LLM Alignment Project
1.0.0
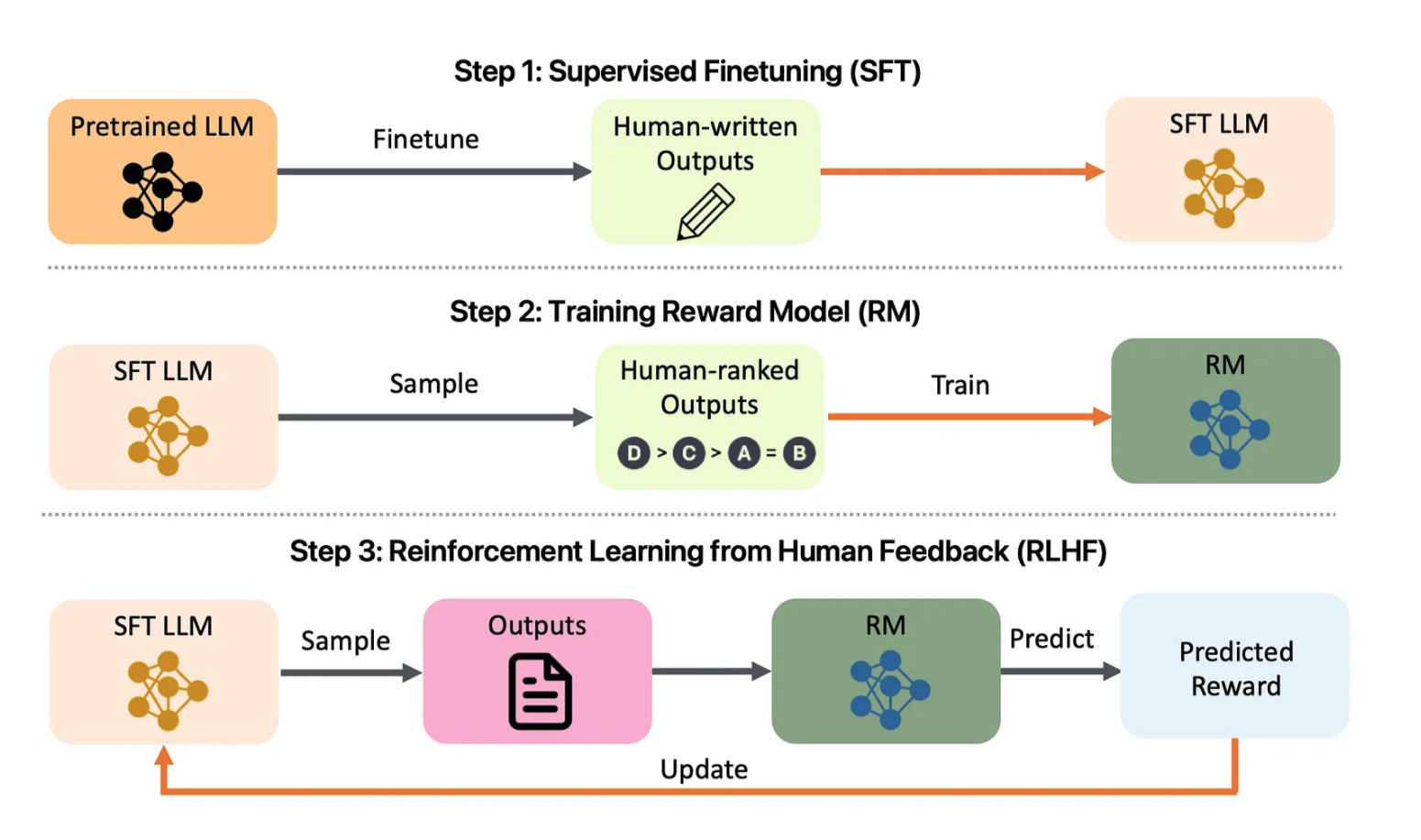
그림 1: LLM 정렬 프로젝트 개요. 살펴보세요: arXiv:2308.05374
LLM 정렬 템플릿은 LLM(대형 언어 모델) 정렬을 위한 포괄적인 도구일 뿐만 아니라 자체 LLM 정렬 애플리케이션을 구축하기 위한 강력한 템플릿 역할도 합니다. PyTorch 프로젝트 템플릿과 같은 프로젝트 템플릿에서 영감을 받은 이 저장소는 전체 기능 스택을 제공하도록 설계되었으며, 자체 LLM 정렬 요구 사항에 맞게 사용자 정의하고 확장할 수 있는 출발점 역할을 합니다. 연구원, 개발자, 데이터 과학자 등 누구에게나 이 템플릿은 인간의 가치와 목표에 맞춰 맞춤화된 LLM을 효율적으로 생성하고 배포하기 위한 견고한 기반을 제공합니다.
LLM 정렬 템플릿은 RLHF(Reinforcement Learning from Human Feedback)를 사용하여 LLM 교육, 미세 조정, 배포 및 모니터링을 포함한 전체 기능 스택을 제공합니다. 이 프로젝트는 또한 평가 지표를 통합하여 언어 모델의 윤리적이고 효과적인 사용을 보장합니다. 인터페이스는 정렬 관리, 교육 지표 시각화 및 대규모 배포를 위한 사용자 친화적인 환경을 제공합니다.
app/ : API 및 UI 코드가 포함되어 있습니다.
auth.py , feedback.py , ui.py : 사용자 상호 작용, 피드백 수집 및 일반 인터페이스 관리를 위한 API 엔드포인트입니다.app.js , chart.js ), CSS( styles.css ) 및 Swagger API 문서( swagger.json ).chat.html , feedback.html , index.html ) src/ : 전처리 및 훈련을 위한 핵심 논리 및 유틸리티입니다.
preprocessing/ ):preprocess_data.py : 원본 데이터세트와 증강된 데이터세트를 결합하고 텍스트 정리를 적용합니다.tokenization.py : 토큰화를 처리합니다.training/ ):fine_tuning.py , transfer_learning.py , retrain_model.py : 모델 학습 및 재학습을 위한 스크립트입니다.rlhf.py , reward_model.py : RLHF를 사용한 보상 모델 훈련을 위한 스크립트입니다.utils/ ): 일반 유틸리티( config.py , logging.py , validation.py ). dashboards/ : 모니터링 및 모델 통찰력을 위한 성능 및 설명 가능성 대시보드입니다.
performance_dashboard.py : 훈련 지표, 검증 손실 및 정확도를 표시합니다.explainability_dashboard.py : SHAP 값을 시각화하여 모델 결정에 대한 통찰력을 제공합니다. tests/ : 단위, 통합 및 엔드투엔드 테스트입니다.
test_api.py , test_preprocessing.py , test_training.py : 다양한 단위 및 통합 테스트.e2e/ ): Cypress 기반 UI 테스트( ui_tests.spec.js ).load_testing/ ): 부하 테스트를 위해 Locust( locustfile.py )를 사용합니다. deployment/ : 배포 및 모니터링을 위한 구성 파일입니다.
kubernetes/ ): 확장 및 카나리아 릴리스를 위한 배포 및 수신 구성입니다.monitoring/ ): 성능 및 시스템 상태 모니터링을 위한 Prometheus( prometheus.yml ) 및 Grafana( grafana_dashboard.json ). 저장소 복제 :
git clone https://github.com/yourusername/LLM-Alignment-Template.git
cd LLM-Alignment-Template종속성 설치 :
pip install -r requirements.txt cd app/static
npm installDocker 이미지 빌드 :
docker-compose up --build애플리케이션에 액세스하십시오 .
http://localhost:5000 방문하세요. kubectl apply -f deployment/kubernetes/deployment.yml
kubectl apply -f deployment/kubernetes/service.ymlkubectl apply -f deployment/kubernetes/hpa.ymldeployment/kubernetes/canary_deployment.yml 사용하여 구성됩니다.deployment/monitoring/ 에서 Prometheus 및 Grafana 구성을 적용하세요.docker-compose.logging.yml 사용하여 Docker로 구성됩니다. 훈련 모듈( src/training/transfer_learning.py )은 BERT 와 같은 사전 훈련된 모델을 사용하여 사용자 정의 작업에 적응함으로써 상당한 성능 향상을 제공합니다.
data_augmentation.py 스크립트( src/data/ )는 역번역 및 패러프레이징과 같은 증강 기술을 적용하여 데이터 품질을 향상시킵니다.
rlhf.py 및 reward_model.py 스크립트를 사용하여 사람의 피드백을 기반으로 모델을 미세 조정합니다.feedback.html )을 통해 응답을 평가하고 모델은 retrain_model.py 를 사용하여 재교육합니다. explainability_dashboard.py 스크립트는 SHAP 값을 사용하여 모델이 특정 예측을 한 이유를 사용자가 이해하도록 돕습니다.
tests/ 에 위치하며 API, 전처리 및 교육 기능을 다룹니다.tests/load_testing/locustfile.py )로 구현되었습니다. 기여를 환영합니다! 개선 사항이나 새로운 기능에 대한 풀 요청이나 문제를 제출해 주세요.
이 프로젝트는 MIT 라이선스에 따라 라이선스가 부여됩니다. 자세한 내용은 LICENSE 파일을 참조하세요.
Amirsina Torfi가 ❤️으로 개발함


