AMchat
1.0.0
?포옹얼굴 |
[2024.08.09] Q8_0 양자화 모델 AMchat-q8_0.gguf를 출시했습니다.
[2024.06.23] InternLM2-Math-Plus-20B 모델 미세 조정.
[2024.06.22] InternLM2-Math-Plus-1.8B 모델 미세 조정, 오픈 소스 소규모 데이터 세트.
[2024.06.21] README, InternLM2-Math-Plus-7B 모델 미세 조정 업데이트되었습니다.
[2024.03.24] 2024 푸위안 대형 모델 시리즈 챌린지(봄 대회) 혁신창의상 상위 12위.
[2024.03.14] HuggingFace에 모델이 업로드 되었습니다.
[2024.03.08] README 개선, 카탈로그 및 기술 루트 추가. README_en-US.md를 추가했습니다.
[2024.02.06] Docker 배포가 지원됩니다.
[2024.02.01] AMchat 첫 번째 버전 온라인 배포 https://openxlab.org.cn/apps/detail/youngdon/AMchat
참조 모델 다운로드.
pip install modelscope from modelscope . hub . snapshot_download import snapshot_download
model_dir = snapshot_download ( 'yondong/AMchat' , cache_dir = './' )다운로드 모델을 참조하세요.
pip install openxlab from openxlab . model import download
download ( model_repo = 'youngdon/AMchat' ,
model_name = 'AMchat' , output = './' )git clone https://github.com/AXYZdong/AMchat.git
python start.pydocker run -t -i --rm --gpus all -p 8501:8501 guidonsdocker/amchat:latest bash start.shgit clone https://github.com/AXYZdong/AMchat.git
cd AMchatconda env create -f environment.yml
conda activate AMchat
pip install xtuner # 列出所有内置配置
xtuner list-cfg
mkdir -p /root/math/data
mkdir /root/math/config && cd /root/math/config
xtuner copy-cfg internlm2_chat_7b_qlora_oasst1_e3 .mkdir -p /root/math/model download.py
import torch
from modelscope import snapshot_download , AutoModel , AutoTokenizer
import os
model_dir = snapshot_download ( 'Shanghai_AI_Laboratory/internlm2-math-7b' , cache_dir = '/root/math/model' )웨어하우스의
config폴더에 미세 조정된 구성 파일이 제공됩니다.internlm_chat_7b_qlora_oasst1_e3_copy.py를 참조하세요. 직접 사용할 수 있습니다.pretrained_model_name_or_path및data_path경로를 수정하는 데 주의하세요.
cd /root/math/config
vim internlm_chat_7b_qlora_oasst1_e3_copy.py # 修改模型为本地路径
- pretrained_model_name_or_path = 'internlm/internlm-chat-7b'
+ pretrained_model_name_or_path = './internlm2-math-7b'
# 修改训练数据集为本地路径
- data_path = 'timdettmers/openassistant-guanaco'
+ data_path = './data'xtuner train /root/math/config/internlm2_chat_7b_qlora_oasst1_e3_copy.pymkdir hf
export MKL_SERVICE_FORCE_INTEL=1
export MKL_THREADING_LAYER=GNU
xtuner convert pth_to_hf ./internlm2_chat_7b_qlora_oasst1_e3_copy.py
./work_dirs/internlm2_chat_7b_qlora_oasst1_e3_copy/epoch_3.pth
./hf # 原始模型参数存放的位置
export NAME_OR_PATH_TO_LLM=/root/math/model/Shanghai_AI_Laboratory/internlm2-math-7b
# Hugging Face格式参数存放的位置
export NAME_OR_PATH_TO_ADAPTER=/root/math/config/hf
# 最终Merge后的参数存放的位置
mkdir /root/math/config/work_dirs/hf_merge
export SAVE_PATH=/root/math/config/work_dirs/hf_merge
# 执行参数Merge
xtuner convert merge
$NAME_OR_PATH_TO_LLM
$NAME_OR_PATH_TO_ADAPTER
$SAVE_PATH
--max-shard-size 2GBstreamlit run web_demo.py --server.address=0.0.0.0 --server.port 7860이 리포지토리를 포크한 다음 OpenXLab에서 새 프로젝트를 생성하고 포크 리포지토리를 새 프로젝트와 연결하기만 하면 OpenXLab에 AMchat을 배포할 수 있습니다.

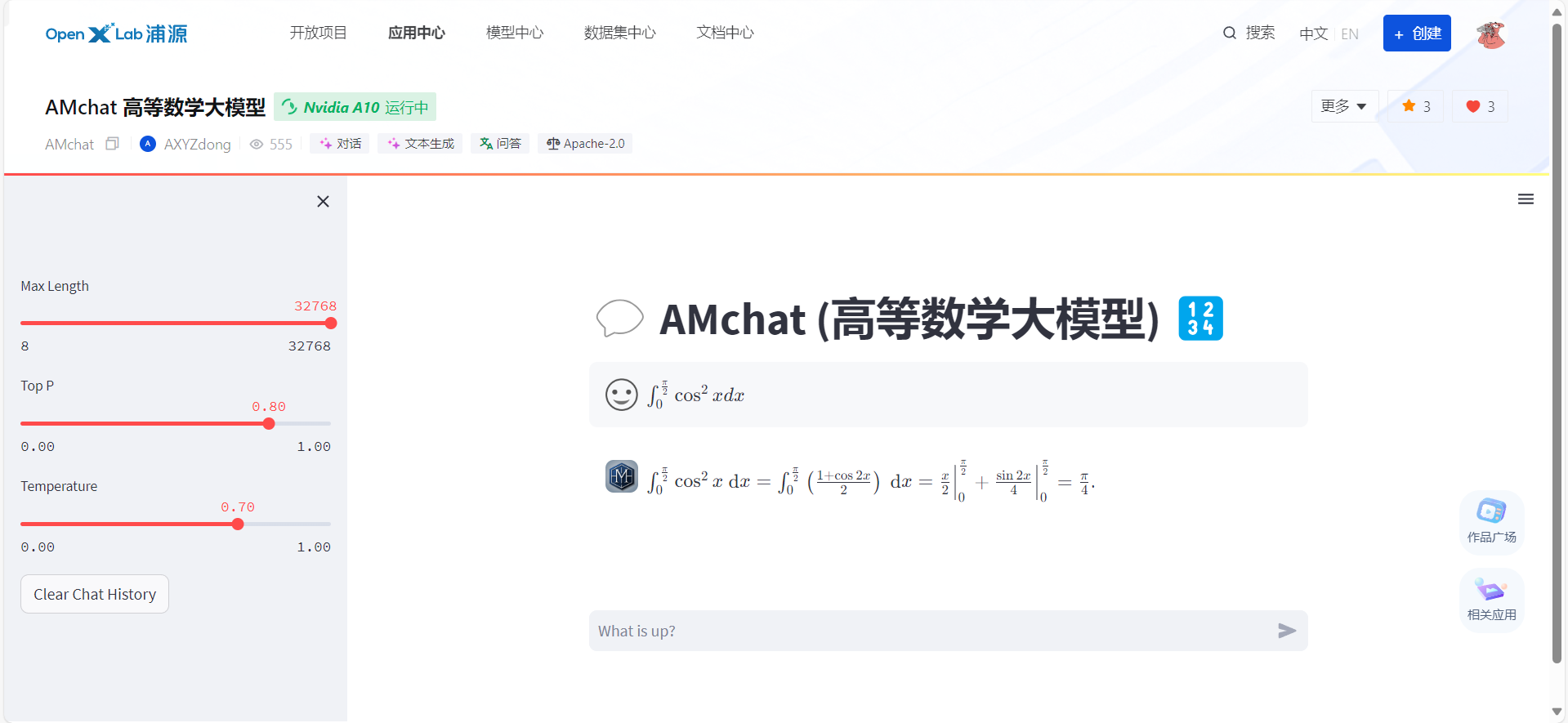

pip install -U lmdeployturbomind 형식으로 변환합니다.--dst-path: 변환된 모델 저장 위치를 지정할 수 있습니다.
lmdeploy convert internlm2-chat-7b 要转化的模型地址 --dst-path 转换后的模型地址lmdeploy chat turbomind 转换后的turbomind模型地址git clone https://github.com/open-compass/opencompass
cd opencompass
pip install -e .cp /share/temp/datasets/OpenCompassData-core-20231110.zip /root/opencompass/
unzip OpenCompassData-core-20231110.zippython run.py
--datasets math_gen
--hf-path 模型地址
--tokenizer-path tokenizer地址
--tokenizer-kwargs padding_side= ' left ' truncation= ' left ' trust_remote_code=True
--model-kwargs device_map= ' auto ' trust_remote_code=True
--max-seq-len 2048
--max-out-len 16
--batch-size 2
--num-gpus 1
--debugW4 정량화 lmdeploy lite auto_awq 要量化的模型地址 --work-dir 量化后的模型地址TurbMind 로 변환 lmdeploy convert internlm2-chat-7b 量化后的模型地址 --model-format awq --group-size 128 --dst-path 转换后的模型地址config 작성 from mmengine . config import read_base
from opencompass . models . turbomind import TurboMindModel
with read_base ():
# choose a list of datasets
from . datasets . ceval . ceval_gen import ceval_datasets
# and output the results in a choosen format
# from .summarizers.medium import summarizer
datasets = [ * ceval_datasets ]
internlm2_chat_7b = dict (
type = TurboMindModel ,
abbr = 'internlm2-chat-7b-turbomind' ,
path = '转换后的模型地址' ,
engine_config = dict ( session_len = 512 ,
max_batch_size = 2 ,
rope_scaling_factor = 1.0 ),
gen_config = dict ( top_k = 1 ,
top_p = 0.8 ,
temperature = 1.0 ,
max_new_tokens = 100 ),
max_out_len = 100 ,
max_seq_len = 512 ,
batch_size = 2 ,
concurrency = 1 ,
# meta_template=internlm_meta_template,
run_cfg = dict ( num_gpus = 1 , num_procs = 1 ),
)
models = [ internlm2_chat_7b ]python run.py configs/eval_turbomind.py -w 指定结果保存路径TurbMind 로 변환 lmdeploy convert internlm2-chat-7b 模型路径 --dst-path 转换后模型路径 # 计算
lmdeploy lite calibrate 模型路径 --calib-dataset ' ptb ' --calib-samples 128 --calib-seqlen 2048 --work-dir 参数保存路径
# 获取量化参数
lmdeploy lite kv_qparams 参数保存路径 转换后模型路径/triton_models/weights/ --num-tp 1quant_policy 4 로 변경하고 위 config 에서 경로를 변경합니다.python run.py configs/eval_turbomind.py -w 结果保存路径학자 Puyu 실습 캠프 학습 활동을 조직한 상하이 인공지능 연구소에 감사드립니다~
프로젝트 배포를 위한 컴퓨팅 성능 지원을 제공한 OpenXLab에 감사드립니다~
프로젝트를 지원해주신 Puyu Assistant님께 감사드립니다~
우리 프로젝트에 귀중한 기술 지침과 강력한 컴퓨팅 성능 지원을 제공하는 Scholar·Puyu 대형 모델 실습 캠프를 시작한 상하이 인공 지능 연구소에 감사드립니다!
InternLM-튜토리얼 , InternStudio , xtuner , InternLM-Math
@misc { 2024AMchat ,
title = { AMchat: A large language model integrating advanced math concepts, exercises, and solutions } ,
author = { AMchat Contributors } ,
howpublished = { url{https://github.com/AXYZdong/AMchat} } ,
year = { 2024 }
}이 프로젝트는 Apache License 2.0 오픈 소스 라이센스를 채택합니다. 사용된 모델 및 데이터 세트의 라이센스를 준수하십시오.


