BinaryVectorDB
1.0.0
이 저장소에는 교육 목적으로 대규모 데이터 세트를 효율적으로 검색하기 위한 바이너리 벡터 데이터베이스가 포함되어 있습니다.
대부분의 임베딩 모델은 벡터를 float32로 표현합니다. 이는 많은 메모리를 소비하고 검색 속도가 매우 느립니다. Cohere에서는 저렴한 비용으로 뛰어난 검색 품질을 제공하는 기본 int8 및 바이너리 지원을 갖춘 최초의 임베딩 모델을 도입했습니다.
| 모델 | 검색 품질 MIRACL | 100만 개의 문서를 검색하는 데 소요되는 시간 | 필요한 메모리 2억 5천만 개 Wikipedia 임베딩 | AWS 가격(x2gb 인스턴스) |
|---|---|---|---|---|
| OpenAI 텍스트 임베딩-3-소형 | 44.9 | 680ms | 1431GB | $65,231 / 년 |
| OpenAI 텍스트 임베딩-3-대형 | 54.9 | 1240ms | 2861GB | $130,463 /년 |
| Cohere Embed v3(다국어) | ||||
| v3 삽입 - float32 | 66.3 | 460ms | 954GB | $43,488 /년 |
| v3 삽입 - 바이너리 | 62.8 | 24ms | 30GB | $1,359/년 |
| v3 삽입 - 바이너리 + int8 재점수 | 66.3 | 28ms | 30GB 메모리 + 240GB 디스크 | $1,589/년 |
월 $15의 비용으로 VM에 대해 1억 개의 Wikipedia Embedding을 검색할 수 있는 데모를 만들었습니다. 데모 - 단 $15/월에 1억 개의 Wikipedia Embedding을 검색하세요.
자신의 데이터에 BinaryVectorDB를 쉽게 사용할 수 있습니다.
설정은 쉽습니다:
pip install BinaryVectorDB
아래 예 중 일부를 사용하려면 cohere.com의 Cohere API 키 (무료 또는 유료)가 필요합니다. 이 API 키를 환경 변수로 설정해야 합니다. export COHERE_API_KEY=your_api_key
자신의 데이터에 벡터 DB를 구축하는 방법은 나중에 보여 드리겠습니다. 먼저 사전 구축된 바이너리 벡터 데이터베이스를 사용해 보겠습니다. 우리는 https://huggingface.co/datasets/Cohere/BinaryVectorDB에서 다양한 사전 구축 데이터베이스를 호스팅합니다. 이를 다운로드하여 로컬에서 사용할 수 있습니다.
시작하려면 Wikipedia의 간단한 영어 버전을 살펴보겠습니다.
wget https://huggingface.co/datasets/Cohere/BinaryVectorDB/resolve/main/wikipedia-2023-11-simple.zip
그런 다음 이 파일의 압축을 풉니다.
unzip wikipedia-2023-11-simple.zip
이전 단계에서 압축을 푼 폴더를 지정하여 데이터베이스를 쉽게 로드할 수 있습니다.
from BinaryVectorDB import BinaryVectorDB
# Point it to the unzipped folder from the previous step
# Ensure that you have set your Cohere API key via: export COHERE_API_KEY=<<YOUR_KEY>>
db = BinaryVectorDB ( "wikipedia-2023-11-simple/" )
query = "Who is the founder of Facebook"
print ( "Query:" , query )
hits = db . search ( query )
for hit in hits [ 0 : 3 ]:
print ( hit )데이터베이스에는 646,424개의 임베딩이 있고 총 크기는 962MB입니다. 그러나 바이너리 임베딩을 위한 80MB만 메모리에 로드됩니다. 문서와 해당 int8 임베딩은 디스크에 보관되며 필요할 때 로드됩니다.
메모리의 바이너리 임베딩과 디스크의 int8 임베딩 및 문서를 이렇게 분할하면 엄청난 양의 메모리가 필요 없이 매우 큰 데이터 세트로 확장할 수 있습니다.
자신만의 바이너리 벡터 데이터베이스를 구축하는 것은 매우 쉽습니다.
from BinaryVectorDB import BinaryVectorDB
import os
import gzip
import json
simplewiki_file = "simple-wikipedia-example.jsonl.gz"
#If file not exist, download
if not os . path . exists ( simplewiki_file ):
cmd = f"wget https://huggingface.co/datasets/Cohere/BinaryVectorDB/resolve/main/simple-wikipedia-example.jsonl.gz"
os . system ( cmd )
# Create the vector DB with an empty folder
# Ensure that you have set your Cohere API key via: export COHERE_API_KEY=<<YOUR_KEY>>
db_folder = "path_to_an_empty_folder/"
db = BinaryVectorDB ( db_folder )
if len ( db ) > 0 :
exit ( f"The database { db_folder } is not empty. Please provide an empty folder to create a new database." )
# Read all docs from the jsonl.gz file
docs = []
with gzip . open ( simplewiki_file ) as fIn :
for line in fIn :
docs . append ( json . loads ( line ))
#Limit it to 10k docs to make the next step a bit faster
docs = docs [ 0 : 10_000 ]
# Add all documents to the DB
# docs2text defines a function that maps our documents to a string
# This string is then embedded with the state-of-the-art Cohere embedding model
db . add_documents ( doc_ids = list ( range ( len ( docs ))), docs = docs , docs2text = lambda doc : doc [ 'title' ] + " " + doc [ 'text' ]) 문서는 Python 직렬화 가능 객체일 수 있습니다. 문서를 문자열에 매핑하는 docs2text 용 함수를 제공해야 합니다. 위의 예에서는 제목과 텍스트 필드를 연결합니다. 이 문자열은 임베딩 모델로 전송되어 필요한 텍스트 임베딩을 생성합니다.
문서 추가/삭제/업데이트가 쉽습니다. 데이터베이스에서 문서를 추가/업데이트/삭제하는 방법에 대한 예제 스크립트는 example/add_update_delete.py를 참조하세요.
우리는 필요한 메모리를 4배 및 32배 감소시키는 Cohere int8 및 바이너리 임베딩 임베딩을 발표했습니다. 또한 벡터 검색 속도가 최대 40배 향상됩니다.
두 기술 모두 BinaryVectorDB에 결합되어 있습니다. 예를 들어, 42M 임베딩이 있는 영어 Wikipedia를 가정해 보겠습니다. 일반적인 float32 임베딩에는 임베딩을 호스팅하기 위해 42*10^6*1024*4 = 160 GB 의 메모리가 필요합니다. float32에 대한 검색은 다소 느리기 때문에(42M 임베딩에서 약 45초) HNSW와 같은 인덱스를 추가하여 20GB의 메모리를 추가해야 하므로 총 180GB가 필요합니다.
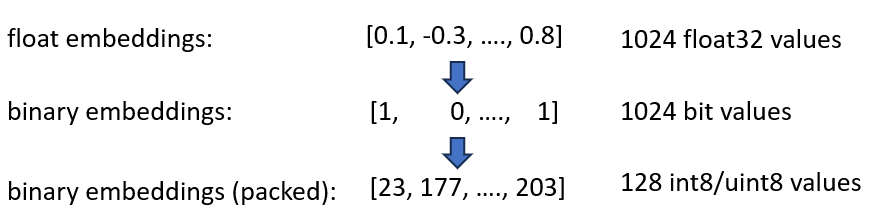
바이너리 임베딩은 모든 차원을 1비트로 나타냅니다. 이렇게 하면 필요한 메모리가 160 GB / 32 = 5GB 로 줄어듭니다. 또한 이진 공간 검색이 40배 더 빠르므로 많은 경우 HNSW 인덱스가 더 이상 필요하지 않습니다. 필요한 메모리를 180GB에서 5GB로 줄여 36배 절약했습니다.
이 인덱스를 쿼리할 때 쿼리도 바이너리로 인코딩하고 해밍 거리를 사용합니다. 해밍 거리는 두 벡터 간의 1비트 차이를 측정합니다. 이는 매우 빠른 작업입니다. 두 개의 이진 벡터를 비교하려면 2-CPU 주기만 필요합니다: popcount(xor(vector1, vector2)) . XOR은 CPU에서 가장 기본적인 연산이므로 매우 빠르게 실행됩니다. popcount 레지스터에서 1의 수를 계산하며, 여기에도 1개의 CPU 사이클만 필요합니다.
전반적으로 이는 검색 품질의 약 90%를 유지하는 솔루션을 제공합니다.
<float, binary> 재채점을 통해 이전 단계의 검색 품질을 90%에서 95%로 높일 수 있습니다.
예를 들어 1단계에서 상위 100개 결과를 가져와 dot_product(query_float_embedding, 2*binary_doc_embedding-1) 계산합니다.
쿼리 임베딩이 [0.1, -0.3, 0.4] 이고 이진 문서 임베딩이 [1, 0, 1] 이라고 가정합니다. 그런 다음 이 단계에서는 다음을 계산합니다.
(0.1)*(1) + (-0.3)*(-1) + 0.4*(1) = 0.1 + 0.3 + 0.4 = 0.8

우리는 이 점수를 사용하여 결과를 다시 채점합니다. 이로 인해 검색 품질이 90%에서 95%로 향상됩니다. 이 작업은 매우 빠르게 수행할 수 있습니다. 임베딩 모델에서 쿼리 부동 임베딩을 가져오고 이진 임베딩은 메모리에 있으므로 합계 연산을 100회만 수행하면 됩니다.
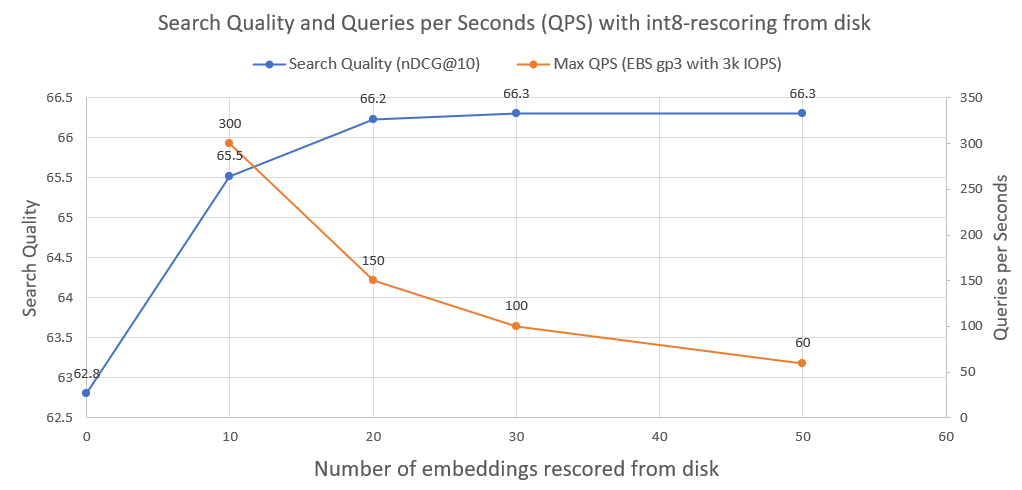
검색 품질을 95%에서 99.99%로 더욱 향상시키기 위해 디스크에서 int8 rescoring을 사용합니다.
모든 int8 문서 임베딩을 디스크에 저장합니다. 그런 다음 위 단계에서 상위 30개를 가져와 디스크에서 int8-embeddings를 로드하고 cossim(query_float_embedding, int8_doc_embedding_from_disk) 계산합니다.
다음 이미지에서는 int8-rescoring의 정도를 확인하고 검색 성능을 향상시킬 수 있습니다.
또한 이러한 시스템이 3000 IOPS의 일반 AWS EBS 네트워크 드라이브에서 실행될 때 달성할 수 있는 초당 쿼리 수를 표시했습니다. 보시다시피 디스크에서 로드해야 하는 int8 임베딩이 많을수록 QPS는 줄어듭니다.
이진 검색을 수행하기 위해 faiss의 IndexBinaryFlat 인덱스를 사용합니다. 바이너리 임베딩만 저장하고 초고속 인덱싱과 초고속 검색이 가능합니다.
문서와 int8 임베딩을 저장하기 위해 RocksDB를 기반으로 하는 Python용 온디스크 키-값 저장소인 RocksDict를 사용합니다.
클래스의 전체 구현은 BinaryVectorDB를 참조하세요.
설마. 저장소는 주로 대규모 데이터 세트로 확장하는 방법을 보여주는 교육 목적으로 사용됩니다. 사용 편의성에 더 중점을 두었고 다중 프로세스 안전, 롤백 등과 같은 구현에서 일부 중요한 측면이 누락되었습니다.
실제로 생산에 들어가고 싶다면 유사한 결과를 얻을 수 있는 Vespa.ai와 같은 적절한 벡터 데이터베이스를 사용하십시오.
Cohere에서는 고객이 적은 비용으로 수백억 개의 임베딩에 대해 의미 체계 검색을 실행할 수 있도록 도왔습니다. 확장 가능한 솔루션이 필요한 경우 언제든지 Nils Reimers에 문의하세요.


