serverless rag ynetnews bedrock demo
1.0.0
QA(질문응답)는 자연어로 제기된 사실적 질의에 대한 답변을 추출하는 중요한 작업입니다. 일반적으로 QA 시스템은 정형 또는 비정형 데이터가 포함된 지식 기반에 대한 쿼리를 처리하고 정확한 정보로 응답을 생성합니다. 높은 정확성을 보장하는 것은 특히 기업 사용 사례에 유용하고 안정적이며 신뢰할 수 있는 질문 응답 시스템을 개발하는 데 핵심입니다.
Amazon Titan, Anthropic Claude 및 AI21 Jurassic 2와 같은 생성적 AI 모델은 확률 분포를 사용하여 질문에 대한 응답을 생성합니다. 이러한 모델은 방대한 양의 텍스트 데이터에 대해 훈련되어 시퀀스에서 다음에 무엇이 올지 또는 특정 단어 뒤에 어떤 단어가 올지 예측할 수 있습니다. 그러나 이러한 모델은 데이터에 항상 어느 정도의 불확실성이 있기 때문에 모든 질문에 대해 정확하거나 결정적인 답변을 제공할 수 없습니다.
기업은 도메인별 독점 데이터를 쿼리하고 해당 정보를 사용하여 질문에 답해야 하며, 보다 일반적으로는 모델이 훈련되지 않은 데이터를 사용해야 합니다.
이 리포지토리에서는 다음 QA 패턴을 살펴보겠습니다.
우리는 질문을 가능한 한 많은 관련 컨텍스트와 연결하여 우리가 찾고 있는 답변이나 정보를 포함할 가능성이 있는 첫 번째 방법을 개선하는 검색 증강 생성을 사용합니다. 여기서 문제는 컨텍스트 정보를 얼마나 사용할 수 있는지에 대한 제한이 모델의 토큰 제한에 따라 결정된다는 것입니다.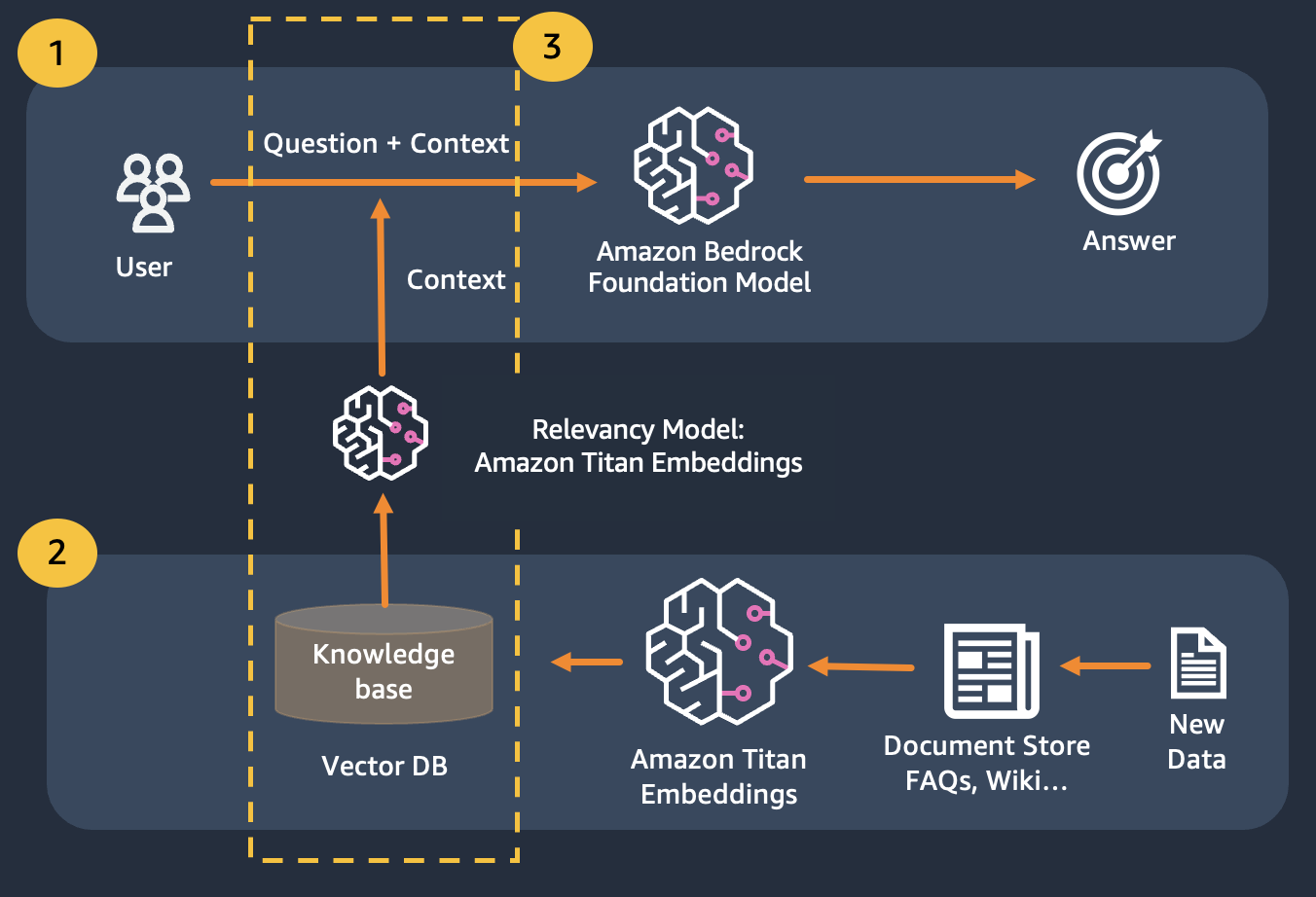
이는 RAG(Retrival Augmented Generation)를 사용하여 극복할 수 있습니다.
RAG는 임베딩 사용을 결합하여 문서 코퍼스를 색인화하여 지식 베이스를 구축하고 LLM을 사용하여 지식 베이스에 있는 문서의 하위 집합에서 정보를 추출합니다.
RAG를 위한 준비 단계로 지식 베이스를 구성하는 문서를 고정된 크기(선택한 임베딩 모델의 최대 입력 크기와 일치)의 청크로 분할한 후 모델에 전달하여 임베딩 벡터를 얻습니다. 문서의 원본 청크 및 추가 메타데이터와 함께 포함된 내용은 벡터 데이터베이스에 저장됩니다. 벡터 데이터베이스는 벡터 간의 유사성 검색을 효율적으로 수행하도록 최적화되어 있습니다.
비공개이거나 자주 변경되는 데이터 저장소를 보유한 고객. RAG 접근 방식은 두 가지 문제를 해결합니다. 다음과 같은 과제를 안고 있는 고객은 이 랩을 통해 이점을 얻을 수 있습니다.
이 모듈을 마친 후에는 다음 사항을 잘 이해해야 합니다.
이 모듈에서는 Bedrock을 사용하여 QA 패턴을 구현하는 방법을 안내합니다. 또한 벡터 데이터베이스에 로드할 임베딩을 준비했습니다.
Titan Embeddings를 사용하여 사용자 질문의 임베딩을 얻은 다음 해당 임베딩을 사용하여 벡터 데이터베이스에서 가장 관련성이 높은 문서를 검색하고 상위 3개 문서를 연결하는 프롬프트를 구축하고 Bedrock을 통해 LLM 모델을 호출할 수 있습니다.


