LLM4Decompile
1.0.0
![]()
결과 | ? 모델 | 빠른 시작 | HumanEval-디컴파일 | ? 인용 | 종이 | 코랩 |
리버스 엔지니어링: 대규모 언어 모델을 사용하여 이진 코드 디컴파일
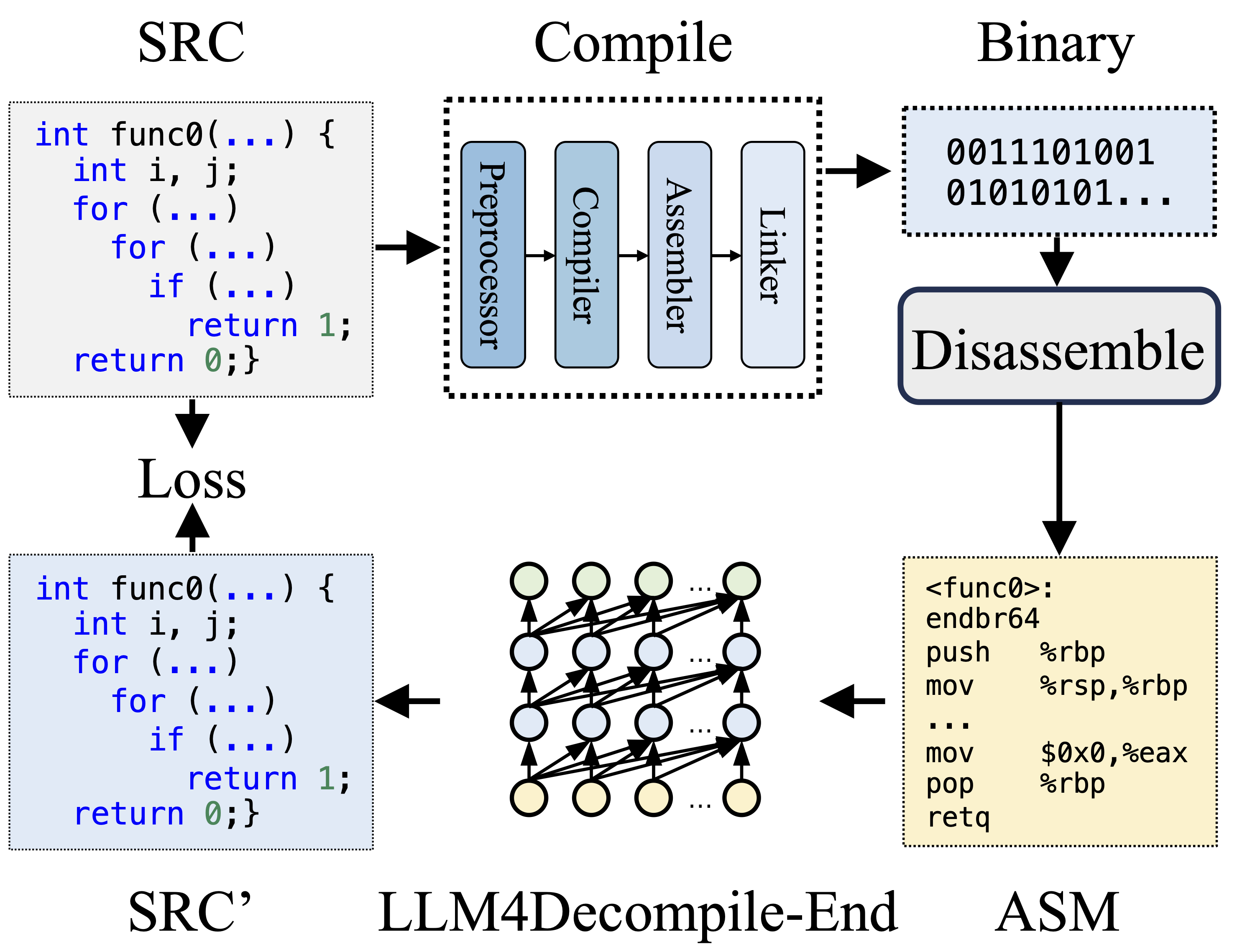
컴파일하는 동안 전처리기는 소스 코드(SRC)를 처리하여 주석을 제거하고 매크로 또는 포함을 확장합니다. 정리된 코드는 컴파일러로 전달되어 어셈블리 코드(ASM)로 변환됩니다. 이 ASM은 어셈블러에 의해 이진 코드(0과 1)로 변환됩니다. 링커는 함수 호출을 연결하여 실행 파일을 생성함으로써 프로세스를 마무리합니다. 반면에 디컴파일에는 바이너리 코드를 다시 소스 파일로 변환하는 작업이 포함됩니다. 텍스트 교육을 받은 LLM은 이진 데이터를 직접 처리하는 능력이 부족합니다. 따라서 먼저 Objdump 를 통해 바이너리를 어셈블리 언어(ASM)로 분해해야 합니다. 바이너리 ASM과 디스어셈블된 ASM은 동일하며 상호 변환이 가능하므로 서로 바꿔서 참조할 수 있습니다. 마지막으로, 훈련을 안내하기 위해 디컴파일된 코드와 소스 코드 사이에서 손실이 계산됩니다. 디컴파일된 코드(SRC')의 품질을 평가하기 위해 테스트 어설션(재실행성)을 통해 기능을 테스트합니다.
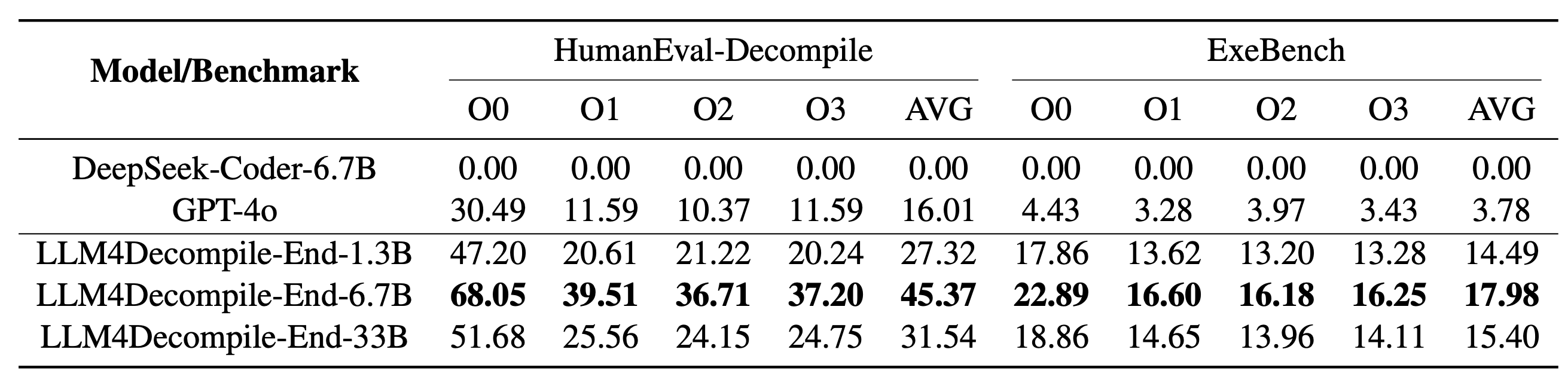
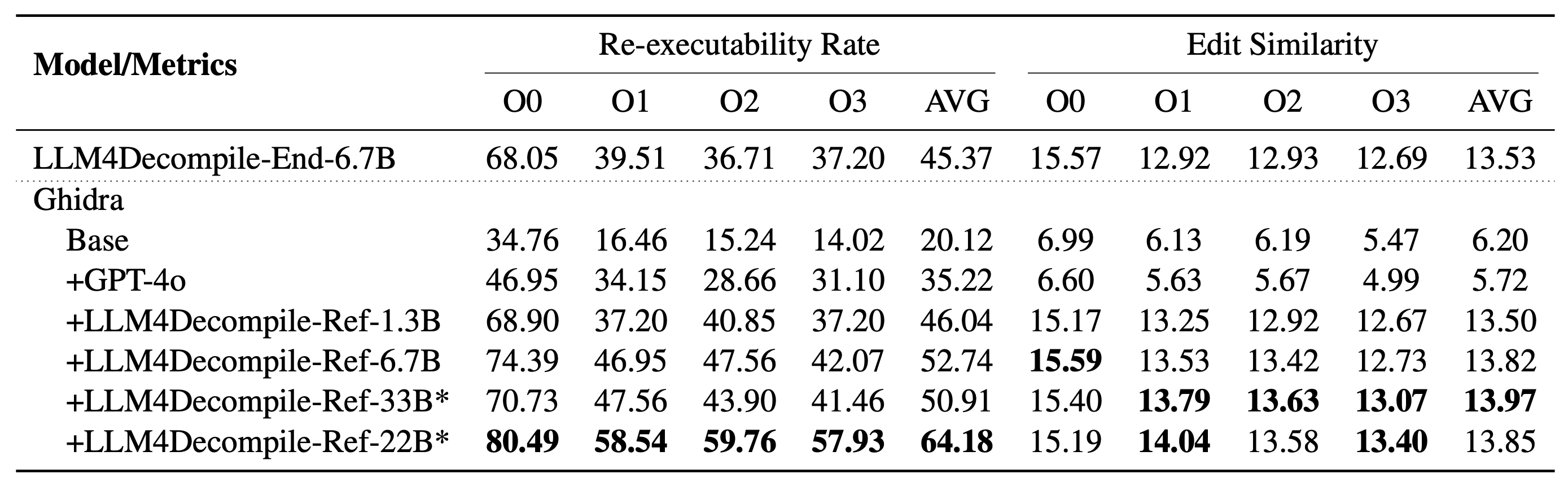
LLM4Decompile에는 13억~330억 개의 매개변수 크기를 가진 모델이 포함되어 있으며 이러한 모델을 Hugging Face에서 사용할 수 있도록 만들었습니다.
| 모델 | 검문소 | 크기 | 재실행성 | 메모 |
|---|---|---|---|---|
| llm4decompile-1.3b-v1.5 | ? HF링크 | 1.3B | 27.3% | 참고 3 |
| llm4decompile-6.7b-v1.5 | ? HF링크 | 6.7B | 45.4% | 참고 3 |
| llm4decompile-1.3b-v2 | ? HF링크 | 1.3B | 46.0% | 참고 4 |
| llm4decompile-6.7b-v2 | ? HF링크 | 6.7B | 52.7% | 참고 4 |
| llm4decompile-9b-v2 | ? HF링크 | 9B | 64.9% | 참고 4 |
| llm4decompile-22b-v2 | ? HF링크 | 22B | 63.6% | 참고 4 |
참고 3: V1.5 시리즈는 더 큰 데이터 세트(15B 토큰)와 최대 토큰 크기 4,096으로 훈련되었으며 이전 모델에 비해 놀라운 성능(100% 이상 개선)을 보였습니다.
참고 4: V2 시리즈는 Ghidra를 기반으로 구축되었으며 Ghidra에서 디컴파일된 의사 코드를 개선하기 위해 20억 개의 토큰으로 훈련되었습니다. 자세한 내용은 ghidra 폴더를 확인하세요.
설정: 아래 스크립트를 사용하여 필요한 환경을 설치하세요.
git clone https://github.com/albertan017/LLM4Decompile.git
cd LLM4Decompile
conda create -n 'llm4decompile' python=3.9 -y
conda activate llm4decompile
pip install -r requirements.txt
다음은 당사 모델 사용 방법의 예입니다(V1.5용 개정. 이전 모델의 경우 HF에서 해당 모델 페이지를 확인하세요). 참고: "func0"을 디컴파일하려는 함수 이름으로 바꾸세요 .
전처리: C 코드를 바이너리로 컴파일하고 바이너리를 어셈블리 명령어로 분해합니다.
import subprocess
import os
func_name = 'func0'
OPT = [ "O0" , "O1" , "O2" , "O3" ]
fileName = 'samples/sample' #'path/to/file'
for opt_state in OPT :
output_file = fileName + '_' + opt_state
input_file = fileName + '.c'
compile_command = f'gcc -o { output_file } .o { input_file } - { opt_state } -lm' #compile the code with GCC on Linux
subprocess . run ( compile_command , shell = True , check = True )
compile_command = f'objdump -d { output_file } .o > { output_file } .s' #disassemble the binary file into assembly instructions
subprocess . run ( compile_command , shell = True , check = True )
input_asm = ''
with open ( output_file + '.s' ) as f : #asm file
asm = f . read ()
if '<' + func_name + '>:' not in asm : #IMPORTANT replace func0 with the function name
raise ValueError ( "compile fails" )
asm = '<' + func_name + '>:' + asm . split ( '<' + func_name + '>:' )[ - 1 ]. split ( ' n n ' )[ 0 ] #IMPORTANT replace func0 with the function name
asm_clean = ""
asm_sp = asm . split ( " n " )
for tmp in asm_sp :
if len ( tmp . split ( " t " )) < 3 and '00' in tmp :
continue
idx = min (
len ( tmp . split ( " t " )) - 1 , 2
)
tmp_asm = " t " . join ( tmp . split ( " t " )[ idx :]) # remove the binary code
tmp_asm = tmp_asm . split ( "#" )[ 0 ]. strip () # remove the comments
asm_clean += tmp_asm + " n "
input_asm = asm_clean . strip ()
before = f"# This is the assembly code: n " #prompt
after = " n # What is the source code? n " #prompt
input_asm_prompt = before + input_asm . strip () + after
with open ( fileName + '_' + opt_state + '.asm' , 'w' , encoding = 'utf-8' ) as f :
f . write ( input_asm_prompt )조립 지침은 다음 형식이어야 합니다.
<FUNCTION_NAME>:n작업n작업n
일반적인 조립 지침은 다음과 같습니다.
<func0>:
endbr64
lea (%rdi,%rsi,1),%eax
retq
디컴파일: LLM4Decompile을 사용하여 어셈블리 지침을 C로 변환합니다.
from transformers import AutoTokenizer , AutoModelForCausalLM
import torch
model_path = 'LLM4Binary/llm4decompile-6.7b-v1.5' # V1.5 Model
tokenizer = AutoTokenizer . from_pretrained ( model_path )
model = AutoModelForCausalLM . from_pretrained ( model_path , torch_dtype = torch . bfloat16 ). cuda ()
with open ( fileName + '_' + OPT [ 0 ] + '.asm' , 'r' ) as f : #optimization level O0
asm_func = f . read ()
inputs = tokenizer ( asm_func , return_tensors = "pt" ). to ( model . device )
with torch . no_grad ():
outputs = model . generate ( ** inputs , max_new_tokens = 2048 ) ### max length to 4096, max new tokens should be below the range
c_func_decompile = tokenizer . decode ( outputs [ 0 ][ len ( inputs [ 0 ]): - 1 ])
with open ( fileName + '.c' , 'r' ) as f : #original file
func = f . read ()
print ( f'original function: n { func } ' ) # Note we only decompile one function, where the original file may contain multiple functions
print ( f'decompiled function: n { c_func_decompile } ' ) 데이터는 JSON 목록 형식을 사용하여 llm4decompile/decompile-eval/decompile-eval-executable-gcc-obj.json 에 저장됩니다. 164*4(O0, O1, O2, O3) 샘플이 있으며 각각 5개의 키가 있습니다.
task_id : 문제의 ID를 나타냅니다.type : 최적화 단계로 [O0, O1, O2, O3] 중 하나입니다.c_func : HumanEval 문제에 대한 C 솔루션입니다.c_test : C 테스트 어설션.input_asm_prompt : 프롬프트가 포함된 어셈블리 지침은 전처리 예제에서와 같이 파생될 수 있습니다.평가 스크립트를 확인하세요.
이 코드 저장소는 MIT 및 DeepSeek 라이선스에 따라 라이선스가 부여됩니다.
@misc{tan2024llm4decompile,
title={LLM4Decompile: Decompiling Binary Code with Large Language Models},
author={Hanzhuo Tan and Qi Luo and Jing Li and Yuqun Zhang},
year={2024},
eprint={2403.05286},
archivePrefix={arXiv},
primaryClass={cs.PL}
}


