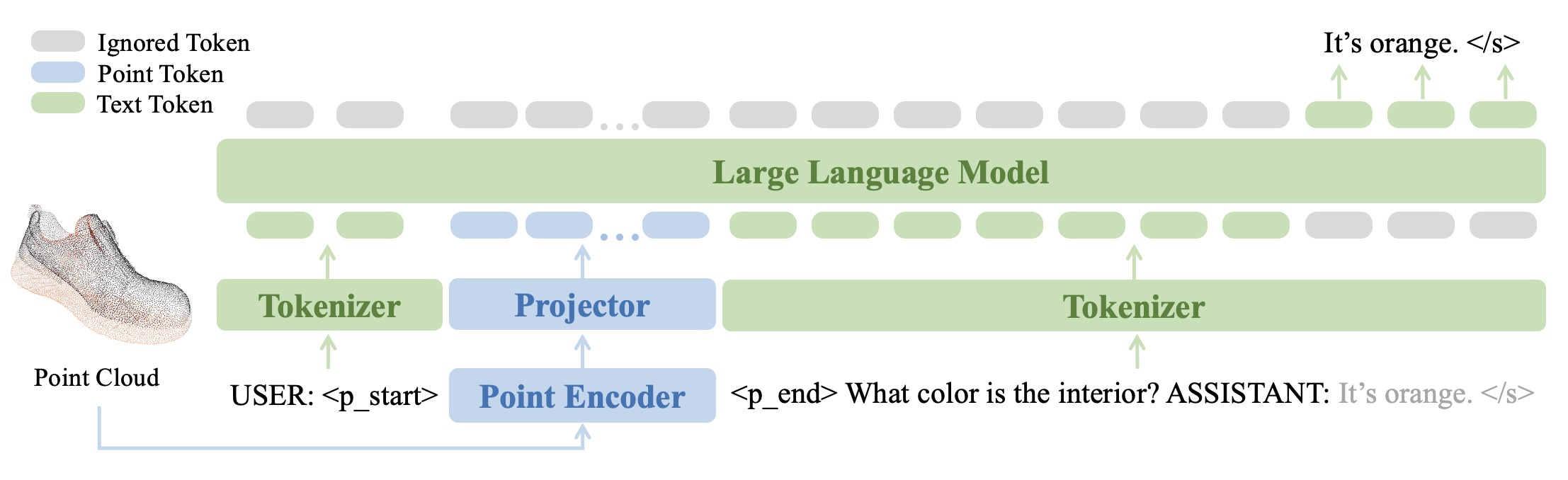
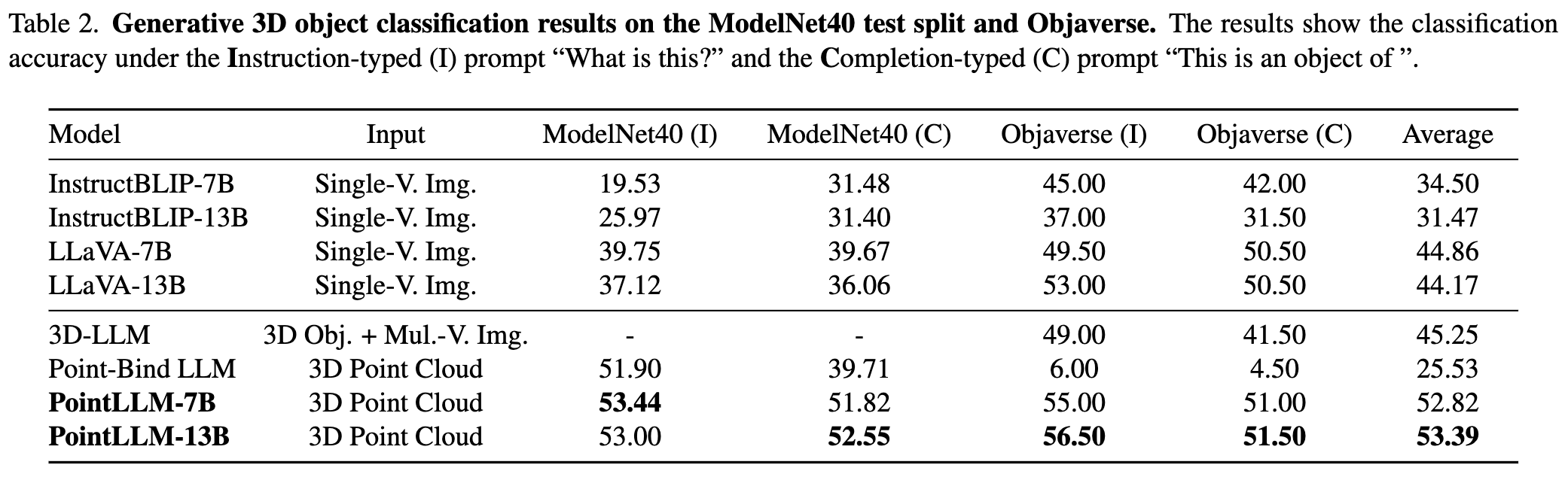
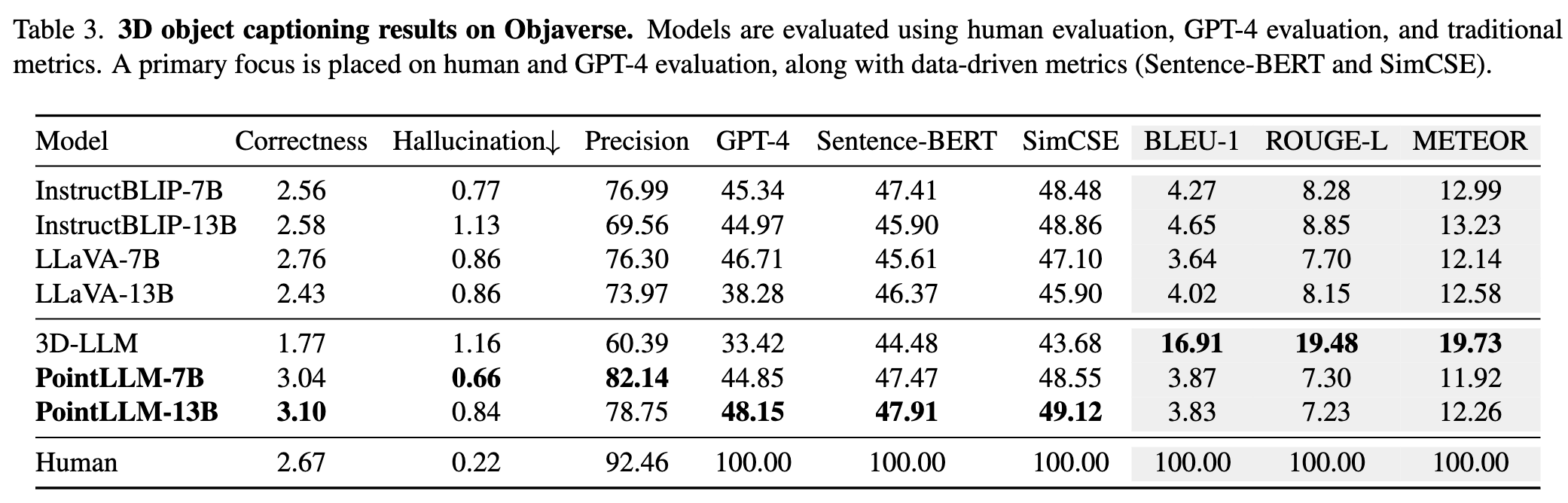
PointLLM
1.0.0
 PointLLM: 포인트 클라우드를 이해하기 위한 대규모 언어 모델 지원
PointLLM: 포인트 클라우드를 이해하기 위한 대규모 언어 모델 지원 Runsen Xu Xiaolong Wang Tai Wang Yilun Chen Jiangmiao Pang* Dahua Lin
홍콩중문대학교 상하이 AI 연구소 저장대학교

PointLLM이 온라인 상태입니다! http://101.230.144.196 또는 OpenXLab/PointLLM에서 사용해 보세요.
Objaverse 데이터 세트의 모델이나 자신의 포인트 클라우드에 대해 PointLLM과 대화할 수 있습니다!
피드백이 있으면 주저하지 말고 알려주시기 바랍니다! ?
| 대화 1 | 대화 2 | 대화 3 | 대화 4 |
|---|---|---|---|
 |  |  |  |
더 많은 결과를 보려면 우리의 논문을 참조하세요.
더 많은 결과를 보려면 우리의 논문을 참조하세요.

우리는 다음 환경에서 코드를 테스트합니다.
시작하려면:
git clone [email protected]:OpenRobotLab/PointLLM.git
cd PointLLMconda create -n pointllm python=3.10 -y
conda activate pointllm
pip install --upgrade pip # enable PEP 660 support
pip install -e .
# * for training
pip install ninja
pip install flash-attn{Objaverse_ID}_8192.npy 라는 660K 포인트 클라우드 파일이 포함된 8192_npy 라는 폴더가 생성됩니다. 각 파일은 차원(8192, 6)을 갖는 numpy 배열입니다. 여기서 처음 3개 차원은 xyz 이고 마지막 3개 차원은 [0, 1] 범위의 rgb 입니다. cat Objaverse_660K_8192_npy_split_a * > Objaverse_660K_8192_npy.tar.gz
tar -xvf Objaverse_660K_8192_npy.tar.gzPointLLM 폴더에서 data 폴더를 생성하고 디렉터리에 압축되지 않은 파일에 대한 소프트 링크를 생성합니다. cd PointLLM
mkdir data
ln -s /path/to/8192_npy data/objaverse_dataPointLLM/data 폴더에 anno_data 라는 디렉터리를 만듭니다.anno_data 디렉터리에 데이터 파일을 넣습니다. 디렉토리는 다음과 같아야 합니다. PointLLM/data/anno_data
├── PointLLM_brief_description_660K_filtered.json
├── PointLLM_brief_description_660K.json
└── PointLLM_complex_instruction_70K.jsonPointLLM_brief_description_660K_filtered.json 유효성 검사 세트로 예약한 3000개 개체를 제거하여 PointLLM_brief_description_660K.json 에서 필터링됩니다. 우리 논문의 결과를 재현하려면 훈련에 PointLLM_brief_description_660K_filtered.json 을 사용해야 합니다. PointLLM_complex_instruction_70K.json 에는 훈련 세트의 개체가 포함되어 있습니다.pointllm/data/data_generation/system_prompt_gpt4_0613.txt 에 있습니다. PointLLM_brief_description_val_200_GT.json 을 다운로드하여 PointLLM/data/anno_data 에 넣습니다. 또한 훈련 중에 필터링하는 3000개의 객체 ID와 여기에 해당하는 참조 GT를 제공합니다. 이는 모든 3000개의 객체를 평가하는 데 사용할 수 있습니다.PointLLM/data 에 modelnet40_data 라는 디렉터리를 만듭니다. 여기에서 ModelNet40 포인트 클라우드 modelnet40_test_8192pts_fps.dat 의 테스트 분할을 다운로드하여 PointLLM/data/modelnet40_data 에 저장하세요.PointLLM 폴더에 checkpoints 라는 디렉터리를 만듭니다.checkpoints 디렉터리에 넣으세요. cd PointLLM
scripts/PointLLM_train_stage1.shscripts/PointLLM_train_stage2.sh일반적으로 다음 내용은 신경쓰지 않으셔도 됩니다. 이는 v1 논문(PointLLM-v1.1)의 결과를 재현하기 위한 것입니다. 우리 모델과 비교하고 싶거나 다운스트림 작업에 우리 모델을 사용하려면 더 나은 성능을 제공하는 PointLLM-v1.2(v2 문서 참조)를 사용하세요.
PointLLM v1.1과 v1.2는 약간 다른 사전 학습된 포인트 인코더와 프로젝터를 사용합니다. PointLLM v1.1을 재현하려면 초기 LLM 및 포인트 인코더 가중치 디렉터리에서 config.json 파일을 편집합니다(예: vim checkpoints/PointLLM_7B_v1.1_init/config.json .
다른 포인트 인코더 구성을 지정하려면 "point_backbone_config_name" 키를 변경하세요.
# change from
" point_backbone_config_name " : " PointTransformer_8192point_2layer " # v1.2
# to
" point_backbone_config_name " : " PointTransformer_base_8192point " , # v1.1 scripts/train_stage1.sh 에서 포인트 인코더의 체크포인트 경로를 편집합니다.
# change from
point_backbone_ckpt= $model_name_or_path /point_bert_v1.2.pt # v1.2
# to
point_backbone_ckpt= $model_name_or_path /point_bert_v1.1.pt # v1.1torch.float32 데이터 유형을 사용하여 챗봇을 시작하려면 다음 명령을 실행하십시오. 모델 체크포인트가 자동으로 다운로드됩니다. 모델 체크포인트를 수동으로 다운로드하고 해당 경로를 지정할 수도 있습니다. 예는 다음과 같습니다. cd PointLLM
PYTHONPATH= $PWD python pointllm/eval/PointLLM_chat.py --model_name RunsenXu/PointLLM_7B_v1.2 --data_name data/objaverse_data --torch_dtype float32 모델에 입력된 포인트 클라우드에 차원(N, 6)이 있는 한, Objaverse의 포인트 클라우드 이외의 포인트 클라우드를 사용하기 위한 코드를 쉽게 수정할 수도 있습니다. 여기서 처음 3차원은 xyz 이고 마지막 3차원은 rgb ( [0, 1] 범위). 우리 모델은 이러한 포인트 클라우드에 대해 훈련되었으므로 포인트 클라우드를 샘플링하여 8192개의 포인트를 가질 수 있습니다.
다음 표에는 다양한 모델 및 데이터 유형에 대한 GPU 요구 사항이 나와 있습니다. 해당되는 경우 우리 논문의 실험에 사용되는 torch.bfloat16 사용하는 것이 좋습니다.
| 모델 | 데이터 유형 | GPU 메모리 |
|---|---|---|
| 포인트LLM-7B | 토치.float16 | 14GB |
| 포인트LLM-7B | 토치.float32 | 28GB |
| 포인트LLM-13B | 토치.float16 | 26GB |
| 포인트LLM-13B | 토치.float32 | 52GB |
cd PointLLM
PYTHONPATH= $PWD python pointllm/eval/chat_gradio.py --model_name RunsenXu/PointLLM_7B_v1.2 --data_name data/objaverse_data cd PointLLM
export PYTHONPATH= $PWD
# Open Vocabulary Classification on Objaverse
python pointllm/eval/eval_objaverse.py --model_name RunsenXu/PointLLM_7B_v1.2 --task_type classification --prompt_index 0 # or --prompt_index 1
# Object captioning on Objaverse
python pointllm/eval/eval_objaverse.py --model_name RunsenXu/PointLLM_7B_v1.2 --task_type captioning --prompt_index 2
# Close-set Zero-shot Classification on ModelNet40
python pointllm/eval/eval_modelnet_cls.py --model_name RunsenXu/PointLLM_7B_v1.2 --prompt_index 0 # or --prompt_index 1{model_name}/evaluation 에 저장됩니다. {
" prompt " : " " ,
" results " : [
{
" object_id " : " " ,
" ground_truth " : " " ,
" model_output " : " " ,
" label_name " : " " # only for classification on modelnet40
}
]
} cd PointLLM
export PYTHONPATH= $PWD
export OPENAI_API_KEY=sk- ****
# Open Vocabulary Classification on Objaverse
python pointllm/eval/evaluator.py --results_path /path/to/model_output --model_type gpt-4-0613 --eval_type open-free-form-classification --parallel --num_workers 15
# Object captioning on Objaverse
python pointllm/eval/evaluator.py --results_path /path/to/model_output --model_type gpt-4-0613 --eval_type object-captioning --parallel --num_workers 15
# Close-set Zero-shot Classification on ModelNet40
python pointllm/eval/evaluator.py --results_path /path/to/model_output --model_type gpt-3.5-turbo-0613 --eval_type modelnet-close-set-classification --parallel --num_workers 15Ctrl+C 사용하면 언제든지 평가 프로세스를 중단할 수 있습니다. 그러면 임시 결과가 저장됩니다. 평가 중에 오류가 발생하면 스크립트는 현재 상태도 저장합니다. 동일한 명령을 다시 실행하여 중단된 부분부터 평가를 재개할 수 있습니다.{model_name}/evaluation 에 또 다른 dict로 저장됩니다. 일부 측정항목은 다음과 같이 설명됩니다. " average_score " : The GPT-evaluated captioning score we report in our paper.
" accuracy " : The classification accuracy we report in our paper, including random choices made by ChatGPT when model outputs are vague or ambiguous and ChatGPT outputs " INVALID " .
" clean_accuracy " : The classification accuracy after removing those " INVALID " outputs.
" total_predictions " : The number of predictions.
" correct_predictions " : The number of correct predictions.
" invalid_responses " : The number of " INVALID " outputs by ChatGPT.
# Some other statistics for calling OpenAI API
" prompt_tokens " : The total number of tokens of the prompts for ChatGPT/GPT-4.
" completion_tokens " : The total number of tokens of the completion results from ChatGPT/GPT-4.
" GPT_cost " : The API cost of the whole evaluation process, in US Dollars ?.--start_eval 플래그를 전달하고 --gpt_type 을 지정하여 추론 후 즉시 평가를 시작할 수도 있습니다. 예를 들어: python pointllm/eval/eval_objaverse.py --model_name RunsenXu/PointLLM_7B_v1.2 --task_type classification --prompt_index 0 --start_eval --gpt_type gpt-4-0613python pointllm/eval/traditional_evaluator.py --results_path /path/to/model_captioning_output커뮤니티 기여를 환영합니다!? 지원이 필요한 경우 언제든지 문제를 공개하거나 당사에 문의해 주세요.
우리 작업과 이 코드베이스가 도움이 된다면 이 저장소에 별표를 표시해 보세요. 그리고 인용:
@inproceedings { xu2024pointllm ,
title = { PointLLM: Empowering Large Language Models to Understand Point Clouds } ,
author = { Xu, Runsen and Wang, Xiaolong and Wang, Tai and Chen, Yilun and Pang, Jiangmiao and Lin, Dahua } ,
booktitle = { ECCV } ,
year = { 2024 }
}
이 저작물은 크리에이티브 커먼즈 저작자표시-비영리-동일조건변경허락 4.0 국제 라이선스를 따릅니다.
함께 3D용 LLM을 훌륭하게 만들어 봅시다!


