open_llama
1.0.0
요약 : 우리는 Meta AI LLaMA의 허용 라이선스 오픈 소스 복제품인 OpenLLaMA의 공개 미리 보기를 출시합니다. 우리는 다양한 데이터 혼합에 대해 훈련된 일련의 3B, 7B 및 13B 모델을 출시하고 있습니다. 우리의 모델 가중치는 기존 구현에서 LLaMA를 대체하는 역할을 할 수 있습니다.
이 리포지토리에서는 Meta AI의 LLaMA 대형 언어 모델에 대한 허가된 오픈 소스 복제물을 제시합니다. 우리는 1T 토큰에 대해 훈련된 일련의 3B, 7B 및 13B 모델을 출시하고 있습니다. 사전 훈련된 OpenLLaMA 모델의 PyTorch 및 JAX 가중치뿐만 아니라 원래 LLaMA 모델과의 평가 결과 및 비교도 제공합니다. v2 모델은 다른 데이터 혼합으로 훈련된 이전 v1 모델보다 낫습니다.
우리는 7Bv2 모델과 동일한 데이터 세트 혼합에서 1T 토큰에 대해 훈련된 3B 모델인 OpenLLaMA 3Bv3 모델을 출시합니다.
Falcon의 세련된 웹 데이터세트와 스타코더 데이터세트, Wikipedia, arxiv, Books, RedPajama의 stackexchange를 혼합하여 훈련된 OpenLLaMA 7Bv2 모델을 출시하게 되어 기쁘게 생각합니다.
OpenLLaMA 13B의 최종 1T 토큰 버전을 출시하게 되어 기쁘게 생각합니다. 평가 결과를 업데이트했습니다. 현재 버전의 OpenLLaMA 모델의 경우, 우리의 토크나이저는 T5 토크나이저와 유사하게 토큰화 전에 여러 개의 빈 공간을 하나로 병합하도록 훈련되었습니다. 이로 인해 코드에 빈 공간이 많이 포함되므로 토크나이저는 코드 생성 작업(예: HumanEval)에서 작동하지 않습니다. 코드 관련 작업에는 v2 모델을 사용하세요.
OpenLLaMA 3B 및 7B의 최종 1T 토큰 버전을 출시하게 되어 기쁘게 생각합니다. 평가 결과를 업데이트했습니다. 또한 Stability AI와 협력하여 훈련된 13B 모델의 600B 토큰 미리보기를 출시하게 되어 기쁘게 생각합니다.
OpenLLaMA 7B 모델용 700B 토큰 체크포인트와 3B 모델용 600B 토큰 체크포인트를 출시하게 되어 기쁘게 생각합니다. 평가 결과도 업데이트했습니다. 전체 1T 토큰 교육 실행이 이번 주 말에 완료될 것으로 예상합니다.
커뮤니티로부터 피드백을 받은 후, 이전 체크포인트 릴리스의 토크나이저가 잘못 구성되어 새 줄이 유지되지 않는다는 사실을 발견했습니다. 이 문제를 해결하기 위해 토크나이저를 다시 훈련하고 모델 훈련을 다시 시작했습니다. 또한 이 새로운 토크나이저를 사용하면 훈련 손실이 더 낮아지는 것을 관찰했습니다.
우리는 EasyLM 프레임워크에 사용할 EasyLM 형식과 Hugging Face 변환기 라이브러리에 사용할 PyTorch 형식의 두 가지 형식으로 가중치를 릴리스합니다. 훈련 프레임워크인 EasyLM과 체크포인트 가중치 모두 Apache 2.0 라이센스에 따라 라이센스가 허용됩니다.
미리보기 체크포인트는 Hugging Face Hub에서 직접 로드할 수 있습니다. 자동 변환된 빠른 토크나이저가 때때로 잘못된 토큰화를 제공하는 것을 관찰했으므로 지금은 Hugging Face 빠른 토크나이저를 사용하지 않는 것이 좋습니다 . 이는 LlamaTokenizer 클래스를 직접 사용하거나 AutoTokenizer 클래스에 대해 use_fast=False 옵션을 전달하여 달성할 수 있습니다. 사용법은 다음 예를 참조하세요.
import torch
from transformers import LlamaTokenizer , LlamaForCausalLM
## v2 models
model_path = 'openlm-research/open_llama_3b_v2'
# model_path = 'openlm-research/open_llama_7b_v2'
## v1 models
# model_path = 'openlm-research/open_llama_3b'
# model_path = 'openlm-research/open_llama_7b'
# model_path = 'openlm-research/open_llama_13b'
tokenizer = LlamaTokenizer . from_pretrained ( model_path )
model = LlamaForCausalLM . from_pretrained (
model_path , torch_dtype = torch . float16 , device_map = 'auto' ,
)
prompt = 'Q: What is the largest animal? n A:'
input_ids = tokenizer ( prompt , return_tensors = "pt" ). input_ids
generation_output = model . generate (
input_ids = input_ids , max_new_tokens = 32
)
print ( tokenizer . decode ( generation_output [ 0 ]))보다 고급 사용법을 보려면 변환기 LLaMA 문서를 따르십시오.
모델은 lm-eval-harness를 사용하여 평가할 수 있습니다. 그러나 앞서 언급한 토크나이저 문제로 인해 올바른 결과를 얻으려면 빠른 토크나이저를 사용하지 않아야 합니다. 이는 아래 예와 같이 lm-eval-harness의 이 부분에 use_fast=False 전달하여 달성할 수 있습니다.
tokenizer = self . AUTO_TOKENIZER_CLASS . from_pretrained (
pretrained if tokenizer is None else tokenizer ,
revision = revision + ( "/" + subfolder if subfolder is not None else "" ),
use_fast = False
)EasyLM 프레임워크에서 가중치를 사용하려면 EasyLM의 LLaMA 설명서를 참조하세요. 원래 LLaMA 모델과 달리 OpenLLaMA 토크나이저 및 가중치는 처음부터 완전히 훈련되므로 더 이상 원래 LLaMA 토크나이저 및 가중치를 얻을 필요가 없습니다.
v1 모델은 RedPajama 데이터 세트에서 학습되었습니다. v2 모델은 Falcon 세련된 웹 데이터세트, StarCoder 데이터세트, Wikipedia, arxiv, book 및 RedPajama 데이터세트의 stackexchange 부분을 혼합하여 학습되었습니다. 모델 아키텍처, 컨텍스트 길이, 교육 단계, 학습 속도 일정 및 최적화 프로그램을 포함하여 원본 LLaMA 논문과 정확히 동일한 전처리 단계 및 교육 하이퍼 매개변수를 따릅니다. 우리 설정과 원래 설정의 유일한 차이점은 사용된 데이터 세트입니다. OpenLLaMA는 원래 LLaMA에서 사용하는 것이 아닌 개방형 데이터 세트를 사용합니다.
대규모 언어 모델을 훈련하고 미세 조정하기 위해 개발한 JAX 기반 훈련 파이프라인인 EasyLM을 사용하여 클라우드 TPU-v4에서 모델을 훈련합니다. 우리는 훈련 처리량과 메모리 사용량의 균형을 맞추기 위해 일반 데이터 병렬 처리와 완전히 분할된 데이터 병렬 처리(Zero 3단계라고도 함)의 조합을 사용합니다. 전체적으로 우리는 7B 모델의 경우 초당 2200개 이상의 토큰/TPU-v4 칩의 처리량에 도달했습니다. 훈련 손실은 아래 그림에서 볼 수 있습니다.
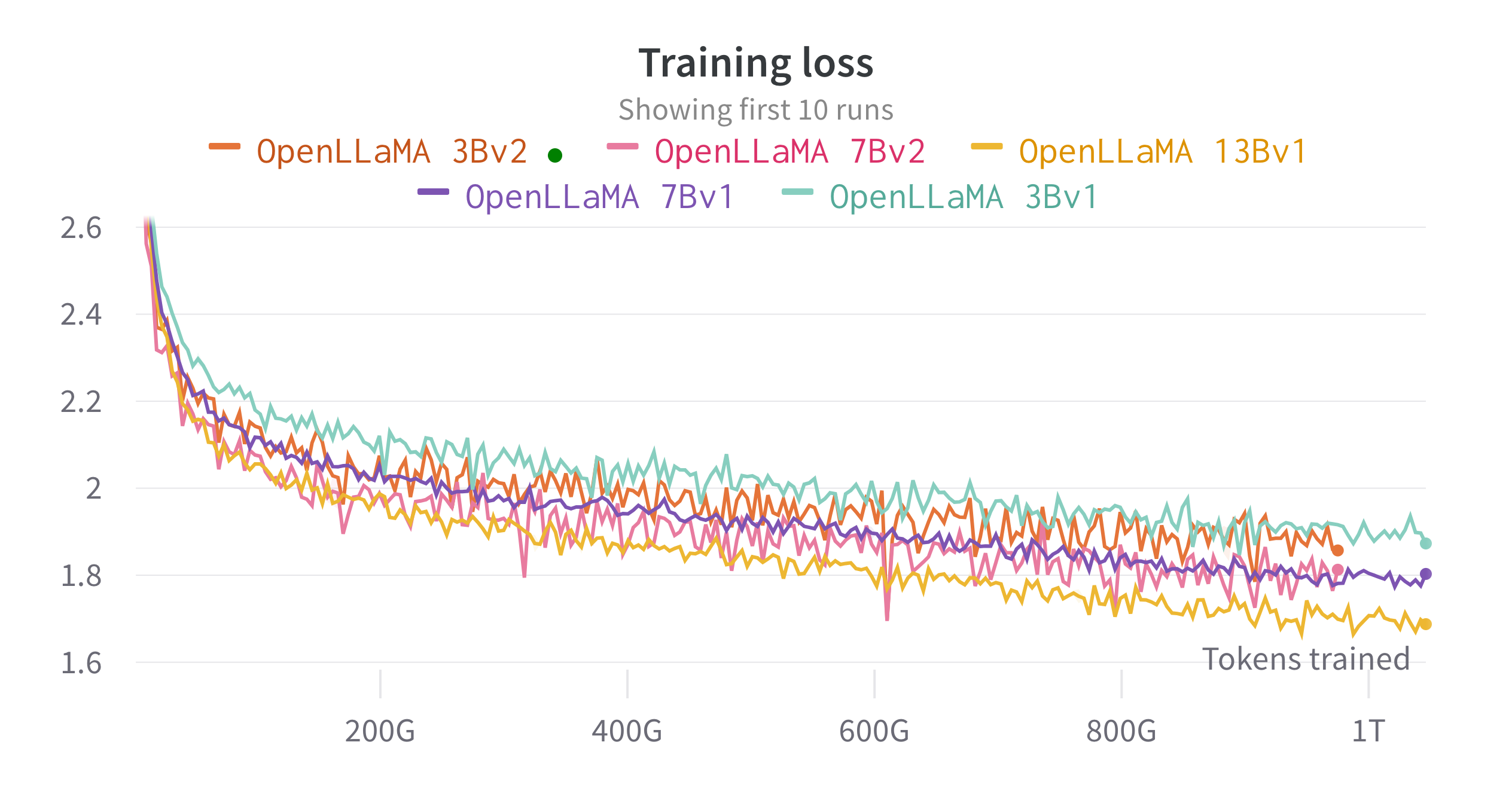
우리는 lm-evaluation-harness를 사용하여 광범위한 작업에서 OpenLLaMA를 평가했습니다. LLaMA 결과는 동일한 평가 지표에서 원본 LLaMA 모델을 실행하여 생성됩니다. 우리는 LLaMA 모델에 대한 결과가 원본 LLaMA 논문과 약간 다르다는 점에 주목합니다. 이는 서로 다른 평가 프로토콜의 결과라고 생각됩니다. 이번 호 영화 평가 하네스에서도 비슷한 차이점이 보고되었습니다. 또한 EleutherAI가 Pile 데이터세트를 학습한 6B 매개변수 모델인 GPT-J의 결과를 제시합니다.
원래 LLaMA 모델은 1조 토큰에 대해 훈련되었고 GPT-J는 5000억 토큰에 대해 훈련되었습니다. 그 결과를 아래 표에 제시합니다. OpenLLaMA는 대부분의 작업에서 원래 LLaMA 및 GPT-J와 비슷한 성능을 나타내며 일부 작업에서는 더 뛰어난 성능을 보입니다.
| 작업/지표 | GPT-J 6B | 라마 7B | 라마 13B | OpenLLaMA 3Bv2 | OpenLLaMA 7Bv2 | OpenLLaMA 3B | OpenLLaMA 7B | OpenLLaMA 13B |
|---|---|---|---|---|---|---|---|---|
| anli_r1/acc | 0.32 | 0.35 | 0.35 | 0.33 | 0.34 | 0.33 | 0.33 | 0.33 |
| anli_r2/acc | 0.34 | 0.34 | 0.36 | 0.36 | 0.35 | 0.32 | 0.36 | 0.33 |
| anli_r3/acc | 0.35 | 0.37 | 0.39 | 0.38 | 0.39 | 0.35 | 0.38 | 0.40 |
| arc_challenge/acc | 0.34 | 0.39 | 0.44 | 0.34 | 0.39 | 0.34 | 0.37 | 0.41 |
| arc_challenge/acc_norm | 0.37 | 0.41 | 0.44 | 0.36 | 0.41 | 0.37 | 0.38 | 0.44 |
| arc_easy/acc | 0.67 | 0.68 | 0.75 | 0.68 | 0.73 | 0.69 | 0.72 | 0.75 |
| arc_easy/acc_norm | 0.62 | 0.52 | 0.59 | 0.63 | 0.70 | 0.65 | 0.68 | 0.70 |
| boolq/acc | 0.66 | 0.75 | 0.71 | 0.66 | 0.72 | 0.68 | 0.71 | 0.75 |
| hellaswag/acc | 0.50 | 0.56 | 0.59 | 0.52 | 0.56 | 0.49 | 0.53 | 0.56 |
| hellaswag/acc_norm | 0.66 | 0.73 | 0.76 | 0.70 | 0.75 | 0.67 | 0.72 | 0.76 |
| 오픈북qa/acc | 0.29 | 0.29 | 0.31 | 0.26 | 0.30 | 0.27 | 0.30 | 0.31 |
| 오픈북qa/acc_norm | 0.38 | 0.41 | 0.42 | 0.38 | 0.41 | 0.40 | 0.40 | 0.43 |
| 피카/acc | 0.75 | 0.78 | 0.79 | 0.77 | 0.79 | 0.75 | 0.76 | 0.77 |
| 피카/acc_norm | 0.76 | 0.78 | 0.79 | 0.78 | 0.80 | 0.76 | 0.77 | 0.79 |
| 녹음/EM | 0.88 | 0.91 | 0.92 | 0.87 | 0.89 | 0.88 | 0.89 | 0.91 |
| 기록/f1 | 0.89 | 0.91 | 0.92 | 0.88 | 0.89 | 0.89 | 0.90 | 0.91 |
| rte/acc | 0.54 | 0.56 | 0.69 | 0.55 | 0.57 | 0.58 | 0.60 | 0.64 |
| 진실한qa_mc/mc1 | 0.20 | 0.21 | 0.25 | 0.22 | 0.23 | 0.22 | 0.23 | 0.25 |
| 진실한qa_mc/mc2 | 0.36 | 0.34 | 0.40 | 0.35 | 0.35 | 0.35 | 0.35 | 0.38 |
| WIC/ACC | 0.50 | 0.50 | 0.50 | 0.50 | 0.50 | 0.48 | 0.51 | 0.47 |
| 위노그란데/acc | 0.64 | 0.68 | 0.70 | 0.63 | 0.66 | 0.62 | 0.67 | 0.70 |
| 평균 | 0.52 | 0.55 | 0.57 | 0.53 | 0.56 | 0.53 | 0.55 | 0.57 |
우리 모델이 이 두 작업에서 의심스러울 정도로 높은 성능을 발휘하므로 벤치마크에서 CB 및 WSC 작업을 제거했습니다. 우리는 훈련 세트에 벤치마크 데이터 오염이 있을 수 있다고 가정합니다.
우리는 커뮤니티로부터 피드백을 받고 싶습니다. 질문이 있는 경우 문제를 열거나 당사에 문의해 주세요.
OpenLLaMA는 Berkeley AI Research의 Xinyang Geng*과 Hao Liu*가 개발했습니다. *동등한 기여
계산 리소스의 일부를 제공해주신 Google TPU Research Cloud 프로그램에 감사드립니다. 컴퓨팅 리소스 구성에 도움을 준 TPU Research Cloud의 Jonathan Caton, Google Cloud 팀의 Rafi Witten, 학습 처리량 최적화에 도움을 준 Google JAX 팀의 James Bradbury에게 특별히 감사의 말씀을 전하고 싶습니다. 또한 토론과 피드백을 주신 Charlie Snell, Gautier Izacard, Eric Wallace, Lianmin Zheng 및 사용자 커뮤니티에도 감사의 말씀을 전하고 싶습니다.
OpenLLaMA 13B v1 모델은 Stability AI와 협력하여 훈련되었으며 계산 리소스를 제공해준 Stability AI에 감사드립니다. 특히 물류를 조정하고 엔지니어링 지원을 제공한 David Ha와 Shivanshu Purohit에게 감사의 말씀을 전하고 싶습니다.
OpenLLaMA가 연구나 응용 분야에 유용하다고 생각되면 다음 BibTeX를 사용하여 인용해 주세요.
@software{openlm2023openllama,
author = {Geng, Xinyang and Liu, Hao},
title = {OpenLLaMA: An Open Reproduction of LLaMA},
month = May,
year = 2023,
url = {https://github.com/openlm-research/open_llama}
}
@software{together2023redpajama,
author = {Together Computer},
title = {RedPajama-Data: An Open Source Recipe to Reproduce LLaMA training dataset},
month = April,
year = 2023,
url = {https://github.com/togethercomputer/RedPajama-Data}
}
@article{touvron2023llama,
title={Llama: Open and efficient foundation language models},
author={Touvron, Hugo and Lavril, Thibaut and Izacard, Gautier and Martinet, Xavier and Lachaux, Marie-Anne and Lacroix, Timoth{'e}e and Rozi{`e}re, Baptiste and Goyal, Naman and Hambro, Eric and Azhar, Faisal and others},
journal={arXiv preprint arXiv:2302.13971},
year={2023}
}


