INTR
1.0.0
이 저장소는 INTR: 세분화된 이미지 분류 및 분석을 위한 단순 해석 가능한 변환기의 공식 구현입니다. 현재 여기에는 세분화된 데이터 해석을 위한 코드와 모델이 포함되어 있습니다. 이 논문이 온라인으로 공개되면 다가오는 ICLR 2024 절차에 대한 링크를 제공할 것입니다.
INTR은 이미지 분류를 해석 가능하게 만드는 Transformer의 새로운 사용법입니다. INTR에서는 분류에 대한 사전 예방적 접근 방식을 조사하여 각 클래스가 이미지에서 자신을 찾도록 요청합니다. 우리는 디코더에 대한 입력으로 클래스별 쿼리(각 클래스당 하나)를 학습하여 교차 주의를 통해 이미지에서 자신의 존재를 찾을 수 있도록 합니다. 우리는 INTR이 각 수업이 뚜렷하게 참석하도록 본질적으로 장려한다는 것을 보여줍니다. 따라서 교차 주의 가중치는 모델 예측에 대한 의미 있는 해석을 제공합니다. 흥미롭게도 INTR은 다중 헤드 교차 주의를 통해 클래스의 다양한 속성을 지역화하는 방법을 학습할 수 있어 특히 세부적인 분류 및 분석에 적합합니다.
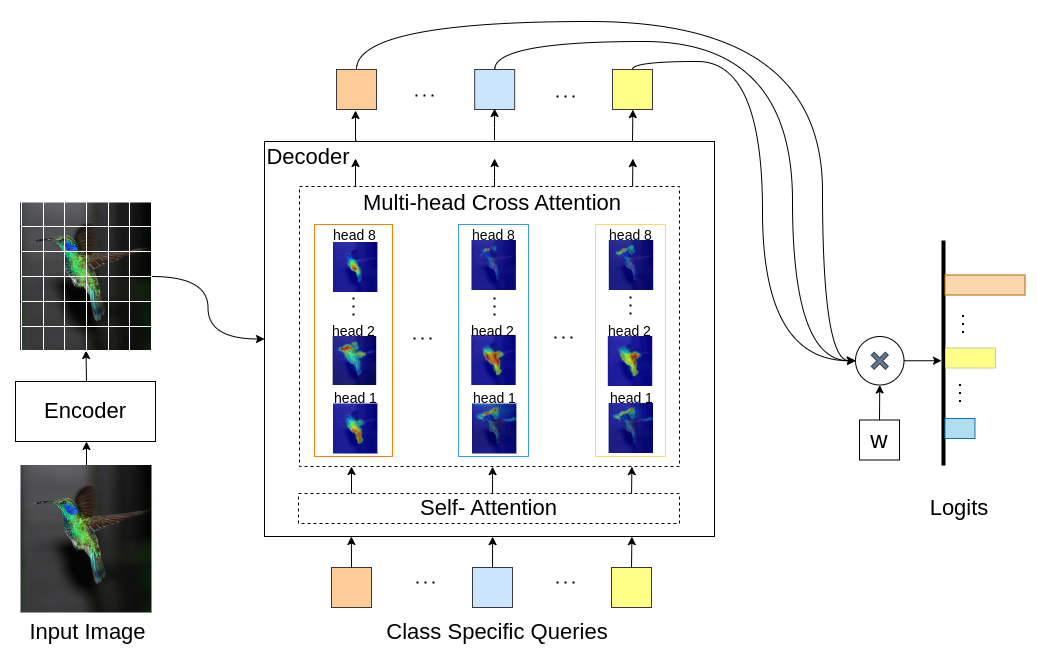
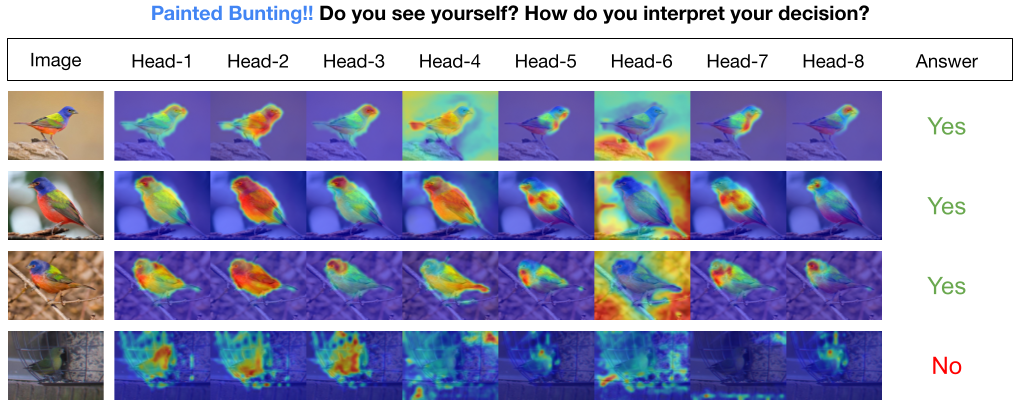
INTR 모델에서 디코더의 각 쿼리는 클래스 예측을 담당합니다. 따라서 쿼리는 기능 맵에서 클래스별 기능을 찾기 위해 자체를 살펴봅니다. 먼저, 이미지에서 객체의 중요한 부분을 보기 위해 변환기 아키텍처의 값 매트릭스인 특징 맵을 시각화합니다. 모델이 값 매트릭스에서 주의를 기울이는 특정 기능을 찾기 위해 모델 주의 히트맵을 표시합니다. 분류에서 외부 간섭을 피하기 위해 분류에 공유 가중치 벡터를 사용하므로 주의 가중치가 모델의 예측을 설명합니다.
DETR-R50 백본의 INTR, 분류 성능 및 다양한 데이터 세트에 대한 미세 조정 모델.
| 데이터세트 | acc@1 | acc@5 | 모델 |
|---|---|---|---|
| 견습생 | 71.8 | 89.3 | 체크포인트 다운로드 |
| 새 | 97.4 | 99.2 | 체크포인트 다운로드 |
| 나비 | 95.0 | 98.3 | 체크포인트 다운로드 |
Python 환경 만들기(선택 사항)
conda create -n intr python=3.8 -y
conda activate intr저장소 복제
git clone https://github.com/dipanjyoti/INTR.git
cd INTRPython 종속성 설치
pip install -r requirements.txt데이터는 아래 형식을 따르세요.
datasets
├── dataset_name
│ ├── train
│ │ ├── class1
│ │ │ ├── img1.jpeg
│ │ │ ├── img2.jpeg
│ │ │ └── ...
│ │ ├── class2
│ │ │ ├── img3.jpeg
│ │ │ └── ...
│ │ └── ...
│ └── val
│ ├── class1
│ │ ├── img4.jpeg
│ │ ├── img5.jpeg
│ │ └── ...
│ ├── class2
│ │ ├── img6.jpeg
│ │ └── ...
│ └── ...
다중 GPU(예: GPU 4개) 설정에서 CUB 데이터세트에 대한 INTR의 성능을 평가하려면 아래 명령을 실행합니다. INTR 체크포인트는 모델 및 결과 미세 조정에서 사용할 수 있습니다.
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 --master_port 12345 --use_env main.py --eval --resume < path/to/intr_checkpoint_cub_detr_r50.pth > --dataset_path < path/to/datasets > --dataset_name < dataset_name > INTR 해석의 시각적 표현을 생성하려면 아래 제공된 명령을 실행하십시오. 이 명령은 <class_number> 인덱스를 사용하여 특정 클래스에 대한 해석을 표시합니다. 기본적으로 모든 주의 헤드의 해석이 표시됩니다. top_q로 라벨이 지정된 상위 쿼리와 관련된 해석에 집중하려면 sim_query_heads 매개변수를 1로 설정합니다. 시각화에는 배치 크기 1을 사용합니다.
python -m tools.visualization --eval --resume < path/to/intr_checkpoint_cub_detr_r50.pth > --dataset_path < path/to/datasets > --dataset_name < dataset_name > --class_index < class_number >추론 시간 단일 이미지 예측 및 시각화: 추론 프로세스 중 단일 이미지 예측 및 시각화를 위해 설계된 Jupyter Notebook인 데모.ipynb도 제공했습니다. 데모는 CUB 데이터 세트에 중점을 두고 있습니다.
훈련을 위해 INTR을 준비하려면 사전 훈련된 모델 DETR-R50을 사용하십시오. 특정 데이터세트에 대해 훈련하려면 '--num_queries'를 데이터세트의 클래스 수로 설정하여 수정하세요. INTR 아키텍처 내에서 디코더의 각 쿼리에는 클래스별 기능을 캡처하는 작업이 할당됩니다. 이는 모든 쿼리가 학습 프로세스를 통해 조정될 수 있음을 의미합니다. 결과적으로 모델 매개변수의 총 개수는 데이터 세트의 클래스 수에 비례하여 증가합니다. 다중 GPU 시스템(예: GPU 4개)에서 INTR을 훈련하려면 아래 명령을 실행하십시오.
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 --master_port 12345 --use_env main.py --finetune < path/to/detr-r50-e632da11.pth > --dataset_path < path/to/datasets > --dataset_name < dataset_name > --num_queries < num_of_classes > 우리 모델은 DETR(DEtection TRansformer) 방법에서 영감을 받았습니다.
이러한 훌륭한 작업을 수행한 DETR 작성자에게 감사드립니다.
우리 작업이 귀하의 연구에 도움이 된다면 BibTeX 항목을 인용하는 것을 고려해 보십시오.
@inproceedings{paul2024simple,
title={A Simple Interpretable Transformer for Fine-Grained Image Classification and Analysis},
author={Paul, Dipanjyoti and Chowdhury, Arpita and Xiong, Xinqi and Chang, Feng-Ju and Carlyn, David and Stevens, Samuel and Provost, Kaiya and Karpatne, Anuj and Carstens, Bryan and Rubenstein, Daniel and Stewart, Charles and Berger-Wolf, Tanya and Su, Yu and Chao, Wei-Lun},
booktitle={International Conference on Learning Representations},
year={2024}
}

