horovod
v0.28.1: Build fixes (ROCm, GCC 12)
Horovod는 TensorFlow, Keras, PyTorch 및 Apache MXNet을 위한 분산형 딥 러닝 교육 프레임워크입니다. Horovod의 목표는 분산 딥 러닝을 빠르고 쉽게 사용하도록 만드는 것입니다.
Horovod는 LF AI & Data Foundation(LF AI & Data)에서 호스팅합니다. 인공지능, 머신러닝, 딥러닝 분야에서 오픈소스 기술을 활용하는 데 전념하고 있으며 이러한 도메인의 오픈소스 프로젝트 커뮤니티를 지원하고 싶다면 LF AI & Data Foundation 가입을 고려해 보세요. 누가 참여하고 Horovod가 어떤 역할을 하는지에 대한 자세한 내용은 Linux Foundation 발표를 읽어보세요.
내용물
이 프로젝트의 주된 동기는 단일 GPU 훈련 스크립트를 쉽게 취하고 성공적으로 확장하여 여러 GPU에 걸쳐 병렬로 훈련할 수 있도록 하는 것입니다. 여기에는 두 가지 측면이 있습니다.
Uber 내부적으로 우리는 MPI 모델이 매개변수 서버를 갖춘 Distributed TensorFlow와 같은 이전 솔루션보다 훨씬 더 간단하고 코드 변경이 훨씬 적다는 것을 발견했습니다. Horovod를 사용하여 확장할 수 있도록 교육 스크립트를 작성하면 추가 코드 변경 없이 단일 GPU, 다중 GPU 또는 다중 호스트에서 실행할 수 있습니다. 자세한 내용은 사용법 섹션을 참조하세요.
Horovod는 사용하기 쉬울 뿐만 아니라 빠릅니다. 다음은 각각 RoCE 지원 25Gbit/s 네트워크로 연결된 4개의 Pascal GPU가 있는 128개의 서버에서 수행된 벤치마크를 나타내는 차트입니다.
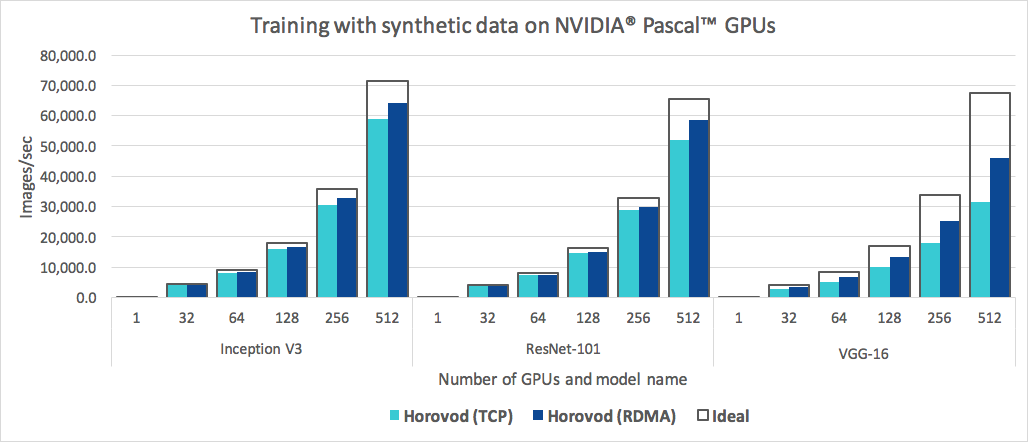
Horovod는 Inception V3 및 ResNet-101 모두에 대해 90%의 확장 효율성을 달성하고 VGG-16에 대해 68%의 확장 효율성을 달성합니다. 이러한 수치를 재현하는 방법을 알아보려면 벤치마크를 참조하세요.
MPI 및 NCCL 설치 자체가 번거로워 보일 수 있지만 인프라를 다루는 팀에서 한 번만 수행하면 되며 모델을 구축하는 회사의 다른 모든 사람은 대규모 교육의 단순성을 누릴 수 있습니다.
Linux 또는 macOS에 Horovod를 설치하려면:
PyPI에서 TensorFlow를 설치한 경우 g++-5 이상이 설치되어 있는지 확인하세요. TensorFlow 2.10부터는 g++8 이상과 같은 C++17 호환 컴파일러가 필요합니다.
PyPI에서 PyTorch를 설치한 경우 g++-5 이상이 설치되어 있는지 확인하세요.
Conda에서 두 패키지 중 하나를 설치한 경우 gxx_linux-64 Conda 패키지가 설치되어 있는지 확인하세요.
horovod pip 패키지를 설치합니다.
CPU에서 실행하려면:
$ pip install horovodNCCL이 포함된 GPU에서 실행하려면:
$ HOROVOD_GPU_OPERATIONS=NCCL pip install horovodGPU 지원이 포함된 Horovod 설치에 대한 자세한 내용은 GPU의 Horovod를 읽어보세요.
Horovod 설치 옵션의 전체 목록을 보려면 설치 가이드를 읽어보세요.
MPI를 사용하려면 MPI가 포함된 Horovod를 읽어보세요.
Conda를 사용하려면 Horovod에 대한 GPU 지원을 사용하여 Conda 환경 구축을 읽어보세요.
Docker를 사용하려면 Docker의 Horovod를 읽어보세요.
소스에서 Horovod를 컴파일하려면 기여자 가이드의 지침을 따르세요.
Horovod 핵심 원칙은 크기 , 순위 , 로컬 순위 , allreduce , allgather , 방송 및 alltoall 과 같은 MPI 개념을 기반으로 합니다. 자세한 내용은 이 페이지를 참조하세요.
Horovod 예시 및 모범 사례는 다음 페이지를 참조하세요.
Horovod를 사용하려면 프로그램에 다음을 추가하세요.
hvd.init() 실행하여 Horovod를 초기화합니다.리소스 경합을 방지하려면 각 GPU를 단일 프로세스에 고정하세요.
프로세스당 하나의 GPU로 구성된 일반적인 설정을 사용하여 이를 local Rank 로 설정합니다. 서버의 첫 번째 프로세스에는 첫 번째 GPU가 할당되고, 두 번째 프로세스에는 두 번째 GPU가 할당되는 식입니다.
워커 수에 따라 학습률을 조정합니다.
동기식 분산 훈련의 효과적인 배치 크기는 작업자 수에 따라 조정됩니다. 학습률의 증가는 증가된 배치 크기를 보상합니다.
최적화 프로그램을 hvd.DistributedOptimizer 로 래핑합니다.
분산 최적화 프로그램은 기울기 계산을 원래 최적화 프로그램에 위임하고 allreduce 또는 allgather를 사용하여 기울기의 평균을 낸 다음 평균된 기울기를 적용합니다.
초기 변수 상태를 순위 0부터 다른 모든 프로세스로 브로드캐스트합니다.
이는 훈련이 무작위 가중치로 시작되거나 체크포인트에서 복원될 때 모든 작업자의 일관된 초기화를 보장하는 데 필요합니다.
TensorFlow v1을 사용한 예(전체 학습 예는 예제 디렉토리 참조):
import tensorflow as tf
import horovod . tensorflow as hvd
# Initialize Horovod
hvd . init ()
# Pin GPU to be used to process local rank (one GPU per process)
config = tf . ConfigProto ()
config . gpu_options . visible_device_list = str ( hvd . local_rank ())
# Build model...
loss = ...
opt = tf . train . AdagradOptimizer ( 0.01 * hvd . size ())
# Add Horovod Distributed Optimizer
opt = hvd . DistributedOptimizer ( opt )
# Add hook to broadcast variables from rank 0 to all other processes during
# initialization.
hooks = [ hvd . BroadcastGlobalVariablesHook ( 0 )]
# Make training operation
train_op = opt . minimize ( loss )
# Save checkpoints only on worker 0 to prevent other workers from corrupting them.
checkpoint_dir = '/tmp/train_logs' if hvd . rank () == 0 else None
# The MonitoredTrainingSession takes care of session initialization,
# restoring from a checkpoint, saving to a checkpoint, and closing when done
# or an error occurs.
with tf . train . MonitoredTrainingSession ( checkpoint_dir = checkpoint_dir ,
config = config ,
hooks = hooks ) as mon_sess :
while not mon_sess . should_stop ():
# Perform synchronous training.
mon_sess . run ( train_op )아래 예제 명령은 분산 훈련을 실행하는 방법을 보여줍니다. RoCE/InfiniBand 조정 및 중단 처리 팁을 포함한 자세한 내용은 Run Horovod를 참조하세요.
4개의 GPU가 있는 머신에서 실행하려면:
$ horovodrun -np 4 -H localhost:4 python train.py각각 4개의 GPU가 있는 4대의 머신에서 실행하려면:
$ horovodrun -np 16 -H server1:4,server2:4,server3:4,server4:4 python train.py horovodrun 래퍼 없이 Open MPI를 사용하여 실행하려면 Open MPI를 사용하여 Horovod 실행을 참조하세요.
Docker에서 실행하려면 Docker의 Horovod를 참조하세요.
Kubernetes에서 실행하려면 Helm Chart, Kubeflow MPI Operator, FfDL 및 Polyaxon을 참조하세요.
Spark에서 실행하려면 Spark의 Horovod를 참조하세요.
Ray에서 실행하려면 Ray의 Horovod를 참조하세요.
Singularity에서 실행하려면 Singularity를 참조하세요.
LSF HPC 클러스터(예: Summit)에서 실행하려면 LSF를 참조하세요.
Hadoop Yarn에서 실행하려면 TonY를 참조하세요.
Gloo는 Facebook이 개발한 오픈소스 집단 커뮤니케이션 라이브러리입니다.
Gloo는 Horovod에 포함되어 있으며 사용자가 MPI를 설치하지 않고도 Horovod를 실행할 수 있습니다.
MPI와 Gloo를 모두 지원하는 환경의 경우 --gloo 인수를 horovodrun 에 전달하여 런타임에 Gloo를 사용하도록 선택할 수 있습니다.
$ horovodrun --gloo -np 2 python train.pyHorovod는 MPI가 멀티 스레딩 지원으로 구축된 경우 Horovod Collective를 mpi4py와 같은 다른 MPI 라이브러리와 혼합 및 일치시키는 것을 지원합니다.
hvd.mpi_threads_supported() 함수를 쿼리하여 MPI 멀티스레딩 지원을 확인할 수 있습니다.
import horovod . tensorflow as hvd
# Initialize Horovod
hvd . init ()
# Verify that MPI multi-threading is supported.
assert hvd . mpi_threads_supported ()
from mpi4py import MPI
assert hvd . size () == MPI . COMM_WORLD . Get_size ()mpi4py 하위 커뮤니케이터를 사용하여 Horovod를 초기화할 수도 있습니다. 이 경우 각 하위 커뮤니케이터는 독립적인 Horovod 교육을 실행합니다.
from mpi4py import MPI
import horovod . tensorflow as hvd
# Split COMM_WORLD into subcommunicators
subcomm = MPI . COMM_WORLD . Split ( color = MPI . COMM_WORLD . rank % 2 ,
key = MPI . COMM_WORLD . rank )
# Initialize Horovod
hvd . init ( comm = subcomm )
print ( 'COMM_WORLD rank: %d, Horovod rank: %d' % ( MPI . COMM_WORLD . rank , hvd . rank ()))여기에서 추론을 위해 모델을 최적화하고 그래프에서 Horovod 작업을 제거하는 방법을 알아보세요.
Horovod의 독특한 점 중 하나는 소규모 전체 축소 작업을 일괄 처리하는 기능과 함께 통신 및 계산을 인터리브하는 기능으로, 이로 인해 성능이 향상됩니다. 우리는 이 일괄 처리 기능을 Tensor Fusion이라고 부릅니다.
자세한 내용과 조정 지침은 여기를 참조하세요.
Horovod에는 Horovod Timeline이라는 활동 타임라인을 기록하는 기능이 있습니다.
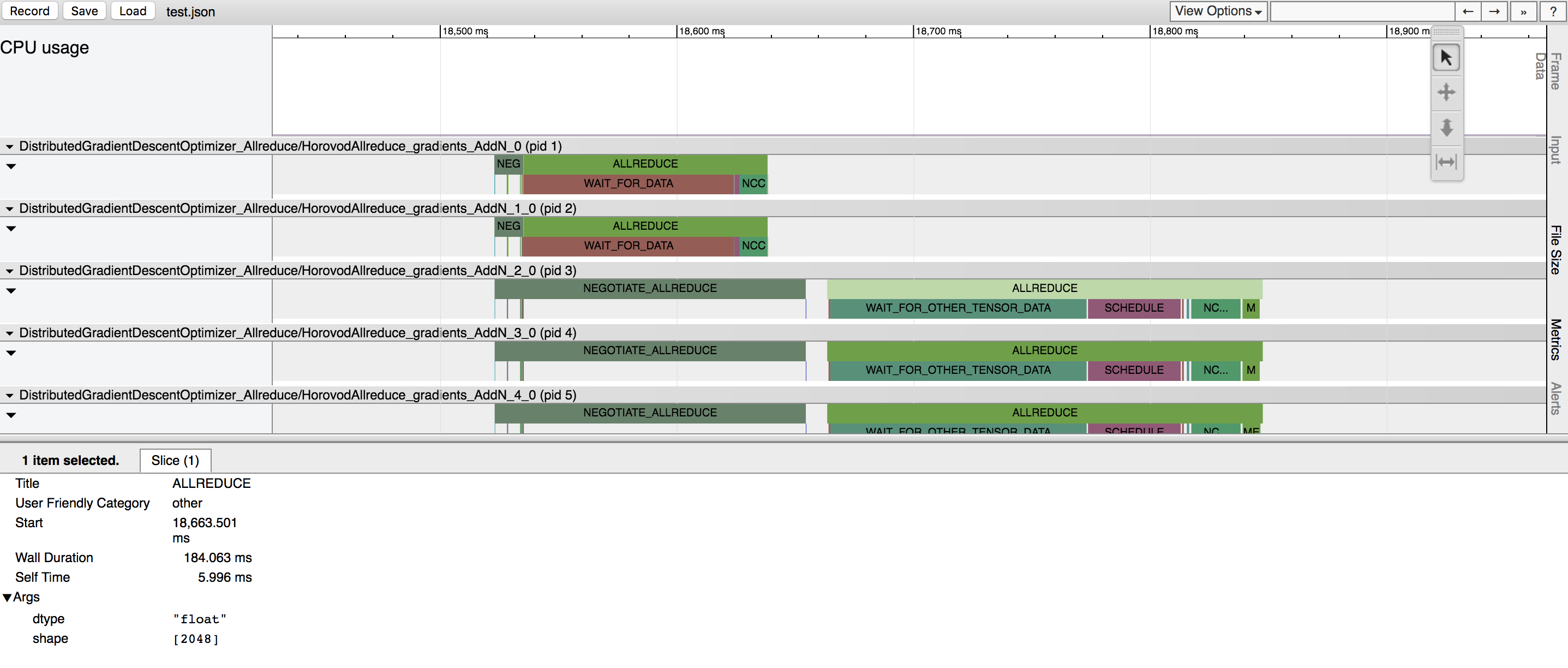
Horovod 타임라인을 사용하여 Horovod 성능을 분석하세요. 자세한 내용과 사용 지침은 여기를 참조하세요.
Tensor Fusion 및 기타 고급 Horovod 기능을 효율적으로 사용하기 위해 올바른 값을 선택하려면 상당한 시행착오가 필요할 수 있습니다. 우리는 자동 튜닝(autotuning) 이라는 성능 최적화 프로세스를 자동화하는 시스템을 제공합니다. 이는 horovodrun 에 대한 단일 명령줄 인수를 사용하여 활성화할 수 있습니다.
자세한 내용과 사용 지침은 여기를 참조하세요.
Horovod를 사용하면 하나의 분산 교육에 참여하는 다양한 프로세스 그룹에서 고유한 집단 작업을 동시에 실행할 수 있습니다. 이 기능을 활용하려면 hvd.process_set 객체를 설정하세요.
자세한 지침은 프로세스 세트를 참조하세요.
이 사이트에 게시하고 싶은 사용자 가이드의 링크를 보내주세요.
답변을 찾을 수 없으면 문제 해결을 참조하고 티켓을 제출하세요.
귀하의 연구에 도움이 된다면 출판물에 Horovod를 인용해 주십시오:
@article{sergeev2018horovod,
저자 = {Alexander Sergeev 및 Mike Del Balso},
저널 = {arXiv preprint arXiv:1802.05799},
제목 = {Horovod: {TensorFlow}의 빠르고 쉬운 분산 딥 러닝},
연도 = {2018}
}
1. Sergeev, A., Del Balso, M.(2017) Horovod를 만나보세요: TensorFlow용 Uber의 오픈 소스 분산 딥 러닝 프레임워크 . https://eng.uber.com/horovod/에서 검색함
2. Sergeev, A. (2017) Horovod - 간편한 분산 TensorFlow . https://www.slideshare.net/AlexanderSergeev4/horovod-distributed-tensorflow-made-easy에서 검색함
3. Sergeev, A., Del Balso, M. (2018) Horovod: TensorFlow의 빠르고 쉬운 분산 딥 러닝 . arXiv:1802.05799에서 검색됨
Horovod 소스 코드는 Andrew Gibiansky와 Joel Hestness가 작성한 Baidu tensorflow-allreduce 저장소를 기반으로 했습니다. 이들의 원본 작업은 HPC 기술을 딥 러닝에 적용이라는 기사에 설명되어 있습니다.


