bida
v0.9.4
pip install -U bida from bida import ChatLLM
llm = ChatLLM (
model_type = 'openai' , # 调用openai的chat模型
model_name = 'gpt-4' ) # 设定模型为:gpt-4,默认是gpt3.5
result = llm . chat ( "从1加到100等于多少?只计算奇数相加呢?" )
print ( result ) from bida import ChatLLM
llm = ChatLLM (
model_type = "baidu" , # 调用百度文心一言
stream_callback = ChatLLM . stream_callback_func ) # 使用默认的流式输出函数
llm . chat ( "你好呀,请问你是谁?" ) | 모델 회사 | 모델 유형 | 모델명 | 지원 여부 | 설명하다 |
|---|---|---|---|---|
| 오픈AI | 채팅 | gpt-3.5, gpt-4 | √ | 모든 gpt3.5 및 gpt4 모델 지원 |
| 텍스트 완성 | 텍스트-davinci-003 | √ | 텍스트 생성 클래스 모델 | |
| 임베딩 | 텍스트 임베딩-ada-002 | √ | 벡터화된 모델 | |
| 바이두원신이옌 | 채팅 | 어니봇, 어니봇 터보 | √ | Baidu 상업용 채팅 모델 |
| 임베딩 | embedding_v1 | √ | Baidu 상업 벡터화 모델 | |
| 호스팅 모델 | 다양한 오픈소스 모델 | √ | Baidu에서 호스팅하는 다양한 오픈 소스 모델의 경우 Baidu의 타사 모델 액세스 프로토콜을 사용하여 직접 구성하세요. 자세한 내용은 아래 모델 액세스 섹션을 참조하세요. | |
| Alibaba Cloud-Tongyi Qianwen | 채팅 | qwen-v1, qwen-plus-v1, qwen-7b-chat-v1 | √ | Alibaba Cloud 상용 및 오픈 소스 Chat 모델 |
| 임베딩 | 텍스트 임베딩-v1 | √ | Alibaba Cloud 상업 벡터화 모델 | |
| 호스팅 모델 | 다양한 오픈소스 모델 | √ | Alibaba Cloud에서 호스팅하는 다른 유형의 오픈 소스 모델의 경우 Alibaba Cloud 타사 모델 액세스 프로토콜을 사용하여 직접 구성하세요. 자세한 내용은 아래 모델 액세스 섹션을 참조하세요. | |
| 미니맥스 | 채팅 | abab5, abab5.5 | √ | MiniMax 상업용 채팅 모델 |
| 채팅 프로 | abab5.5 | √ | 맞춤형 Chatcompletion 프로 모드를 사용하는 MiniMax 상용 채팅 모델은 다중 사용자 및 다중 봇 대화 시나리오, 샘플 대화, 반환 형식 제한, 함수 호출, 플러그인 및 기타 기능을 지원합니다. | |
| 임베딩 | 엠보-01 | √ | MiniMax 상용 벡터 모델 | |
| 지혜 AI-ChatGLM | 채팅 | ChatGLM-Pro, Std, Lite, 캐릭터glm | √ | Zhipu AI 다중 버전 상업용 대형 모델 |
| 임베딩 | 텍스트 삽입 | √ | Zhipu AI 상업용 텍스트 벡터 모델 | |
| iFlytek-스파크 | 채팅 | 스파크데스크 V1.5, V2.0 | √ | iFlytek Spark 인지 대형 모델 |
| 임베딩 | 삽입 | √ | iFlytek Spark 텍스트 벡터 모델 | |
| SenseTime-RiRiXin | 채팅 | 노바-ptc-xl-v1, 노바-ptc-xs-v1 | √ | SenseNova SenseTime 데일리 신형 대형 모델 |
| 바이촨 인텔리전스 | 채팅 | 바이촨-53b-v1.0.0 | √ | Baichuan 53B 대형 모델 |
| 텐센트-훈위안 | 채팅 | 텐센트 훈위안 | √ | Tencent Hunyuan 대형 모델 |
| 자체 배포 오픈 소스 모델 | 채팅, 완료, 임베딩 | 다양한 오픈소스 모델 | √ | FastChat 및 기타 배포로 배포된 오픈 소스 모델을 사용하여 제공된 웹 API 인터페이스는 OpenAI 호환 RESTful API를 따르며 직접 지원될 수 있습니다. 자세한 내용은 아래 모델 액세스 장을 참조하세요. |
알아채다 :
AIGC의 모델 LLM과 프롬프트 단어 프롬프트의 두 가지 기술은 매우 새롭고 빠르게 발전하고 있습니다. 이론, 튜토리얼, 도구, 엔지니어링 및 기타 측면이 현재 주류 개발자의 경험과 거의 겹치지 않습니다. :
| 분류 | 현재 주류 개발 | 프롬프트 프로젝트 | 모델 개발, 모델 미세 조정 |
|---|---|---|---|
| 개발 언어 | Java, .Net, Javscript, ABAP 등 | 자연어, 파이썬 | 파이썬 |
| 개발 도구 | 매우 성숙하고 | 없음 | 성숙한 |
| 개발 임계값 | 낮고 성숙하다 | 낮지만 매우 미성숙함 | 매우 높다 |
| 개발 기술 | 명확하고 꾸준한 | 시작하기는 쉽지만 안정적인 출력을 달성하는 것은 매우 어렵습니다. | 복잡하고 다양하다 |
| 일반적으로 사용되는 기술 | 객체지향, 데이터베이스, 빅데이터 | 신속한 튜닝, 비맥락 학습, 임베딩 | 트랜스포머, RLHF, 미세 조정, LoRA |
| 오픈소스 지원 | 풍부하고 성숙한 | 낮은 수준에서는 매우 혼란스럽습니다. | 부유하지만 미성숙하다 |
| 개발 비용 | 낮은 | 더 높은 | 매우 높다 |
| 개발자 | 부자 | 극히 희소함 | 매우 부족하다 |
| 협업 모델 개발 | 제품 관리자가 전달한 문서에 따라 개발 | 한 사람 또는 최소한의 팀이 요구 사항부터 배송까지 모든 작업을 처리할 수 있습니다. | 이론적 연구방향에 따라 개발 |
현재 거의 모든 기술 기업, 인터넷 기업, 빅데이터 기업이 모두 이 방향으로 가고 있지만, 전통적인 기업들은 여전히 혼란스러운 상태에 있다. 전통적인 기업이 이를 필요로 하지 않는다는 것은 아니지만, 1) 예비 기술 인재가 없기 때문에 무엇을 해야 할지 모릅니다. 2) 하드웨어 예비가 없고, 그렇지 않습니다. 3) 비즈니스 디지털화 수준이 낮고 AIGC 변환 및 업그레이드 주기가 길고 결과가 느립니다.
현재 국내외에는 상용 및 오픈 소스 모델이 너무 많고 매우 빠르게 발전하고 있습니다. 그러나 결과적으로 새로운 모델(또는 심지어는 모델)에 직면할 때 모델의 API 및 데이터 개체가 다릅니다. 새 버전), 우리는 개발 문서를 읽고 적응하기 위해 자신의 응용 프로그램 코드를 수정해야 합니다. 모든 응용 프로그램 개발자는 많은 모델을 테스트했으며 이로 인해 어려움을 겪었을 것입니다.
실제로 모델 기능은 다르지만 기능을 제공하는 모드는 일반적으로 동일합니다. 따라서 많은 수의 모델 API에 적응하고 통합된 호출 모드를 제공할 수 있는 프레임워크를 갖는 것이 많은 개발자에게 시급한 요구 사항이 되었습니다.
우선 bida는 langchain을 대체하기 위한 것이 아니지만 목표 포지셔닝 및 개발 개념도 매우 다릅니다.
| 분류 | 랭체인 | 비다 |
|---|---|---|
| 대상 그룹 | AIGC를 향한 전체 개발 군중 | AIGC와 애플리케이션 개발의 결합이 시급한 개발자 |
| 모델 지원 | 로컬 또는 원격 배포를 위한 다양한 모델 지원 | 현재 대부분의 상용 모델에서는 Web API를 제공하는 모델 호출만 지원됩니다. FastChat과 같은 프레임워크를 사용하여 배포한 후 Web API도 제공할 수 있습니다. |
| 프레임 구조 | 많은 기능과 매우 복잡한 구조를 제공하기 때문에 2023년 8월 현재 핵심 코드는 1,700개 이상의 파일과 150,000줄의 코드를 보유하고 있으며 학습 임계값이 높습니다. | 10개 이상의 핵심 코드와 약 2,000줄의 코드가 있으며, 코드를 배우고 수정하는 것은 비교적 쉽습니다. |
| 기능 지원 | AIGC가 지향하는 다양한 모델, 기술, 응용분야에 대한 Full Coverage 제공 | 현재 ChatCompletions, Completions, Embeddings, Function Call 및 기타 기능(음성, 이미지 등)에 대한 지원을 제공하고 있으며 가까운 시일 내에 출시될 예정입니다. |
| 즉각적인 | 프롬프트 템플릿이 제공되지만, 자체 기능에서 사용하는 프롬프트가 코드에 내장되어 있어 디버깅 및 수정이 어렵습니다. | 프롬프트 템플릿은 제공되지 않으며, 향후 사용할 경우 사용자 조정을 용이하게 하기 위해 구성 기반 포스트 로딩 모드가 사용됩니다. |
| 대화와 기억 | 다양한 메모리 관리 방법 지원 및 제공 | 지원, 지원 대화 지속성(duckdb에 저장됨), 메모리는 제한된 보관 세션 기능을 제공하며 기타 기능은 확장 프레임워크로 확장 가능 |
| 기능 및 플러그인 | 풍부한 확장 기능을 지원하고 제공하지만 사용 효과는 대형 모델의 자체 기능에 따라 다릅니다. | OpenAI의 Function Call 사양을 사용하여 대형 모델과 호환 가능 |
| 에이전트 및 체인 | 풍부한 확장 기능을 지원하고 제공하지만 사용 효과는 대형 모델의 자체 기능에 따라 다릅니다. | 지원되지 않습니다. 이를 구현하기 위해 다른 프로젝트를 열 계획이거나 현재 프레임워크를 기반으로 자체적으로 확장 및 개발할 수 있습니다. |
| 기타 기능 | 문서 분할과 같은 다양한 기능 지원(분할 후 포함이 이루어지며 chatpdf 및 기타 유사한 기능을 구현하는 데 사용됨) | 현재는 다른 기능이 추가되지 않은 상태로, 새로운 호환 프로젝트를 오픈하여 구현될 예정이며, 현재는 다른 제품에서 제공하는 기능을 조합하여 구현할 수 있습니다. |
| 운영 효율성 | 많은 개발자들이 API를 직접 호출하는 것보다 속도가 느리다고 보고하고 있으며 그 이유는 알려져 있지 않습니다. | 호출 프로세스만 캡슐화하고 호출 인터페이스를 통합하며 성능은 API를 직접 호출하는 것과 다르지 않습니다. |
업계 최고의 오픈 소스 프로젝트로서 langchain은 대형 모델 및 AGI의 홍보에 큰 기여를 했으며 동시에 개발 시에도 이를 프로젝트에 적용했습니다. 비다. 그러나 langchain은 크고 포괄적인 도구가 되기를 원하며 이로 인해 필연적으로 많은 단점이 발생합니다. 다음 기사에는 비슷한 의견이 있습니다. Max Woolf - 중국어, Hacker News - 중국어.
널리 알려진 속담이 이를 매우 잘 요약하고 있습니다. langchain은 모든 사람이 배우지만 결국에는 버리게 될 교과서입니다.
pip 또는 pip3에서 최신 bida 설치
pip install -U bidagithub에서 로컬 디렉터리로 프로젝트 코드를 복제합니다.
git clone https://github.com/pfzhou/bida.git
pip install -r requirements.txt현재 코드 루트 디렉터리 아래의 파일을 수정합니다. ".env.template" 확장자는 ".env" 환경 변수 파일이 됩니다. 해당 파일의 안내에 따라 적용 모델의 키를 설정해 주세요.
참고 : 이 파일은 무시 목록에 추가되었으며 Git 서버로 전송되지 않습니다.
예제1.초기화 환경.ipynb
다음 데모 코드는 bida에서 지원하는 다양한 모델을 사용합니다. 구매한 모델에 따라 코드의 **[model_type]** 값을 해당 모델 회사명으로 수정하여 교체하세요. 경험을 위해:
# 更多信息参看bidamodels*.json中的model_type配置
# openai
llm = ChatLLM ( model_type = "openai" )
# baidu
llm = ChatLLM ( model_type = "baidu" )
# baidu third models(llama-2...)
llm = ChatLLM ( model_type = "baidu-third" )
# aliyun
llm = ChatLLM ( model_type = "aliyun" )
# minimax
llm = ChatLLM ( model_type = "minimax" )
# minimax ccp
llm = ChatLLM ( model_type = "minimax-ccp" )
# zhipu ai
llm = ChatLLM ( model_type = "chatglm2" )
# xunfei xinghuo
llm = ChatLLM ( model_type = "xfyun" )
# senstime
llm = ChatLLM ( model_type = "senstime" )
# baichuan ai
llm = ChatLLM ( model_type = "baichuan" )
# tencent ai
llm = ChatLLM ( model_type = "tencent" )채팅 모드: 현재 주류 LLM 상호 작용 모드인 ChatCompletion, bida는 세션 관리, 지속성 및 메모리 관리를 지원합니다.
from bida import ChatLLM
llm = ChatLLM ( model_type = 'baidu' )
result = llm . chat ( "你好呀,请问你是谁?" )
print ( result ) from bida import ChatLLM
# stream调用
llm = ChatLLM ( model_type = "baidu" , stream_callback = ChatLLM . stream_callback_func )
result = llm . chat ( "你好呀,请问你是谁?" ) from bida import ChatLLM
llm = ChatLLM ( model_type = "baidu" , stream_callback = ChatLLM . stream_callback_func )
result = llm . chat ( "你是一个服务助理,请简洁回答我的问题。我的名字是老周。" )
result = llm . chat ( "我的名字是?" )위의 자세한 코드와 더 많은 기능적 예제를 보려면 아래 NoteBook을 참조하세요.
예제2.1.채팅 모드.ipynb
그래디언트를 사용하여 챗봇 구축
Gradio는 매우 인기 있는 자연어 처리 인터페이스 프레임워크입니다.
bida + grario는 단 몇 줄의 코드만으로 사용 가능한 애플리케이션을 구축할 수 있습니다.
import gradio as gr
from bida import ChatLLM
llm = ChatLLM ( model_type = 'openai' )
def predict ( message , history ):
answer = llm . chat ( message )
return answer
gr . ChatInterface ( predict ). launch ()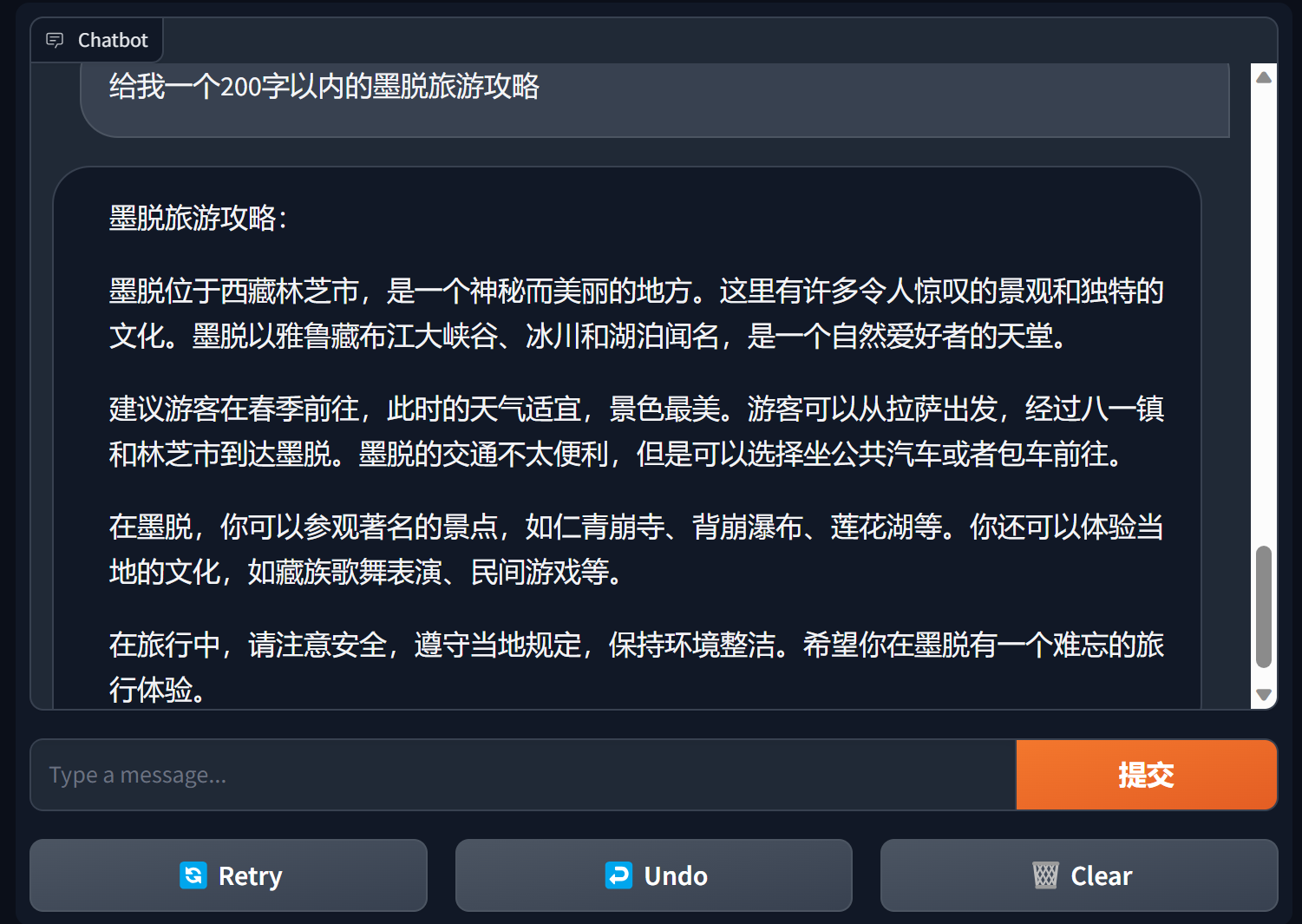
자세한 내용은 bida+gradio의 챗봇 데모를 참조하세요.
완료 모드: 이전 세대 LLM 상호 작용 모드인 완료 또는 TextCompletions는 단일 대화만 지원하고 채팅 기록을 저장하지 않으며 각 통화는 새로운 통신입니다.
참고: 2023년 7월 6일 OpenAI 기사에는 이 모델이 단계적으로 폐지될 것이라고 명시되어 있습니다. 새로운 모델은 기본적으로 관련 기능을 제공하지 않습니다. 심지어 지원되는 모델도 OpenAI를 따를 것으로 추정되며, 향후 단계적으로 단계적으로 폐지될 것으로 예상됩니다. 미래. .
from bida import TextLLM
llm = TextLLM ( model_type = "openai" )
result = llm . completion ( "你是一个服务助理,请简洁回答我的问题。我的名字是老周。" )
print ( result )샘플 코드 세부정보는 다음을 참조하세요.
예제2.2.완료 모드.ipynb
Prompt라는 단어는 대규모 언어 모델에서 가장 중요한 기능으로 기존의 객체 지향 개발 모델을 전복하여 Prompt 프로젝트 로 변환합니다. 이 프레임워크는 교체 태그, 여러 모델에 대해 서로 다른 프롬프트 단어 설정, 모델이 상호 작용을 수행할 때 자동 교체 등의 기능을 지원하는 "Prompt Templete"를 사용하여 구현됩니다.
PromptTemplate_Text 는 현재 제공됩니다. 문자열 텍스트를 사용하여 프롬프트 템플릿을 생성하도록 지원하고 bida는 유연한 사용자 정의 템플릿도 지원하며 향후 json 및 데이터베이스에서 템플릿을 로드하는 기능을 제공할 계획입니다.
자세한 샘플 코드는 다음 파일을 참조하세요.
예제2.3.프롬프트 프롬프트 word.ipynb
프롬프트 단어의 중요한 지침
일반적으로 프롬프트 단어는 역할 설정, 작업 명확화, 맥락 제공(관련 정보 또는 예)의 세 문단 구조를 따르는 것이 좋습니다. 작성 방법은 예를 참조하세요.
Andrew Ng의 강좌 시리즈 https://learn.deeplearning.ai/login, 중국어 버전, 통역
openai 요리책 https://github.com/openai/openai-cookbook
Microsoft Azure 설명서: 팁 엔지니어링 소개, 팁 엔지니어링 기술
Github에서 가장 인기 있는 Prompt Engineering Guide, 중국어 버전
Function Calling 은 OpenAI가 2023년 6월 13일에 출시한 기능입니다. ChatGPT에서 학습한 데이터는 2021년 이전을 기준으로 한 것으로 모두 알고 있습니다. 실시간으로 관련 질문을 하시면 답변을 드릴 수 없으며, 함수 통화를 하면 실시간으로 일기예보 확인, 주식 확인, 최근 영화 추천 등 네트워크 데이터를 얻을 수 있게 된다.
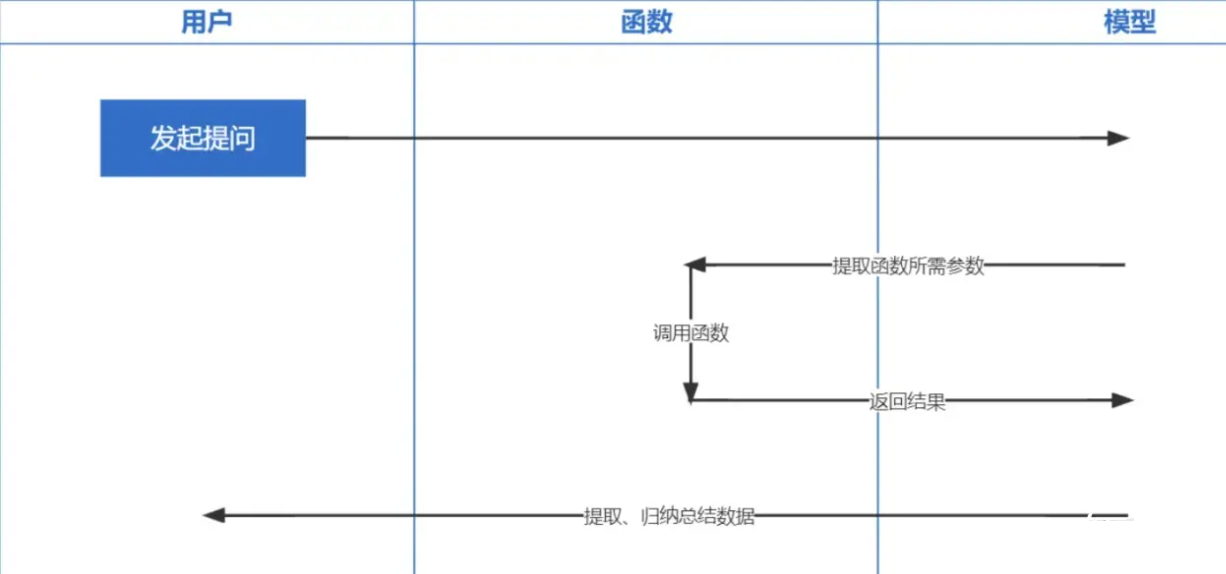
Embeddings 기술은 Prompt in Context Learning을 구현하기 위한 가장 중요한 기술로, 기존의 키워드 검색에 비해 한 단계 더 발전한 기술입니다.
참고 : 서로 다른 모델의 데이터 임베딩은 보편적이지 않으므로 검색 중 질문 임베딩에 동일한 모델을 사용해야 합니다.
| 모델명 | 출력 크기 | 배치 레코드 수 | 단일 텍스트 토큰 제한 |
|---|---|---|---|
| 오픈AI | 1536년 | 제한 없음 | 8191 |
| 바이두 | 384 | 16 | 384 |
| 알리 | 1536년 | 10 | 2048년 |
| 미니맥스 | 1536년 | 제한 없음 | 4096 |
| 지혜 스펙트럼 AI | 1024 | 하나의 | 512 |
| 아이플라이텍 스파크 | 1024 | 하나의 | 256 |
참고: bida의 임베딩 인터페이스는 일괄 처리를 지원합니다. 모델 일괄 처리 한도를 초과하면 자동으로 일괄 처리되어 함께 반환됩니다. 단일 텍스트 내용이 제한된 토큰 수를 초과하는 경우 모델의 논리에 따라 일부는 오류를 보고하고 일부는 이를 자릅니다.
자세한 예는 example2.6.Embeddingsembeddingmodel.ipynb를 참조하세요.
├─bida # bida框架主目录
│ ├─core # bida框架核心代码
│ ├─functions # 自定义function文件
│ ├─ *.json # function定义
│ ├─ *.py # 对应的调用代码
│ ├─models # 接入模型文件
│ ├─ *.json # 模型配置定义:openai.json、baidu.json等
│ ├─ *_api.py # 模型接入代码:openai_api.py、baidu_api.py等
│ ├─ *_sdk.py # 模型sdk代码:baidu_sdk.py等
│ ├─prompts # 自定义prompt模板文件
│ ├─*.py # 框架其他代码文件
├─docs # 帮助文档
├─examples # 演示代码、notebook文件和相关数据文件
├─test # pytest测试代码
│ .env.template # .env的模板
│ LICENSE # MIT 授权文件
│ pytest.ini # pytest配置文件
│ README.md # 本说明文件
│ requirements.txt # 相关依赖包
우리는 더 많은 모델에 적응할 수 있기를 바라며, 개발자들에게 더 나은 제품을 함께 제공할 수 있도록 여러분의 소중한 의견을 환영합니다!


