CAMEL
1.0.0

더욱 발전된 임상용 대형 언어 모델 인 Asclepius를 소개하게 된 것을 자랑스럽게 생각합니다. 이 모델은 합성 임상 노트로 훈련되었으므로 Huggingface를 통해 공개적으로 액세스할 수 있습니다. CAMEL 사용을 고려하고 있다면 대신 Asclepius로 전환하는 것이 좋습니다. 자세한 내용은 이 링크를 참조하세요.
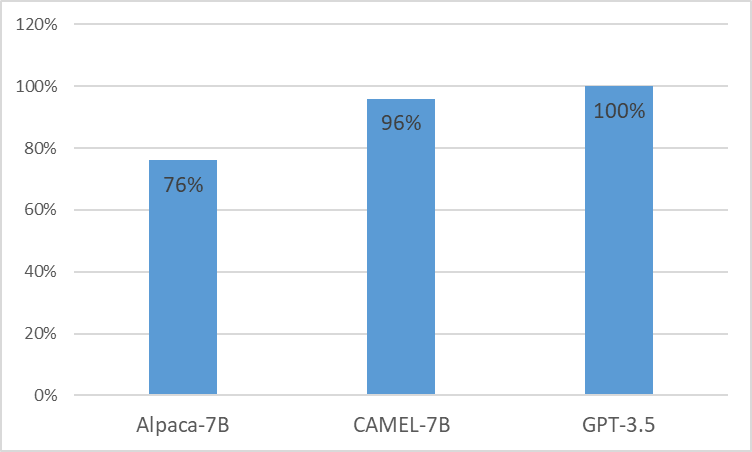
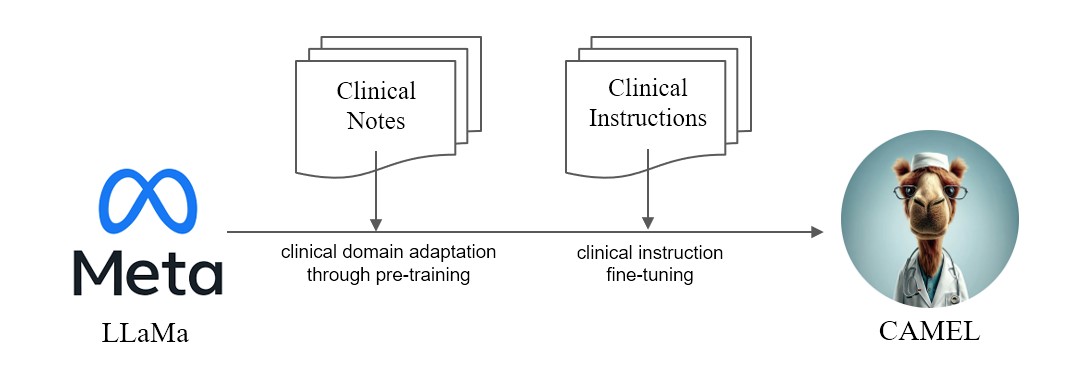
우리는 LLaMA에서 향상된 임상 적응 모델인 CAMEL을 제시합니다. LLaMA의 기초로서 CAMEL은 MIMIC-III 및 MIMIC-IV 임상 노트에 대해 추가로 사전 교육을 받고 임상 지침에 따라 미세 조정됩니다(그림 2). GPT-4 평가를 통한 예비 평가는 CAMEL이 OpenAI GPT-3.5 품질의 96% 이상을 달성했음을 보여줍니다(그림 1). 소스 데이터의 데이터 사용 정책에 따라 지침 데이터세트와 모델 모두 인증된 액세스를 통해 PhysioNet에 게시됩니다. 복제를 용이하게 하기 위해 모든 코드를 공개하여 개별 의료 기관이 자체 임상 노트를 사용하여 모델을 재현할 수 있도록 할 것입니다. 자세한 내용은 블로그 게시물 을 참조하세요.
MIMIC 및 i2b2 데이터세트의 라이선스 문제로 인해 지침 데이터세트와 체크포인트를 게시할 수 없습니다. 우리는 몇 주 안에 피지오넷을 통해 우리의 모델과 데이터를 게시할 것입니다.
conda create -n camel python=3.9 -y
conda activate camel
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia -y
pip install pandarallel pandas jupyter numpy datasets sentencepiece openai fire
pip install git+https://github.com/huggingface/transformers.git@871598be552c38537bc047a409b4a6840ba1c1e4
<eos> 토큰으로 연결합니다.$ python pretraining_preprocess/mimiciii_preproc.py --mimiciii_note_path {MIMICIII_NOTE_PATH} --output_path {OUTPUT_PATH}$ python pretraining_preprocess/mimiciv_preproc.py --discharge_note_path {DISCHAGE_NOTE_PATH} --radiology_note_path {RADIOLOGY_NOTE_PATH} --output_path {OUTPUT_PATH}$ python pretraining_preprocess/tokenize_data.py --data_path {DATA_PATH} --save_path {SAVE_PATH} $ torchrun --nproc_per_node=8 --master_port={YOUR_PORT}
src/train.py
--model_name_or_path "decapoda-research/llama-7b-hf"
--data_path {DATA_FILE}
--bf16 True
--output_dir ./checkpoints
--num_train_epochs 1
--per_device_train_batch_size 2
--per_device_eval_batch_size 2
--gradient_accumulation_steps 8
--evaluation_strategy "no"
--save_strategy "steps"
--save_steps 1000
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--lr_scheduler_type "cosine"
--logging_steps 1
--fsdp "full_shard auto_wrap"
--fsdp_transformer_layer_cls_to_wrap 'LlamaDecoderLayer'
--tf32 True
--model_max_length 2048
--gradient_checkpointing True
참고: 지침을 생성하려면 인증된 Azure Openai API를 사용해야 합니다.
명령어 생성
OPENAI_API_KEYOPENAI_API_BASEOPENAI_DEPLOYMENT_NAME$ python instructino/preprocess_note.py$ python instruction/de_id_gen.py --input {PREPROCESSED_NOTES} --output {OUTPUT_FILE_1} --mode inst$ python instruction/de_id_postprocess.py --input {OUTPUT_FILE_1} --output {OUTPUT_FILE_2}$ python instruction/de_id_gen.py --input {OUTPUT__FILE_2} --output {inst_output/OUTPUT_FILE_deid} --mode ans$ python instruction/instructtion_gen.py --input {PREPROCESSED_NOTES} --output {inst_output/OUTPUT_FILE} --source {mimiciii, mimiciv, i2b2}$ python instruction/merge_data.py --data_path {inst_output} --output {OUTPUT_FILE_FINAL}명령어 미세 조정 실행
nproc_per_node 및 gradient accumulate step 조정합니다(글로벌 배치 크기=128). $ torchrun --nproc_per_node=8 --master_port={YOUR_PORT}
src/instruction_ft.py
--model_name_or_path "decapoda-research/llama-7b-hf"
--data_path {OUTPUT_FILE_FINAL}
--bf16 True
--output_dir ./checkpoints
--num_train_epochs 3
--per_device_train_batch_size 2
--per_device_eval_batch_size 2
--gradient_accumulation_steps 8
--evaluation_strategy "no"
--save_strategy "epoch"
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--lr_scheduler_type "cosine"
--logging_steps 1
--fsdp "full_shard auto_wrap"
--fsdp_transformer_layer_cls_to_wrap 'LlamaDecoderLayer'
--tf32 True
--model_max_length 2048
--gradient_checkpointing True
--ddp_timeout 18000
MTSamples에서 모델 실행
CUDA_VISIBLE_DEVICES=0 python src/evaluate.py
--model_name {MODEL_PATH}
--data_path eval/mtsamples_instructions.json
--output_path {OUTPUT_PATH}
eval 폴더에 mtsamples_results.json 으로 제공합니다.평가를 위해 GPT-4 실행
python eval/gpt4_evaluate.py --input {INPUT_PATH} --output {OUTPUT_PATH}
@misc{CAMEL,
title = {CAMEL : Clinically Adapted Model Enhanced from LLaMA},
author = {Sunjun Kweon and Junu Kim and Seongsu Bae and Eunbyeol Cho and Sujeong Im and Jiyoun Kim and Gyubok Lee and JongHak Moon and JeongWoo Oh and Edward Choi},
month = {May},
year = {2023}
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/starmpcc/CAMEL}},
}


