StableDiffusionEndToEndGuide
1.0.0
저는 SD를 사용하여 군사용 이미지를 생성하는 데 관심을 갖게 되었습니다. Anons는 SD를 사용하여 헨타이를 만들기 때문에 대부분의 리소스는 4chan의 NSFW 보드에서 가져옵니다. 흥미롭게도 표준 SD WebUI에는 애니메이션/헨타이 이미지 보드와 함께 기능이 내장되어 있습니다. DALL-E가 애니메이션 소녀를 생성한 직후 SD의 첫 번째 사용 사례 중 하나이므로 헨타이로의 도약은 놀라운 일이 아닙니다.
어쨌든, 이 이상한 사람들의 기술은 다양한 애플리케이션, 특히 모델 미세 조정기와 같은 LoRA에 적용 가능합니다. 아이디어는 특정 LoRA(예: 군용 차량, 항공기, 무기 등)를 사용하여 비전 모델 훈련을 위한 합성 이미지 데이터를 생성하는 것입니다. 새롭고 유용한 LoRA를 훈련하는 것도 흥미롭습니다. 나중에는 교란을 위한 인페인팅이 포함될 수 있습니다.
Every link here may contain NSFW content, as most of the cutting-edge work on SD and LoRAs is with porn or hentai. So, please be wary when you are working with these resources. ALSO, Rentry.org pages are the main resources linked to in this guide. If any of the rentry pages do not work, change the .org to .co and the link should work. Otherwise, use the Wayback machine.
-TP
실제로 SD로 무엇을 할 수 있나요? Huggingface와 일부 다른 앱에는 브라우저에 몇 가지 앱이 있습니다. 힘을 확인하기 위해 그들과 함께 놀아보세요! 이 가이드에서 우리가 할 일은 우리가 원하는 모든 것을 할 수 있도록 완전하고 확장 가능한 WebUI를 얻는 것입니다.
이 작업을 시작하는 것은 다소 어려운 일이지만... 4channers는 이 작업을 접근하기 쉽게 만드는 데 훌륭한 역할을 했습니다. 다음은 제가 취한 단계를 가장 간단한 용어로 설명합니다. 귀하의 의도는 Stable Diffusion WebUI(Gradio로 구축)를 로컬에서 실행하여 메시지를 표시하고 이미지 만들기를 시작할 수 있도록 하는 것입니다.
나중에 Google Colab Pro 설정을 수행하여 원하는 모든 장치에서 SD를 실행할 수 있습니다. 하지만 시작하려면 PC에서 WebUI를 설정해 보겠습니다. 16GB RAM, 2GB VRAM이 있는 GPU, Windows 7 이상 및 20GB 이상의 디스크 공간이 필요합니다.
127.0.0.1:7860 (이 명령은 CLI를 닫을 수 있으므로 Ctrl + C를 사용 하지 마십시오 ).stable-diffusion-webuioutputstxt2img-images<date> 에 자동으로 저장됩니다.git pull 명령을 입력하세요. 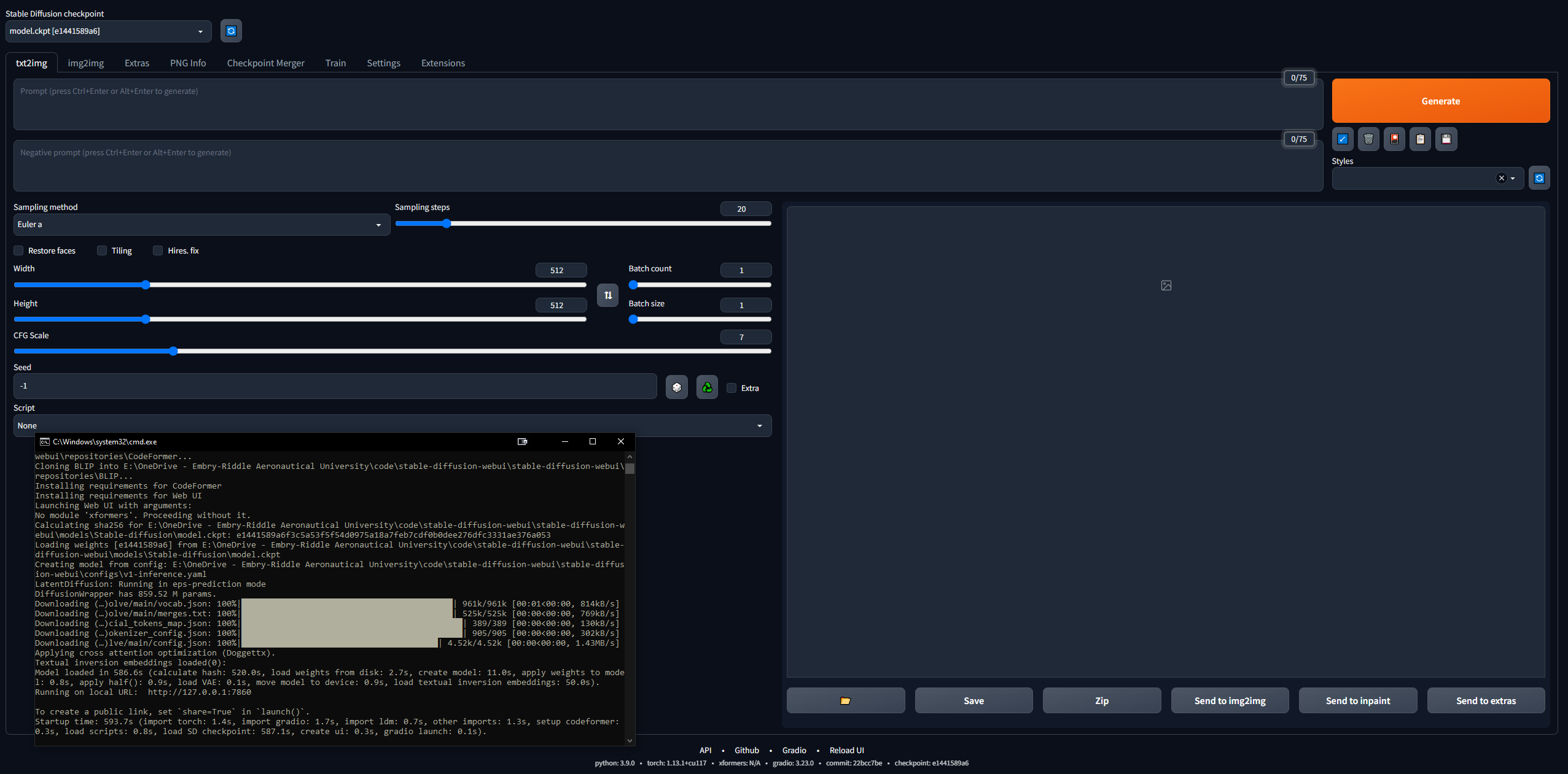
Windows를 사용하는 경우에는 이를 완전히 무시하세요. 좀 더 복잡하긴 하지만 Linux에서도 실행할 수 있었습니다. 나는 이 가이드를 따라 시작했지만 다소 형편없게 작성되었으므로 Linux에서 실행하기 위해 취한 단계는 다음과 같습니다. 저는 Ubuntu 20 배포판인 Linux Mint 20을 사용하고 있었습니다.
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.gitstable-diffusion-webui/models/Stable-diffusion 에 넣습니다.sudo apt install python3 python3-pip python3-virtualenv wget git wget https://repo.anaconda.com/miniconda/Minconda3-latest-Linux-x86_64.sh
chmod +x Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.sh
conda create --name sdwebui python=3.10.6conda activate sdwebui./webui.sh 입력하세요. sudo apt update
sudo apt purge *nvidia*
sudo add-apt-repository ppa:graphics-drivers/ppasudo apt-get update 로 업데이트sudo apt-get install nvidia-driver-530 사용하여 터미널에 설치합니다.nvidia-smi 명령을 입력하십시오. 성공하면 테이블이 인쇄됩니다. 그렇지 않은 경우 "GPU에 연결할 수 없습니다. 최신 드라이버가 설치되어 있는지 확인하십시오"와 같은 메시지가 표시됩니다. sudo apt update
sudo apt install apt-transport-https ca-certificates gnupg
sudo apt install nvidia-cuda-toolkit
nvcc-version
python3 -c 'import venv'
python3 -m venv venv/
그런 다음 /stable-diffusion-webui 폴더로 이동하여 다음을 실행합니다.
rm -rf venv/
python3 -m venv venv/
그 후에 그것은 나에게 효과적이었습니다.
프롬프트의 단어 순서는 영향을 미칩니다. 이전 단어가 우선 적용됩니다. 좋은 프롬프트의 일반적인 구조는 다음과 같습니다.
<general positives> <descriptors of subject> <descriptors of background> <post-processing, camera, etc.>
또 다른 좋은 가이드에서는 프롬프트가 다음 구조를 따라야 한다고 말합니다.
<subject> <medium> <style> <artist> <website> <resolution> <additional details> <color> <lighting>
프롬프트 엔지니어링 txt2img 모델에 대한 중요한 논문은 여기를 참조하세요. LLM 프롬프트에 대한 최종 리소스는 여기입니다.
무엇을 요청하든 프로세스가 복제 가능하도록 일종의 구조를 따르도록 노력하십시오. 다음은 필요한 프롬프트 구문 요소입니다.
1girl standing on grass in front of castle AND castle in background 기본 모델은 매우 깔끔하지만 역사상 일반적으로 그렇듯이 섹스가 대부분의 일을 주도합니다. NovelAI(NAI)는 애니메이션 중심의 SD 콘텐츠 생성 서비스로, 주요 모델이 유출되었습니다. 당신이 보는 애니메이션 남성과 여성의 SD 생성 이미지(NSFW 여부에 관계없이)의 대부분은 이 유출된 모델에서 나온 것입니다.
어쨌든 사람을 생성하는 데는 정말 효과적이며 병합을 통해 플레이할 대부분의 모델이나 LoRA는 애니메이션 이미지에 대해 교육을 받았기 때문에 호환됩니다. 또한 인간은 전문적인 목적으로 사용하려는 LoRA를 정확히 미세 조정하기 위한 정말 좋은 시작 사용 사례를 제시합니다. 문제 해결을 많이 하게 될 것이며 대부분의 가이드는 여성 이미지에 대한 것입니다. 나중에 모델에 진정한 사실성을 부여하는 VAE(가변 자동 인코더)에 대해 살펴보겠습니다.
stable-diffusion-webuimodelsStable-diffusion 에 파일을 가져오고 거기에서 모델을 선택하면 CLI가 VAE 가중치를 로드하는 동안 몇 분 정도 기다려야 합니다.LoRA(Low-Rank Adaptation)를 사용하면 특정 모델에 대한 미세 조정이 가능합니다. LoRA에 대한 자세한 내용은 여기를 참조하세요. WebUI에서는 케이크 위에 아이싱을 장식하는 것처럼 모델에 LoRA를 추가할 수 있습니다. 새로운 LoRA를 훈련시키는 것도 꽤 쉽습니다. 미세 조정을 위한 다른 "전통" 수단(예: 텍스트 반전 및 하이퍼네트워크)이 있지만 LoRA는 최첨단입니다.
가이드 전반에 걸쳐 탱크 LoRA를 사용하겠습니다. 애니메이션 스타일의 이미지를 위한 것이므로 그다지 좋은 LoRA는 아니지만 가지고 놀기에는 괜찮습니다.
stable-diffusion-webuiextensionssd-webui-additional-networksmodelslora 에 넣으세요.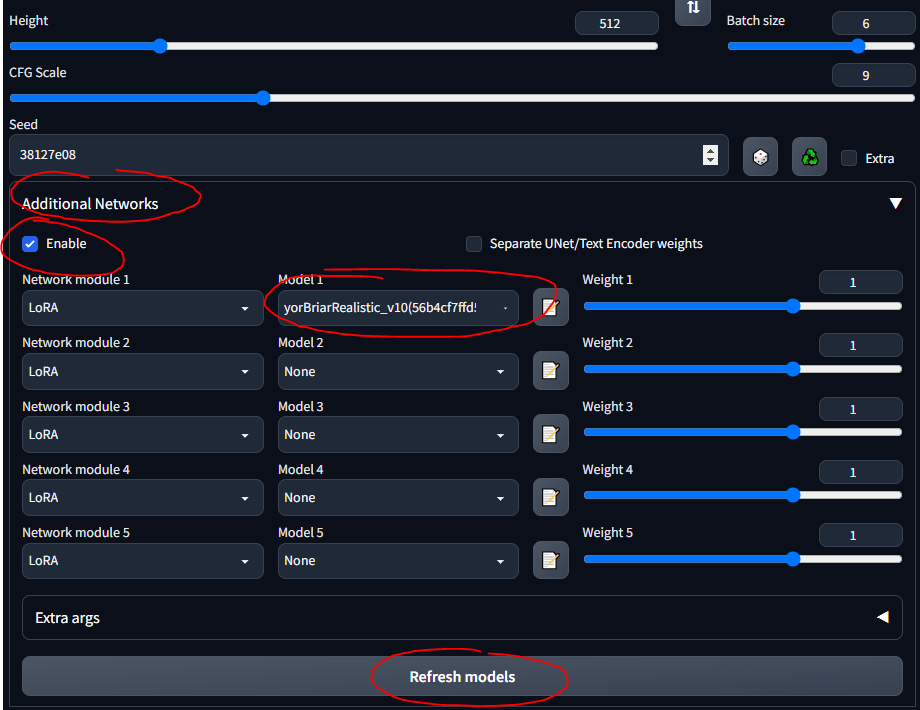
이전 섹션을 기반으로 하면... 모델마다 훈련 데이터와 훈련 키워드가 다르기 때문에 일부 모델에서는 booru 태그를 사용하는 것이 잘 작동하지 않습니다. 다음은 제가 가지고 놀았던 일부 모델과 해당 모델에 대한 "지침"입니다.
대부분의 모델을 가져오는 데 사용되는 SDG 모델 마더로드는 빠른 참조를 위해 여기에 지침을 요약하고 있습니다. 대부분의 모델은 실제 포르노를 위한 것이므로 저는 현실적인 모델에 중점을 두었습니다. 링크를 따라가면 각 사용법에 대한 예제 프롬프트, 이미지 및 자세한 참고 사항을 볼 수 있습니다.
CivitAI는 다른 모든 것을 얻는 데 사용되었습니다. 계정을 만들어야 합니다. 그렇지 않으면 무기 및 군사 장비를 포함한 NSFW 항목을 볼 수 없습니다. CivitAI에서는 일부 모델(체크포인트)에 VAE가 포함되어 있습니다. 이에 관한 내용이 있으면 다운로드하여 모델 옆에 배치하십시오.
가변 자동 인코더는 이미지를 더 좋게, 또렷하게, 덜 깨뜨려 보이게 만듭니다. 일부는 손과 얼굴을 고치기도 합니다. 그러나 그것은 대부분 채도와 음영입니다. 여기와 여기(NSFW)에 설명되어 있습니다. NovelAI/Anything VAE가 일반적으로 사용됩니다. 기본적으로 LoRA와 마찬가지로 모델에 추가되는 기능입니다.
VAE 목록에서 VAE를 찾으세요.
stable-diffusion-webuimodelsVAE 에 넣어야 합니다.다음은 이 가이드의 연대순 흐름에 반드시 맞지는 않지만 제가 배운 몇 가지 일반적인 참고 사항과 유용한 사항입니다.
학습하는 좋은 방법은 CivitAI, AIbooru 또는 기타 SD 사이트(4chan, Reddit 등)에서 멋진 이미지를 찾아보고 원하는 것을 열고 생성 매개변수를 WebUI에 복사하는 것입니다. 전체 공개: 여기에 설명된 대로 이미지를 정확하게 다시 만드는 것이 항상 가능한 것은 아닙니다. 그러나 일반적으로 꽤 가까워질 수 있습니다. 실제로 실험해 보려면 CFG를 낮게 설정하여 모델이 더욱 창의적이 되도록 하세요. 배치를 시도하고 컴퓨터에서 벗어나 로트에 돌아와서 선택하세요.
WebUI 워크플로의 일반적인 프로세스는 다음과 같습니다.
find/pick models/LoRAs -> txt2img (repeat, change params, etc.) -> img2img -> inpainting -> extra ->
때로는 이미지를 붙여넣거나 처음부터 작성하지 않고 프롬프트로 돌아가고 싶을 때가 있습니다. WebUI에서 재사용하기 위해 프롬프트를 저장할 수 있습니다.
이 섹션은 이 가이드의 정보를 요약한 것입니다.
이미 존재하는 SD 생성 이미지에서 작업하려면 누군가가 당신에게 그것을 보냈거나 당신이 만든 것을 다시 만들고 싶을 수도 있습니다.
stable-diffusion-webuioutputstxt2img-images<date> 에 저장됩니다.일부 사이트에서는 이미지가 업로드될 때(예: 4chan) PNG 메타데이터를 제거하므로 전체 이미지에 대한 URL을 찾거나 CivitAI 또는 AIbooru와 같이 SD 메타데이터를 유지하는 사이트를 사용하십시오.
가끔 몇 가지 오류가 발생했습니다. 대부분의 메모리 부족(VRAM) 오류는 일부 매개변수의 값을 낮춤으로써 해결되었습니다. 때로는 복원 얼굴과 고용. 설정 수정으로 인해 이 문제가 발생할 수 있습니다. stable-diffusion-webuiwebui-user.bat 파일의 set COMMANDLINE_ARGS= 줄에 일반적인 오류를 수정하는 몇 가지 플래그를 넣을 수 있습니다.
--disable-nan-check 매개변수를 추가합니다.--no-half 추가하세요.--medvram 추가하거나 감자 컴퓨터의 경우 --lowvram 추가하세요.매우 일반적인 문제 중 하나는 잘못된 Python 버전이나 Torch 버전에서 비롯됩니다. "Torch를 설치할 수 없습니다" 또는 "Torch가 GPU를 찾을 수 없습니다"와 같은 오류가 발생합니다. 가장 간단한 수정은 다음과 같습니다.
Python 폴더와 Python/Scripts 폴더 모두)에 추가했는지 확인하세요.stable-diffusion-webui 폴더에서 venv 폴더를 삭제하세요.stable-diffusion-webuiwebui-user.bat 실행하고 venv를 올바르게 다시 빌드하도록 합니다.모든 명령줄 인수는 여기에서 찾을 수 있습니다.
일부 확장을 사용하면 WebUI를 더 효과적으로 사용할 수 있습니다. Github 링크를 받고 Extensions 탭으로 이동하여 URL에서 설치하세요. 선택적으로 확장 탭에서 사용 가능을 클릭한 다음 다음에서 로드를 클릭하면 확장을 로컬로 찾아볼 수 있습니다. 이는 확장 Github 위키를 미러링합니다.
이제 몇 가지 모델, LoRA 및 프롬프트가 있습니다. 무엇이 가장 효과적인지 확인하기 위해 어떻게 테스트할 수 있습니까? 추가 네트워크 창 아래에는 스크립트 드롭다운이 있습니다. 여기에서 X/Y/Z 플롯을 클릭합니다. X 유형에서 체크포인트 이름을 선택합니다. X 값에서 오른쪽에 있는 버튼을 클릭하여 모든 모델을 붙여넣습니다. Y 유형에서는 VAE, 시드 또는 CFG 스케일을 사용해 보세요. 어떤 속성을 선택하든 그래프로 표시하려는 값을 붙여넣거나 입력하세요. 예를 들어, 5개의 모델과 5개의 VAE가 있는 경우 25개의 이미지로 구성된 그리드를 만들어 각 모델이 각 VAE와 어떻게 출력되는지 비교합니다. 이는 매우 다양하며 무엇을 사용할지 결정하는 데 도움이 될 수 있습니다. X 또는 Y 축이 VAE 모델인 경우 모든 조합에 대해 모델 또는 VAE 가중치를 로드해야 하므로 시간이 걸릴 수 있습니다.
SD 비교에 대한 정말 좋은 리소스는 여기(NSFW)에서 찾을 수 있습니다. 따라야 할 링크가 많이 있습니다. 다양한 모델, VAE, LoRA, 매개변수 값 등이 이미지 생성에 어떤 영향을 미치는지에 대한 이해를 시작할 수 있습니다.
저는 여기에서 테스트 프롬프트를 채택하고 탱크 LoRA를 사용하여 이 X/Y 그리드를 만들었습니다. 다양한 모델과 샘플러가 서로 어떻게 작동하는지 확인할 수 있습니다. 이 테스트를 통해 다음을 평가할 수 있습니다.

이러한 모든 탱크 이미지에 사용된 정확한 매개변수(모델이나 샘플러 제외)는 아래에 나와 있습니다(다시 여기에서 가져옴).
이 섹션에서는 WebUI의 txt2image 탭에 있는 모델, LoRA, VAE, 프롬프트, 매개변수, 스크립팅 및 확장 사용에 익숙해지면 수행할 수 있는 고급 작업에 대해 설명합니다.
프롬프트 블렌딩이라고도 합니다. 프롬프트 편집을 사용하면 모델이 지정된 단계에서 프롬프트를 변경하도록 할 수 있습니다. 아래 이미지는 4chan 게시물에서 가져온 것이며 기술을 설명합니다. 예를 들어, 이 가이드에 설명된 대로 신속한 편집을 사용하여 면을 혼합할 수 있습니다.
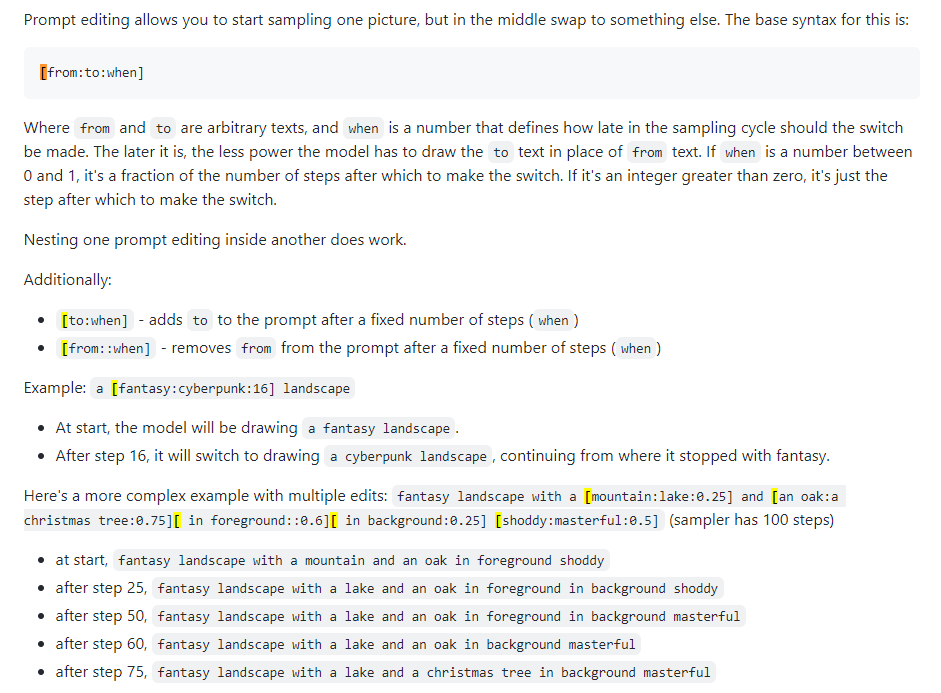
Xformers 또는 교차 관심 레이어. Nvidia GPU에서 이미지 생성 속도(초/반복 또는 s/it로 측정)를 높이는 방법은 VRAM 사용량을 낮추지만 비결정성을 유발합니다. 강력한 GPU가 있는 경우에만 이것을 고려하십시오. 현실적으로 Quadro가 필요합니다.
정확히 많이 사용되지는 않았으며 일종의 혼란스러운 탭입니다. Huggingface Image to Image SD Playground와 같이 주어진 스케치에 따라 이미지를 생성하는 데 사용할 수 있습니다. 이 탭에는 다음 섹션의 주제이자 WebUI의 매우 중요한 기능인 인페인팅(inpainting) 하위 탭이 있습니다. 이 섹션을 사용하여 이미 만든 이미지( stable-diffusion-webuioutputsimg2img-images 로 출력)에 대해 변경된 이미지를 생성할 수 있지만 기능이 불분명합니다... 엄청난 양의 메모리를 사용하는 것 같습니다. 나는 그것을 거의 작동시킬 수 없습니다. 아래의 다음 섹션으로 이동하세요.
콘텐츠 제작자나 이미지 교란에 관심이 있는 사람에게는 이것이 힘이 있는 곳입니다. 출력은 stable-diffusion-webuioutputsimg2img-images 에 있습니다.
아웃페인팅은 다소 복잡한 의미론적 과정입니다. Outpainting을 사용하면 이미지를 촬영하고 원하는 만큼 확장하여 본질적으로 이미지의 경계를 늘릴 수 있습니다. 프로세스는 여기에 설명되어 있습니다. 한 번에 64픽셀씩만 이미지를 확장할 수 있습니다. 이를 위한 두 가지 UI 도구가 있습니다(찾을 수 있음).
이 WebUI 탭은 특히 업스케일링을 위한 것입니다. 정말 마음에 드는 이미지를 얻었다면 작업 흐름이 끝날 때 여기에서 이미지를 확대할 수 있습니다. 확대된 이미지는 stable-diffusion-webuioutputsextras-images 에 저장됩니다. txt2img 탭에서 생성하는 동안 더 강력한 업스케일러를 사용한 업스케일링과 관련된 일부 메모리 문제(예: 4x+ 이미지)는 여기서 발생하지 않습니다. 왜냐하면 새 이미지를 생성하는 것이 아니라 정적 이미지만 업스케일링하기 때문입니다.
ControlNet이 수행하는 작업을 이해하는 가장 좋은 방법은 "스테로이드에 대한 페인팅"이라고 말하는 것과 같습니다. 입력 이미지(SD 생성 여부)를 제공하면 전체를 수정할 수 있습니다. ControlNet을 사용하면 포즈도 가능합니다. 사람에 대한 참조 포즈를 제공하고 일반적인 프롬프트에 따라 해당 이미지를 생성할 수 있습니다. ControlNet을 이해하기 위한 좋은 시작이 여기에 있습니다.
stable-diffusion-webuiextensionssd-webui-controlnetmodels 에 넣으세요.

이것은 모두 훌륭하지만 때로는 전문적인 사용 사례를 위해 더 나은 모델이나 LoRA가 필요할 수도 있습니다. 대부분의 SD 콘텐츠는 말 그대로 여성이나 포르노를 생성하기 위한 것이므로 특정 모델과 LoRA를 교육해야 할 수도 있습니다.
DreamBooth 섹션을 참조하세요.
TODO
WebUI의 체크포인트 병합 탭을 사용하면 마치 냄비에 두 소스를 섞는 것처럼 두 모델을 결합할 수 있습니다. 여기서 두 소스를 결합한 새로운 소스가 출력됩니다.
TODO
LoRA를 훈련시키는 것은 반드시 어려운 것은 아니며, 단지 충분한 데이터를 수집하는 것의 문제일 뿐입니다.
장비에서 멀리 떨어져 작업해야 하는 경우 이는 중요한 단계입니다. Google Colab Pro는 한 달에 10달러이며 89GB의 RAM과 우수한 GPU에 대한 액세스를 제공하므로 기술적으로 휴대폰에서 메시지를 실행하고 팀북투의 서버에서 작동하도록 할 수 있습니다. 약간의 추가 비용이 부담되지 않는다면 Google Colab Pro+는 한 달에 50달러이며 훨씬 더 좋습니다.
gdrive/MyDrive/sd/stable-diffusion-webui 가 있어야 하며 이 기본 폴더에서 로컬에서 수행했던 것과 동일한 폴더 구조를 사용할 수 있습니다. 웹UIGoogle Colab은 항상 무료이며 영원히 사용할 수 있지만 약간 느릴 수 있습니다. 월 10달러에 Colab Pro로 업그레이드하면 더 많은 기능을 사용할 수 있습니다. 하지만 월 50달러의 Colab Pro+에는 정말 재미가 있습니다. Pro+를 사용하면 탭을 닫은 후에도 24시간 동안 코드를 실행할 수 있습니다.
할 일 런타임 -> 런타임 유형 노트북 설정을 프리미엄 GPU 클래스 및 높은 RAM으로 설정할 때 Pro 구독이 중단되는 이상한 오류가 발생합니다. xFormers가 CUDA 지원으로 구축되지 않았기 때문입니다. 대신 TPU를 사용하거나 xFormers를 비활성화하면 이 문제를 해결할 수 있지만 지금은 인내심이 없습니다. Colab의 문제를 시도해 보세요.
MJ는 아티스트에게 정말 좋은 사람이에요. WebUI의 SD만큼 확장 가능하거나 강력하지는 않지만(NSFW는 불가능함) 꽤 멋진 것을 생성할 수 있습니다. MJ Discord(해당 사이트에 가입)에서 몇 가지 메시지를 무료로 사용하거나 기본 플랜으로 월 8달러를 지불한 후 개인 서버에서 사용할 수 있습니다. 모든 Discord 명령은 여기와 여기에서 찾을 수 있습니다. MJ의 프롬프트 구조는 다음과 같습니다.
/imagine <optional image prompt> <prompt> --parameters
이는 MJ V4용이며 대부분 MJ 5와 동일합니다. 모든 모델은 여기에 설명되어 있습니다.
TODO
DreamStudio (DreamSbooth가 아님)는 Stability AI Company의 플래그십 플랫폼입니다. 그들의 사이트는 이미지를 생성 할 수있는 플랫폼 인 Dreambooth Studio입니다. 그것은 열린 기능 측면에서 Midjourney와 Webui 사이에 있습니다. Dreambooth Studio는 invoke.ai 플랫폼 위에 세워진 것 같습니다.
TODO
안정적인 호드는 모든 사람에게 안정적인 확산을 자유롭게하기위한 커뮤니티 노력입니다. 본질적으로 토렌팅 또는 비트 코인 해싱과 같이 작동하며, 여기서 모든 사람이 SD 컨텐츠를 생성하기 위해 GPU 전력의 일부를 기여합니다. Horde 앱에 액세스 할 수 있습니다.
TODO
Dreambooth (DreamStudio가 아님)는 안정적인 확산 모델 미세 조정 기술을 구현했습니다. 요컨대 : 자신의 사진으로 모델을 훈련시키는 데 사용할 수 있습니다. 여기에서 또는 여기에서 직접 사용할 수 있습니다. 실제로 새로운 모델을 교육하고 직렬화하기 위해 모델을 다운로드하고 Webui에서 클릭하는 것보다 더 복잡합니다. 일부 비디오는이를 수행하는 방법을 요약합니다.
그리고 좋은 가이드 :
Dreambooth의 Google Colab :
EveryDream이라는 모델 트레이너도 있습니다. Dreambooth와 EveryDream의 전체 비교는 여기에서 찾을 수 있습니다.
TODO
3 월 -Shish 2023 기준으로 안정적인 확산을 사용하여 비디오를 생성 할 수 있습니다. 현재 (2023 년 4 월), 비디오가 유사한 이미지에서 프레임별로 생성되어 비디오에 일종의 "플립 북"모양을 제공함에 따라 기능은 다소 단순합니다. 사용할 수있는 webui에는 두 가지 기본 확장 기능이 있습니다.
내가 많이 모르지만 조사해야 할 것
좋은 결과를 반복해서 얻기 위해 따라갈 수있는 프로세스가 있습니다 ... 시간이 지남에 따라 개선됩니다.
chatgpt 통합?
유도
달 -E 2
Deforum https://deforum.github.io/


