BeatLearning
1.0.0
좋아하는 리듬 게임에서 사용할 수 없는 노래를 연주하고 싶었던 적이 있나요? 해당 노래의 무한한 변주곡을 연주하고 싶었던 적이 있나요?
이 오픈 소스 연구 프로젝트는 자동 비트맵 생성 프로세스를 민주화하고 게임 개발자, 플레이어 및 매니아 모두에게 접근 가능한 도구와 기반 모델을 제공하여 리듬 게임에서 창의성과 혁신의 새로운 시대를 여는 것을 목표로 합니다.
예(더 많은 내용이 곧 제공될 예정):
먼저 Python 3.12를 설치하고 저장소 디렉터리로 이동하여 다음을 통해 가상 환경을 만들어야 합니다.
python3 -m venv venv
그런 다음 Windows 시스템을 사용하는 경우 source venv/bin/activate 또는 venvScriptsactivate 호출하십시오. 가상 환경이 활성화된 후 다음을 통해 필요한 라이브러리를 설치할 수 있습니다.
pip3 install -r requirements.txt
Jupyter를 사용하여 예제 notebooks/ 액세스할 수 있습니다.
jupyter notebook
GPU 인스턴스를 사용할 수 있는 한 Google Collab 버전도 사용해 볼 수 있습니다(기본 CPU 인스턴스는 노래를 변환하는 데 시간이 오래 걸립니다).
파이프라인은 현재 OSU 비트맵만 지원합니다.
이 저장소는 아직 작업 중입니다 . 목표는 노래에 관계없이 다양한 리듬 게임의 비트맵을 자동으로 생성할 수 있는 생성 모델을 개발하는 것입니다. 이 연구는 아직 진행 중이지만 목표는 MVP를 최대한 빨리 출시하는 것입니다.
모든 기여는 가치가 있으며, 특히 기초 모델 교육을 위한 컴퓨팅 기부 형태에서는 더욱 그렇습니다. 그러니 관심이 있으시면 자유롭게 참여해 보세요!
AI 기반 비트맵 생성의 무한한 가능성을 탐구하고 리듬 게임의 미래를 형성하는 데 동참하세요!
HuggingFace에서 모델을 볼 수 있습니다.
리듬 게임 비트맵은 처음에 중간 파일 형식으로 변환된 후 100ms 청크로 토큰화됩니다. 각 토큰은 이 기간 내에 최대 2개의 서로 다른 이벤트(홀드 및/또는 히트)를 10ms 정확도로 양자화하여 인코딩할 수 있습니다. 토크나이저의 어휘는 이 기준을 충족하기 위해 데이터에서 학습되는 것이 아니라 미리 계산됩니다. 해당 분야의 품질 훈련 사례가 부족하기 때문에 문맥 길이와 어휘 크기는 의도적으로 작게 유지됩니다.
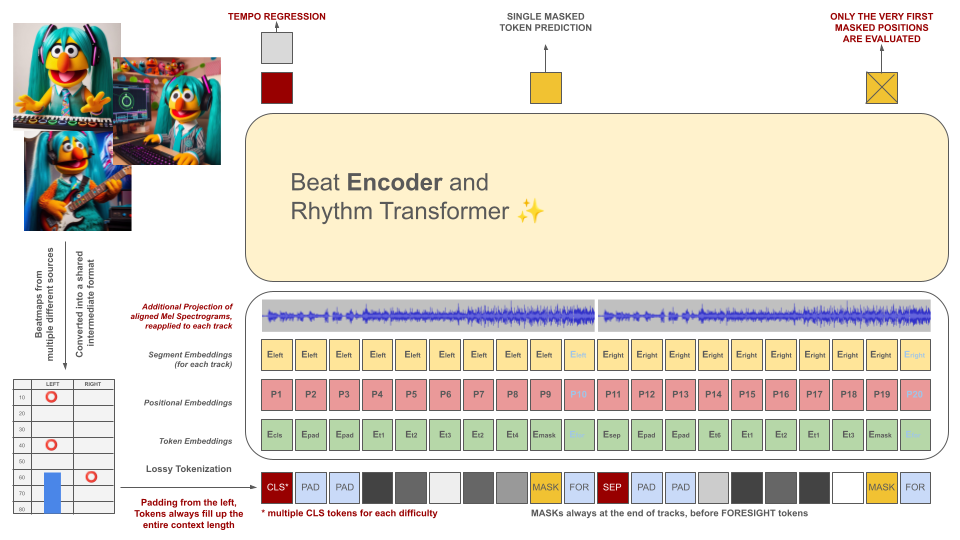 이러한 토큰은 오디오 데이터 조각(토큰과 정렬된 투영된 Mel 스펙토그램)과 함께 마스크된 인코더 모델의 입력 역할을 합니다. BeRT와 유사하게 인코더 모델에는 훈련 중에 두 가지 목표가 있습니다. 즉, 회귀 작업을 통해 템포를 추정하고 청력 손실 기능을 통해 마스크된(다음) 토큰을 예측하는 것입니다. 1, 2, 4개의 트랙이 있는 비트맵이 지원됩니다. 각 토큰은 디코더 아키텍처의 생성 프로세스를 반영하여 왼쪽에서 오른쪽으로 예측됩니다. 그러나 마스킹된 토큰은 오른쪽에서 예측 토큰으로 표시되는 미래의 추가 오디오 정보에도 액세스할 수 있습니다.
이러한 토큰은 오디오 데이터 조각(토큰과 정렬된 투영된 Mel 스펙토그램)과 함께 마스크된 인코더 모델의 입력 역할을 합니다. BeRT와 유사하게 인코더 모델에는 훈련 중에 두 가지 목표가 있습니다. 즉, 회귀 작업을 통해 템포를 추정하고 청력 손실 기능을 통해 마스크된(다음) 토큰을 예측하는 것입니다. 1, 2, 4개의 트랙이 있는 비트맵이 지원됩니다. 각 토큰은 디코더 아키텍처의 생성 프로세스를 반영하여 왼쪽에서 오른쪽으로 예측됩니다. 그러나 마스킹된 토큰은 오른쪽에서 예측 토큰으로 표시되는 미래의 추가 오디오 정보에도 액세스할 수 있습니다.
AI 모델의 목적은 개별적으로 제작된 비트맵의 가치를 낮추는 것이 아니라 다음과 같습니다.
생성된 모든 콘텐츠는 EU 규정을 준수해야 하며 AI 모델의 관련성을 나타내는 메타데이터를 포함하여 적절하게 라벨이 지정되어야 합니다.
저작권 보호 자료에 대한 비트맵 생성은 엄격히 금지됩니다! 귀하에게 권리가 있는 노래만 사용하세요!
OSU 파일 예제에 포함된 오디오는 OSU 웹사이트의 주요 아티스트 섹션에 나열된 아티스트로부터 가져온 것이며 특히 osu! 관련 콘텐츠에 사용하도록 라이센스가 부여되었습니다.
향후 비트맵이 훈련 데이터로 활용되는 것을 방지하려면 비트맵 파일에 다음 메타데이터를 포함하세요.
robots: disallow
이 프로젝트는 AIOSU로 알려진 이전 시도에서 영감을 얻었습니다.
OSU의 위키에 의존하는 것 외에도, osu-parser는 비트맵 선언(특히 슬라이더)을 명확하게 하는 데 중요한 역할을 했습니다. 트랜스포머 모델은 NanoGPT와 BeRT의 파이토치 구현의 영향을 받았습니다.


