VideoX
1.0.0
당사의 영상이해 작업물 모음입니다.
SeqTrack (
@CVPR'23): SeqTrack: 시각적 객체 추적을 위한 시퀀스 학습
X-CLIP (
@ECCV'22 Oral): 일반 비디오 인식을 위한 언어-이미지 사전 학습 모델 확장
MS-2D-TAN (
@TPAMI'21): 자연 언어를 사용한 순간 위치 파악을 위한 다중 규모 2D 시간 인접 네트워크
2D-TAN (
@AAAI'20): 자연 언어를 사용한 순간 위치 파악을 위한 2D 시간 인접 네트워크 학습
강력한 코딩 능력을 갖춘 연구인턴 채용: [email protected] | [email protected]
2023년 4월: SeqTrack 용 코드가 출시되었습니다.
2023년 2월: SeqTrack이 CVPR'23에 승인되었습니다.
2022년 9월: X-CLIP 이 이제
2022년 8월: X-CLIP 용 코드가 출시되었습니다.
2022년 7월: X-CLIP이 ECCV'22에 Oral로 승인되었습니다.
2021년 10월: MS-2D-TAN 용 코드가 출시되었습니다.
2021년 9월: MS-2D-TAN이 TPAMI'21에 승인되었습니다.
2019년 12월: 2D-TAN 용 코드가 출시되었습니다.
2019년 11월: 2D-TAN이 AAAI'20에 승인되었습니다.
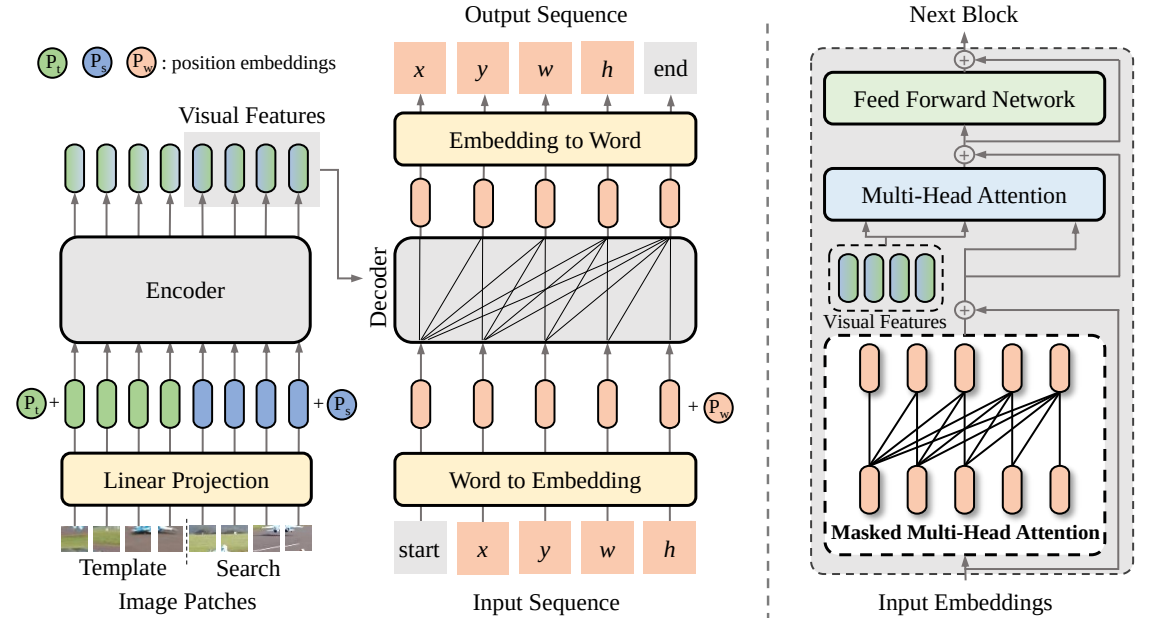
본 논문에서는 SeqTrack이라는 시각적 추적을 위한 새로운 시퀀스 간 학습 프레임워크를 제안합니다. 자동 회귀 방식으로 객체 경계 상자를 예측하는 시퀀스 생성 문제로 시각적 추적을 캐스팅합니다. SeqTrack은 단순한 인코더-디코더 변환기 아키텍처만 채택합니다. 인코더는 양방향 변환기를 사용하여 시각적 특징을 추출하는 반면, 디코더는 인과 디코더를 사용하여 자동 회귀 방식으로 일련의 경계 상자 값을 생성합니다. 손실 함수는 단순한 교차 엔트로피입니다. 이러한 시퀀스 학습 패러다임은 추적 프레임워크를 단순화할 뿐만 아니라 많은 벤치마크에서 경쟁력 있는 성능을 달성합니다.
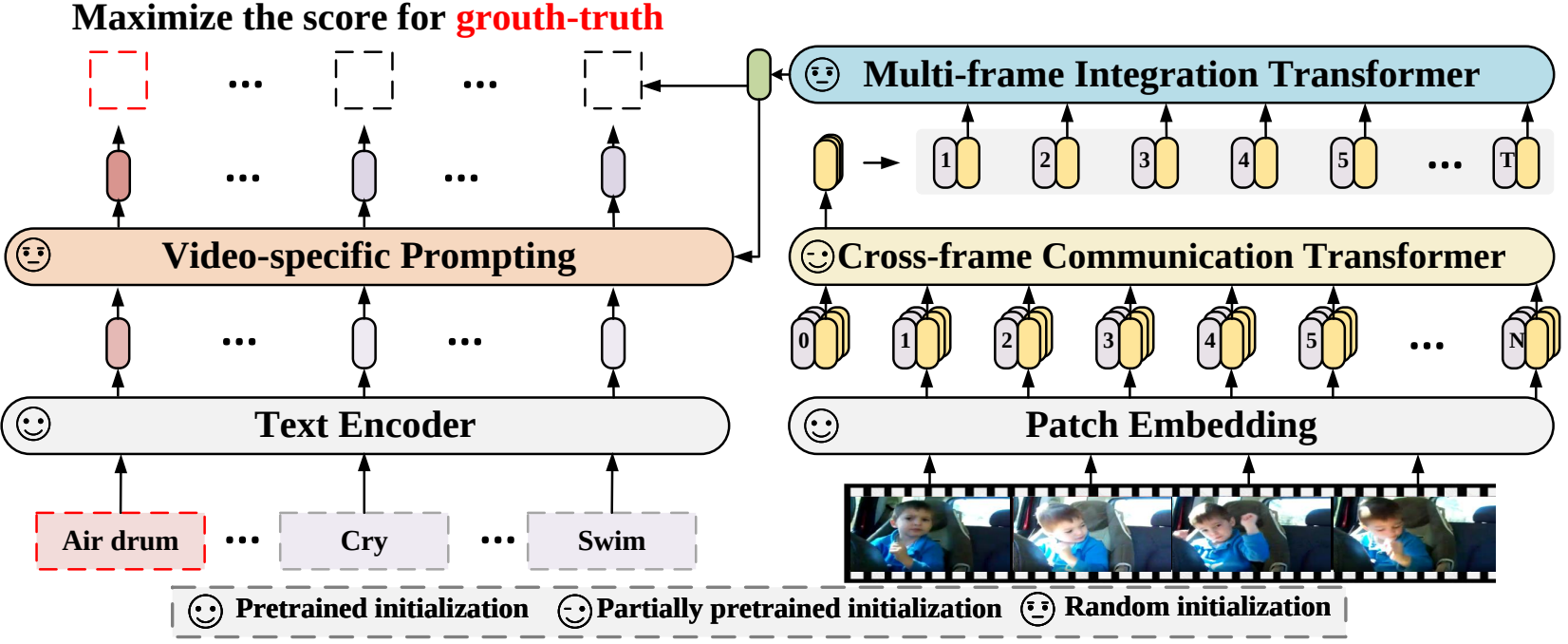
본 논문에서는 사전 학습된 언어-이미지 모델을 영상 인식에 적용하는 새로운 영상 인식 프레임워크를 제안합니다. 특히 시간 정보를 캡처하기 위해 프레임 간에 정보를 명시적으로 교환하는 프레임 간 주의 메커니즘을 제안합니다. 비디오 카테고리의 텍스트 정보를 활용하기 위해 인스턴스 수준의 차별적인 텍스트 표현을 생성할 수 있는 비디오별 프롬프트 기법을 설계합니다. 광범위한 실험을 통해 우리의 접근 방식이 효과적이며 완전 감독, 퓨샷 및 제로샷을 포함한 다양한 비디오 인식 시나리오에 일반화될 수 있음이 입증되었습니다.
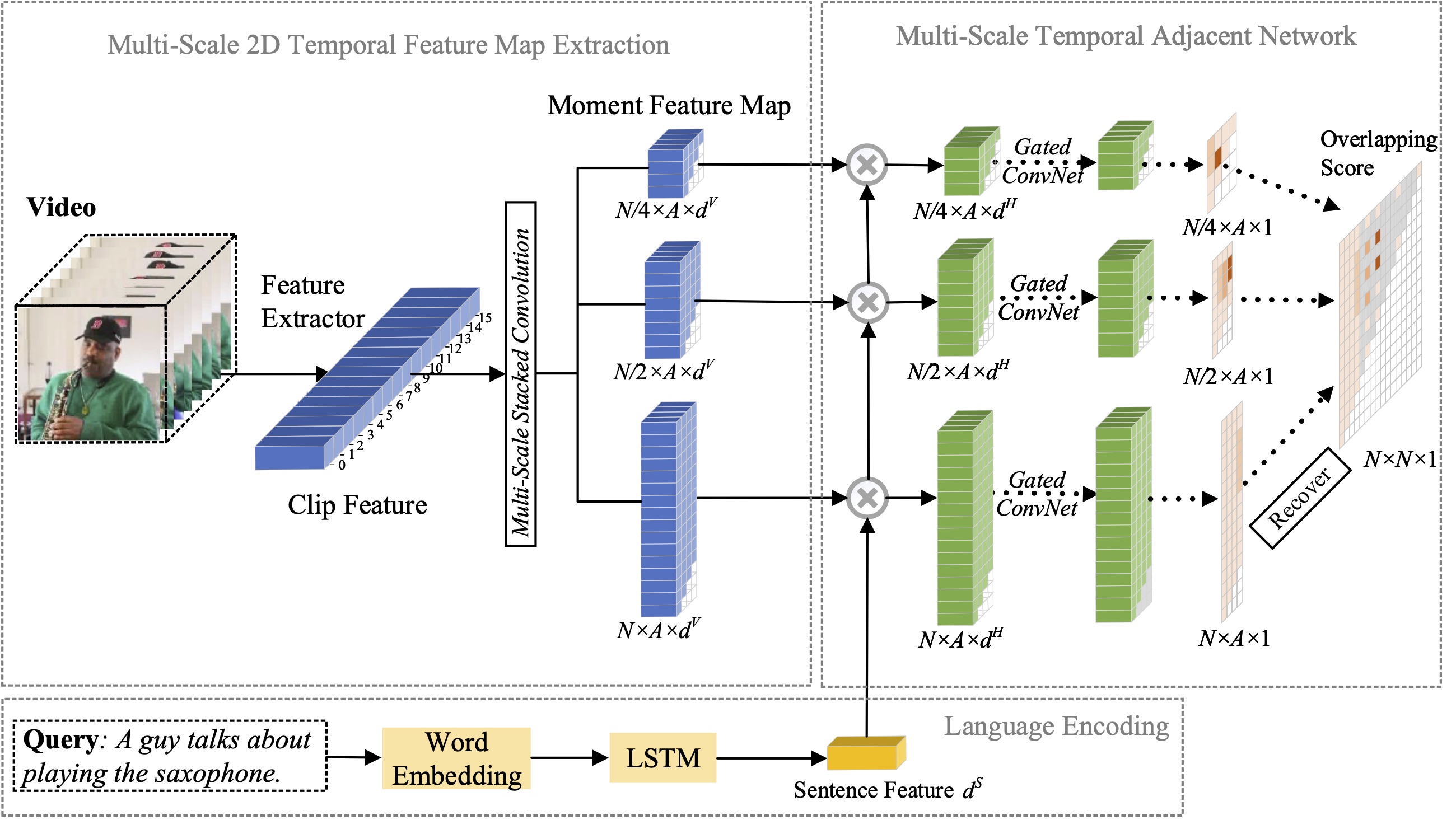
본 논문에서는 자연어를 이용한 순간 위치 파악 문제를 연구하고, 이전에 제안한 2D-TAN 방법을 다중 규모 버전으로 확장하는 방법을 제안합니다. 핵심 아이디어는 인접한 순간 후보를 시간적 맥락으로 간주하는 다양한 시간 규모의 2차원 시간 맵에서 순간을 검색하는 것입니다. 확장 버전은 서로 다른 규모로 인접한 시간적 관계를 인코딩하는 동시에 비디오 순간을 참조 표현과 일치시키는 식별 기능을 학습할 수 있습니다. 우리 모델은 설계가 간단하고 세 가지 벤치마크 데이터 세트에 대한 최첨단 방법과 비교하여 경쟁력 있는 성능을 달성합니다.
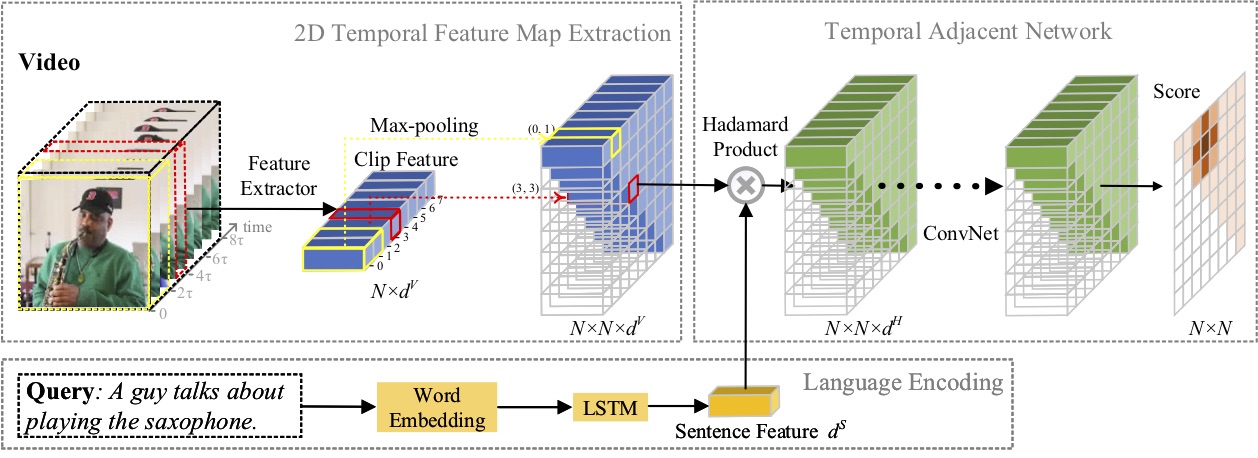
본 논문에서는 자연어를 이용한 순간 위치 파악 문제를 연구하고, 새로운 2D Temporal Adjacent Networks(2D-TAN) 방법을 제안합니다. 핵심 아이디어는 인접한 순간 후보를 시간적 맥락으로 간주하는 2차원 시간 지도에서 순간을 검색하는 것입니다. 2D-TAN은 인접한 시간 관계를 인코딩하는 동시에 비디오 순간을 참조 표현과 일치시키는 식별 기능을 학습할 수 있습니다. 우리 모델은 설계가 간단하고 세 가지 벤치마크 데이터 세트에 대한 최첨단 방법과 비교하여 경쟁력 있는 성능을 달성합니다.
@InProceedings{SeqTrack, title={SeqTrack: 시각적 객체 추적을 위한 시퀀스 학습 시퀀스}, 저자={Chen, Xin and Peng, Houwen and Wang, Dong and Lu, Huchuan and Hu, Han}, booktitle={CVPR}, year={2023}}@InProceedings{XCLIP, title={일반 영상 인식을 위한 언어-이미지 사전 학습 모델 확장}, 저자={Ni, Bolin 및 Peng, Houwen 및 Chen, Minghao 및 Zhang, Songyang 및 Meng, Gaofeng 및 Fu, Jianlong 및 Xiang, Shiming 및 Ling, Haibin}, booktitle={ECCV(European Conference on Computer Vision)}, 연도 ={2022}}@InProceedings{Zhang2021MS2DTAN,
저자 = {Zhang, Songyang 및 Peng, Houwen 및 Fu, Jianlong 및 Lu, Yijuan 및 Luo, Jiebo},
title = {자연어를 이용한 순간 위치 파악을 위한 다중 규모 2D 시간적 인접 네트워크},
책제목 = {TPAMI},
연도 = {2021}}@InProceedings{2DTAN_2020_AAAI,
저자 = {Zhang, Songyang 및 Peng, Houwen 및 Fu, Jianlong 및 Luo, Jiebo},
title = {자연어를 이용한 순간 위치 파악을 위한 2D 시간적 인접 네트워크 학습},
책제목 = {AAAI},
연도 = {2020}}MIT 라이선스에 따른 라이선스입니다.


