image ranker
1.0.0
git clone https://github.com/QuentinWach/image-ranker.git
cd image-ranker
python -m venv venv
source venv/bin/activate # On Windows, use `venvScriptsactivate`
pip install flask trueskill
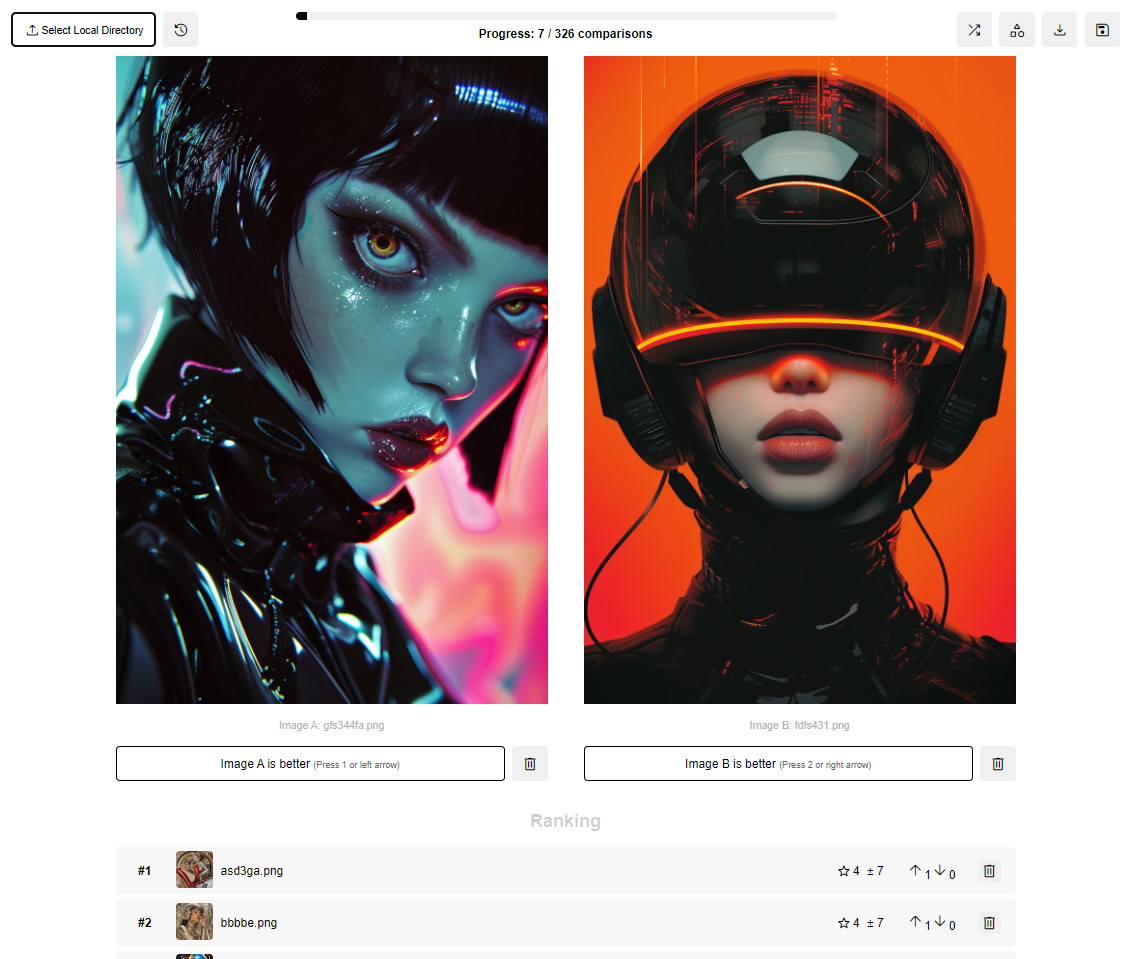
python app.py .http://localhost:5000 으로 이동합니다. 각 이미지는 두 가지 값으로 표시됩니다.
새 항목은 기본 μ(종종 25이지만 여기서는 0)와 높은 σ(종종 8.33)로 시작합니다. 두 항목을 비교할 때 해당 항목의 μ 및 σ 값을 사용하여 예상 결과를 계산합니다. 실제 결과는 이러한 기대와 비교됩니다. 승자의 μ는 증가하고 패자의 μ는 감소합니다. 두 항목의 σ는 일반적으로 감소합니다(확률 증가를 나타냄). 변화의 규모는 다음에 따라 달라집니다.
가우스 분포를 사용하여 기술 수준을 모델링하고 효율적인 업데이트를 위해 요인 그래프와 메시지 전달을 사용합니다. 항목은 일반적으로 μ - 3σ(보수적 추정치)에 따라 순위가 지정됩니다.
중요한 점은 알고리즘이 새 이미지만 업데이트하는 것이 아니라 모든 비교 시 이전에 순위가 매겨진 모든 항목을 동시에 업데이트한다는 것입니다. 이는 알고리즘이 쌍별 비교뿐만 아니라 비교에서 사용 가능한 모든 정보를 고려할 수 있음을 의미합니다.
따라서 전반적으로 이 시스템은 불완전한 비교 데이터로 효율적인 순위를 매길 수 있으므로 철저한 쌍별 비교가 실용적이지 않은 대규모 항목 세트에 적합합니다!
순위를 매기려면 순차적 제거를 활성화할 수 있는 옵션이 있습니다.
셔플 버튼을 클릭하여 언제든지 이미지 쌍을 수동으로 셔플하거나 세 번의 비교마다 자동으로 셔플할 수 있습니다. 이는 순위의 불확실성을 최대한 빨리 최소화하려는 경우에 유용합니다. 순위가 몇 번만 지정되고 불확실성 σ가 높은 이미지가 우선순위를 갖습니다. 이렇게 하면 이미 확신하고 있는 이미지의 순위를 매기는 데 더 많은 시간을 소비하지 않고 매우 유사한 점수를 가진 이미지의 보다 정확한 순위를 더 빠르게 얻을 수 있습니다.
Image Ranker 는 누구나 자신의 특정 요구 사항에 맞게 맞춤화된 기반 모델을 만들 수 있도록 하기 위한 전반적인 노력의 일부입니다.
훈련 후 기초 모델은 이를 실제로 유용하게 만듭니다. 예를 들어, 대규모 언어 모델은 사후 교육 없이는 대화조차 할 수 없습니다. 이미지의 경우에도 마찬가지입니다. 이를 위해 일반적인 기술은 RLHF인데, 이는 보상 모델을 사용하여 사용자 선호도에 따라 생성 기반 모델의 출력을 보상하거나 처벌합니다. 이 보상 모델을 생성하려면 데이터 세트(여기서는 이미지)가 필요한 사용자 선호도를 알아야 합니다. 따라서 Stable Diffusion 또는 Flux와 같은 기존 모델에 근본적인 변화를 주거나 자체 모델을 교육하려는 경우 어떤 이미지가 더 나은지 알기 위해 이미지의 순위를 매기는 것이 중요합니다. 이것이 바로 이 앱이 등장하는 곳입니다.
질문이 있으시면 GitHub에서 이슈를 열어주세요! 그리고 새로운 기능을 제안하거나 기여하기 위해 이 프로젝트를 자유롭게 포크해 보세요. OPEN_TODO.md 파일에는 구현 예정인 기능 목록이 포함되어 있습니다. 도움을 주시면 대단히 감사하겠습니다! 즉, 프로젝트를 지원하는 가장 쉬운 방법은 이 저장소에 !
감사합니다!


