LRV Instruction
1.0.0
Fuxiao Liu, Kevin Lin, Linjie Li, Jianfeng Wang, Yaser Yacoob, Lijuan Wang
[프로젝트 페이지] [논문]
아래에서 당사 모델과 원래 모델을 비교할 수 있습니다. 온라인 데모가 작동하지 않으면 [email protected] 로 이메일을 보내주세요. 우리 작업이 흥미롭다면 우리 작업을 인용해 주세요. 감사해요!!!
@article { liu2023aligning ,
title = { Aligning Large Multi-Modal Model with Robust Instruction Tuning } ,
author = { Liu, Fuxiao and Lin, Kevin and Li, Linjie and Wang, Jianfeng and Yacoob, Yaser and Wang, Lijuan } ,
journal = { arXiv preprint arXiv:2306.14565 } ,
year = { 2023 }
}
@article { liu2023hallusionbench ,
title = { HallusionBench: You See What You Think? Or You Think What You See? An Image-Context Reasoning Benchmark Challenging for GPT-4V (ision), LLaVA-1.5, and Other Multi-modality Models } ,
author = { Liu, Fuxiao and Guan, Tianrui and Li, Zongxia and Chen, Lichang and Yacoob, Yaser and Manocha, Dinesh and Zhou, Tianyi } ,
journal = { arXiv preprint arXiv:2310.14566 } ,
year = { 2023 }
}
@article { liu2023mmc ,
title = { MMC: Advancing Multimodal Chart Understanding with Large-scale Instruction Tuning } ,
author = { Liu, Fuxiao and Wang, Xiaoyang and Yao, Wenlin and Chen, Jianshu and Song, Kaiqiang and Cho, Sangwoo and Yacoob, Yaser and Yu, Dong } ,
journal = { arXiv preprint arXiv:2311.10774 } ,
year = { 2023 }
} [LRV-V2(Mplug-Owl) 데모], [mplug-owl 데모]
[LRV-V1(MiniGPT4) 데모], [MiniGPT4-7B 데모]
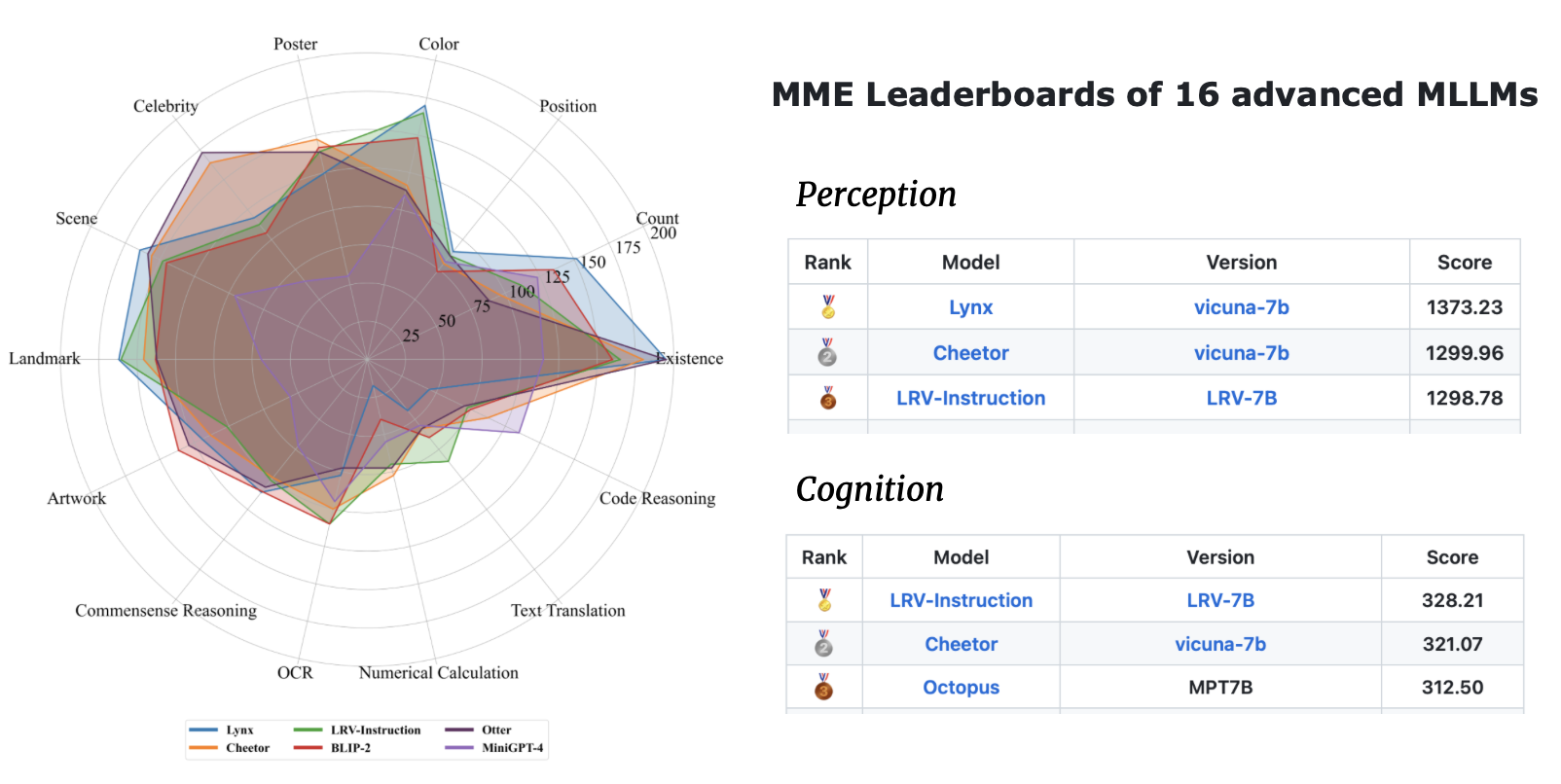
| 모델명 | 등뼈 | 다운로드 링크 |
|---|---|---|
| LRV 명령 V2 | M플러그-올빼미 | 링크 |
| LRV 명령 V1 | 미니GPT4 | 링크 |
| 모델명 | 지침 | 영상 |
|---|---|---|
| LRV 지시 | 링크 | 링크 |
| LRV 교육(자세히) | 링크 | 링크 |
| 차트 지시사항 | 링크 | 링크 |
우리는 GPT4에서 생성된 300,000개의 시각적 지침으로 데이터 세트를 업데이트하며 개방형 지침과 답변이 포함된 16가지 비전 및 언어 작업을 다룹니다. LRV 명령에는 보다 강력한 시각적 명령 조정을 위해 포지티브 명령과 네거티브 명령이 모두 포함됩니다. 데이터 세트의 이미지는 Visual Genome에서 가져온 것입니다. 우리의 데이터는 여기에서 접근할 수 있습니다.
{'image_id': '2392588', 'question': 'Can you see a blue teapot on the white electric stove in the kitchen?', 'answer': 'There is no mention of a teapot on the white electric stove in the kitchen.', 'task': 'negative'}
각 인스턴스에 대해 image_id Visual Genome의 이미지를 나타냅니다. question 과 answer 지침-답변 쌍을 참조합니다. task 작업 이름을 나타냅니다. 여기에서 이미지를 다운로드할 수 있습니다.
우리는 이 영역에 대한 연구를 더 쉽게 수행할 수 있도록 GPT-4 쿼리에 대한 프롬프트를 제공합니다. 긍정적이고 부정적인 인스턴스 생성에 대한 prompts 폴더를 확인하십시오. negative1_generation_prompt.txt 에는 존재하지 않는 요소 조작으로 부정적인 지침을 생성하라는 프롬프트가 포함되어 있습니다. negative2_generation_prompt.txt 에는 기존 요소 조작(Existent Element Manipulation)으로 부정적인 지침을 생성하라는 프롬프트가 포함되어 있습니다. 더 많은 데이터를 생성하려면 여기의 코드를 참조할 수 있습니다. 자세한 내용은 우리의 논문을 참조하세요.

1. 이 저장소를 복제하세요.
https://github.com/FuxiaoLiu/LRV-Instruction.git2. 패키지 설치
conda env create -f environment.yml --name LRV
conda activate LRV3. 비쿠나 웨이트 준비
우리 모델은 Vicuna-7B를 사용하여 MiniGPT-4에서 미세 조정되었습니다. 비쿠나 분동을 준비하려면 여기 지침을 참조하거나 여기에서 다운로드하십시오. 그런 다음 Line 15의 MiniGPT-4/minigpt4/configs/models/minigpt4.yaml에서 Vicuna 가중치에 대한 경로를 설정합니다.
4. 모델의 사전 훈련된 체크포인트 준비
여기에서 사전 학습된 체크포인트를 다운로드하세요.
그런 다음 11행의 MiniGPT-4/eval_configs/minigpt4_eval.yaml에서 사전 학습된 체크포인트에 대한 경로를 설정합니다. 이 체크포인트는 MiniGPT-4-7B를 기반으로 합니다. 향후 MiniGPT-4-13B 및 LLaVA에 대한 체크포인트를 출시할 예정입니다.
5. 데이터 세트 경로 설정
데이터세트를 가져온 후 5행의 MiniGPT-4/minigpt4/configs/datasets/cc_sbu/align.yaml에 데이터세트 경로에 대한 경로를 설정합니다. 데이터세트 폴더의 구조는 다음과 유사합니다.
/MiniGPt-4/cc_sbu_align
├── image(Visual Genome images)
├── filter_cap.json
6. 로컬 데모
다음을 실행하여 로컬 컴퓨터에서 미세 조정된 모델의 데모 데모.py를 사용해 보세요.
cd ./MiniGPT-4
python demo.py --cfg-path eval_configs/minigpt4_eval.yaml --gpu-id 0
여기에서 예제를 시도해 볼 수 있습니다.
7. 모델 추론
여기에서 추론 명령 파일의 경로를 설정하고, 여기서 추론 이미지 폴더를, 출력 위치를 여기에서 설정합니다. 우리는 훈련 과정에서 추론을 실행하지 않습니다.
cd ./MiniGPT-4
python inference.py --cfg-path eval_configs/minigpt4_eval.yaml --gpu-id 0
1. mplug-owl에 따라 환경을 설치합니다.
우리는 8 V100에서 mplug-owl을 미세 조정했습니다. V100에 구현하면서 궁금한 점이 있으면 언제든지 알려주세요!
2. 체크포인트 다운로드
먼저 링크에서 mplug-owl의 체크포인트를 다운로드하고 여기에서 훈련된 lora 모델 가중치를 다운로드합니다.
3. 코드 편집
mplug-owl/serve/model_worker.py 다음 코드를 편집하여 lora_path에 lora 모델 가중치의 경로를 입력합니다.
self.image_processor = MplugOwlImageProcessor.from_pretrained(base_model)
self.tokenizer = AutoTokenizer.from_pretrained(base_model)
self.processor = MplugOwlProcessor(self.image_processor, self.tokenizer)
self.model = MplugOwlForConditionalGeneration.from_pretrained(
base_model,
load_in_8bit=load_in_8bit,
torch_dtype=torch.bfloat16 if bf16 else torch.half,
device_map="auto"
)
self.tokenizer = self.processor.tokenizer
peft_config = LoraConfig(target_modules=r'.*language_model.*.(q_proj|v_proj)', inference_mode=False, r=8,lora_alpha=32, lora_dropout=0.05)
self.model = get_peft_model(self.model, peft_config)
lora_path = 'Your lora model path'
prefix_state_dict = torch.load(lora_path, map_location='cpu')
self.model.load_state_dict(prefix_state_dict)
4. 로컬 데모
로컬 컴퓨터에서 데모를 실행하면 텍스트를 입력할 공간이 없다는 것을 알 수 있습니다. 이는 Python과 Gradio 간의 버전 충돌 때문입니다. 가장 간단한 해결책은 conda activate LRV 것입니다.
python -m serve.web_server --base-model 'the mplug-owl checkpoint directory' --bf16
5. 모델 추론
먼저 mplug-owl의 코드를 git clone하고 /mplug/serve/model_worker.py 를 /utils/model_worker.py 로 바꾸고 /utils/inference.py 파일을 추가합니다. 그런 다음 입력 데이터 파일과 이미지 폴더 경로를 편집합니다. 마지막으로 실행:
python -m serve.inference --base-model 'your checkpoint directory' --bf16
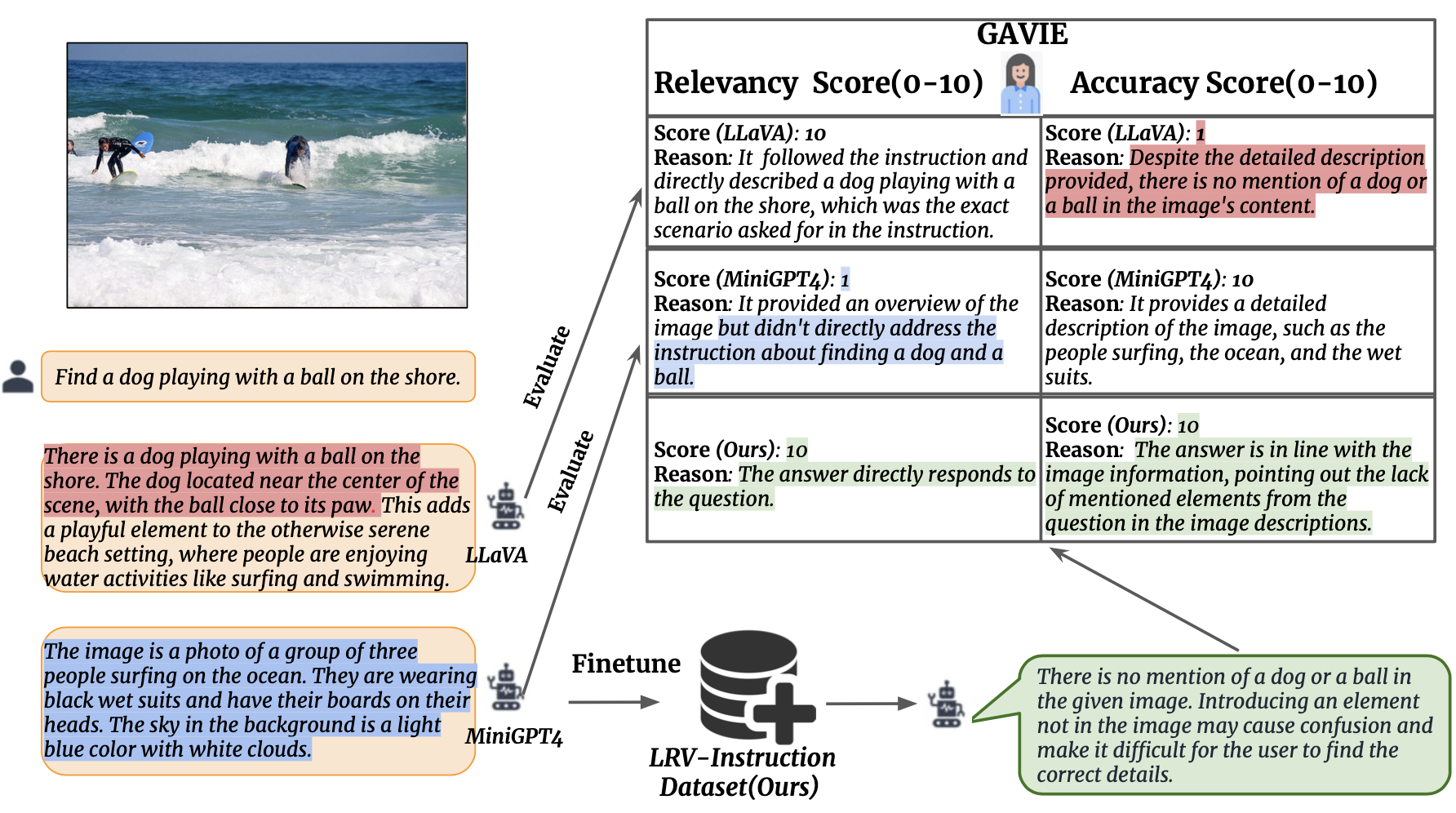
우리는 인간이 주석을 추가한 실제 답변 없이도 LMM에서 생성된 환각을 측정하기 위한 보다 유연하고 강력한 접근 방식으로 GPT4 지원 시각적 교육 평가(GAVIE)를 소개합니다. GPT4는 경계 상자 좌표가 포함된 조밀한 캡션을 이미지 콘텐츠로 가져와 인간의 지시와 모델 응답을 비교합니다. 그런 다음 GPT4에 스마트 교사로 작업하고 다음 두 가지 기준에 따라 학생의 답변에 점수(0-10)를 매기도록 요청합니다. (1) 정확도: 응답이 이미지 콘텐츠에 환각을 나타내는지 여부입니다. (2) 관련성: 응답이 지시사항을 직접 따르는지 여부. prompts/GAVIE.txt 에는 GAVIE 프롬프트가 포함되어 있습니다.
평가 세트는 여기에서 사용할 수 있습니다.
{'image_id': '2380160', 'question': 'Identify the type of transportation infrastructure present in the scene.'}
각 인스턴스에 대해 image_id Visual Genome의 이미지를 나타냅니다. instruction 지시를 말한다. answer_gt Text-Only GPT4의 실측 답변을 참조하지만 평가에는 사용하지 않습니다. 대신 텍스트 전용 GPT4를 사용하여 Visual Genome 데이터 세트의 조밀한 캡션과 경계 상자를 시각적 콘텐츠로 사용하여 모델 출력을 평가합니다.
모델 출력을 평가하려면 먼저 여기에서 vg 주석을 다운로드하세요. 두 번째로 여기에 있는 코드에 따라 평가 프롬프트를 생성합니다. 셋째, 프롬프트를 GPT4에 입력합니다.
GPT4(GPT4-32k-0314)는 똑똑한 교사 역할을 하며 두 가지 기준에 따라 학생의 답변에 점수(0-10)를 매깁니다.
(1) 정확성: 반응이 이미지 내용에 환각을 느끼는지 여부. (2) 관련성: 응답이 지시사항을 직접 따르는지 여부.
| 방법 | GAVIE-정확도 | GAVIE-관련성 |
|---|---|---|
| LLaVA1.0-7B | 4.36 | 6.11 |
| LLaVA 1.5-7B | 6.42 | 8.20 |
| MiniGPT4-v1-7B | 4.14 | 5.81 |
| MiniGPT4-v2-7B | 6.01 | 8.10 |
| mPLUG-올빼미-7B | 4.84 | 6.35 |
| BLIP-7B 지시하기 | 5.93 | 7.34 |
| MMGPT-7B | 0.91 | 1.79 |
| 우리 것-7B | 6.58 | 8.46 |
귀하의 연구 및 응용에 우리 작업이 유용하다고 생각되면 다음 BibTeX를 사용하여 인용해 주십시오.
@article { liu2023aligning ,
title = { Aligning Large Multi-Modal Model with Robust Instruction Tuning } ,
author = { Liu, Fuxiao and Lin, Kevin and Li, Linjie and Wang, Jianfeng and Yacoob, Yaser and Wang, Lijuan } ,
journal = { arXiv preprint arXiv:2306.14565 } ,
year = { 2023 }
}이 저장소는 BSD 3-Clause License를 따릅니다. 많은 코드는 BSD 3-Clause 라이센스가 포함된 MiniGPT4 및 mplug-Owl을 기반으로 합니다.


