RWKV LM
v5
RWKV 홈페이지: https://www.rwkv.com
RWKV-5/6 Eagle/Finch 논문 : https://arxiv.org/abs/2404.05892
Vision의 멋진 RWKV: https://github.com/Yaziwel/Awesome-RWKV-in-Vision
RWKV-6 3B 데모: https://huggingface.co/spaces/BlinkDL/RWKV-Gradio-1
RWKV-6 7B 데모: https://huggingface.co/spaces/BlinkDL/RWKV-Gradio-2
RWKV-6 GPT 모드 데모 코드(설명 및 설명 포함) : https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v5/rwkv_v6_demo.py
RWKV-6 RNN 모드 데모: https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v6_demo.py
참고로 Python 3.10+, torch 2.5+, cuda 12.5+, 최신 deepspeed를 사용하되 pytorch-lightning==1.9.5를 유지하세요 .
RWKV-6 훈련 : /RWKV-v5/를 사용하고 deco-training-prepare.sh 및 deco-training-run.sh에서 --my_testing "x060"을 사용합니다.
RWKV-7 훈련 : /RWKV-v5/를 사용하고 deco-training-prepare.sh 및 deco-training-run.sh에서 --my_testing "x070"을 사용합니다.
pip install torch --upgrade --extra-index-url https://download.pytorch.org/whl/cu121
pip install pytorch-lightning==1.9.5 deepspeed wandb ninja --upgrade
cd RWKV-v5/
./demo-training-prepare.sh
./demo-training-run.sh
(you may want to log in to wandb first)
귀하의 손실 곡선은 상승과 하락이 동일하여 이와 거의 동일하게 보일 것입니다(동일한 bsz 및 구성을 사용하는 경우).
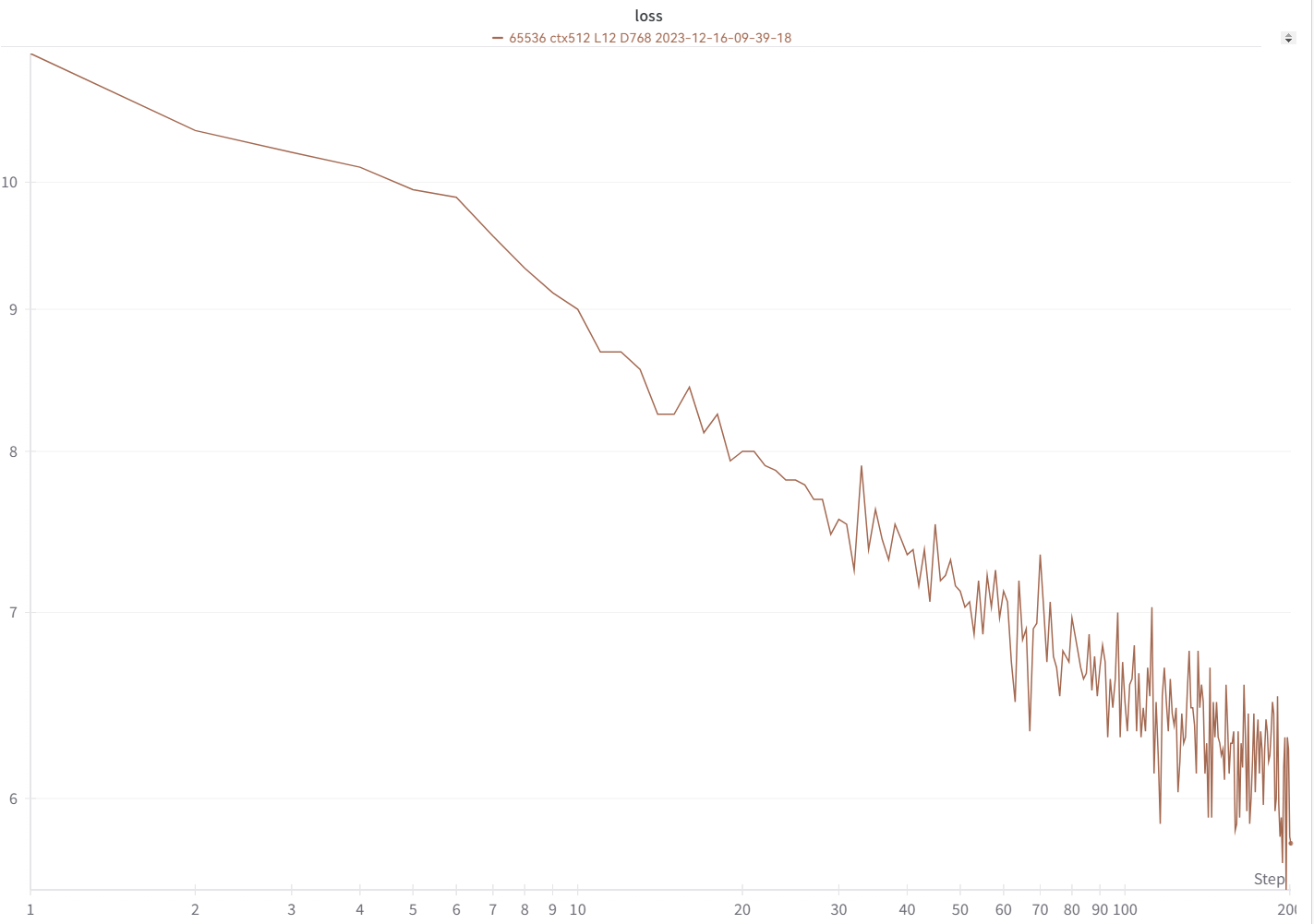
https://pypi.org/project/rwkv/를 사용하여 모델을 실행할 수 있습니다("20B_tokenizer.json" 대신 "rwkv_vocab_v20230424" 사용).
https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v5/make_data.py를 사용하여 jsonl에서 binidx 데이터를 준비하고 "--my_exit_tokens" 및 "--magic_prime"을 계산합니다.
대용량 데이터의 훨씬 빠른 토크나이저: https://github.com/cahya-wirawan/json2bin
train.py의 "에포크"는 "미니 에포크"(실제 에포크가 아닙니다. 편의상)이며 1 미니 에포크 = 40320 * ctx_len 토큰입니다.
예를 들어, binidx에 1498226207개의 토큰이 있고 ctxlen=4096인 경우 "--my_exit_tokens 1498226207"을 설정하면(epoch_count가 재정의됨) 1498226207/(40320 * 4096) = 9.07 miniepochs가 됩니다. 트레이너는 "--my_exit_tokens" 토큰 이후 자동 종료됩니다. "--magic_prime"을 datalen/ctxlen-1(= 1498226207/4096-1 = 365776)보다 작은 가장 큰 3n+2 소수로 설정합니다. 이 경우 "--magic_prime 365759"입니다.
간단함: SFT jsonl 준비 => make_data.py에서 SFT 데이터를 3~4회 반복합니다. 더 많은 반복은 과적합으로 이어집니다.
고급: jsonl에서 SFT 데이터를 3~4회 반복합니다(make_data.py는 모든 jsonl 항목을 섞습니다) => jsonl에 일부 기본 데이터(예: slimpajama)를 추가하고 => make_data.py에서 1회만 반복합니다.
훈련 스파이크 수정 : 이 페이지의 "RWKV-6 스파이크 수정" 부분을 참조하세요.
RWKV-5에 대한 간단한 추론 : https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v5_demo.py
RWKV-6에 대한 간단한 추론 : https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v6_demo.py
참고: [state = kv + w * state]에서는 w가 1에 매우 가까울 수 있으므로 모든 것이 fp32에 있어야 합니다. 따라서 상태와 w를 fp32에 유지하고 kv를 fp32로 변환할 수 있습니다.
lm_eval: https://github.com/BlinkDL/ChatRWKV/blob/main/run_lm_eval.py
개발자를 위한 채팅 데모: https://github.com/BlinkDL/ChatRWKV/blob/main/API_DEMO_CHAT.py
작은 모델/작은 데이터에 대한 팁 : RWKV 음악 모델을 훈련할 때 깊고 좁은 차원(예: L29-D512)을 사용하고 wd 및 드롭아웃(예: wd=2 dropout=0.02)을 적용합니다. 참고 RWKV-LM 드롭아웃은 매우 효과적입니다. 평소 값의 1/4을 사용하십시오.
데이터에 .jsonl 형식을 사용하세요(형식은 https://huggingface.co/BlinkDL/rwkv-5-world 참조).
https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v5/make_data.py를 사용하여 World 토크나이저를 사용하여 World 모델을 미세 조정하는 데 적합한 binidx로 토큰화합니다.
모델 폴더의 기본 체크포인트 이름을 rwkv-init.pth로 바꾸고, 7B의 경우 --n_layer 32 --n_embd 4096 --vocab_size 65536 --lr_init 1e-5 --lr_final 1e-5를 사용하도록 훈련 명령을 변경합니다.
0.1B = --n_layer 12 --n_embd 768 // 0.4B = --n_layer 24 --n_embd 1024 // 1.5B = --n_layer 24 --n_embd 2048 // 3B = --n_layer 32 --n_embd 2560 / / 7B = --n_layer 32 --n_embd 4096
현재 최적화되지 않은 구현은 전체 SFT와 동일한 vram을 사용합니다.
--train_type "states" --load_partial 1 --lr_init 1 --lr_final 0.01 --warmup_steps 10 (yes, use very high LR)
학습된 "time_state"를 자동 로드하려면 rwkv 0.8.26+를 사용하세요.
RWKV를 처음부터 훈련할 때 최고의 성능을 위해 초기화를 시도해보세요. src/model.py의 generate_init_weight()를 확인하세요.
emb.weight => nn.init.uniform_(a=-1e-4, b=1e-4)
(Note ln0 of block0 is the layernorm for emb.weight)
head.weight => nn.init.orthogonal_(gain=0.5*sqrt(n_vocab / n_embd))
att.receptance.weight => nn.init.orthogonal_(gain=1)
att.key.weight => nn.init.orthogonal_(gain=0.1)
att.value.weight => nn.init.orthogonal_(gain=1)
att.gate.weight => nn.init.orthogonal_(gain=0.1)
att.output.weight => zero
att.ln_x.weight (groupnorm) => ((1 + layer_id) / total_layers) ** 0.7
ffn.key.weight => nn.init.orthogonal_(gain=1)
ffn.value.weight => zero
ffn.receptance.weight => zero
!!! 위치 임베딩을 사용하는 경우 block.0.ln0을 제거하고 내uniform_(a=-1e-4, b=1e-4) 대신 emb.weight에 대한 기본 초기화를 사용하는 것이 더 나을 수도 있습니다!!!
처음부터 훈련할 때 "RUN_CUDA_RWKV6(r, k, v, w, u)" 앞에 "k = k * torch.clamp(w, max=0).exp()"를 추가하고 추론 코드도 변경하는 것을 잊지 마세요. . 더 빠른 수렴을 볼 수 있습니다.
"--adam_eps 1e-18"을 사용하십시오.
스파이크가 보이면 "--beta2 0.95"
Trainer.py에서 "lr = lr * (0.01 + 0.99 * Trainer.global_step / w_step)"(원래 0.2 + 0.8) 및 "--warmup_steps 20"을 실행합니다.
"--weight_decay 0.1"은 많은 양의 데이터를 훈련하는 경우 최종 손실이 더 좋습니다. 이 작업을 수행할 때 lr_final을 lr_init의 1/100으로 설정하십시오.
RWKV는 Transformer 수준의 LLM 성능을 갖춘 RNN으로, GPT Transformer처럼 직접 훈련할 수도 있습니다(병렬화 가능). 그리고 100% 주의가 필요하지 않습니다. 위치 t+1의 상태를 계산하려면 위치 t의 숨겨진 상태만 필요합니다. "GPT" 모드를 사용하면 "RNN" 모드에 대한 숨겨진 상태를 빠르게 계산할 수 있습니다.
따라서 뛰어난 성능, 빠른 추론, VRAM 절약, 빠른 훈련, "무한" ctx_len 및 자유 문장 임베딩 (최종 숨겨진 상태 사용) 등 RNN과 변환기의 장점을 결합합니다.
원클릭 설치 및 API를 갖춘 RWKV Runner GUI https://github.com/josStorer/RWKV-Runner
모든 최신 RWKV 가중치: https://huggingface.co/BlinkDL
HF 호환 RWKV 가중치: https://huggingface.co/RWKV
RWKV pip 패키지 : https://pypi.org/project/rwkv/
os . environ [ "RWKV_JIT_ON" ] = '1'
os . environ [ "RWKV_CUDA_ON" ] = '0' # if '1' then use CUDA kernel for seq mode (much faster)
from rwkv . model import RWKV # pip install rwkv
model = RWKV ( model = '/fsx/BlinkDL/HF-MODEL/rwkv-4-pile-1b5/RWKV-4-Pile-1B5-20220903-8040' , strategy = 'cuda fp16' )
out , state = model . forward ([ 187 , 510 , 1563 , 310 , 247 ], None ) # use 20B_tokenizer.json
print ( out . detach (). cpu (). numpy ()) # get logits
out , state = model . forward ([ 187 , 510 ], None )
out , state = model . forward ([ 1563 ], state ) # RNN has state (use deepcopy if you want to clone it)
out , state = model . forward ([ 310 , 247 ], state )
print ( out . detach (). cpu (). numpy ()) # same result as abovenanoRWKV : https://github.com/BlinkDL/nanoRWKV(학습을 위해 사용자 정의 CUDA 커널이 필요하지 않으며 모든 GPU/CPU에서 작동함)
트위터 : https://twitter.com/BlinkDL_AI
홈페이지 : https://www.rwkv.com
멋진 커뮤니티 RWKV 프로젝트 :
모든(300+) RWKV 프로젝트: https://github.com/search?o=desc&q=rwkv&s=updated&type=Repositories
https://github.com/OpenGVLab/Vision-RWKV 비전 RWKV
https://github.com/feizc/Diffusion-RWKV 확산 RWKV
https://github.com/cgisky1980/ai00_rwkv_server 가장 빠른 WebGPU 추론(nVidia/AMD/Intel)
ai00_rwkv_server에 대한 https://github.com/cryscan/web-rwkv 백엔드
https://github.com/saharNooby/rwkv.cpp 빠른 CPU/cuBLAS/CLBlast 추론: int4/int8/fp16/fp32
https://github.com/JL-er/RWKV-PEFT lora/pissa/Qlora/Qpissa/상태 튜닝
https://github.com/RWKV/RWKV-infctx-trainer Infctx 트레이너
https://github.com/daquexian/faster-rwkv
mlc-ai/mlc-llm#1275
https://github.com/TheRamU/Fay/blob/main/README_EN.md RWKV를 갖춘 디지털 어시스턴트
https://github.com/harrisonvanderbyl/rwkv-cpp-cuda cuda/amd/vulkan을 사용한 빠른 GPU 추론
250줄의 RWKV v6 (토큰나이저 포함): https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v6_demo.py
250줄의 RWKV v5 (토큰나이저 포함): https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v5_demo.py
150줄의 RWKV v4 (모델, 추론, 텍스트 생성): https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_in_150_lines.py
RWKV v4 사전 인쇄 https://arxiv.org/abs/2305.13048
RWKV v4 소개 및 100줄의 numpy : https://johanwind.github.io/2023/03/23/rwkv_overview.html https://johanwind.github.io/2023/03/23/rwkv_details.html
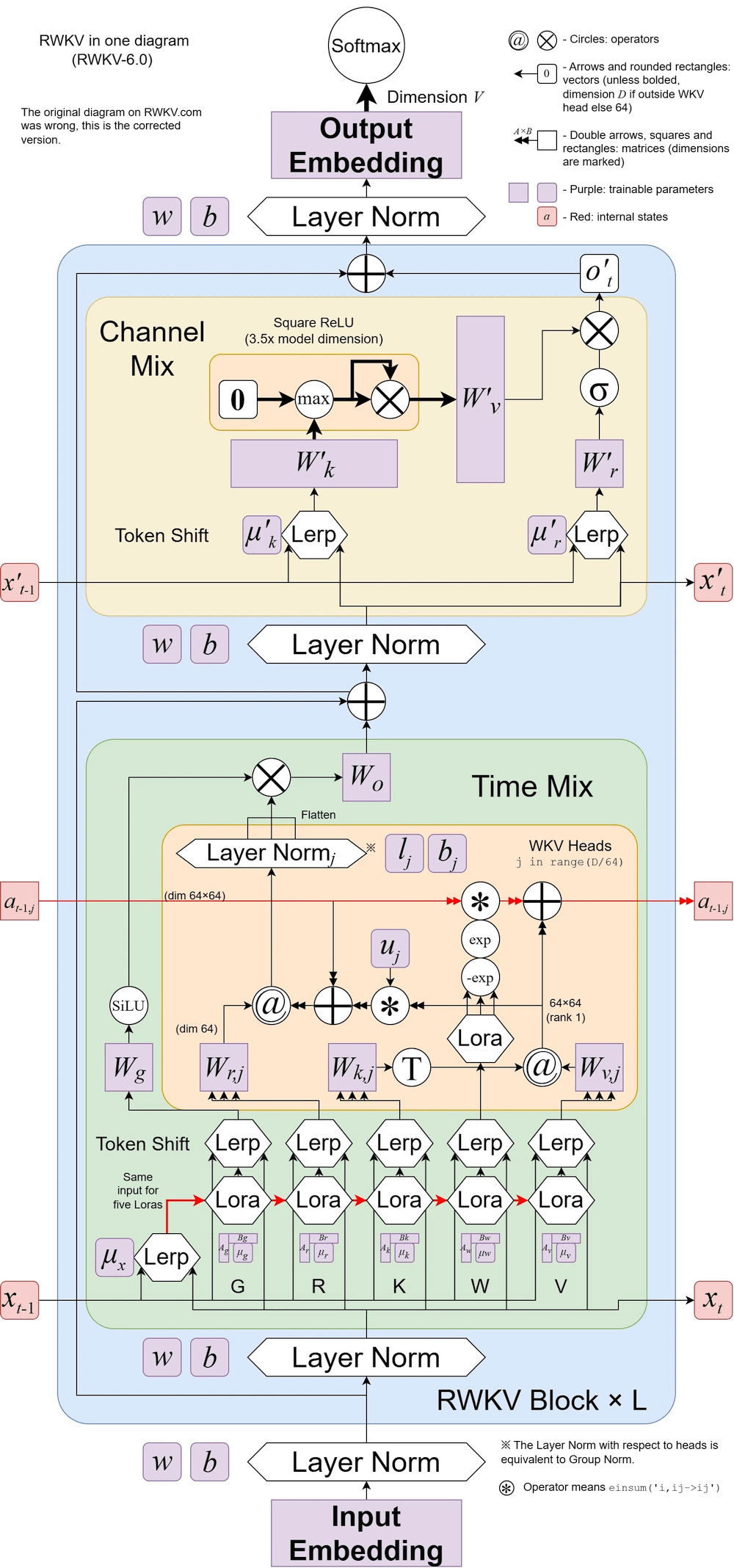
RWKV v6 그림:
RWKV를 사용한 멋진 논문(Spiking Neural Network): https://github.com/ridgerchu/SpikeGPT
RWKV 디스코드(https://discord.gg/bDSBUMeFpc)에 참여하여 이를 기반으로 구축하실 수 있습니다. 우리는 현재 (Stability 및 EleutherAI 덕분에) 잠재적인 컴퓨팅(A100 40G)을 충분히 보유하고 있으므로 흥미로운 아이디어가 있으면 이를 실행할 수 있습니다.

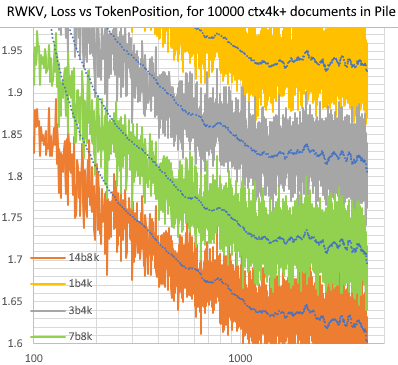
Pile의 10000개 ctx4k+ 문서에 대한 RWKV [손실 대 토큰 포지션]. RWKV 1B5-4k는 ctx1500 이후는 대부분 평탄한데 3B-4k와 7B-4k, 14B-4k는 약간의 경사가 있고 점점 좋아지고 있습니다. 이는 RNN이 긴 ctxlens를 모델링할 수 없다는 기존 견해를 반박합니다. 우리는 RWKV 100B가 훌륭할 것이라고 예측할 수 있으며, RWKV 1T만 있으면 아마도 충분할 것입니다 :)
RWKV 14B ctx8192를 사용한 ChatRWKV:

나는 RNN이 기본 모델에 더 나은 후보라고 생각합니다. 그 이유는 다음과 같습니다. (1) ASIC에 더 친숙합니다(kv 캐시 없음). (2) RL에 더 친숙합니다. (3) 글을 쓸 때 우리의 뇌는 RNN과 더 유사합니다. (4) 우주도 (지역성 때문에) RNN과 같습니다. 변압기는 비지역 모델입니다.
A40(tf32)의 RWKV-3 1.5B = 항상 0.015초/토큰, 간단한 파이토치 코드(CUDA 없음)를 사용하여 테스트, GPU 사용률 45%, VRAM 7823M
A40(tf32)의 GPT2-XL 1.3B = 0.032초/토큰(ctxlen 1000의 경우), HF를 사용하여 테스트됨, GPU 사용률도 45%(흥미롭음), VRAM 9655M
훈련 속도: (새 훈련 코드) RWKV-4 14B BF16 ctxlen4096 = 8x8 A100 80G(ZERO2+CP)에서 114K 토큰/초. (이전 교육 코드) RWKV-4 1.5B BF16 ctxlen1024 = 8xA100 40G에서 106K 토큰/초.
이미지 실험도 하고 있습니다(예: https://huggingface.co/BlinkDL/clip-guided-binary-autoencoder). RWKV는 txt2img 확산을 수행할 수 있습니다. :) 내 생각: 256x256 rgb 이미지 -> 32x32x13bit 잠재성 - > RWKV를 적용하여 각 32x32 그리드에 대한 전환 확률을 계산합니다. -> 그리드가 독립적인 것으로 가정하고 이러한 확률을 사용하여 "확산"합니다.
원활한 훈련 - 손실 급증 없음! (lr & bsz는 약 15G 토큰으로 변경됩니다)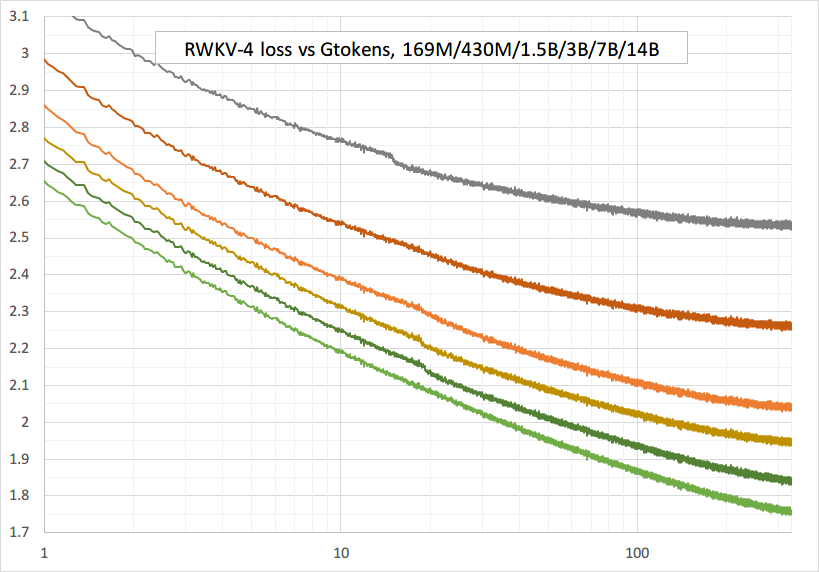
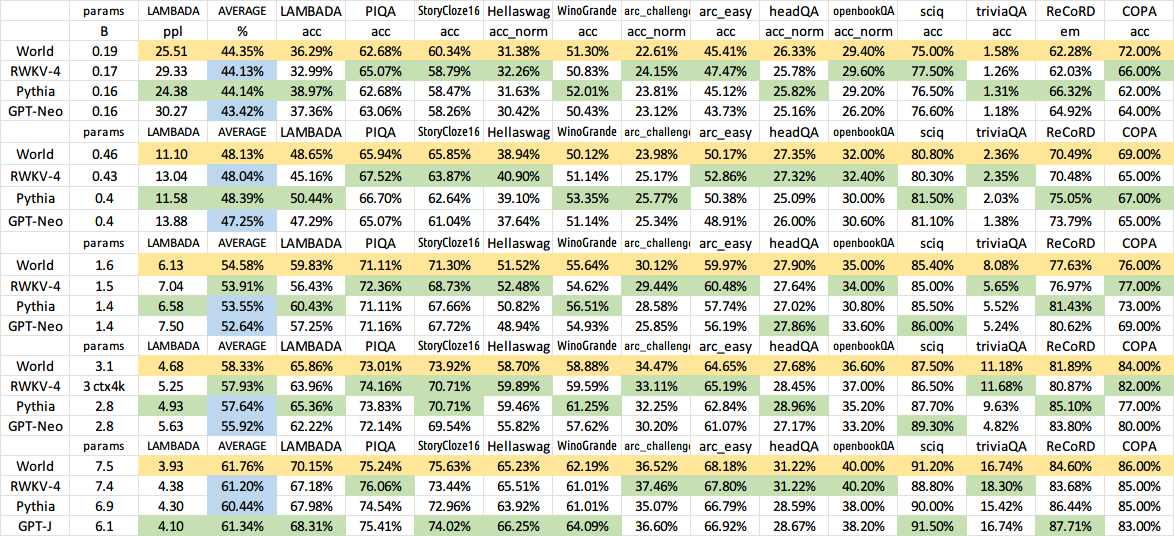
학습된 모든 모델은 오픈 소스입니다. 추론은 CPU에서도 매우 빠르므로(행렬-벡터 곱셈만 가능, 행렬-행렬 곱셈 없음) 휴대폰에서 LLM을 실행할 수도 있습니다.
작동 방식: RWKV는 여러 채널에 정보를 수집하며, 이 채널은 다음 토큰으로 이동할 때 속도가 달라집니다. 일단 이해하고 나면 매우 간단합니다.
RWKV는 각 채널의 시간 감쇠가 데이터 독립적이고 훈련 가능하기 때문에 병렬화 가능합니다 . 예를 들어, 일반적인 RNN에서는 채널의 시간 감소를 0.8에서 0.5("게이트"라고 함)로 조정할 수 있는 반면, RWKV에서는 정보를 W-0.8 채널에서 W-0.5로 간단히 이동할 수 있습니다. -동일한 효과를 얻으려면 채널을 사용하세요. 또한 추가 성능을 원할 경우 RWKV를 병렬화 불가능한 RNN으로 미세 조정할 수 있습니다(그런 다음 이전 토큰의 이후 레이어 출력을 사용할 수 있음).

다음은 내 TODO 중 일부입니다. 함께 일합시다 :)
HuggingFace 통합(huggingface/transformers#17230 확인) 및 최적화된 CPU & iOS & Android & WASM & WebGL 추론. RWKV는 RNN이며 엣지 장치에 매우 친숙합니다. 귀하의 휴대폰에서 LLM을 실행할 수 있도록 합시다.
양방향 및 MLM 작업, 이미지, 오디오 및 비디오 토큰에서 테스트하세요. RWKV는 다음을 통해 인코더-디코더를 지원할 수 있다고 생각합니다. 각 디코더 토큰에 대해 [디코더 이전 숨겨진 상태] 및 [인코더 최종 숨겨진 상태]의 학습된 혼합을 사용합니다. 따라서 모든 디코더 토큰은 인코더 출력에 액세스할 수 있습니다.
이제 작은 모델에 대한 일부 어려운 제로샷 작업(예: LAMBADA)을 더욱 개선하기 위해 하나의 작은 추가 주의(RWKV-4에 비해 몇 줄만 추가)로 RWKV-4a를 훈련합니다. https://github.com/BlinkDL/RWKV-LM/commit/a268cd2e40351ee31c30c5f8a5d1266d35b41829를 참조하세요.
사용자 피드백:
나는 지금까지 상대적으로 작은 사전 훈련 데이터 세트(약 10GB의 텍스트)에서 문자 기반 모델을 시험해 보았는데 결과는 매우 좋습니다. 훈련하는 데 훨씬 더 오랜 시간이 걸리는 모델과 비슷한 ppl입니다.
친애하는 신 rwkv는 빠릅니다. 처음부터 훈련을 시작한 후 다른 탭으로 전환했고 돌아왔을 때 그럴듯한 영어 및 마오리어 단어가 나오고 있었고 전자레인지에 커피를 마시러 떠났고 돌아왔을 때 완전히 문법적으로 올바른 문장이 생성되었습니다.
Sepp Hochreiter의 트윗(감사합니다!): https://twitter.com/HochreiterSepp/status/1524270961314484227
EleutherAI Discord에서도 저(BlinkDL)를 찾으실 수 있습니다: https://www.eleuther.ai/get-involved/
중요: deepspeed==0.7.0 pytorch-lightning==1.9.5 torch==1.13.1+cu117 및 cuda 11.7.1 또는 11.7을 사용하십시오(torch2 + deepspeed에는 이상한 버그가 있으며 모델 성능이 저하됩니다).
https://github.com/BlinkDL/RWKV-LM/tree/main/RWKV-v4neo(최신 코드, v4와 호환 가능)를 사용하세요.
LLM의 Q&A 테스트를 위한 훌륭한 프롬프트는 다음과 같습니다. 모든 모델에서 작동: (RWKV 1.5B에 대해 ChatGPT ppl을 최소화하여 발견)
prompt = f' n Q & A n n Question: n { qq } n n Detailed Expert Answer: n ' # let the model generate after thisRWKV-4 파일 모델 실행: https://huggingface.co/BlinkDL에서 모델을 다운로드하세요. run.py에 TOKEN_MODE = 'pile'을 설정하고 실행하세요. CPU(기본 모드)에서도 빠릅니다.
RWKV-4 파일 1.5B용 Colab : https://colab.research.google.com/drive/1F7tZoPZaWJf1fsCmZ5tjw6sYHiFOYVWM
브라우저(및 onnx 버전)에서 RWKV-4 파일 모델 실행: 이 문제 #7 참조
RWKV-4 웹 데모: https://josephrocca.github.io/rwkv-v4-web/demo/(참고: 현재는 탐욕스러운 샘플링만 가능)
이전 RWKV-2의 경우: 0.72 BPC(dev)가 포함된 enwik8의 27M 매개변수 모델에 대한 릴리스를 참조하세요. https://github.com/BlinkDL/RWKV-LM/tree/main/RWKV-v2-RNN에서 run.py를 실행합니다. 브라우저에서 실행할 수도 있습니다: https://github.com/BlinkDL/AI-Writer/tree/main/docs/eng https://blinkdl.github.io/AI-Writer/eng/ (이것은 다음을 사용하고 있습니다. tf.js WASM 단일 스레드 모드).
pip install deepspeed==0.7.0 // pip install pytorch-lightning==1.9.5 // 토치 1.13.1+cu117
참고: 적은 양의 데이터를 교육할 때 가중치 감소(0.1 또는 0.01) 및 드롭아웃(0.1 또는 0.01)을 추가합니다. x=x+dropout(att(x)) x=x+dropout(ffn(x)) x=dropout(x+att(x)) x=dropout(x+ffn(x)) 등을 시도해 보세요.
처음부터 RWKV-4 학습: 기본적으로 enwik8 데이터 세트(압축 해제 https://data.deepai.org/enwik8.zip)를 사용하는 train.py를 실행합니다.
병렬화가 가능하고 훈련 속도가 더 빠르기 때문에 "GPT" 버전을 훈련하게 됩니다. RWKV-4는 추정이 가능하므로 ctxLen 1024를 사용한 교육은 2500+의 ctxLen에 대해 작동할 수 있습니다. 더 긴 ctxLen을 사용하여 모델을 미세 조정할 수 있으며 더 긴 ctxLens에 빠르게 적응할 수 있습니다.
RWKV-4 파일 모델 미세 조정: https://github.com/BlinkDL/RWKV-v2-RNN-Pile/tree/main/RWKV-v3의 'prepare-data.py'를 사용하여 .txt를 기차로 토큰화합니다. npy 데이터. 그런 다음 https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v4neo/train.py를 사용하여 훈련하세요.
src/model.py에서 추론 코드를 읽고 최종 숨겨진 상태(.xx .aa .bb)를 다른 작업에 대한 충실한 문장 임베딩으로 사용해 보세요. 아마도 .xx 및 .aa/.bb(.aa를 .bb로 나눈 값)로 시작해야 할 것입니다.
RWKV-4 파일 모델 미세 조정을 위한 Colab: https://colab.research.google.com/github/resloved/RWKV-notebooks/blob/master/RWKV_v4_RNN_Pile_Fine_Tuning.ipynb
대규모 자료: https://github.com/Abel2076/json2binidx_tool을 사용하여 .jsonl을 .bin 및 .idx로 변환
jsonl 형식 샘플(각 문서당 한 줄):
{"text": "This is the first document."}
{"text": "HellonWorld"}
{"text": "1+1=2n1+2=3n2+2=4"}
다음과 같은 코드로 생성됩니다.
ss = json.dumps({"text": text}, ensure_ascii=False)
out.write(ss + "n")
무한 ctxlen 훈련(WIP): https://github.com/Blealtan/RWKV-LM-LoRA/tree/dev-infctx
RWKV 14B를 고려해보세요. 상태에는 200개의 벡터가 있습니다. 즉, 각 블록에 대해 5개의 벡터(fp16(xx), fp32(aa), fp32(bb), fp32(pp), fp16(xx)))가 있습니다.
상태의 다양한 벡터(xx aa bb pp xx)는 매우 다른 의미와 범위를 갖기 때문에 평균 풀을 사용하지 마세요. 아마도 pp를 제거할 수 있을 것입니다.
먼저 각 벡터의 각 채널에 대한 평균+표준편차 통계를 수집하고 모두 정규화하는 것이 좋습니다(참고: 정규화는 데이터 독립적이어야 하며 다양한 텍스트에서 수집되어야 합니다). 그런 다음 선형 분류기를 훈련시킵니다.
RWKV-5는 다중 헤드이며 여기서는 하나의 헤드를 보여줍니다. 각 헤드에 대한 LayerNorm도 있습니다(따라서 실제로 GroupNorm).
다이나믹 믹스 및 다이나믹 디케이. 예(TimeMix 및 ChannelMix 모두에 대해 수행):
TIME_MIX_EXTRA_DIM = 32
self.time_mix_k_w1 = nn.Parameter(torch.empty(args.n_embd, TIME_MIX_EXTRA_DIM).uniform_(-0.01, 0.01))
self.time_mix_k_w2 = nn.Parameter(torch.zeros(TIME_MIX_EXTRA_DIM, args.n_embd))
self.time_mix_v_w1 = nn.Parameter(torch.empty(args.n_embd, TIME_MIX_EXTRA_DIM).uniform_(-0.01, 0.01))
self.time_mix_v_w2 = nn.Parameter(torch.zeros(TIME_MIX_EXTRA_DIM, args.n_embd))
self.time_mix_r_w1 = nn.Parameter(torch.empty(args.n_embd, TIME_MIX_EXTRA_DIM).uniform_(-0.01, 0.01))
self.time_mix_r_w2 = nn.Parameter(torch.zeros(TIME_MIX_EXTRA_DIM, args.n_embd))
self.time_mix_g_w1 = nn.Parameter(torch.empty(args.n_embd, TIME_MIX_EXTRA_DIM).uniform_(-0.01, 0.01))
self.time_mix_g_w2 = nn.Parameter(torch.zeros(TIME_MIX_EXTRA_DIM, args.n_embd))
...
time_mix_k = self.time_mix_k.view(1,1,-1) + (x @ self.time_mix_k_w1) @ self.time_mix_k_w2
time_mix_v = self.time_mix_v.view(1,1,-1) + (x @ self.time_mix_v_w1) @ self.time_mix_v_w2
time_mix_r = self.time_mix_r.view(1,1,-1) + (x @ self.time_mix_r_w1) @ self.time_mix_r_w2
time_mix_g = self.time_mix_g.view(1,1,-1) + (x @ self.time_mix_g_w1) @ self.time_mix_g_w2
xx = self.time_shift(x)
xk = x * time_mix_k + xx * (1 - time_mix_k)
xv = x * time_mix_v + xx * (1 - time_mix_v)
xr = x * time_mix_r + xx * (1 - time_mix_r)
xg = x * time_mix_g + xx * (1 - time_mix_g)

상태를 신속하게 생성하려면 병렬 모드를 사용하고 순차적 생성을 위해 미세 조정된 전체 RNN(토큰 n의 레이어는 토큰 n-1의 모든 레이어의 출력을 사용할 수 있음)을 사용합니다.
이제 시간 붕괴는 0.999^T와 같습니다(0.999는 학습 가능). 0.1도 학습 가능한 (0.999^T + 0.1)과 같은 것으로 변경하세요. 0.1 부분은 영원히 유지됩니다. 또는 A^T + B^T + C = 빠른 감쇠 + 느린 감쇠 + 상수입니다. 다른 공식을 사용할 수도 있습니다(예: 붕괴 구성 요소에 대해 e^K 대신 K^2를 사용하거나 정규화 없이 사용).
일부 채널에서는 복소수 붕괴(즉, 붕괴 대신 회전)를 사용합니다.
훈련 가능하고 추정 가능한 위치 인코딩을 삽입하시겠습니까?
2D 회전 외에도 3D 회전( SO(3) )과 같은 다른 Lie 그룹을 시도해 볼 수 있습니다. 비아벨리안 RWKV ㅋㅋ.
RWKV는 아날로그 장치에 적합할 수 있습니다(아날로그 매트릭스-벡터 곱셈 및 광자 매트릭스-벡터 곱셈 검색). RNN 모드는 매우 하드웨어 친화적입니다(메모리 내 처리). SNN일 수도 있습니다(https://github.com/ridgerchu/SpikeGPT). 양자 계산에 최적화할 수 있는지 궁금합니다.
훈련 가능한 초기 숨겨진 상태(xx aa bb pp xx).
레이어별(또는 행/열별, 요소별) LR 및 Lion 최적화 프로그램을 테스트합니다.
self.pos_emb_x = nn.Parameter(torch.zeros((1,args.my_pos_emb,args.n_embd)))
self.pos_emb_y = nn.Parameter(torch.zeros((args.my_pos_emb,1,args.n_embd)))
...
x = x + pos_emb_x + pos_emb_y
아마도 문맥을 단순히 반복함으로써 암기력을 향상시킬 수 있을 것입니다. (내 생각에는 2번이면 충분할 것 같습니다.) 예: 참고 -> 참고(재) -> 질문 -> 답변
아이디어는 어휘의 각 토큰이 길이와 원시 UTF-8 바이트를 이해하는지 확인하는 것입니다.
어휘의 모든 토큰에 대해 a = max(len(token))이라고 둡니다. AA 정의 : float[a][d_emb]
vocab의 모든 토큰에 대해 b = max(len_in_utf8_bytes(token))로 설정합니다. BB 정의 : float[b][256][d_emb]
Vocab의 각 토큰 X에 대해 [x0, x1, ..., xn]을 원시 UTF-8 바이트로 둡니다. EMB(X) 내장에 몇 가지 추가 값을 추가하겠습니다.
EMB(X) += AA[len(X)] + BB[0][x0] + BB[1][x1] + ... + BB[n][xn] (참고: AA BB는 학습 가능한 가중치입니다)
토큰화를 개선할 아이디어가 있습니다. 일부 채널을 하드코딩하여 의미를 가질 수 있습니다. 예:
채널 0 = "공간"
채널 1 = "첫 글자를 대문자로 표시"
채널 2 = "모든 문자를 대문자로 표시"
그러므로:
"abc" 임베딩: [0, 0, 0, x0, x1, x2, ..]
" abc" 임베딩: [1, 0, 0, x0, x1, x2, ..]
"Abc" 임베딩: [1, 1, 0, x0, x1, x2, ..]
"ABC" 임베딩: [0, 0, 1, x0, x1, x2, ...]
......
따라서 그들은 대부분의 임베딩을 공유하게 됩니다. 그리고 "abc"의 모든 변형에 대한 출력 확률을 빠르게 계산할 수 있습니다.
참고: 위의 방법은 p(" xyz") / p("xyz")가 모든 "xyz"에 대해 동일하다고 가정하며 이는 틀릴 수 있습니다.
더 나은 방법: emb_space emb_capitalize_first emb_capitalize_all을 emb의 함수로 정의하세요.
어쩌면 최고일 수도 있습니다. 'abc' 'abc' 등을 사용하여 임베딩의 마지막 90%를 공유하도록 합니다.
현재 모든 토크나이저는 'abc' 'abc' 'Abc' 등의 모든 변형을 나타내기 위해 너무 많은 항목을 사용합니다. 더욱이 이러한 변형 중 일부가 데이터세트에서 드물다면 모델은 이러한 변형이 실제로 유사하다는 것을 발견할 수 없습니다. 여기서의 방법은 이를 개선할 수 있습니다. 나는 이것을 RWKV의 새 버전에서 테스트할 계획입니다.
예(단일 질의응답):
모든 위키 문서의 최종 상태를 생성합니다.
사용자 Q에 대해 가장 적합한 위키 문서를 찾고 최종 상태를 초기 상태로 사용하십시오.
모든 사용자 Q에 대한 최적의 초기 상태를 직접 생성하도록 모델을 교육합니다.
그러나 이는 여러 라운드 Q&A의 경우 좀 더 까다로울 수 있습니다. :)
RWKV는 Apple의 AFT(https://arxiv.org/abs/2105.14103)에서 영감을 받았습니다.
또한 다음과 같은 여러 가지 트릭을 사용하고 있습니다.
SmallInitEmb: https://github.com/BlinkDL/SmallInitEmb(모든 변환기에 적용 가능)는 임베딩 품질을 돕고 Post-LN(내가 사용하는 것)을 안정화합니다.
토큰 이동: https://github.com/BlinkDL/RWKV-LM#token-shift-time-shift-mixing (모든 변환기에 적용 가능), 특히 문자 수준 모델에 유용합니다.
Head-QK: https://github.com/BlinkDL/RWKV-LM#the-head-qk-trick-learning-to-copy-and-avoid-tokens(모든 변환기에 적용 가능). 참고: 도움이 되지만 100% RNN을 유지하기 위해 Pile 모델에서 비활성화했습니다.
FFN의 추가 R-게이트(모든 변압기에 적용 가능) 저도 Primer의 reluSquared를 사용하고 있습니다.
더 나은 초기화: 대부분의 행렬을 ZERO로 초기화합니다(https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v2-RNN/src/model.py의 RWKV_Init 참조).
더 빠르고 더 나은 수렴을 위해 일부 매개변수를 작은 모델에서 큰 모델로 전송할 수 있습니다(참고: 저도 정렬하고 평활화합니다). /).
내 CUDA 커널: 훈련 속도를 높이는 https://github.com/BlinkDL/RWKV-CUDA.

abcd 요소는 함께 작용하여 시간 감쇠 곡선([X, 1, W, W^2, W^3, ...])을 작성합니다.
"위치 2의 토큰"과 "위치 3의 토큰"에 대한 공식을 작성하면 다음과 같은 아이디어를 얻을 수 있습니다.
kv / k는 메모리 메커니즘입니다. 채널에서 W가 1에 가까우면 k가 높은 토큰을 오랫동안 기억할 수 있습니다.
R-gate는 성능에 중요합니다. k = 이 토큰의 정보 강도(향후 토큰으로 전달됨) r = 이 토큰에 정보를 적용할지 여부입니다.
SA 및 FF 레이어의 R/K/V에 대해 서로 다른 훈련 가능한 TimeMix 요소를 사용합니다. 예:
xx = self . time_shift ( x )
xk = x * self . time_mix_k + xx * ( 1 - self . time_mix_k )
xv = x * self . time_mix_v + xx * ( 1 - self . time_mix_v )
xr = x * self . time_mix_r + xx * ( 1 - self . time_mix_r )postLN 대신 preLN을 사용합니다(보다 안정적이고 빠른 수렴).
if self . layer_id == 0 :
x = self . ln0 ( x )
x = x + self . att ( self . ln1 ( x ))
x = x + self . ffn ( self . ln2 ( x ))RWKV-3 GPT 모드의 구성 요소는 일반적인 preLN GPT의 구성 요소와 유사합니다.
유일한 차이점은 임베딩 후 추가 LN입니다. 훈련을 마친 후 이 LN을 임베딩에 흡수할 수 있습니다.
x = self . emb ( idx ) # input: idx = token indices
x = self . ln_emb ( x ) # extra LN after embedding
x = x + self . att_0 ( self . ln_att_0 ( x )) # preLN
x = x + self . ffn_0 ( self . ln_ffn_0 ( x ))
...
x = x + self . att_n ( self . ln_att_n ( x ))
x = x + self . ffn_n ( self . ln_ffn_n ( x ))
x = self . ln_head ( x ) # final LN before projection
x = self . head ( x ) # output: x = logits내 트릭(https://github.com/BlinkDL/SmallInitEmb)을 활용하려면 emb을 nn.init.uniform_(a=-1e-4, b=1e-4)과 같은 작은 값으로 초기화하는 것이 중요합니다.
1.5B RWKV-3의 경우 8*A100 40G에서 Adam(wd 없음, 드롭아웃 없음) 최적화 프로그램을 사용합니다.
배치Sz = 32 * 896, ctxLen = 896. tf32를 사용하고 있으므로 배치Sz가 약간 작습니다.
처음 150억 개의 토큰의 경우 LR은 3e-4로 고정되고 베타=(0.9, 0.99)입니다.
그런 다음 beta=(0.9, 0.999)를 설정하고 LR의 지수적 붕괴를 수행하여 332B 토큰에서 1e-5에 도달합니다.
RWKV-3은 일반적인 의미에서 아무런 주의를 기울이지 않지만 어쨌든 이 블록을 ATT라고 부를 것입니다.
B , T , C = x . size () # x = (Batch,Time,Channel)
# Mix x with the previous timestep to produce xk, xv, xr
xx = self . time_shift ( x ) # self.time_shift = nn.ZeroPad2d((0,0,1,-1))
xk = x * self . time_mix_k + xx * ( 1 - self . time_mix_k )
xv = x * self . time_mix_v + xx * ( 1 - self . time_mix_v )
xr = x * self . time_mix_r + xx * ( 1 - self . time_mix_r )
# Use xk, xv, xr to produce k, v, r
k = self . key ( xk ). transpose ( - 1 , - 2 )
v = self . value ( xv ). transpose ( - 1 , - 2 )
r = self . receptance ( xr )
k = torch . clamp ( k , max = 60 ) # clamp k to avoid overflow
k = torch . exp ( k )
kv = k * v
# Compute the W-curve = [e^(-n * e^time_decay), e^(-(n-1) * e^time_decay), ..., 1, e^(time_first)]
self . time_w = torch . cat ([ torch . exp ( self . time_decay ) * self . time_curve . to ( x . device ), self . time_first ], dim = - 1 )
w = torch . exp ( self . time_w )
# Use W to mix kv and k respectively. Add K_EPS to wk to avoid divide-by-zero
if RUN_DEVICE == 'cuda' :
wkv = TimeX . apply ( w , kv , B , C , T , 0 )
wk = TimeX . apply ( w , k , B , C , T , K_EPS )
else :
w = w [:, - T :]. unsqueeze ( 1 )
wkv = F . conv1d ( nn . ZeroPad2d (( T - 1 , 0 , 0 , 0 ))( kv ), w , groups = C )
wk = F . conv1d ( nn . ZeroPad2d (( T - 1 , 0 , 0 , 0 ))( k ), w , groups = C ) + K_EPS
# The RWKV formula
rwkv = torch . sigmoid ( r ) * ( wkv / wk ). transpose ( - 1 , - 2 )
rwkv = self . output ( rwkv ) # final output projectionself.key, self.receptance, self.output 행렬은 모두 0으로 초기화됩니다.
time_mix, time_decay, time_first 벡터는 더 작은 훈련 모델에서 전송됩니다(참고: 나도 정렬하고 평활화합니다).
FFN 블록에는 일반적인 GPT와 비교하여 세 가지 트릭이 있습니다.
내 time_mix 트릭.
Primer 논문의 sqReLU.
추가 수용 게이트(ATT 블록의 수용 게이트와 유사)
# Mix x with the previous timestep to produce xk, xr
xx = self . time_shift ( x )
xk = x * self . time_mix_k + xx * ( 1 - self . time_mix_k )
xr = x * self . time_mix_r + xx * ( 1 - self . time_mix_r )
# The usual FFN operation
k = self . key ( xk )
k = torch . square ( torch . relu ( k )) # from the Primer paper
kv = self . value ( k )
# Apply an extra receptance-gate to kv
rkv = torch . sigmoid ( self . receptance ( xr )) * kv
return rkvself.value, self.receptance 행렬은 모두 0으로 초기화됩니다.

F[t]를 t에서의 시스템 상태로 둡니다.
x[t]를 t의 새로운 외부 입력으로 둡니다.
GPT에서 F[t+1]을 예측하려면 F[0], F[1], .. F[t]를 고려해야 합니다. 따라서 길이가 T인 시퀀스를 생성하려면 O(T^2)가 필요합니다.
GPT의 단순화된 공식 :
이론적으로는 매우 유능하지만 이것이 일반적인 최적화 프로그램을 사용하여 그 기능을 완전히 활용할 수 있다는 의미는 아닙니다 . 현재 방법으로는 손실 환경이 너무 어려운 것 같습니다.
RWKV의 단순화된 공식 과 비교해 보세요(병렬 모드는 Apple의 AFT와 유사함).
R, K, V는 훈련 가능한 행렬이고, W는 훈련 가능한 벡터(각 채널에 대한 시간 감소 인자)입니다.
GPT에서는 F[t+1]에 대한 F[i]의 기여도에 .
RWKV-2에서는 F[t+1]에 대한 F[i]의 기여도에 가중됩니다.
핵심은 다음과 같습니다. 이를 RNN(재귀 공식)으로 다시 작성할 수 있습니다. 메모:
따라서 확인하는 것은 간단합니다.
여기서 A[t]와 B[t]는 각각 이전 단계의 분자와 분모입니다.
W는 대각 행렬을 반복적으로 적용하는 것과 같기 때문에 RWKV가 성능이 좋다고 생각합니다. 참고로 (P^{-1} DP)^n = P^{-1} D^n P이므로 일반 대각화 가능 행렬을 반복 적용하는 것과 유사합니다.
또한 이를 연속 ODE(상태 공간 모델과 약간 유사)로 변환하는 것도 가능합니다. 나중에 그것에 대해 쓰겠습니다.
LM(변압기, RWKV 등)을 사용하여 [텍스트 -> 32x32 RGB 이미지]에 대한 아이디어가 있습니다. 곧 테스트하겠습니다.
첫째, LM 손실(L2 손실 대신)이므로 이미지가 흐려지지 않습니다.
둘째, 색상 양자화. 예를 들어 R/G/B에는 8레벨만 허용됩니다. 그러면 이미지 어휘 크기는 2^24가 아닌 8x8x8 = 512(각 픽셀당)입니다. 따라서 32x32 RGB 이미지 = vocab512(이미지 토큰)의 len1024 시퀀스이며 이는 일반적인 LM의 일반적인 입력입니다. (나중에 확산 모델을 사용하여 RGB888 이미지를 업샘플링하고 생성할 수 있습니다. 이 경우에도 LM을 사용할 수 있습니다.)
셋째, 모델이 이해하기 쉬운 2D 위치 임베딩입니다. 예를 들어, 처음 64(=32+32)개 채널에 원-핫 X 및 Y 좌표를 추가합니다. 픽셀이 x=8, y=20이면 채널 8과 채널 52(=32+20)에 1을 추가합니다. 또한 부동 소수점 X 및 Y 좌표(0~1 범위로 정규화됨)를 다른 2개 채널에 추가할 수도 있습니다. 그리고 기타 정기 pos. 인코딩도 도움이 될 수 있습니다(테스트 예정).
마지막으로 RandRound는


