gptty
0.2.7
TTY의 ChatGPT 래퍼
메모
이 버전은 gpt4 및 gpt4-turbo를 지원합니다!
gptty는 (1) 웹 애플리케이션과 유사한 방식으로 ChatGPT와 상호 작용하지만 웹 애플리케이션의 안정성에 의존할 필요 없이; (2) 채팅 세션 전체에서 컨텍스트를 유지하고 원하는 대로 대화를 구성합니다. (3) 쉽게 참조할 수 있도록 대화의 로컬 사본을 저장하십시오.
아마도 당신은 고용주를 위해 웹 서버를 구성하는 시스템 관리자일 것입니다. 인터넷에 연결되어 있지만 데스크톱 환경이나 그래픽 사용자 인터페이스가 없는 물리적 인터페이스에서 시스템에 액세스하고 있습니다. 웹 서버를 구성하는 동안 파일로 리디렉션되는 설명할 수 없는 오류가 발생하지만 오류를 조회하기 위해 브라우저를 사용하여 다른 시스템에 파일을 복사하기 위해 수고를 하고 싶지는 않습니다. 대신 gptty를 설치하고 gptty query --tag error --question "$(cat app.error | tr 'n' ' ')" (줄 바꿈을 제거함)과 같은 명령을 사용하여 오류를 채팅 클라이언트로 리디렉션합니다. 당신을 위해) 또는 cat app.error | xargs -d 'n' -I {} gptty query --tag error --question "{}" (오류가 한 줄에만 걸쳐 있다고 가정합니다).
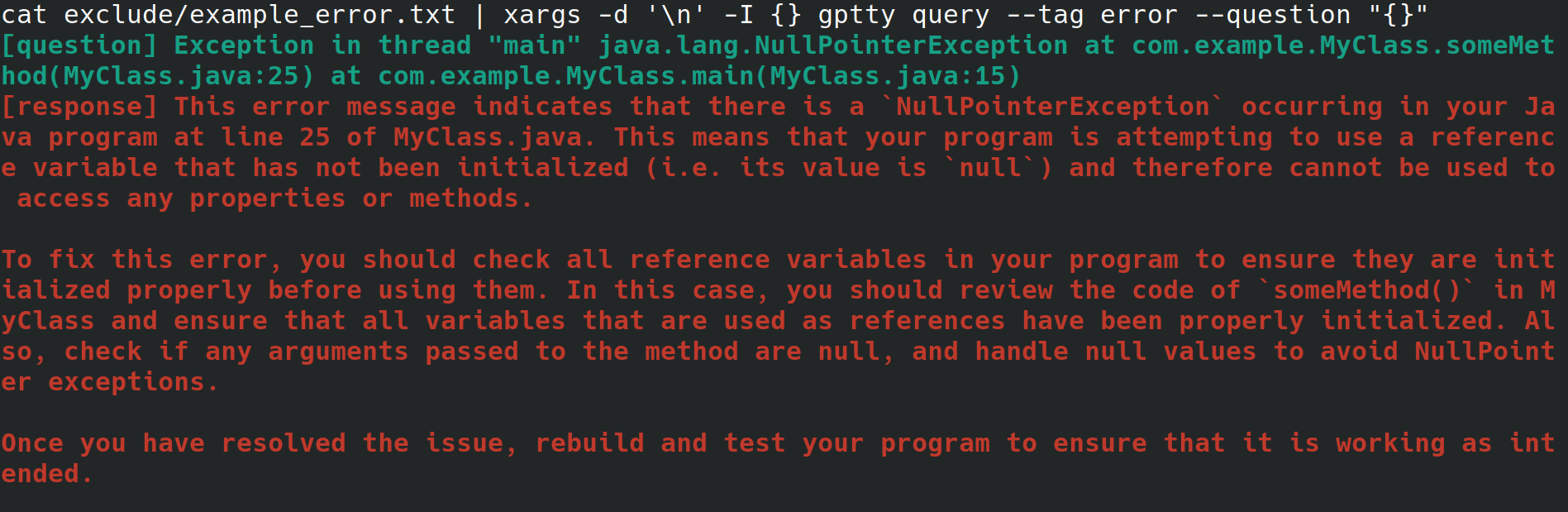
또는 ChatGPT를 통해 데이터를 파이프하고 싶지만 OpenAI API 및 다양한 언어별 래퍼에 익숙해지는 대신 매우 추상적인 API를 사용하여 이러한 요청을 수행하려는 소프트웨어 개발자 또는 데이터 과학자입니다. 다른 모델을 사용하도록 코드 베이스를 업데이트하려는 경우 단일 구성 파일만 수정하고 쿼리 응답 형식이 다양한 모델에서 일관되게 유지되기를 원할 수 있습니다.
또는 대화의 로컬 복사본을 보관하고 싶거나 이러한 대화에 사용하는 분류 방법을 보다 직접적으로 제어하려는 열성팬일 수도 있습니다.
OpenAI는 API를 통해 다양한 모델을 제공합니다. [1] 현재 gptty는 Completions (davinci, curie) 및 ChatCompletions (gpt-3.5-turbo, gpt-4)를 지원합니다. 구성에서 모델 이름을 지정하기만 하면(기본값은 text-davinci-003) 애플리케이션이 나머지를 처리합니다.
pip에 gptty 설치할 수 있습니다.
pip install gptty
git에서 설치할 수도 있습니다:
cd ~/Code # replace this with whatever directory you want to use
git clone https://github.com/signebedi/gptty.git
cd gptty/
# now install the requirements
python3 -m venv venv
source venv/bin/activate
pip install -e .
이제 gptty --help 실행하여 작동하는지 확인할 수 있습니다. 오류가 발생하면 앱을 구성해 보세요.
gptty gptty.ini 라는 파일에서 구성 설정을 읽습니다. 앱은 사용자 정의 config_file 전달하지 않는 한 gptty 실행 중인 동일한 디렉터리에 있을 것으로 예상합니다. 이 파일은 각각 고유한 키-값 쌍이 있는 섹션으로 구성된 INI 파일 형식을 사용합니다.
| 열쇠 | 유형 | 기본값 | 설명 |
|---|---|---|---|
| api_key | 끈 | "" | OpenAI GPT 서비스용 API 키 |
| 조직 ID | 끈 | "" | OpenAI GPT 서비스의 조직 ID |
| 너의_이름 | 끈 | "질문" | 입력 프롬프트의 이름 |
| gpt_name | 끈 | "응답" | 생성된 응답의 이름 |
| 출력_파일 | 끈 | "출력.txt" | 출력이 저장될 파일의 이름 |
| 모델 | 끈 | "텍스트-다빈치-003" | 사용할 GPT 모델의 이름 |
| 온도 | 뜨다 | 0.0 | 샘플링에 사용할 온도 |
| max_tokens | 정수 | 250 | 응답을 위해 생성할 최대 토큰 수 |
| 최대_컨텍스트_길이 | 정수 | 150 | 입력 컨텍스트의 최대 길이 |
| context_keywords_only | 부울 | 진실 | API 사용량을 줄이기 위해 키워드를 토큰화하세요. |
| 보존_새_라인 | 부울 | 거짓 | 응답의 원래 형식을 유지하세요. |
| verify_internet_endpoint | 끈 | "google.com" | 인터넷 연결을 확인할 주소 |
필요에 맞게 구성 파일의 설정을 수정할 수 있습니다. 구성 파일에 키가 없으면 기본값이 사용됩니다. [main] 섹션은 프로그램 설정을 지정하는 데 사용됩니다.
[main]
api_key =my_api_key 이 리포지토리는 시작점으로 사용할 수 있는 샘플 구성 파일 assets/gptty.ini.example 제공합니다.
채팅 기능은 ChatGPT와 통신할 수 있는 대화형 채팅 인터페이스를 제공합니다. 실시간으로 질문하고 답변을 받을 수 있습니다.
채팅 인터페이스를 시작하려면 gptty chat 실행하세요. 다음을 실행하여 사용자 정의 구성 파일 경로를 지정할 수도 있습니다.
gptty chat --config_path /path/to/your/gptty.ini
채팅 인터페이스 내에서 질문이나 명령을 직접 입력할 수 있습니다. 사용 가능한 명령 목록을 보려면 :help 입력하세요. 그러면 다음 옵션이 표시됩니다.
| 메타명령 | 설명 |
|---|---|
| :돕다 | 사용 가능한 명령 목록과 해당 설명을 표시합니다. |
| :그만두다 | ChatGPT를 종료합니다. |
| :로그 | 현재 구성 설정을 표시합니다. |
| :컨텍스트[a:b] | 선택적으로 범위 a 및 b를 지정하여 컨텍스트 기록을 표시합니다. 개발중 |
명령을 사용하려면 명령 프롬프트에 명령을 입력하고 Enter를 누르기만 하면 됩니다. 예를 들어, 다음 명령을 사용하여 터미널의 현재 구성 설정을 표시합니다.
> :configs
api_key: SOME_KEY_HERE
org_id: org-SOME_CHARS_HERE
your_name: question
gpt_name: response
output_file: output.txt
model: text-davinci-003
temperature: 0.0
max_tokens: 250
max_context_length: 5000
언제든지 프롬프트에 질문을 입력하면 응답이 생성됩니다. 쿼리 간에 컨텍스트를 공유하려면 아래 컨텍스트 섹션을 참조하세요.
쿼리 기능을 사용하면 하나 또는 여러 개의 질문을 ChatGPT에 제출하고 명령줄에서 직접 답변을 받을 수 있습니다.
쿼리 기능을 사용하려면 다음과 같이 실행하세요.
gptty query --question "What is the capital of France?" --question "What is the largest mammal?"
쿼리를 분류하기 위해 선택적 태그를 제공할 수도 있습니다.
gptty query --question "What is the capital of France?" --tag "geography"
필요한 경우 사용자 정의 구성 파일 경로를 지정할 수 있습니다.
gptty query --config_path /path/to/your/gptty.ini --question "What is the capital of France?"
gptty는 구성 파일(기본적으로 gptty.ini)을 사용하여 API 키, 모델 구성 및 출력 파일 경로와 같은 설정을 저장한다는 점을 기억하십시오. gptty 명령을 실행하기 전에 유효한 구성 파일이 있는지 확인하십시오.
채팅 및 쿼리 명령 끝에 --verbose 태그를 추가하면 애플리케이션은 각 요청에 대한 토큰 수를 포함하여 추가 디버그 데이터를 제공합니다. 이는 API 사용률을 추적해야 할 때 유용할 수 있습니다.

쿼리 명령에 --additional_context [some_string_here] 옵션을 추가하면 애플리케이션은 질문에 대한 컨텍스트 외부에서 추가로 전달하는 문자열을 추가합니다.
쿼리 명령 끝에 --json 태그를 추가하면 애플리케이션은 사람이 읽을 수 있는 텍스트를 stdout에 작성하는 것을 건너뛰고 대신 [{"question":QUESTION_1, "response":RESPONSE_1},{"question":QUESTION_1, "response":RESPONSE_1},...] 과 같은 json 개체로 질문과 응답을 작성합니다. [{"question":QUESTION_1, "response":RESPONSE_1},{"question":QUESTION_1, "response":RESPONSE_1},...] .

쿼리 명령 끝에 --quiet 태그를 추가하면 애플리케이션은 stdout에 대한 쓰기를 건너뛰지만 여전히 애플리케이션 구성 파일에 지정된 output_file 에 응답을 씁니다.
이 앱에서 chat 및 query 하위 명령을 사용할 때 컨텍스트에 대한 텍스트에 태그를 지정하면 생성된 응답의 정확성을 높이는 데 도움이 될 수 있습니다. 앱이 chat 하위 명령을 사용하여 컨텍스트를 처리하는 방법은 다음과 같습니다.
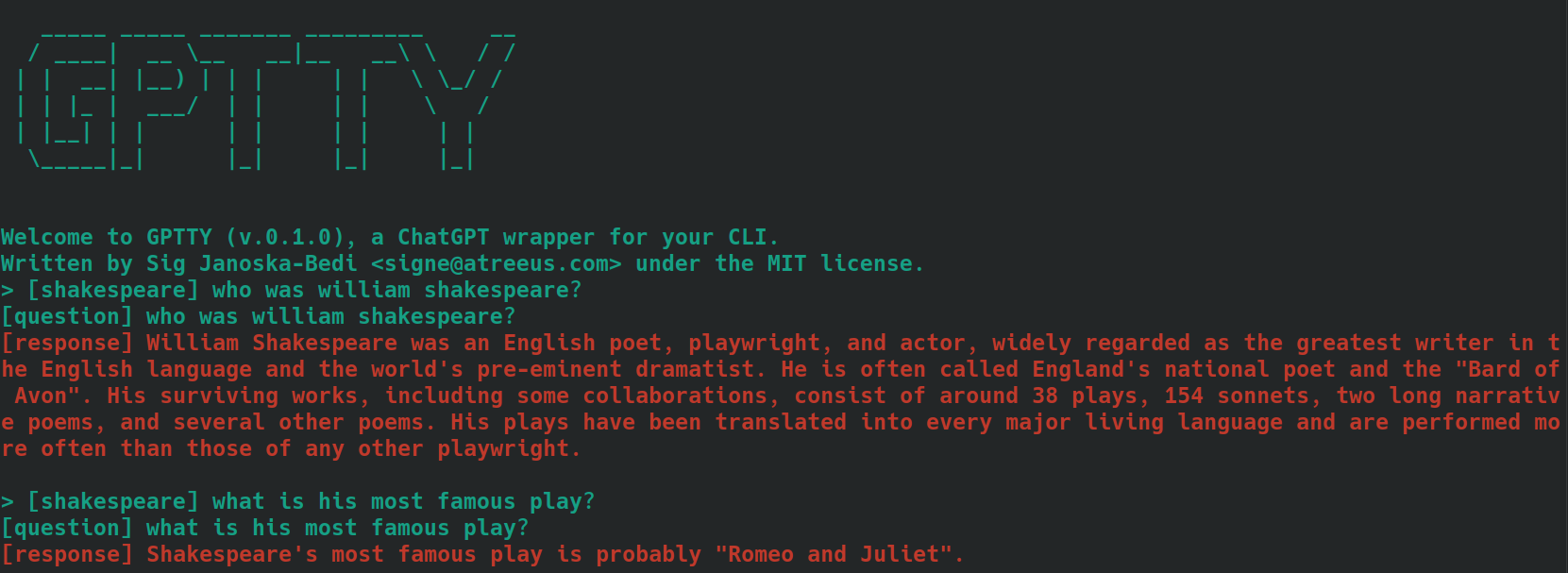
bananas 나 shakespeare 와 같이 맥락을 설명하는 단어나 짧은 문구일 수 있습니다.[tag] 접두사를 붙여 입력 메시지에 태그를 포함합니다. 예를 들어, 질문의 맥락이 '요리'인 경우 [cooking] 로 태그를 지정할 수 있습니다. 모든 관련 검색어에 동일한 태그를 일관되게 사용해야 합니다. 다음은 [shakespeare] 태그가 붙은 질문을 사용하여 이것이 어떤 모습일지 보여주는 예입니다. 두 번째 질문에서는 '윌리엄 셰익스피어'라는 이름이 전혀 언급되지 않았습니다.
query 하위 명령을 사용하는 경우 위에서 설명한 것과 동일한 단계를 따르십시오. 단, 질문 텍스트 앞에 원하는 태그를 추가하는 대신 --tag 옵션을 사용하여 쿼리를 제출할 때 태그를 포함하십시오. 예를 들어, 질문의 맥락이 '요리'인 경우 다음을 사용할 수 있습니다.
gptty --question "some question" --tag cooking
애플리케이션은 태그가 지정된 질문과 응답을 구성 파일에 지정된 출력 파일에 저장합니다.
bash 스크립트를 사용하여 gptty query 명령에 여러 질문을 보내는 프로세스를 자동화할 수 있습니다. 이는 파일에 질문 목록이 저장되어 있고 모든 질문을 한 번에 처리하려는 경우 특히 유용할 수 있습니다. 예를 들어 아래와 같이 각 질문이 새 줄에 포함된 questions.txt 파일이 있다고 가정해 보겠습니다.
What are the key differences between machine learning, deep learning, and artificial intelligence?
How do I choose the best programming language for a specific project or task?
Can you recommend some best practices for code optimization and performance improvement?
What are the essential principles of good software design and architecture?
How do I get started with natural language processing and text analysis in Python?
What are some popular Python libraries or frameworks for building web applications?
Can you suggest some resources to learn about data visualization and its implementation in Python?
What are some important concepts in cybersecurity, and how can I apply them to my projects?
How do I ensure that my machine learning models are fair, ethical, and unbiased?
Can you recommend strategies for staying up-to-date with the latest trends and advancements in technology and programming?
다음 bash one-liner를 사용하여 questions.txt 파일의 각 질문을 gptty query 명령으로 보낼 수 있습니다.
xargs -d ' n ' -I {} gptty query --question " {} " < questions.txt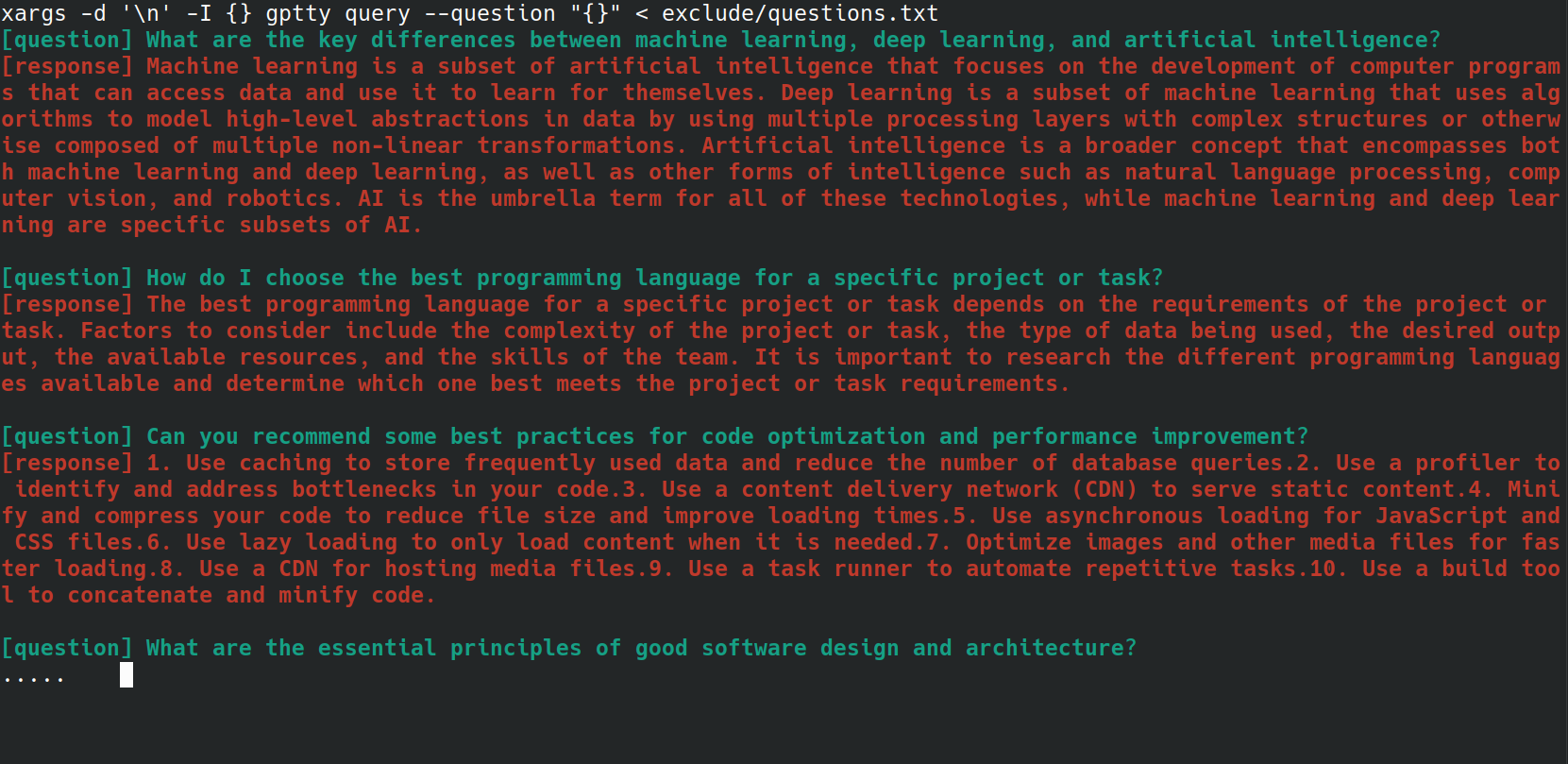
UniversalCompletion 클래스는 OpenAI의 언어 모델과 상호 작용하기 위한 통합 인터페이스를 제공하며 (대부분) 애플리케이션이 Completion 모드를 사용하는지 아니면 ChatCompletion 모드를 사용하는지에 대한 세부 사항을 추상화합니다. 주요 아이디어는 언어 모델의 생성, 구성 및 관리를 용이하게 하는 것입니다. 다음은 몇 가지 사용 예입니다.
# First, import the UniversalCompletion class from the gptty library.
from gptty import UniversalCompletion
# Now, we instantiate a new UniversalCompletion object.
# The 'api_key' parameter is your OpenAI API key, which you get when you sign up for the API.
# The 'org_id' parameter is your OpenAI organization ID, which is also provided when you sign up.
g = UniversalCompletion ( api_key = "sk-SOME_CHARS_HERE" , org_id = "org-SOME_CHARS_HERE" )
# This connects to the OpenAI API using the provided API key and organization ID.
g . connect ()
# Now we specify which language model we want to use.
# Here, 'gpt-3.5-turbo' is specified, which is a version of the GPT-3 model.
g . set_model ( 'gpt-3.5-turbo' )
# This method is used to verify the model type.
# It returns a string that represents the endpoint for the current model in use.
g . validate_model_type ( g . model ) # Returns: 'v1/chat/completions'
# We send a request to the language model here.
# The prompt is a question, given in a format that the model understands.
# The model responds with a completion - an extension of the prompt based on what it has learned during training.
# The returned object is a representation of the response from the model.
g . fetch_response ( prompt = [{ "role" : "user" , "content" : "What is an abstraction?" }])
# Returns a JSON response with the assistant's message.

