?️ LLM을 사용한 이미지 음성 변환 GenAI 도구 ?♨️
OpenAI 및 LangChain과 함께 GenAI LLM 모델, Hugging Face AI 모델을 실행하여 업로드된 이미지의 맥락을 기반으로 오디오 단편 소설을 생성하는 AI 도구입니다. Streamlit & Hugging Space Cloud에 별도로 배포됩니다.
? Streamlit Cloud로 앱 실행
Streamlit에서 앱 실행
?HuggingFace Space Cloud로 앱 실행
HuggingFace Space에서 앱 실행
데모:
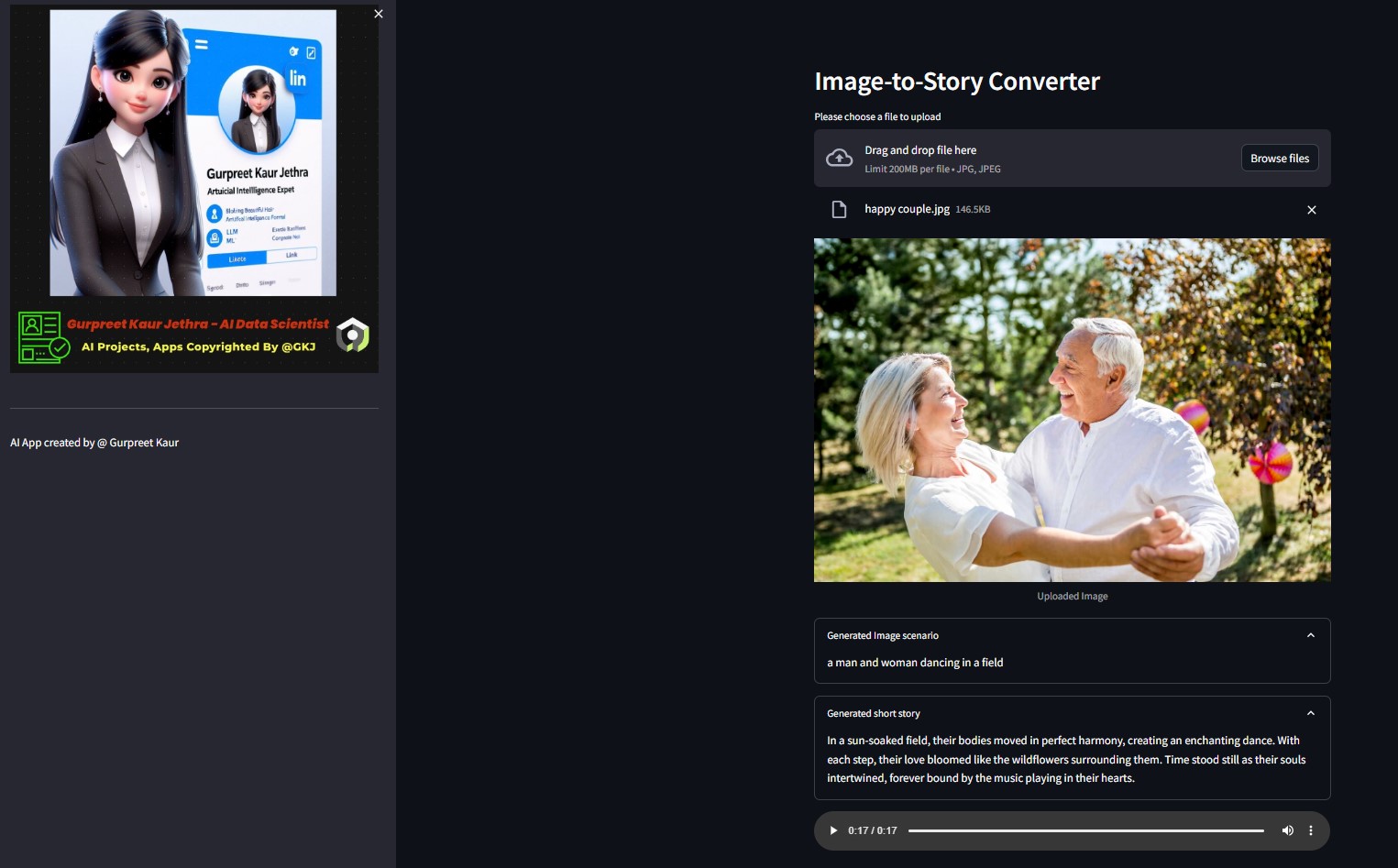
해당 img-audio 폴더에서 이 테스트 데모 이미지의 각 오디오 파일을 들을 수 있습니다.
?시스템 설계
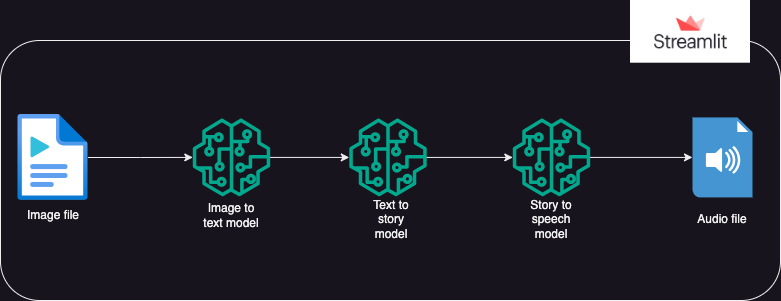
?접근하다
Hugging Face AI 모델을 사용하여 이미지에서 텍스트를 생성한 다음 텍스트에서 오디오를 생성하는 앱입니다.
실행은 3가지 부분으로 나누어집니다:
- 이미지를 텍스트로: 이미지-텍스트 변환기 모델(Salesforce/blip-image-captioning-base)을 사용하여 이미지 컨텍스트에 대한 AI 이해를 기반으로 텍스트 시나리오를 생성합니다.
- 텍스트에서 스토리로: OpenAI LLM 모델은 생성된 시나리오를 기반으로 단편 소설(50단어: 필요에 따라 조정 가능)을 생성하라는 메시지를 받습니다. gpt-3.5-터보
- 스토리-스피치: 텍스트-음성 변환기 모델(espnet/kan-bayashi_ljspeech_vits)을 사용하여 생성된 단편 소설을 음성 내레이션 오디오 파일로 변환합니다.
- Streamlit을 사용하여 사용자 인터페이스가 구축되어 이미지 업로드 및 오디오 파일 재생이 가능합니다.
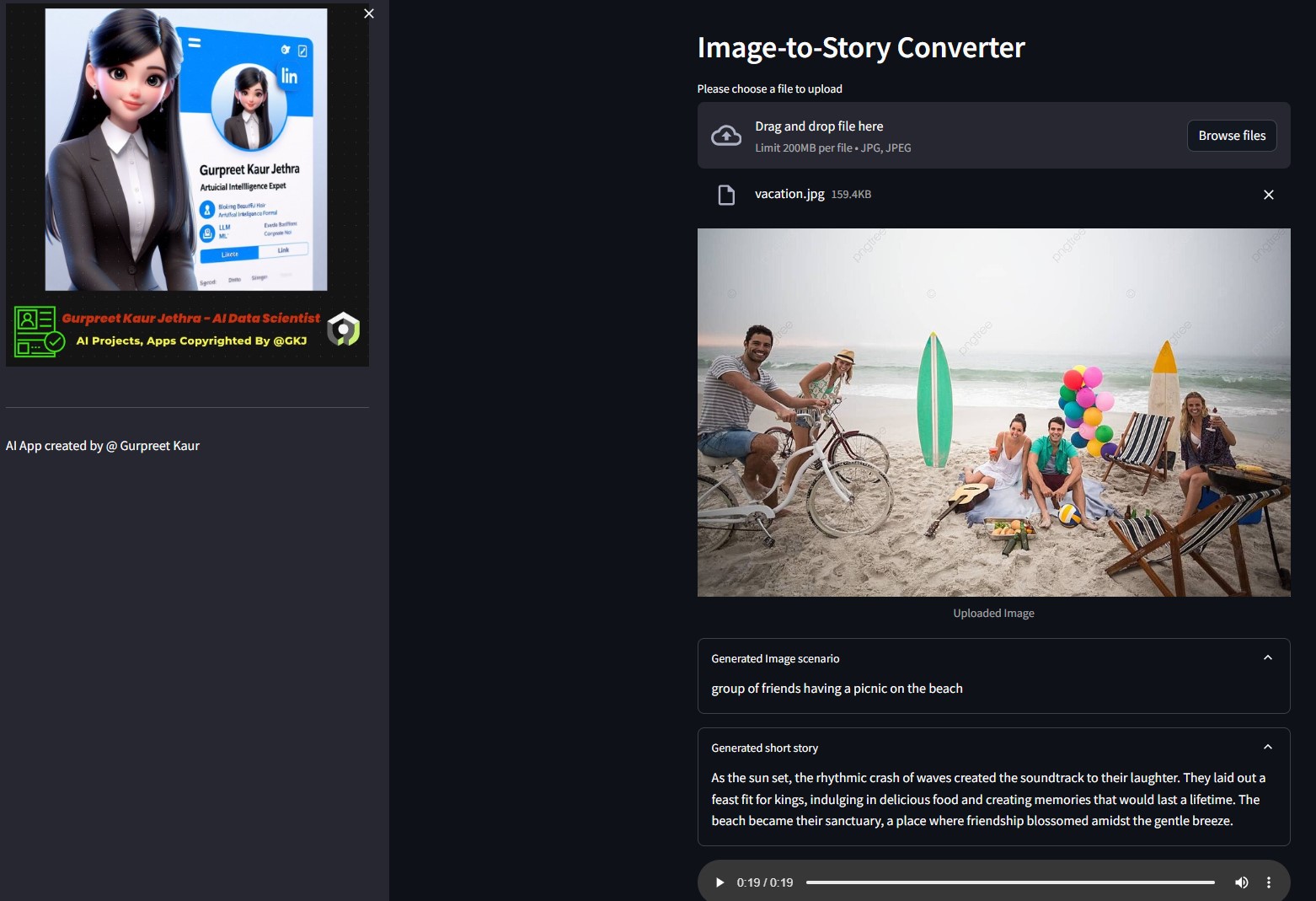
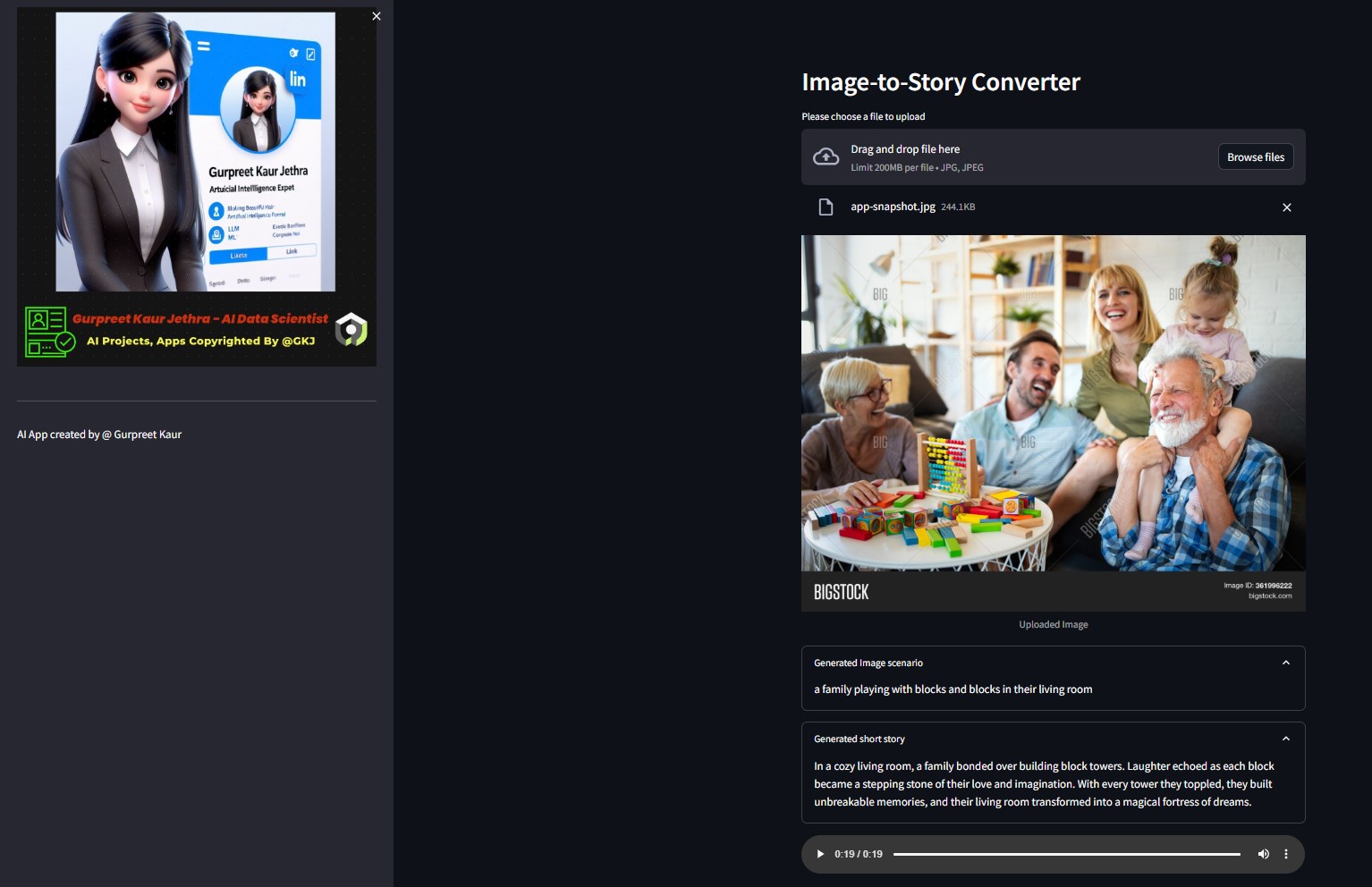 각
각 img-audio 폴더에서 이 테스트 이미지의 각 오디오 파일을 들을 수 있습니다.
?요구사항
- 운영 체제
- 파이썬-dotenv
- 변압기
- 토치
- 랭체인
- 열어라
- 요청
- 유선형
용법
- 앱을 사용하기 전에 사용자는 Hugging Face 및 Open AI에 대한 개인 토큰을 가지고 있어야 합니다.
- 사용자는 로컬 시스템 ide에서 앱을 실행하기 위해 venv 환경을 설정하고 ipykernel 라이브러리를 설치해야 합니다.
- 사용자는 패키지 내의 ".env" 파일에 개인 토큰을 개체 이름(HUGGINGFACE_TOKEN 및 OPENAI_TOKEN) 아래에 문자열 개체로 저장해야 합니다.
- 그런 다음 사용자는 streamlit run app.py 명령을 사용하여 앱을 실행할 수 있습니다.
- 앱이 Streamlit에서 실행되면 사용자는 대상 이미지를 업로드할 수 있습니다.
- 실행이 자동으로 시작되며 완료하는 데 몇 분 정도 걸릴 수 있습니다.
- 완료되면 앱에 다음이 표시됩니다.
- 이미지-텍스트 변환기 HuggingFace 모델에 의해 생성된 시나리오 텍스트
- OpenAI LLM을 통해 생성된 단편 소설
- 텍스트 음성 변환 모델로 생성된 단편 소설을 설명하는 오디오 파일
- 스트림라이트 클라우드 및 Hugging Space에 Gen AI 앱 배포
▶️ 설치
저장소를 복제합니다.
git clone https://github.com/GURPREETKAURJETHRA/Image-to-Speech-GenAI-Tool-Using-LLM.git
필수 Python 패키지를 설치합니다.
pip install -r requirements.txt
다음 내용으로 프로젝트의 루트 디렉터리에 .env 파일을 생성하여 OpenAI API 키 및 Hugging Face 토큰을 설정합니다.
OPENAI_API_KEY=<your-api-key-here> HUGGINGFACE_API_TOKEN=<<your-access-token-here>
Streamlit 앱을 실행합니다.
streamlit run app.py
©️ 라이센스
MIT 라이센스에 따라 배포됩니다. 자세한 내용은 LICENSE 참조하세요.
이 LLM 프로젝트가 마음에 든다면 이 저장소에 들러 기여를 환영합니다! 이 AI Img-Speech Converter 개선을 위한 제안 사항이 있으면 풀 요청을 제출해 주세요.
나를 따라와


