Q Bench
1.0.0
다중 모드 LLM은 낮은 수준의 컴퓨터 비전에서 어떻게 수행됩니까?
Haoning Wu 1 * , Zicheng Zhang 2 * , Erli Zhang 1 * , Chaofeng Chen 1 , Liang Liao 1 ,
Annan Wang 1 , Chunyi Li 2 , Wenxiu Sun 3 , Qiong Yan 3 , Guangtao Zhai 2 , Weisi Lin 1 #
1 난양 기술 대학교, 2 상하이 교통 대학교, 3 Sensetime Research
* 균등 기여. # 교신저자.
ICLR2024 스포트라이트
종이 | 프로젝트 페이지 | 깃허브 | 데이터(LLVisionQA) | 데이터(LLDescribe) |质衡(중국어-Q-벤치)


제안된 Q-Bench에는 낮은 수준의 시력을 위한 세 가지 영역인 인식(A1), 설명(A2) 및 평가(A3)가 포함됩니다.
인식(A1)/설명(A2)의 경우 두 개의 벤치마크 데이터 세트 LLVisionQA/LLDescribe를 수집합니다.
우리는 두 가지 작업에 대해 제출 기반 평가 를 진행하고 있습니다. 제출 세부사항은 다음과 같습니다.
평가(A3)의 경우 공개 데이터 세트를 사용하므로 누구나 테스트할 수 있도록 임의의 MLLM에 대한 추상 평가 코드를 제공합니다.
datasets API와 함께 사용 Q-Bench-A1(객관식 질문 포함)의 경우 자동으로 다운로드하여 datasets API와 함께 사용할 수 있는 HF 형식 데이터세트로 변환했습니다. 다음 지침을 참조하십시오.
pip 설치 데이터 세트
데이터세트에서 import load_datasetds = load_dataset("q-future/Q-Bench-HF")print(ds["dev"][0])### {'id': 0,### 'image': <PIL .JpegImagePlugin.JpegImageFile image mode=RGB size=4160x3120>,### 'question': '이 조명은 어떻습니까? 건물?',### 'option0': '높음',### 'option1': '낮음',### 'option2': '보통',### 'option3': '해당 없음', ### '질문_유형': 2,### '질문_우려사항': 3,### '올바른_선택': 'B'} 데이터세트에서 import load_datasetds = load_dataset("q-future/Q-Bench2-HF")print(ds["dev"][0])### {'id': 0,### 'image1': <PIL .Image.Image 이미지 모드=RGB 크기=4032x3024>,### 'image2': <PIL.JpegImagePlugin.JpegImageFile 이미지 mode=RGB size=864x1152>,### 'question': '첫 번째 이미지와 비교했을 때 두 번째 이미지의 선명도는 어떻습니까?',### 'option0': '더 흐릿함',### 'option1 ': '명확함',### 'option2': '거의 같다',### 'option3': '해당 없음',### 'question_type': 2,### '질문_우려사항': 0,### '올바른_선택': 'B'}[2024/8/8] Q-bench+(Q-Bench2라고도 함)의 저수준 비전 비교 작업 부분이 TPAMI에 승인되었습니다! Q-bench+_Dataset로 MLLM을 테스트해 보세요.
[2024/8/1] Q-Bench가 VLMEvalKit에 출시되었습니다. `python run.py --data Q-Bench1_VAL Q-Bench1_TEST --model InternVL2-1B --verbose'와 같은 명령 하나로 LMM을 테스트해 보세요.
[2024/6/17] Q-Bench , Q-Bench2 (Q-bench+), A-Bench가 이제 lmms-eval에 추가되어 LMM 테스트가 더 쉬워졌습니다!!
[2024/6/3] A-Bench 용 Github 레포가 온라인 상태입니다. 귀하의 LMM이 AI 생성 이미지 평가의 전문가인지 알고 싶으십니까? A-Bench 에 오셔서 테스트해보세요!!
[3/1] 개방형 시각적 품질 비교를 위한 Co-instruct 를 여기서 출시합니다. 자세한 내용은 곧 제공될 예정입니다.
[2/27] 우리의 Q-Insturct 작업이 CVPR 2024에 승인되었습니다. MLLM에게 낮은 수준의 시력을 가르치는 방법에 대해 자세히 알아보세요!
[2/23] Q-bench+의 저수준 비전 비교 작업 부분이 Q-bench+(Dataset)에 출시되었습니다!
[2/10] 저수준 비전에서 단일 이미지와 이미지 쌍 모두를 사용하여 MLLM에 도전하는 확장된 Q-bench+를 출시합니다. LeaderBoard가 현장에 있습니다. 좋아하는 MLLM의 낮은 수준의 시력을 확인하세요!! 자세한 내용은 곧 제공될 예정입니다.
[1/16] 우리의 연구 "Q-Bench: 낮은 수준의 시력에 대한 범용 기초 모델을 위한 벤치마크"가 ICLR2024에서 Spotlight Presentation으로 승인되었습니다.

우리는 GPT-4V-Turbo( gpt-4-vision-preview , 더 이상 사용할 수 없는 이전 버전 GPT-4V 결과 대체), Gemini Pro( gemini-pro-vision ) 및 Qwen의 세 가지 클로즈 소스 API 모델을 테스트합니다. -VL-플러스( qwen-vl-plus ). 이전 버전에 비해 약간 개선된 GPT-4V는 여전히 모든 MLLM 중에서 최고 수준이며 거의 주니어 수준의 성능을 발휘합니다. Gemini Pro와 Qwen-VL-Plus가 뒤를 이어 최고의 오픈 소스 MLLM(전체 0.65)보다 여전히 우수합니다.
[2024/7/18] 업데이트, BlueImage-GPT (클로즈 소스)의 새로운 SOTA 성능을 출시하게 되어 기쁘게 생각합니다.
퍼셉션, A1-싱글
| 참가자 이름 | 예-아니요 | 무엇 | 어떻게 | 왜곡 | 다른 사람 | 맥락 내 왜곡 | 상황에 맞는 기타 | 전반적인 |
|---|---|---|---|---|---|---|---|---|
Qwen-VL-Plus( qwen-vl-plus ) | 0.7574 | 0.7325 | 0.5733 | 0.6488 | 0.7324 | 0.6867 | 0.7056 | 0.6893 |
BlueImage-GPT( from VIVO New Champion 에서) | 0.8467 | 0.8351 | 0.7469 | 0.7819 | 0.8594 | 0.7995 | 0.8240 | 0.8107 |
Gemini-Pro ( gemini-pro-vision ) | 0.7221 | 0.7300 | 0.6645 | 0.6530 | 0.7291 | 0.7082 | 0.7665 | 0.7058 |
GPT-4V-터보( gpt-4-vision-preview ) | 0.7722 | 0.7839 | 0.6645 | 0.7101 | 0.7107 | 0.7936 | 0.7891 | 0.7410 |
| GPT-4V( 이전 버전 ) | 0.7792 | 0.7918 | 0.6268 | 0.7058 | 0.7303 | 0.7466 | 0.7795 | 0.7336 |
| 인간-1-주니어 | 0.8248 | 0.7939 | 0.6029 | 0.7562 | 0.7208 | 0.7637 | 0.7300 | 0.7431 |
| 인간-2-시니어 | 0.8431 | 0.8894 | 0.7202 | 0.7965 | 0.7947 | 0.8390 | 0.8707 | 0.8174 |
인식, A1 쌍
| 참가자 이름 | 예-아니요 | 무엇 | 어떻게 | 왜곡 | 다른 사람 | 비교하다 | 관절 | 전반적인 |
|---|---|---|---|---|---|---|---|---|
Qwen-VL-Plus( qwen-vl-plus ) | 0.6685 | 0.5579 | 0.5991 | 0.6246 | 0.5877 | 0.6217 | 0.5920 | 0.6148 |
Qwen-VL-Max( qwen-vl-max ) | 0.6765 | 0.6756 | 0.6535 | 0.6909 | 0.6118 | 0.6865 | 0.6129 | 0.6699 |
BlueImage-GPT( from VIVO New Champion 에서) | 0.8843 | 0.8033 | 0.7958 | 0.8464 | 0.8062 | 0.8462 | 0.7955 | 0.8348 |
Gemini-Pro ( gemini-pro-vision ) | 0.6578 | 0.5661 | 0.5674 | 0.6042 | 0.6055 | 0.6046 | 0.6044 | 0.6046 |
GPT-4V( gpt-4-vision ) | 0.7975 | 0.6949 | 0.8442 | 0.7732 | 0.7993 | 0.8100 | 0.6800 | 0.7807 |
| 주니어 레벨 인간 | 0.7811 | 0.7704 | 0.8233 | 0.7817 | 0.7722 | 0.8026 | 0.7639 | 0.8012 |
| 상급 인간 | 0.8300 | 0.8481 | 0.8985 | 0.8313 | 0.9078 | 0.8655 | 0.8225 | 0.8548 |
또한 최근 몇 가지 새로운 오픈 소스 모델을 평가했으며 그 결과를 곧 발표할 예정입니다.
이제 데이터세트를 다운로드하는 두 가지 방법을 제공합니다(LLVisionQA&LLDescribe).
GitHub 릴리스를 통해: 자세한 내용은 릴리스를 참조하세요.
Huggingface 데이터세트를 통해: 이미지를 다운로드하려면 데이터 릴리스 노트를 참조하세요.
이러한 데이터를 원활하게 테스트하려면 모델을 Huggingface 형식으로 변환하는 것이 좋습니다. Huggingface의 IDEFICS-9B-Instruct에 대한 예제 스크립트를 예시로 보고 사용자 정의 모델에 맞게 수정하여 모델에서 테스트하세요.
결과를 json 형식으로 제출하려면 [email protected] 로 이메일을 보내주세요.
또한 사용자 정의 평가 스크립트와 함께 모델(Huggingface AutoModel 또는 ModelScope AutoModel)을 제출할 수도 있습니다. LLaVA-v1.5(A1/A2용) 및 여기(이미지 품질 평가용)에서 작동하는 템플릿 스크립트에서 사용자 정의 스크립트를 수정할 수 있습니다.
중국 본토 이외의 지역에 있는 경우 모델을 제출하려면 [email protected] 로 이메일을 보내주세요. 중국 본토 에 거주하는 경우 모델을 제출하려면 [email protected] 으로 이메일을 보내주세요.
MLLM 하위 수준 인식 능력에 대한 LLVisionQA 벤치마크 데이터 세트의 스냅샷은 다음과 같습니다. 여기에서 리더보드를 확인하세요.
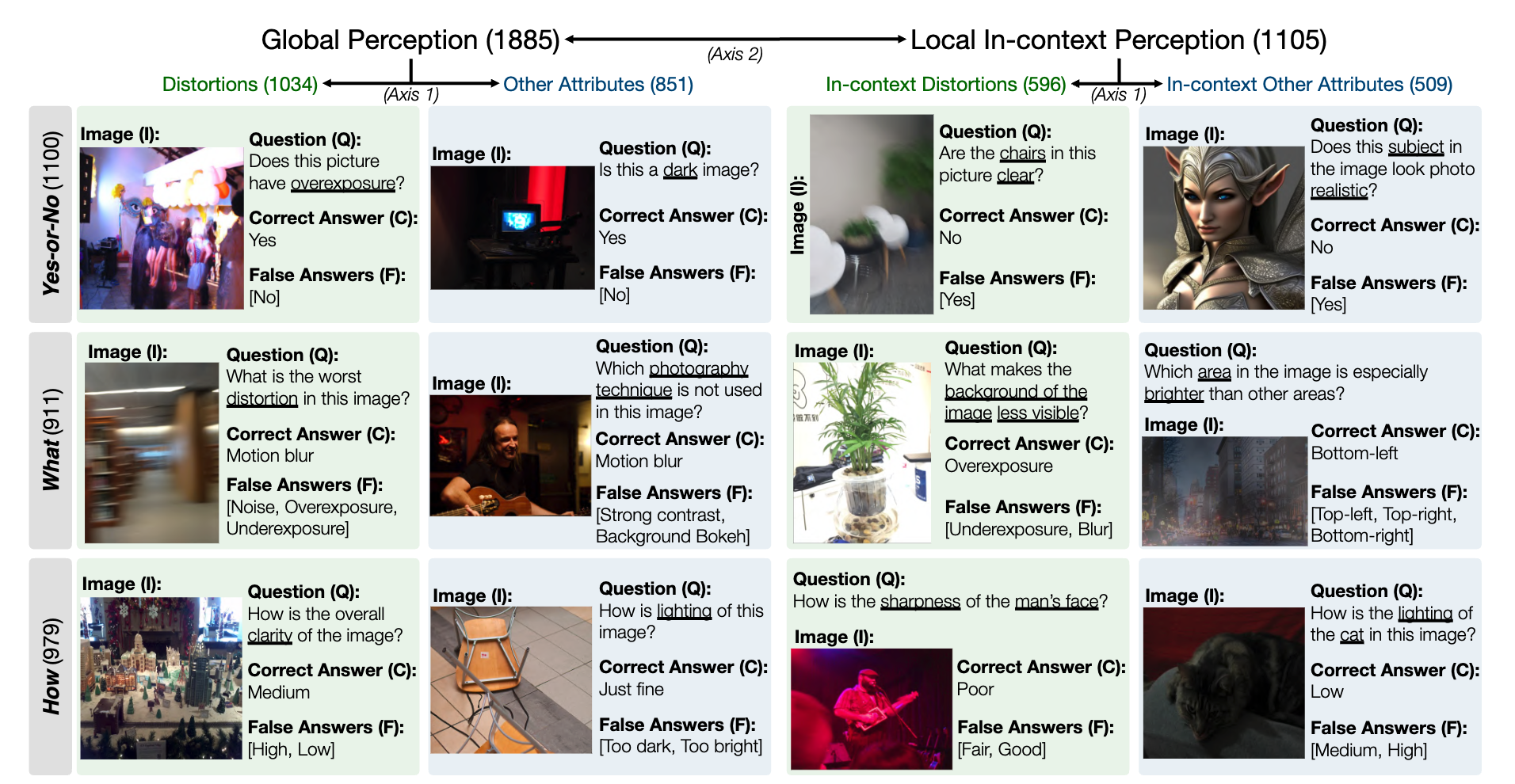
여기에서는 MLLM(질문 및 모든 선택 항목과 함께 제공됨)의 답변 정확도를 측정 기준으로 측정합니다.
MLLM 하위 수준 설명 기능에 대한 LLDescribe 벤치마크 데이터세트의 스냅샷은 다음과 같습니다. 여기에서 리더보드를 확인하세요.

여기서는 MLLM 설명의 완전성 , 정밀도 및 관련성을 지표로 측정합니다.
MLLM이 IQA의 정량적 점수를 예측할 수 있는 흥미로운 능력!
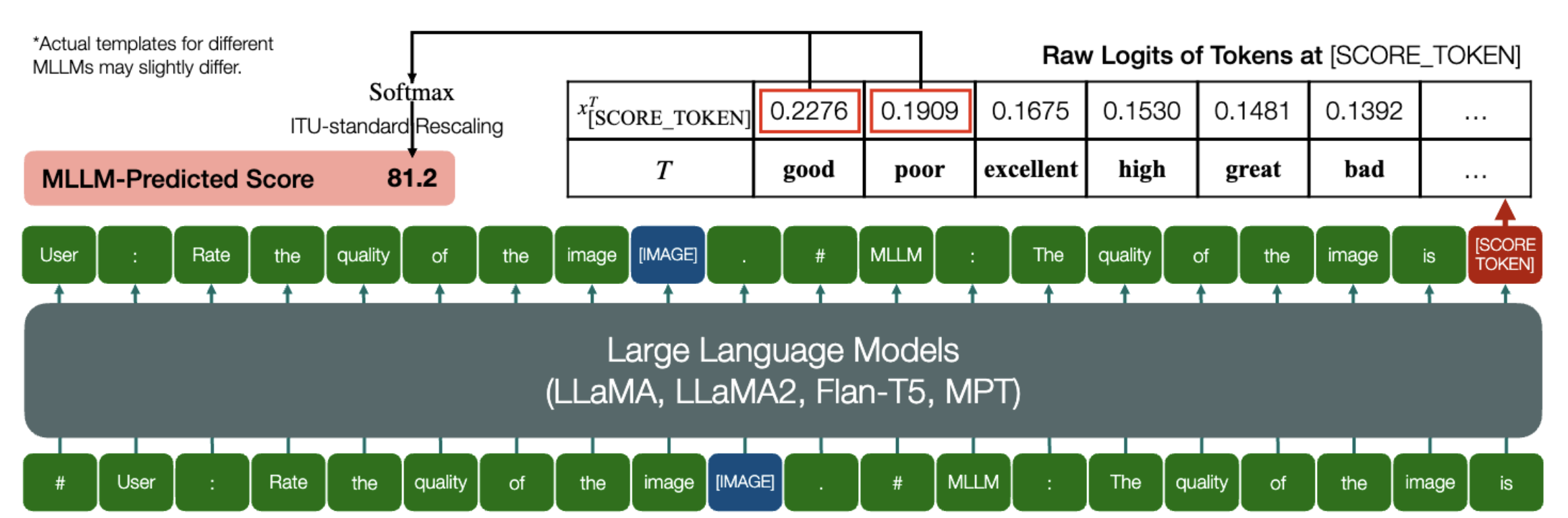
위와 유사하게 모델(인과 언어 모델 기반)에 embed_image_and_text (다중 양식 입력 허용) 및 forward (로짓 계산용)이라는 두 가지 메서드가 있는 한 모델을 사용한 이미지 품질 평가(IQA) 다음과 같이 달성할 수 있습니다:
from PIL import Imagefrom my_mllm_model import Model, Tokenizer, embed_image_and_textmodel, tokenizer = Model(), Tokenizer()prompt = "##User: 이미지 품질 평가.n"
"##Assistant: 이미지 품질은 다음과 같습니다." ### 이 줄은 MLLM의 기본 동작에 따라 수정될 수 있습니다.good_idx,poor_idx = tokenizer(["good","poor"]).tolist()image = 이미지. open("image_for_iqa.jpg")input_embeds = embed_image_and_text(이미지, 프롬프트)output_logits = 모델(input_embeds=input_embeds).logits[0,-1]q_pred = (output_logits[[good_idx,poor_idx]] / 100).softmax(0)[0]*모델의 기본 형식에 따라 두 번째 줄을 수정할 수 있습니다. 예를 들어 Shikra의 경우 "##Assistant: The quality of the image is"가 "##Assistant: The Answer is"로 수정됩니다. MLLM이 먼저 "알겠습니다. 도와드리고 싶습니다. 이미지 품질이 좋습니다."라고 대답해도 괜찮습니다. 이를 프롬프트의 2번째 줄로 바꾸면 됩니다.
또한 IQA에서 IDEFICS의 완전한 구현을 제공합니다. 이 MLLM을 사용하여 IQA를 실행하는 방법에 대한 예를 참조하세요. 다른 MLLM도 IQA에서 사용하기 위해 동일한 방식으로 수정할 수 있습니다.
우리는 벤치마크에서 평가된 7개 IQA 데이터베이스에 대해 JSON 형식의 MOS(인간 의견 점수)를 준비했습니다.
자세한 내용은 IQA_databases를 참조하세요.
리더보드로 이동했습니다. 자세한 내용을 보려면 클릭하세요.
문의 사항이 있는 경우 본 논문의 첫 번째 저자에게 문의하시기 바랍니다.
우 하오닝, [email protected] , @teowu
장지쳉(Zicheng Zhang), [email protected] , @zzc-1998
얼리 장(Erli Zhang), [email protected] , @ZhangErliCarl
우리 작업이 흥미롭다면 언제든지 우리 논문을 인용해 주세요.
@inproceedings{wu2024qbench,author = {Wu, Haoning 및 Zhang, Zicheng 및 Zhang, Erli 및 Chen, Chaofeng 및 Liao, Liang 및 Wang, Annan 및 Li, Chunyi 및 Sun, Wenxiu 및 Yan, Qiong 및 Zhai, Guangtao 및 Lin, Weisi},title = {Q-Bench: 저수준의 범용 기반 모델에 대한 벤치마크 비전},책 제목 = {ICLR}, 연도 = {2024}} 

