MODELS_PATH= " c:/Users/User/.cache/llama.cpp/ "
MODEL= " stories260K.gguf "
MAX_TOKENS= " 512 "
이는 이제 로컬 컴퓨터의 "c:/Users/User/" 아래에 있는 모든 항목이 Docker 컨테이너의 "/User/" 아래에 있다는 의미입니다. 즉, llama.cpp는 모델을 찾을 위치와 찾을 모델을 알고 있습니다. 출력에 대한 최대 새 토큰과 함께.
3. 필요한 이미지를 가져옵니다
docker pull astrabert/everything-ai:latest
docker pull qdrant/qdrant:latest
docker pull ghcr.io/ggerganov/llama.cpp:server
4. 다중 컨테이너 앱 실행
5. localhost:8670 으로 이동하여 어시스턴트를 선택하세요.
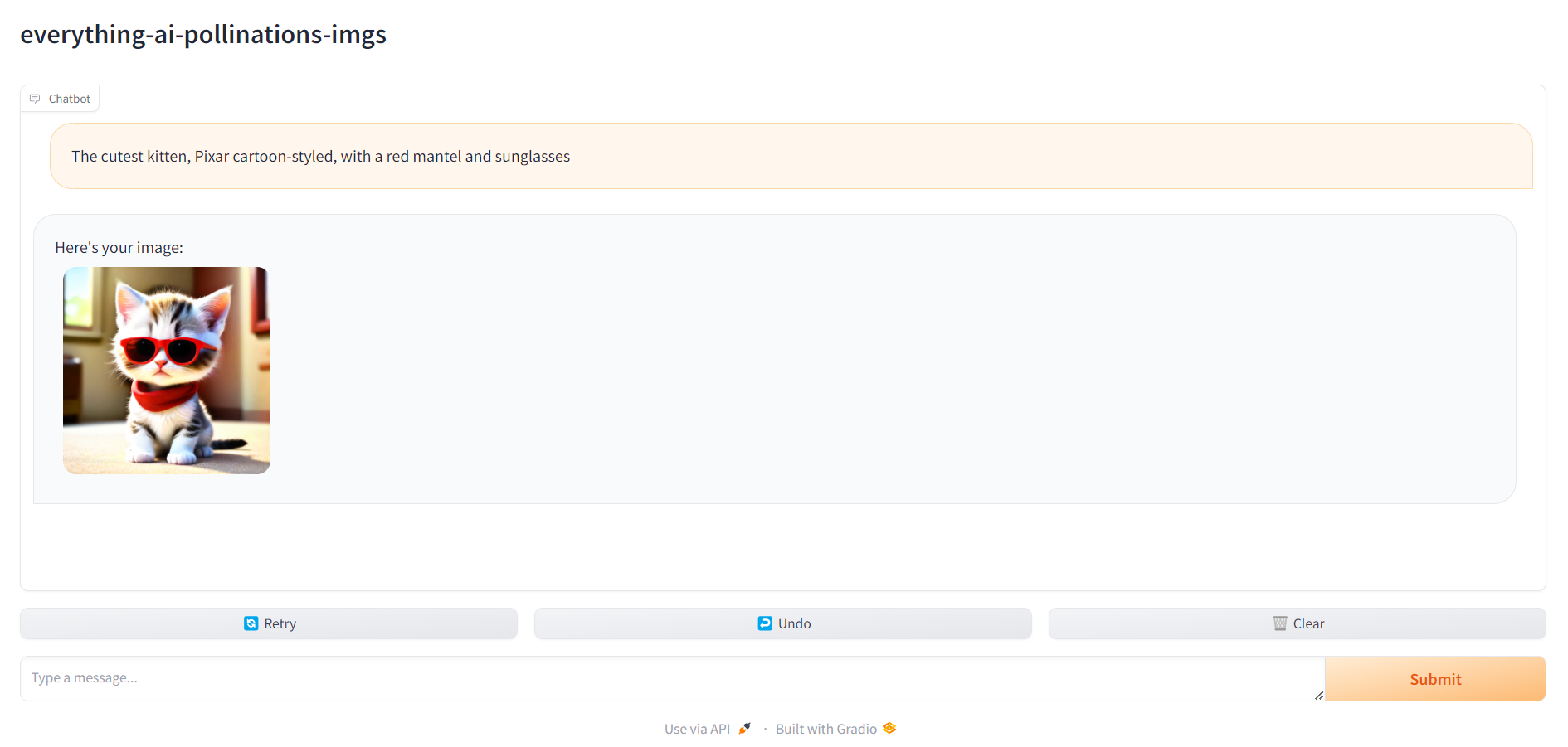
다음과 같은 내용이 표시됩니다.
다음 중에서 작업을 선택하세요.
- 검색 텍스트 생성 :
qdrant 백엔드를 사용하여 모델의 응답을 쿼리하고 조정할 수 있는 검색 친화적인 지식 기반을 구축합니다. 쉼표로 구분된 경로로 지정된 pdf/pdf 묶음 또는 관심 있는 모든 pdf가 저장된 디렉토리를 전달해야 합니다(둘 다 제공 하지 마십시오 ). ISO 명명법 - MULTILINGUAL을 사용하여 PDF가 작성되는 언어를 지정할 수도 있습니다. - agnostic-text-generation : ChatGPT와 유사한 텍스트 생성(검색 아키텍처 없음)이지만 HF Hub의 모든 텍스트 생성 모델을 지원합니다(하드웨어가 지원하는 한!) - 다중 언어
- text-summarization : 텍스트와 PDF를 요약하고 HF Hub의 모든 텍스트 요약 모델을 지원합니다. - 영어로만 제공
- 이미지 생성 : 안정적인 확산, HF Hub의 모든 텍스트-이미지 모델 지원 - 다중 언어
- 이미지 생성-수분 : 안정적인 확산, Pollinations AI API 사용; '이미지 생성-수분'을 선택하면 작업 외에 다른 것을 지정할 필요가 없습니다. - MULTILINGUAL
- image-classification : 이미지 분류, HF Hub의 모든 이미지 분류 모델 지원 - 영어로만 제공
- image-to-text : 이미지를 설명하고 HF Hub의 모든 이미지-텍스트 모델을 지원합니다. - 영어로만 제공
- 오디오 분류 : 오디오 파일 또는 마이크 녹음을 분류하고 HF 허브에서 오디오 분류 모델을 지원합니다.
- 음성 인식 : 오디오 파일 또는 마이크 녹음을 전사하고 HF 허브에서 자동 음성 인식 모델을 지원합니다.
- 비디오 생성 : 텍스트 프롬프트 시 비디오 생성, HF 허브에서 텍스트-비디오 모델 지원 - 영어로만 제공
- 단백질 접힘 : ESM-2 백본 모델을 사용하여 아미노산 서열에서 단백질의 3D 구조를 얻습니다. - GPU 전용
- autotrain : HF 사용자 이름, HF 쓰기 토큰 및 훈련을 위한 yaml 구성 파일 경로를 지정하여 autotrain-advanced를 사용하여 특정 다운스트림 작업에 대한 모델을 미세 조정합니다.
- space-api-supabase : 보다 강력한 LLM 및 대규모 RAG 지향 벡터 데이터베이스를 활용하기 위해 Supabase PostgreSQL 데이터베이스와 함께 HF Spaces API를 사용합니다. - 다중 언어
- llama.cpp-and-qdrant : retrieval-text- Generation 과 동일하지만 llama.cpp를 추론 엔진으로 사용하므로 모델을 지정해서는 안 됩니다. - MULTILINGUAL
- build-your-llm : Qdrant 데이터베이스와 PDF 및 Anthropic, OpenAI, Cohere 또는 Groq 모델의 기능을 결합한 사용자 정의 가능한 채팅 LLM을 구축하세요. API 키만 있으면 됩니다! Qdrant 데이터베이스를 구축하려면 쉼표로 구분된 경로로 지정된 pdf/pdf 묶음 또는 관심 있는 모든 pdf가 저장된 디렉토리를 전달해야 합니다(둘 다 제공 하지 마십시오 ). ISO 명명법( MULTILINGUAL , LANGFUSE INTEGRATION ) 을 사용하여 PDF가 작성되는 언어를 지정할 수도 있습니다.
- simple-chatting : Anthropic, OpenAI, Cohere 또는 Groq 모델(RAG 파이프라인 없음)을 활용하여 사용자 정의 가능한 채팅 LLM을 구축하세요. API 키만 있으면 됩니다! - 다국어 , LANGFUSE 통합
- fal-img2img : fal.ai ComfyUI API를 사용하여 PNG 및 JPEG 이미지에서 시작하는 이미지를 생성하세요. API 키만 있으면 됩니다! 프롬프트와 시드로 작업하는 생성을 사용자 정의할 수도 있습니다. - 영어로만 가능
- image-retrieval-search : 폴더를 데이터베이스 입력으로 업로드하여 이미지 데이터베이스를 검색합니다. 폴더의 구조는 다음과 같아야 합니다.
./
├── test/
| ├── label1/
| └── label2/
└── train/
├── label1/
└── label2/
자신의 사진에서 시작하여 데이터베이스를 쿼리할 수 있습니다.
6. localhost:7860 으로 이동하여 어시스턴트 사용을 시작하세요.
모든 것이 준비되면 localhost:7860 으로 이동하여 어시스턴트 사용을 시작할 수 있습니다.