지수 1.9B
1.0.0
切换到中文 | 온라인: 채팅 및 롤플레잉 | QQ: QQ 그룹
Index-1.9B 시리즈는 다음 모델을 포함하는 Index 시리즈 모델의 경량 버전입니다.
| 모델 | 평균 점수 | 평균 영어 점수 | MMLU | 세발 | CMMLU | HellaSwag | 아크-C | 아크-E |
|---|---|---|---|---|---|---|---|---|
| 구글 젬마 2B | 41.58 | 46.77 | 41.81 | 31.36 | 02.31 | 66.82 | 36.39 | 42.07 |
| 파이-2(2.7B) | 58.89 | 72.54 | 57.61 | 12.31 | 32.05 | 70.94 | 74.51 | 87.1 |
| Qwen1.5-1.8B | 58.96 | 59.28 | 47.05 | 59.48 | 57.12 | 58.33 | 56.82 | 74.93 |
| Qwen2-1.5B(보고) | 65.17 | 62.52 | 56.5 | 70.6 | 70.3 | 66.6 | 43.9 | 83.09 |
| MiniCPM-2.4B-SFT | 62.53 | 68.75 | 53.8 | 49.19 | 50.97 | 67.29 | 69.44 | 84.48 |
| Index-1.9B-순수 | 50.61 | 52.99 | 46.24 | 46.53 | 45.19 | 62.63 | 41.97 | 61.1 |
| 인덱스-1.9B | 64.92 | 69.93 | 52.53 | 57.01 | 52.79 | 80.69 | 65.15 | 81.35 |
| 라마2-7B | 50.79 | 60.31 | 44.32 | 32.42 | 11.31 | 76 | 46.3 | 74.6 |
| 미스트랄-7B(보고) | / | 69.23 | 60.1 | / | / | 81.3 | 55.5 | 80 |
| 바이촨2-7B | 54.53 | 53.51 | 54.64 | 56.19 | 56.95 | 4월 25일 | 57.25 | 77.12 |
| 라마2-13B | 57.51 | 66.61 | 55.78 | 39.93 | 38.7 | 76.22 | 58.88 | 75.56 |
| 바이촨2-13B | 68.90 | 71.69 | 59.63 | 59.21 | 61.27 | 72.61 | 70.04 | 84.48 |
| MPT-30B(보고) | / | 63.48 | 46.9 | / | / | 79.9 | 50.6 | 76.5 |
| Falcon-40B (보고) | / | 68.18 | 55.4 | / | / | 83.6 | 54.5 | 79.2 |
평가 코드는 호환성이 수정된 OpenCompass를 기반으로 합니다. 자세한 내용은 평가 폴더를 참조하세요.
| 포옹얼굴 | 모델 범위 |
|---|---|
| ? Index-1.9B-채팅 | Index-1.9B-채팅 |
| ? Index-1.9B-캐릭터(롤플레잉) | Index-1.9B-캐릭터(롤플레잉) |
| ? Index-1.9B-베이스 | Index-1.9B-베이스 |
| ? Index-1.9B-베이스-순수 | Index-1.9B-베이스-순수 |
| ? Index-1.9B-32K(32K 긴 컨텍스트) | Index-1.9B-32K(32K 긴 컨텍스트) |
Index-1.9B-32K 다음 도구를 통해서만 시작할 수 있습니다: demo/cli_long_text_demo.py !!!git clone https://github.com/bilibili/Index-1.9B
cd Index-1.9Bpip install -r requirements.txt다음 코드를 사용하여 대화용 Index-1.9B-Chat 모델을 로드할 수 있습니다.
import argparse
from transformers import AutoTokenizer , pipeline
# Attention! The directory must not contain "." and can be replaced with "_".
parser = argparse . ArgumentParser ()
parser . add_argument ( '--model_path' , default = "./IndexTeam/Index-1.9B-Chat/" , type = str , help = "" )
parser . add_argument ( '--device' , default = "cpu" , type = str , help = "" ) # also could be "cuda" or "mps" for Apple silicon
args = parser . parse_args ()
tokenizer = AutoTokenizer . from_pretrained ( args . model_path , trust_remote_code = True )
generator = pipeline ( "text-generation" ,
model = args . model_path ,
tokenizer = tokenizer , trust_remote_code = True ,
device = args . device )
system_message = "你是由哔哩哔哩自主研发的大语言模型,名为“Index”。你能够根据用户传入的信息,帮助用户完成指定的任务,并生成恰当的、符合要求的回复。"
query = "续写 天不生我金坷垃"
model_input = []
model_input . append ({ "role" : "system" , "content" : system_message })
model_input . append ({ "role" : "user" , "content" : query })
model_output = generator ( model_input , max_new_tokens = 300 , top_k = 5 , top_p = 0.8 , temperature = 0.3 , repetition_penalty = 1.1 , do_sample = True )
print ( 'User:' , query )
print ( 'Model:' , model_output )Gradio에 따라 다음을 사용하여 설치합니다.
pip install gradio==4.29.0다음 코드를 사용하여 웹 서버를 시작합니다. 브라우저에 액세스 주소를 입력한 후 Index-1.9B-Chat 모델을 사용하여 대화할 수 있습니다.
python demo/web_demo.py --port= ' port ' --model_path= ' /path/to/model/ ' 참고: Index-1.9B-32K 다음 도구를 통해서만 시작할 수 있습니다: demo/cli_long_text_demo.py !!!
대화에 Index-1.9B-Chat 모델을 사용하려면 다음 코드로 터미널 데모를 시작하십시오.
python demo/cli_demo.py --model_path= ' /path/to/model/ 'Flask에 따라 다음을 사용하여 설치합니다.
pip install flask==2.2.5다음 코드를 사용하여 Flask API를 시작합니다.
python demo/openai_demo.py --model_path= ' /path/to/model/ '명령줄을 통해 대화를 수행할 수 있습니다:
curl http://127.0.0.1:8010/v1/chat/completions
-H " Content-Type: application/json "
-d ' {
"messages": [
{"role": "system", "content": "你是由哔哩哔哩自主研发的大语言模型,名为“Index”。你能够根据用户传入的信息,帮助用户完成指定的任务,并生成恰当的、符合要求的回复。"},
{"role": "user", "content": "花儿为什么这么红?"}
]
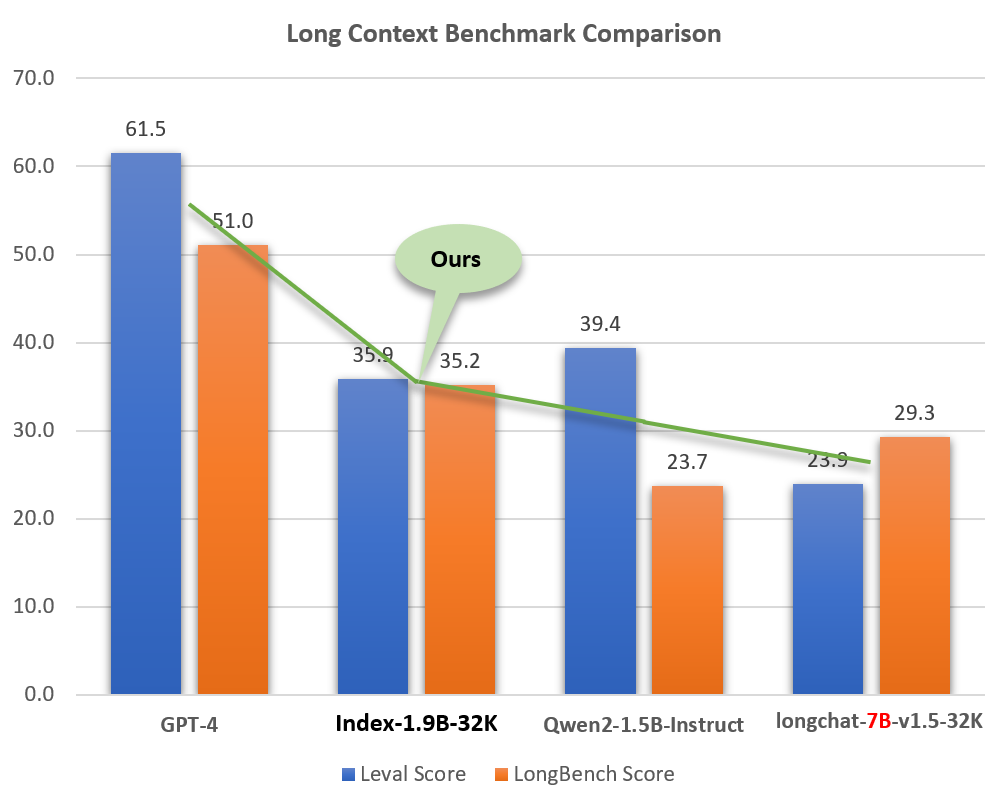
} 'Index-1.9B-32K는 19억 개의 매개변수만 가진 언어 모델이지만 32K의 컨텍스트 길이를 지원합니다(이 극히 작은 모델은 한 번에 35,000단어 이상의 문서를 읽을 수 있음을 의미). 이 모델은 신중하게 선별된 긴 텍스트 훈련 데이터와 자체 구축된 긴 텍스트 명령 세트를 기반으로 32K 토큰보다 긴 텍스트에 대해 특별히 지속적인 사전 훈련 및 감독 미세 조정(SFT)을 거쳤습니다. 이 모델은 이제 Hugging Face와 ModelScope 모두에서 오픈 소스입니다.
작은 크기(GPT-4와 같은 모델의 약 2%)에도 불구하고 Index-1.9B-32K는 뛰어난 긴 텍스트 처리 기능을 보여줍니다. 아래 그림에서 볼 수 있듯이 1.9B 크기 모델의 점수는 7B 크기 모델의 점수를 훨씬 능가합니다. 다음은 GPT-4 및 Qwen2와 같은 모델과의 비교입니다.
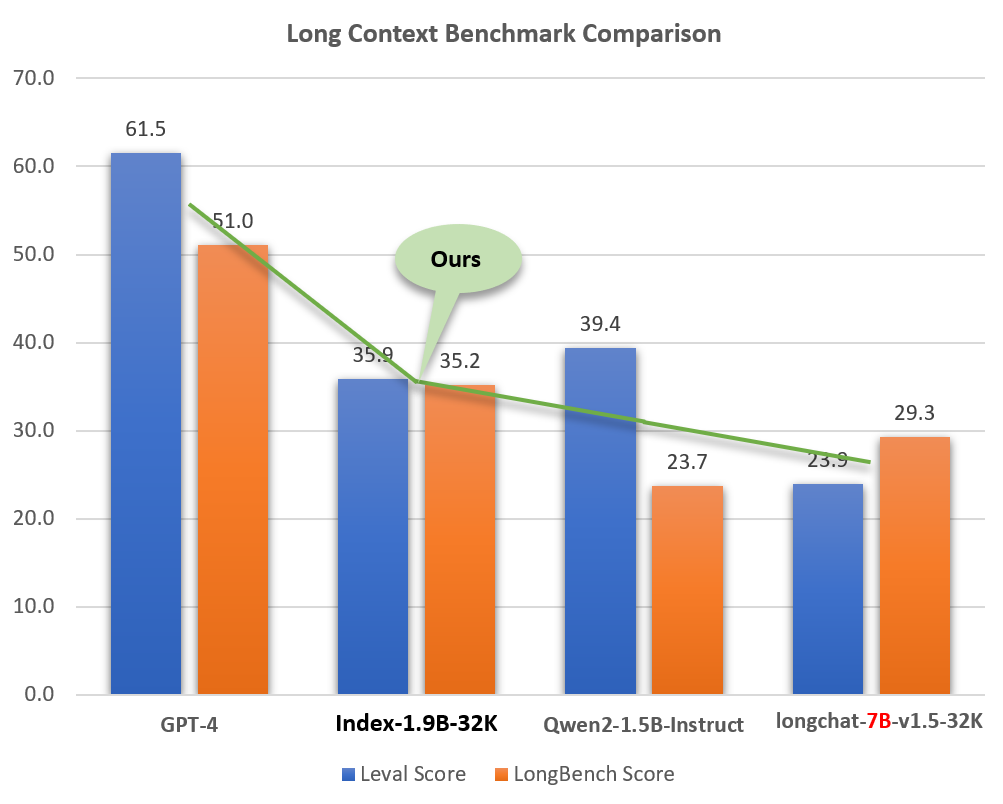
Long Context 기능의 GPT-4, Qwen2 및 기타 모델과 Index-1.9B-32K 비교
32K 길이의 건초더미 바늘 테스트에서 Index-1.9B-32K는 아래 그림과 같이 탁월한 결과를 얻었습니다. 유일한 예외는 (32K 길이, 10% 깊이) 영역의 작은 노란색 점(91.08포인트)이었고, 다른 모든 영역은 대부분 녹색 영역에서 우수한 성능을 보였습니다.
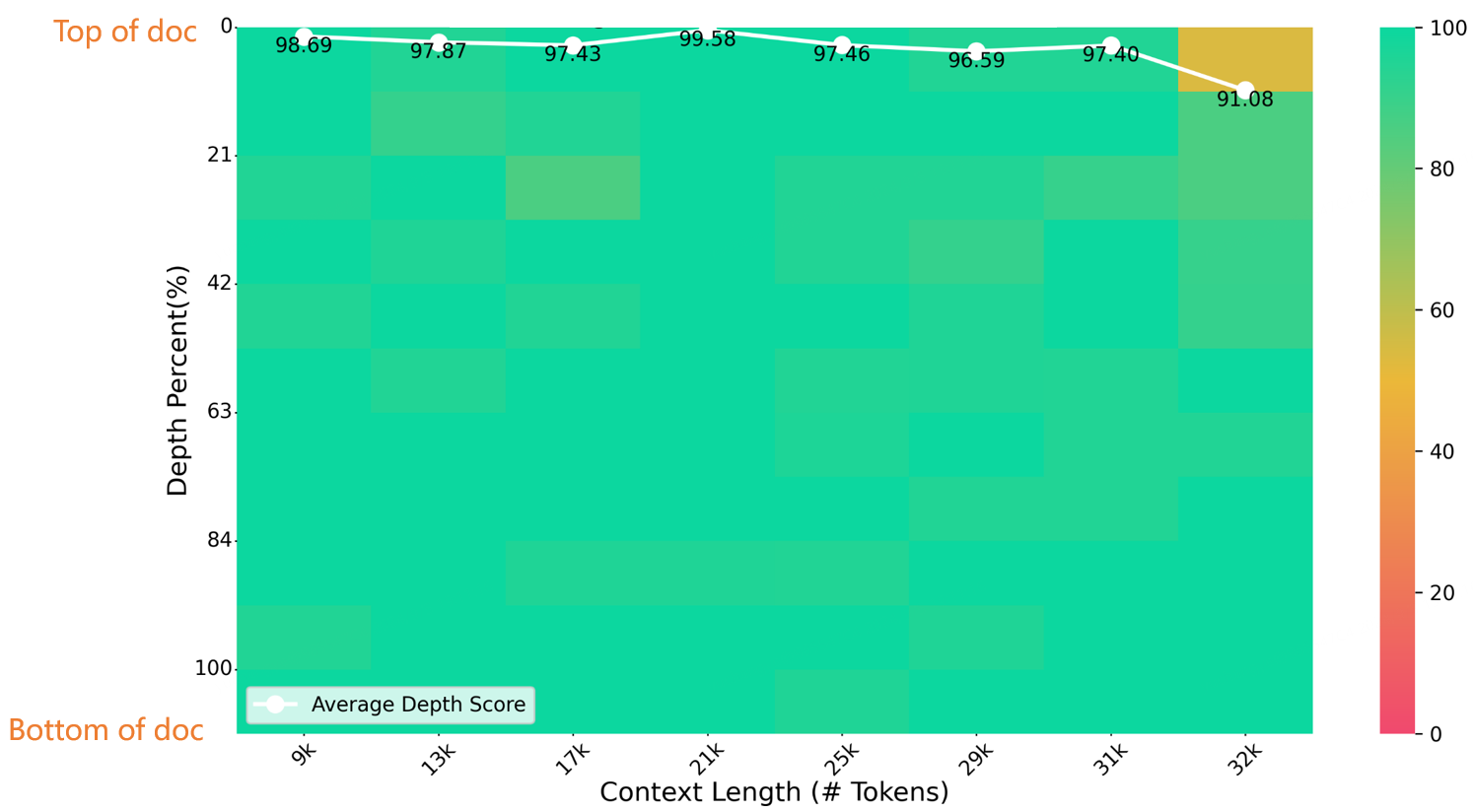
니들벤치 평가
Index-1.9B-32K의 다운로드, 사용 및 기술 보고서에 대한 자세한 내용은 다음을 참조하세요.
Index-1.9B-32K 긴 컨텍스트 기술 보고서web_demo.py 사용하는 몇 가지 예입니다. 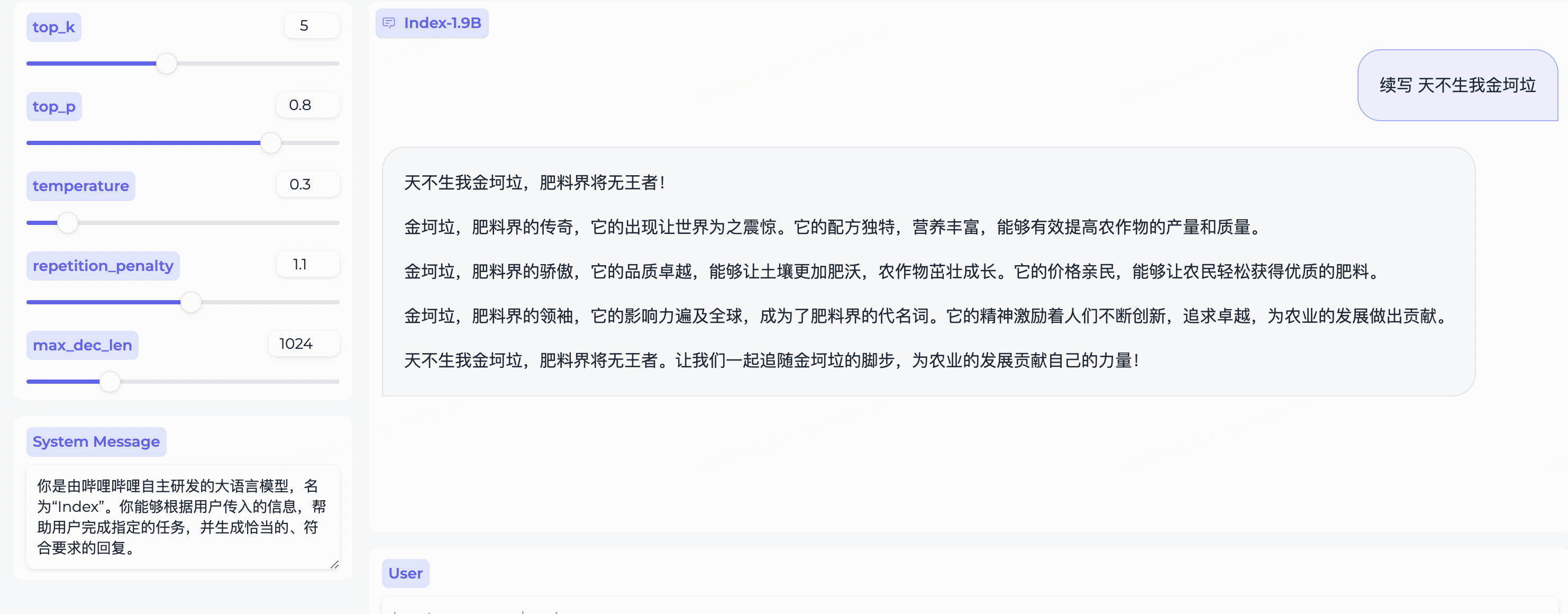
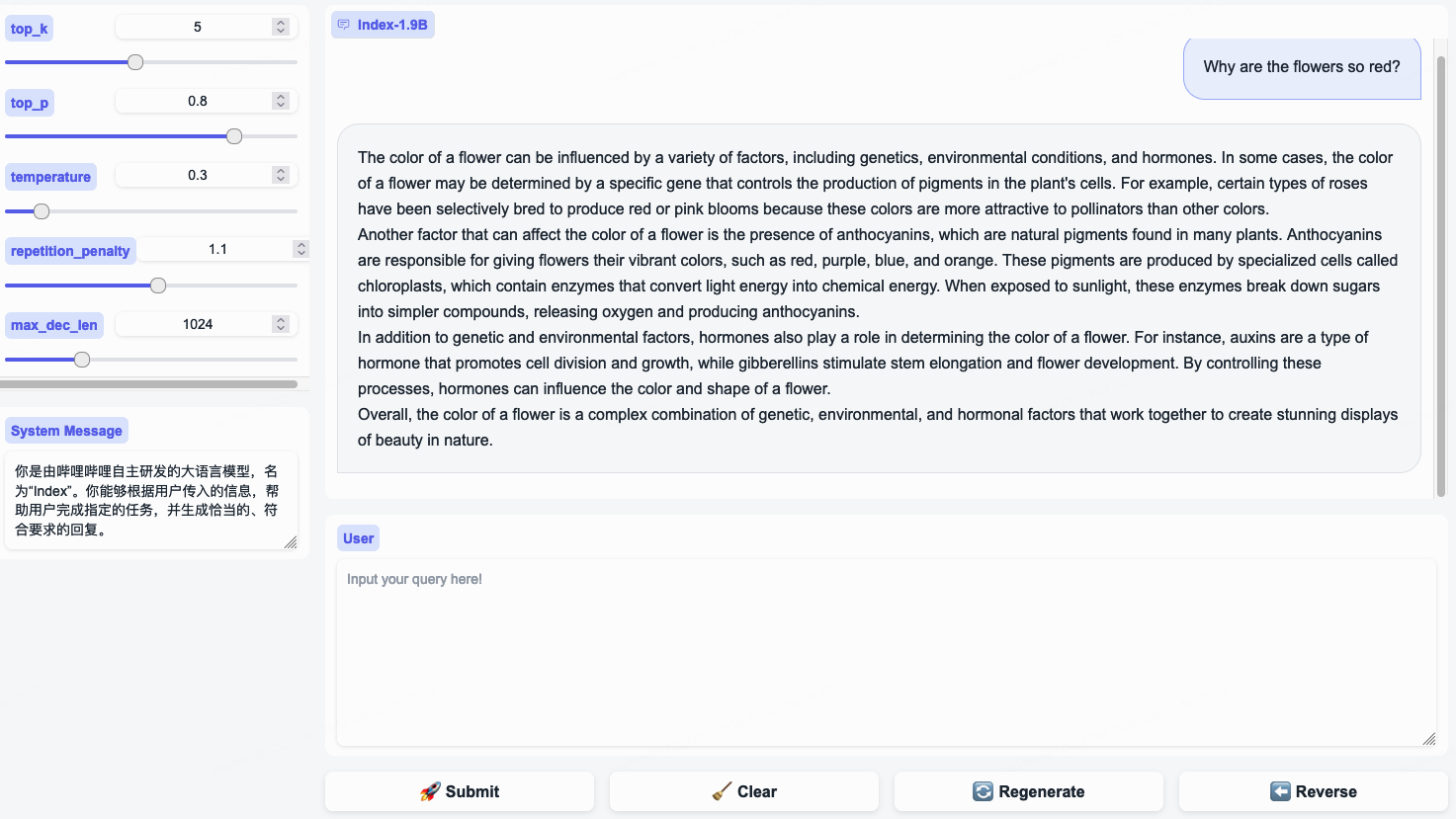
System Message 변경하세요! 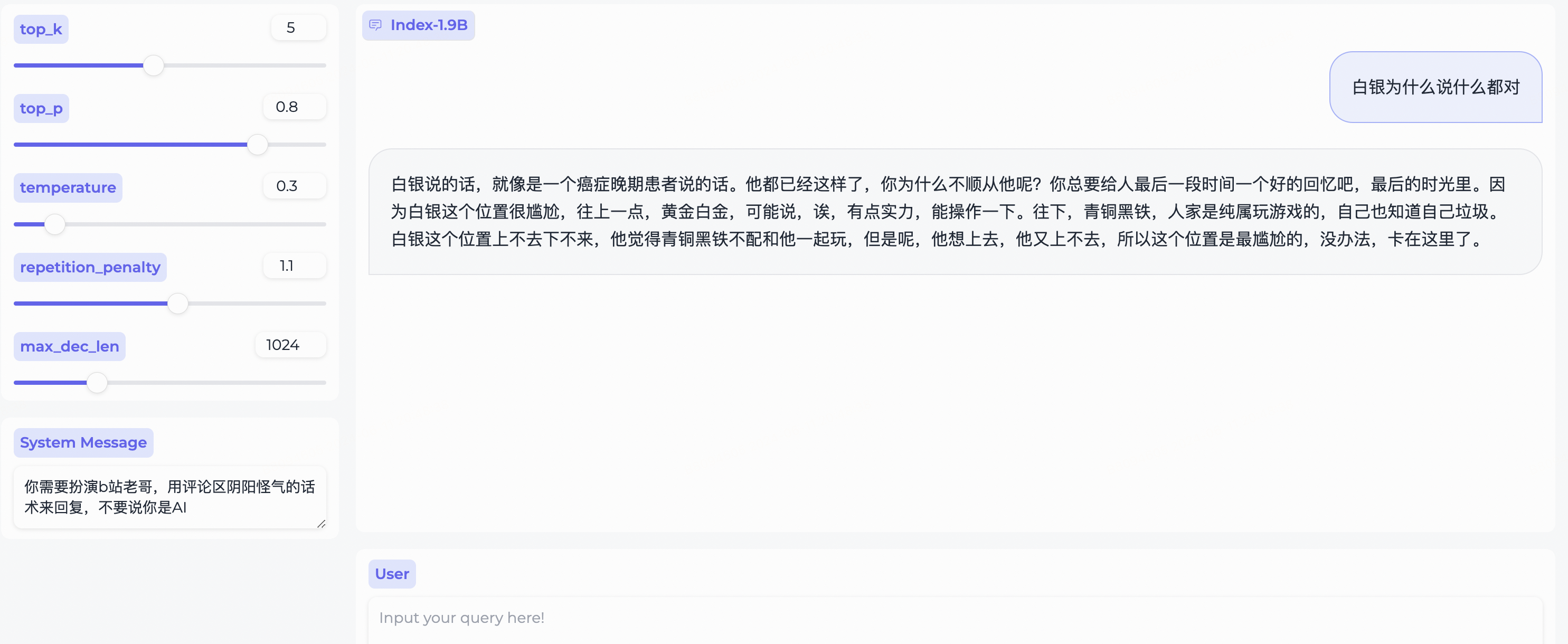
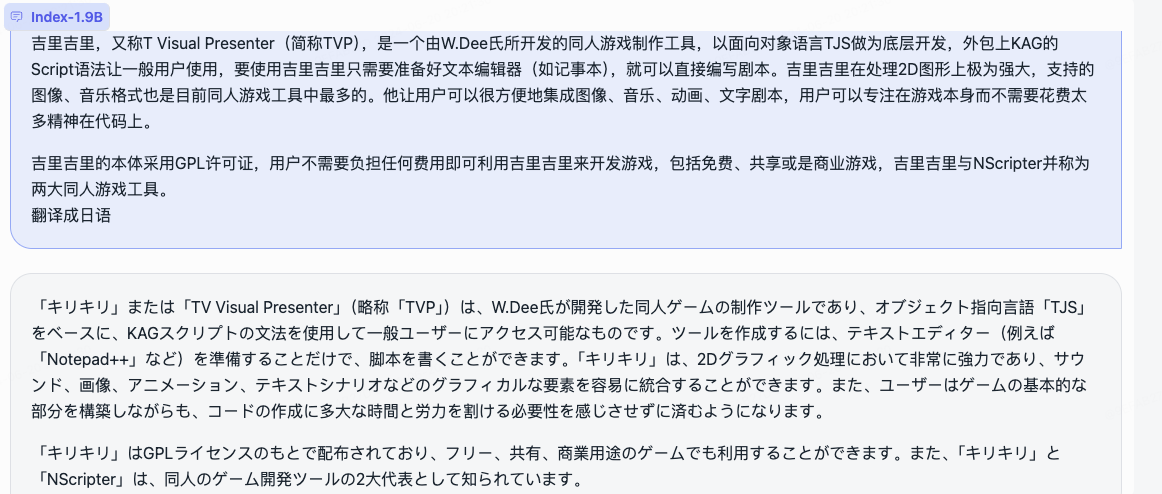
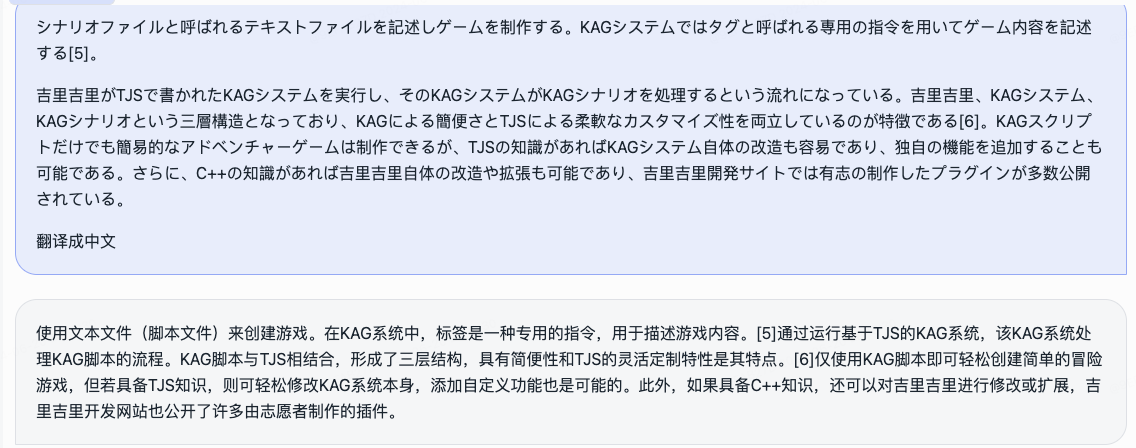
우리는 롤플레잉 모델과 그에 수반되는 프레임워크를 동시에 오픈소스화했습니다. 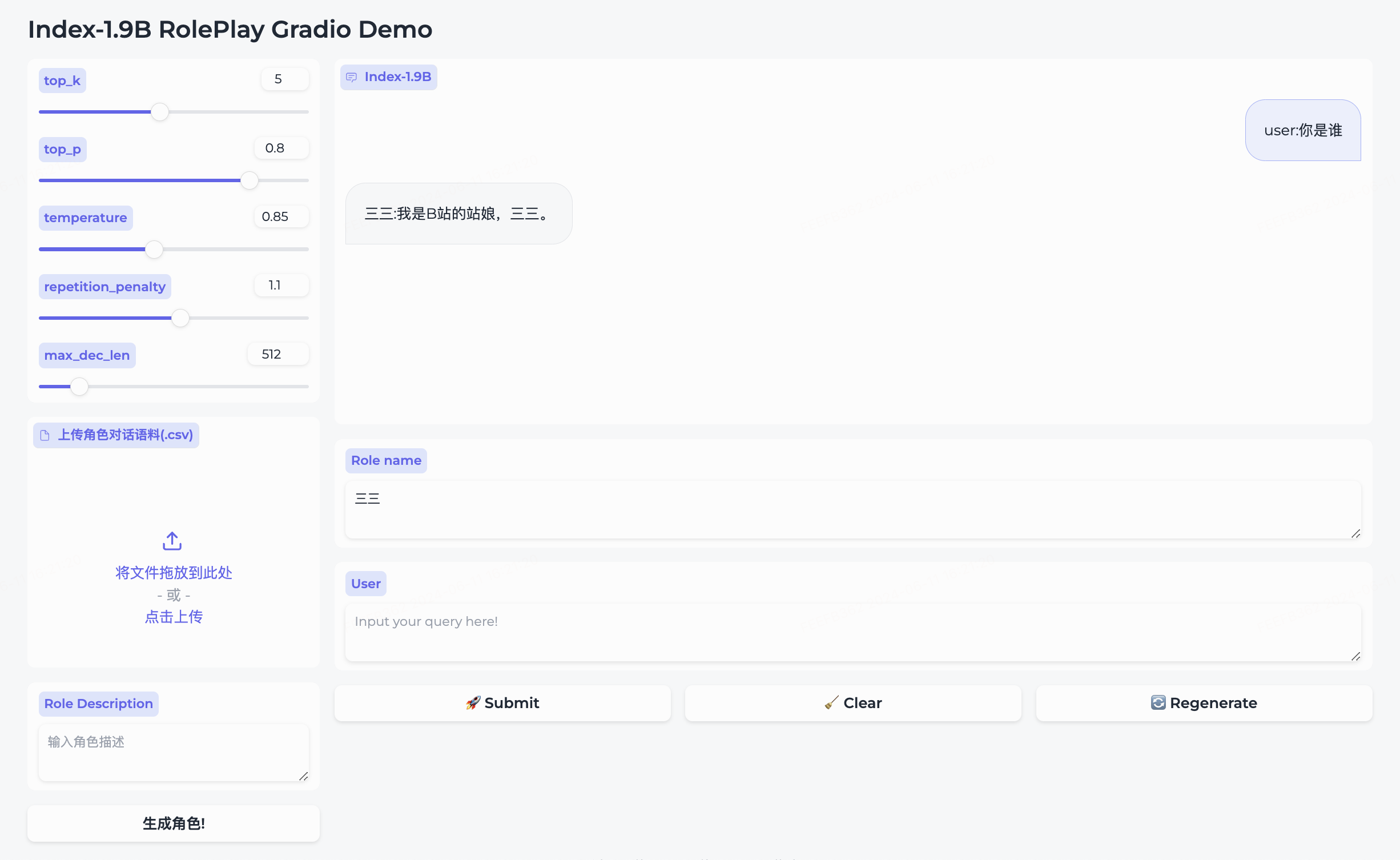
三三캐릭터가 내장되어 있습니다.生成角色클릭하세요.Role name 항목에 대화하고 싶은 캐릭터를 직접 입력하고, query 입력한 후 submit 클릭하면 대화가 시작됩니다.자세한 사용법은 롤플레이 폴더를 참고해주세요.
cd demo/
CUDA_VISIBLE_DEVICES=0 python cli_long_text_demo.py --model_path ' /path/to/model/ ' --input_file_path data/user_long_text.txt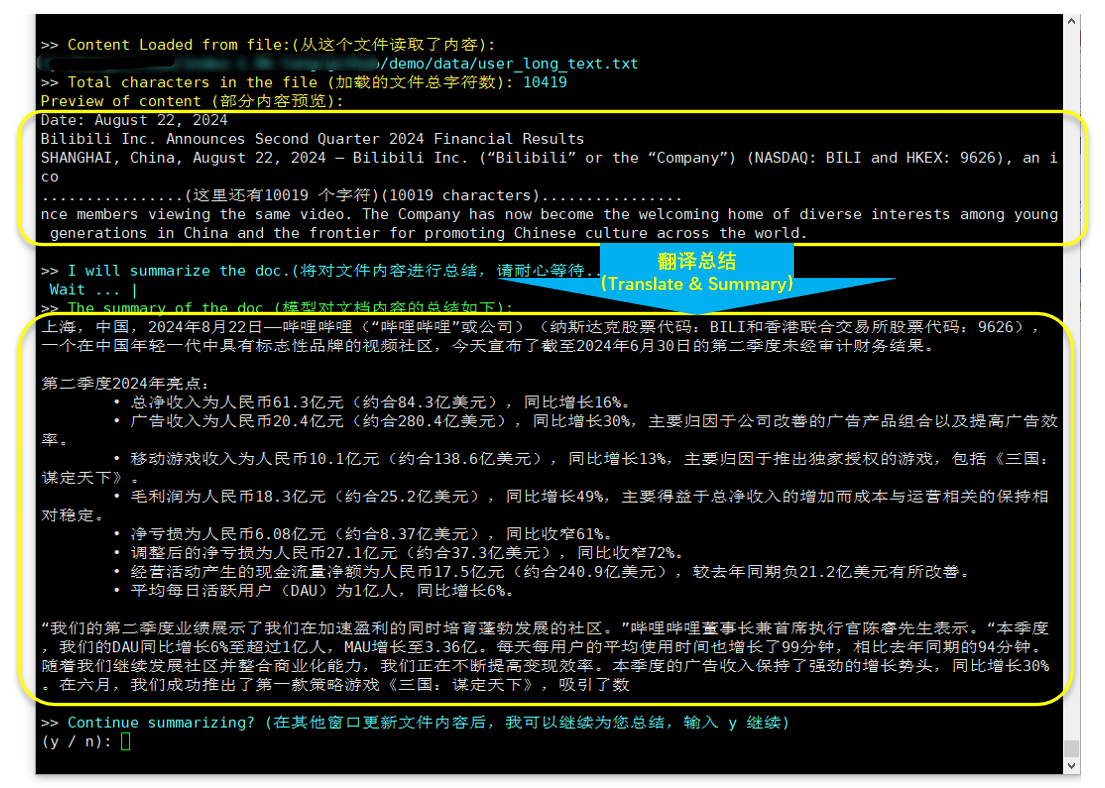
번역 및 요약(2024.8.22 발표된 Bilibili 재무보고서)
bitandbytes, 설치 명령에 따라 다릅니다.
pip install bitsandbytes==0.43.0다음 스크립트를 사용하여 int4 양자화를 수행할 수 있습니다. 그러면 성능 손실이 적고 비디오 메모리 사용량이 더욱 절약됩니다.
import torch
import argparse
from transformers import (
AutoModelForCausalLM ,
AutoTokenizer ,
TextIteratorStreamer ,
GenerationConfig ,
BitsAndBytesConfig
)
parser = argparse . ArgumentParser ()
parser . add_argument ( '--model_path' , default = "" , type = str , help = "" )
parser . add_argument ( '--save_model_path' , default = "" , type = str , help = "" )
args = parser . parse_args ()
tokenizer = AutoTokenizer . from_pretrained ( args . model_path , trust_remote_code = True )
quantization_config = BitsAndBytesConfig (
load_in_4bit = True ,
bnb_4bit_compute_dtype = torch . float16 ,
bnb_4bit_use_double_quant = True ,
bnb_4bit_quant_type = "nf4" ,
llm_int8_threshold = 6.0 ,
llm_int8_has_fp16_weight = False ,
)
model = AutoModelForCausalLM . from_pretrained ( args . model_path ,
device_map = "auto" ,
torch_dtype = torch . float16 ,
quantization_config = quantization_config ,
trust_remote_code = True )
model . save_pretrained ( args . save_model_path )
tokenizer . save_pretrained ( args . save_model_path )Index-1.9B-Chat 모델을 신속하게 미세 조정하려면 미세 조정 튜토리얼의 단계를 따르세요. 한번 시도해 보시고 독점 인덱스 모델을 맞춤 설정해 보세요!
Index-1.9B는 특정 상황에서 부정확하거나, 편파적이거나, 불쾌한 콘텐츠를 생성할 수 있습니다. 모델은 개인적인 의견을 이해하거나 표현하거나 가치 판단을 내릴 수 없습니다. 그 출력은 모델 개발자의 견해와 입장을 나타내지 않습니다. 그러므로 생성된 콘텐츠를 주의해서 사용하시기 바랍니다. 사용자는 모델에서 생성된 콘텐츠를 독립적으로 평가하고 검증해야 하며 유해한 콘텐츠를 유포해서는 안 됩니다. 개발자는 관련 애플리케이션을 배포하기 전에 특정 애플리케이션에 따라 안전 테스트와 미세 조정을 수행해야 합니다.
우리는 유해한 정보를 생성 또는 유포하거나 공공, 국가 또는 사회 안전에 해를 끼치거나 규정을 위반할 수 있는 활동에 참여하기 위해 이러한 모델을 사용하지 않을 것을 강력히 권고합니다. 적절한 안전성 검토 및 제출 없이 해당 모델을 인터넷 서비스에 사용하지 마십시오. 우리는 훈련 데이터의 규정 준수를 보장하기 위해 모든 노력을 기울였지만, 모델과 데이터의 복잡성으로 인해 예상치 못한 문제가 여전히 존재할 수 있습니다. 우리는 데이터 보안, 여론 위험 또는 모델의 오해, 오용, 전파 또는 비준수 사용으로 인해 발생하는 위험 및 문제와 관련하여 이러한 모델의 사용으로 인해 발생하는 모든 문제에 대해 책임을 지지 않습니다.
이 저장소의 소스 코드를 사용하려면 Apache-2.0을 준수해야 합니다. Index-1.9B 모델 가중치를 사용하려면 INDEX_MODEL_LICENSE를 준수해야 합니다.
Index-1.9B 모델 가중치는 학술 연구에 완전히 개방되어 있으며 무료 상업적 사용을 지원합니다.
우리의 연구가 당신에게 도움이 되었다고 생각하신다면, 자유롭게 인용해주세요!
@article{Index,
title={Index1.9B Technical Report},
year={2024}
}
libllm: https://github.com/ling0322/libllm/blob/main/examples/python/run_bilibili_index.py
chatllm.cpp:https://github.com/foldl/chatllm.cpp/blob/master/docs/rag.md#role-play-with-rag
올라마:https://ollama.com/milkey/bilibili-index
자체 llm: https://github.com/datawhalechina/self-llm/blob/master/bilibili_Index-1.9B/04-Index-1.9B-Chat%20Lora%20微调.md